从0开始基于docker的大数据环境搭建/Hadoop+Spark+Flink+Hbase+Kafka+Hive+Flume+Zookeeper+Mysql等
基于docker的大数据单节点整合容器
该博客由上海第二工业大学数据科学与大数据技术专业师生共同探索、共同打造,期间踩坑无数,旨在为后续教学工作提供参考,为其他有需要的同行提供便利。
目录
如果不想了解docker的配置过程,可以直接阅读第一部分与第二部分的代理配置环节
前言
1、Docker compose链接:
通过网盘分享的文件:Great-United-Docker
链接: https://pan.baidu.com/s/1SDtTb7N0HTx4zC6fYB5dRg?pwd=s9fg 提取码: s9fg
Great-United-Docker![]() https://pan.baidu.com/s/1SDtTb7N0HTx4zC6fYB5dRg?pwd=s9fg
https://pan.baidu.com/s/1SDtTb7N0HTx4zC6fYB5dRg?pwd=s9fg
2、本文会详细介绍如何从Ubuntu镜像开始搭建单节点大数据环境,供测试教学使用
3、容器中的环境安装均采用本地COPY,支持更改为wget,
无安装包,由wget实现的Github链接:/使用wget从官网下载,有需求可以更改dockerfile中的链接地址
-
Hadoop 3.3.6
-
Spark 3.2.0
-
HBase 2.5.11
-
Kafka 3.7.2
-
Flink 1.13.0
-
Zookeeper 3.8.4
-
Hive 4.0.1
-
Phoenix 5.1.3/6.0.0
-
Flume 1.11.0
-
MySQL(直接安装)
一、直接安装
0.安装docker desktop与WSL
docker desktop![]() https://www.docker.com/products/docker-desktop/WSL
https://www.docker.com/products/docker-desktop/WSL![]() https://learn.microsoft.com/zh-cn/windows/wsl/install
https://learn.microsoft.com/zh-cn/windows/wsl/install
安装WSL只需要打开cmd输入
wsl --install即可
没有WSL,docker desktop无法正常启动,安装过程中需要重启,注意保存文件
拉取镜像需要配置代理,详见后文
1.准备
将 安装包(hbase,zookeeper,Hadoop等) ,Dockerfile , docker-compose.yml ,entrypoint.sh ,kf.sh放在同一文件夹下
2.使用cmd进行安装
在文件夹中打开cmd
3.使用命令
#安装docker镜像
docker-compose build
#生成docker容器
docker-compose up
#卸载由该docker-compose安装的本地镜像(会删除容器)
#docker-compose down --rmi local
#不需要执行4.等待安装
5.安装完成
类似:
6.点击运行按钮启动容器
7.在cmd中连接容器
#连接docker容器
docker exec -it <容器名> /bin/bash
#容器名能连,容器ID(Container ID)的前三位也可以(更方便)8.启动完成
容器相当于一个虚拟机,在bash界面直接操作即可
- 自启动项目:
SSH Hadoop zookeeper
Spark Hbase Flink
Kafka MySQL Phoenix Query Server
以上项目已配置自启动,无需再次运行启动命令
其他项目启动命令如下
#Hive
/opt/hive/bin/hive
#Phoenix Hbase
/opt/phoenix/bin/sqlline.py localhost
#Flume
bin/flume-ng agent -c ./conf -f ./conf/hdfs-avro.conf -n a1 -Dflume.root.logger=INFO,console- 可选安装:
pyspark
phoenixdb等
二、Dokcer概念与配置
1.Docker概念
镜像与容器:
镜像是一个只读的模板,所有容器通过镜像生成
容器类似于一台虚拟机
docker通过镜像来保证 由同一个镜像生成的所有容器里面的配置内容在初始状态都完全一致
Dockerfile:
镜像具体的安装配置
不指定名称的情况下D必须大写
相当于一个执行脚本,但是需要通过特殊命令执行
Docker-compose:安装脚本
可以通过配置这个文件来指定很多个性化的配置需求(如Dockerfile名称):
zookeeper1: #执行安装镜像
container_name: zookeeper1 #容器名称
image: zookeeper1 #镜像名称
build:
context: ./zookeeper #dockerfile所在目录
dockerfile: zookeeper.Dockerfile #dockerfile名称
environment: #环境变量
MY_ID: 1
networks: #docker网络依赖
bigdata-net:
ipv4_address: 172.20.0.11
depends_on: #该镜像依赖于哪些前置镜像
- base
ports: #端口映射
- "2181:2181"
- "2888:2888"
- "3888:3888"
基于docker-compose创建多个镜像对于互相没有依赖的镜像是并行创建的,因此:
depends_on设置决定了docker镜像的创建顺序,有依赖的镜像会等待前置镜像创建完成后再创建,但是这个依赖与dockerfile中的FROM无关,如果在镜像中的FROM依赖同一批docker镜像中的某一个,请在这里配置他的依赖镜像,如果不配置会从dockerhub中拉取同名镜像
端口映射在docker容器的配置中十分重要,一旦容器配置完毕映射到宿主机的端口无法更改,只能删除容器重新配置端口映射
entrypoint:启动脚本
便捷的在容器启动时启动其他服务(如SSH,Hadoop,Hbase等)
#!/bin/bash #必须在第一行
# 等待YARN ResourceManager就绪
while ! nc -z resourcemanager 8088; do #等待前置 / nc命令需要安装netcat
echo "等待ResourceManager启动..."
sleep 5
done# 配置Spark以使用YARN
echo "配置Spark以使用YARN集群..."# 启动Spark Master (独立模式)
$SPARK_HOME/sbin/start-master.sh -h 0.0.0.0 #启动服务# 保持容器运行
tail -f $SPARK_HOME/logs/*#docker容器会在执行完这个脚本后自动退出,需要上面这个命令运行在前台,否则无法持续运行
#也可写为tail -f /dev/null
2.Docker配置
以dockerfile为基础,dockercompose设置内容,entrypoint执行脚本
只有dockerfile也能安装docker镜像和容器
也可从dockerhub等地方拉取 国内通常需要配置代理
代理配置
打开docker desktop,点击右上角齿轮,选择DockerEngine选项
复制代码并粘贴到框内
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.mybacc.com",
"https://dytt.online",
"https://lispy.org",
"https://docker.xiaogenban1993.com",
"https://docker.yomansunter.com",
"https://aicarbon.xyz",
"https://666860.xyz",
"https://docker.zhai.cm",
"https://a.ussh.net",
"https://hub.littlediary.cn",
"https://hub.rat.dev",
"https://docker.m.daocloud.io"
]
}应用并重启
镜像存储
同一页面,上一行,选择 Resource,下拉菜单中选择第一个 Advances
在Disk image location 旁边点击 Browse 选择一个 空间足够大(最好空余50G以上)的路径,可以直接选择大的盘符目录,会自动生成文件夹,不用担心文件乱飞
三、Docker file配置
1.Docker file概念
docker file是docker镜像的核心,大部分的配置需要靠docker file实现,他相当于一个脚本,通过命令来构建和配置docker镜像
dockerfile中的命令:
FROM:指定从哪个基础镜像进行安装
ENV:直接设置环境变量
RUN:相当于在容器中执行命令
COPY:与liunx的cp命令类似
ENTRYPOINT & CMD:指定进入容器后执行的命令,ENTRYPOINT优先级最高,同时配置会把CMD中传入的数据接在ENTRYPOINT之后。
- 有ENTRYPOINT执行ENTRYPOINT,没有ENTRYPOINT执行CMD
- 多个CMD只执行最后一个
单节点的dockerfile配置十分冗长,建议将各种环境配置文件写好后统一复制到对应路径中
在这为了演示配置过程与变量设置选择使用sed命令与echo命令编辑配置文件
2.前置环境,下载与放置安装包,配置环境变量
FROM ubuntu:22.04 AS builder
RUN echo "Acquire::https::Verify-Peer \"false\";" >> /etc/apt/apt.conf.d/99verify-peer.conf && \
echo "Acquire::https::Verify-Host \"false\";" >> /etc/apt/apt.conf.d/99verify-host.conf
# 更换为阿里云源
RUN sed -i 's|http://.*ubuntu.com|https://mirrors.aliyun.com|g' /etc/apt/sources.list
# 安装必要的工具和依赖
RUN apt-get update && apt-get install -y \
mysql-server && \
mkdir -p /opt && \
mkdir -p /install
# 设置环境变量
# 基础环境变量
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 \
HADOOP_HOME=/opt/hadoop \
ZOOKEEPER_HOME=/opt/zookeeper \
SPARK_HOME=/opt/spark \
SCALA_HOME=/opt/scala \
HBASE_HOME=/opt/hbase \
FLINK_HOME=/opt/flink \
KAFKA_HOME=/opt/kafka \
HIVE_HOME=/opt/hive \
FLUME_HOME=/opt/flume \
CONDA_HOME=/opt/miniconda3
# 其他组件
ENV JRE_HOME=$JAVA_HOME \
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop \
SPARK_DIST_CLASSPATH=$HBASE_HOME/lib/* \
HBASE_CONF_DIR=$HBASE_HOME/conf \
HIVE_CONF_DIR=$HIVE_HOME/conf \
FLUME_CONF_DIR=$FLUME_HOME/conf
# 统一 PATH 配置
ENV PATH=$PATH:\
$CONDA_HOME/bin:\
$JAVA_HOME/bin:\
$HADOOP_HOME/bin:\
$HADOOP_HOME/sbin:\
$ZOOKEEPER_HOME/bin:\
$SCALA_HOME/bin:\
$SPARK_HOME/bin:\
$SPARK_HOME/sbin:\
$HBASE_HOME/bin:\
$HIVE_HOME/bin:\
$KAFKA_HOME/bin:\
$FLINK_HOME/bin:\
$FLUME_HOME/bin基于Ubuntu 22.04配置,设置环境变量javahome,创建安装包目录/install
配置代理到国内镜像源,由于后面新增了通过apt安装mysql,国内镜像会更快一些
第一个RUN禁用了证书验证,Ubuntu 22.04没有内置CA证书,导致无法验证阿里云镜像站的 HTTPS 证书,会导致无法下载,为方便直接禁用了,通过apt再下载ca-certificates和apt-transport-https太麻烦还花更多时间
FROM ubuntu:22.04 AS builder这一段是优化后的构建阶段,不需要可以把 AS builder 删除
3.解压缩并安装
# 从本地复制安装包到容器中
COPY opt/* /install/
#安装软件并统一命名
RUN mkdir -p /opt/hadoop /opt/zookeeper /opt/scala /opt/spark /opt/hbase /opt/hive /opt/kafka /opt/flink /opt/flume /opt/phoenix /opt/phoenix-queryserver && \
tar -xzf /install/hadoop-3.3.6.tar.gz -C /opt/hadoop --strip-components=1 && \
tar -xzf /install/apache-zookeeper-3.8.4-bin.tar.gz -C /opt/zookeeper --strip-components=1 && \
tar -xzf /install/scala-2.12.0.tgz -C /opt/scala --strip-components=1 && \
tar -xzf /install/spark-3.2.0-bin-hadoop3.2.tgz -C /opt/spark --strip-components=1 && \
tar -xzf /install/hbase-2.5.11-bin.tar.gz -C /opt/hbase --strip-components=1 && \
tar -xzf /install/apache-hive-4.0.1-bin.tar.gz -C /opt/hive --strip-components=1 && \
tar -xzf /install/kafka_2.12-3.7.2.tgz -C /opt/kafka --strip-components=1 && \
tar -xzf /install/flink-1.13.0-bin-scala_2.11.tgz -C /opt/flink --strip-components=1 && \
tar -xzf /install/apache-flume-1.11.0-bin.tar.gz -C /opt/flume --strip-components=1 && \
tar -xzf /install/phoenix-hbase-2.5-5.1.3-bin.tar.gz -C /opt/phoenix --strip-components=1 && \
tar -xzf /install/phoenix-queryserver-6.0.0-bin.tar.gz -C /opt/phoenix-queryserver --strip-components=1 && \
cp /opt/phoenix/phoenix-pherf-5.1.3.jar $HBASE_HOME/lib/ && \
cp /opt/phoenix/phoenix-server-hbase-2.5-5.1.3.jar $HBASE_HOME/lib/ && \
cp /opt/phoenix/phoenix-client-hbase-2.5-5.1.3.jar /opt/phoenix-queryserver/
复制安装包到安装包目录/install
phoenix的安装只需要解压与复制文件,不再后面列出
scala如上
环境配置已写入单独的配置文件,只需要放在dockerfile同级的/conf文件夹中,后续配置会统一复制进入对应的路径
请确保hadoop,zookeeper,hbase三者版本互相兼容
请确保hbase-x.y.*版本与phoenix-hbase-x.y-*版本完全对应
如果不能保证请安装与上述版本之间足够接近的版本(如hdp3.3.*/zk3.8.*/hbase2.5.*)
Phoenix-hbase需要复制自己的文件到hbase的文件夹中,前面已经操作完成,后面不再配置
Phoenix-queryserver依赖Phoenix-hbase的jar包,前面已经复制了,其余配置已经整合进hbase与Phoenix-hbase的配置中,后面不再配置queryserver
值得注意的是,对于phoenix-hbase-2.5-5.2.1,其与queryserver-6.0.0似乎存在兼容性问题,如果同时选择会导致queryserver自带的servlet API 与 hadoop和hbase的servlet API产生冲突,原因不明,故选择5.1.3版本
4.环境配置文件
参考环境配置方案,会与原文有所不同
所有原文件都能从压缩包中直接获取,未作说明默认基于原文件直接添加,如果不想自行配置请从网盘中下载已配置完的文件
1-Hadoop
#配置Hadoop
COPY conf/hadoop/* /opt/hadoop/etc/hadoop/hadoop-env.sh
#hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_PID_DIR=/opt/hadoop/pids
export HADOOP_LOG_DIR=/opt/hadoop/logs
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml
#core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-container:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description>Hadoop的超级用户root能代理的节点</description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>Hadoop的超级用户root能代理的用户组</description>
</property>
</configuration>fs.defaultfs定义了hdfs的访问端口,后面会经常配到
如果需要跨容器访问hdfs,localhost需要改为当前容器名,如bigdata-container
yarn-site.xml
#yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>fs.namenode.name.dir</name>
<value>/opt/hadoop/namenode</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/datanode</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:8088</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2548</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8192</value>
<discription>单个任务可申请最大内存,默认8192MB</discription>
</property>
</configuration>dfs.replication配置了有多少备份,测试环境配1就行
yarn.*.hostname定义了manager的访问地址,很重要
注意到在hostname与bind-host等中配置了0.0.0.0,是因为需要外部访问容器内的模块时,需要开放给所有ip,如果设置127.0.0.1或者localhost会出现只能在容器内访问而不能从宿主机中访问的情况,后面会多次遇到需要这样配置的地方
hdfs-site.xml
#hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/namenode</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.datanode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/datanode</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
</configuration>dfs.webhdfs.enable决定了是否启用webhdfs服务,启用后任何能发送http请求的语言都能接入hdfs,用于python连接等
mapred-site.xml
#mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
</configuration>2-Zookeeper
#配置Zookeeper
RUN mv /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg && \
mkdir /opt/zookeeper/data
zoo.cfg & myid
RUN sed -i 's/dataDir=\/tmp\/zookeeper/dataDir=\/opt\/zookeeper\/data/' /opt/zookeeper/conf/zoo.cfg && \
echo 'server.0=localhost:2888:3888' >> /opt/zookeeper/conf/zoo.cfg
RUN echo '0' >> /opt/zookeeper/data/myid在zoo.cfg中,server.x需要设置与自己配置的zookeeper节点数相同的数量,myid每个节点只需要写一份,标识自己节点的id。该id需要与server.x中的x对应,即存在x为1,2,3;则myid应当为1 / 2 / 3中的一个,不能为0或其他不存在于前文x的数。从几开始分配没有限制,不一定需要从0开始。
在单节点配置中,myid也不能省略。
对于3888端口,该端口为zookeeper的选举端口,即使只有一个节点的zookeeper也需要配置该端口
对于前文在docker-compose中做案例的zookeeper节点配置,其中的MY_ID环境变量不能替代myid文件,这个环境变量可以用来创建myid文件,在其entrypoint.sh文件中实现如下
echo ${MY_ID:-1} > $ZOOKEEPER_HOME/data/myid
#根据 MY_ID 写入数据,如果 MY_ID 变量为空,则默认写入1
#代码仅作演示,在该配置中非必要3-Hbase
#配置Hbase
COPY conf/hbase/* /opt/hbase/conf/
在不同版本的hbase中可能有不同于hadoop中的slf4j绑定文件,不删除会出现slf4j多重绑定问题,但是执行过程中没有报错就不要乱删
对于出现了多重绑定问题的情况,删除其中一个即可,一般选择保留版本较高的
hbase-env.sh
#hbase-env.sh
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_CLASSPATH=/opt/hadoop/etc/hadoop
export HADOOP_HOME=/opt/hadoop
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
定义环境变量,因为要使用外部zookeeper,所以hbase-manages-zk要设置成false
hbase-site.xml
#hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
<description>这个目录是region server的共享目录,用来持久化Hbase</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>Hbase的运行模式。false是单机模式,true是分布式模式</description>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://localhost:60000</value>
<description>hmaster port</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
<description>zookeeper集群的URL配置,多个host之间用逗号(,)分割</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/zookeeper/data</value>
<description>zookeeper的zooconf中的配置,快照的存储位置</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.master.ipc.address</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hbase.regionserver.ipc.address</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespace</name>
<value>true</value>
</property>
</configuration>hbase.rootdir中地址要与前面hadoop中的配置相同
regionservers
#单节点无需配置
#RUN echo'' >> /opt/hbase-2.5.11/conf/regionservers虽然单节点无需配置,但是如果有多节点需求,需要在这里写其他regionserver的主机名或ip,如:regionserver1 regionserver2
hadoop-conf
#拷贝Hadoop配置
RUN cp /opt/hadoop/etc/hadoop/hdfs-site.xml /opt/hbase/conf && \
cp /opt/hadoop/etc/hadoop/core-site.xml /opt/hbase/confHbase依赖hdfs存储数据,所以需要知道hadoop的设置
在后面的许多依赖hadoop的软件中都会用到hadoop设置或者hadoop设置的路径
4-Phoenix-hbase
Phoenix-hbase与Phoenix-queryserver之间有依赖,但是这个依赖已经在安装Phoenix-queryserver的时候处理了,这边不再配置
hbase-site.xml
#hbase-site.xml
RUN sed -i '/<\/configuration>/i\<property>\n\
<name>hbase.regionserver.wal.codec</name>\n\
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>\n\
</property>\n\
<property>\n\
<name>phoenix.schema.mapSystemTablesToNamespace</name>\n\
<value>true</value>\n\
</property>' /opt/hbase-2.5.11/conf/hbase-site.xml
这里可通过pip安装phoenixdb
phoenixdb
RUN pip3 install phoenixdb5-Spark
#配置Spark
COPY conf/spark/* /opt/spark/conf/
COPY opt/spark-examples_2.11-1.6.0-typesafe-001.jar \
/opt/spark/jars/这里需要单独下载一个文件spark-examples用于pyspark的调用
# local部署模式
spark-env.sh
#spark-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SCALA_HOME=/opt/scala
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/spark
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export YARN_CONF_DIR=/opt/hadoop/etc/hadoopspark依赖hadoop的hdfs存储数据、yarn的资源调度,所以这里要配置hadoop参数
# yarn部署模式
spark-defaults.conf
#spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:9000/user/spark/directory注意eventLog.dir 中的路径需要与hadoop中的保持一致
#修改wokers
workers
#修改wokers
RUN cp /opt/spark/conf/workers.template /opt/spark/conf/workers这里只对文件进行重命名的原因是:workers文件自带localhost,单节点配置的worker本来就是localhost,不需要再配置了
这里可以通过pip安装pyspark
pyspark
#在容器启动后的jupyter内或其他ide中单独安装
!pip install pyspark==3.2.0
6-Scala
Scala语言的安装不是必须的,spark自带scala语言环境,如果需要使用scala语言编程可以安装
Scala的配置只需要解压后配置环境变量即可,已经在安装时完成了,这里不再给出代码
7-Kafka
server.properties
RUN sed -i 's/#listeners=PLAINTEXT:\/\/:9092/listeners=PLAINTEXT:\/\/:9092/' /opt/kafka/config/server.properties && \
sed -i 's/zookeeper.connect=localhost:2181/zookeeper.connect=localhost:2181\/kafka/' /opt/kafka/config/server.properties && \
sed -i 's|#advertised.listeners=.*|advertised.listeners=PLAINTEXT://localhost:9092|' /opt/kafka/config/server.properties && \
sed -i 's|log.dirs=\/tmp\/kafka-logs|log.dirs=\/opt\/kafka\/data|' /opt/kafka/config/server.properties && \
mkdir -p /opt/kafka/data需要注意的是,PLAINTEXT虽然被写死为了localhost:9092,但是如果需要从宿主机外部连接容器内的kafka,需要配置为一个可被外界访问的地址,如192.168.xxx.yyy等。
8-Flink
#配置Flink
COPY conf/flink/* /opt/flink/conf/flink-conf.yaml
#flink-conf.yaml
jobmanager.rpc.address: 0.0.0.0
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: 0.0.0.0
rest.port: 8083
rest.address: 0.0.0.0
rest.bind-port: 8083-8090
rest.bind-address: 0.0.0.0原文件较长,不想单独修改可以用以下代码
#flink-conf.yaml
RUN sed -i 's/jobmanager.rpc.address: localhost/jobmanager.rpc.address: 0.0.0.0/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/jobmanager.bind-host: localhost/jobmanager.bind-host: 0.0.0.0/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/taskmanager.bind-host: localhost/taskmanager.bind-host: 0.0.0.0/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/taskmanager.host: localhost/taskmanager.host: 0.0.0.0/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/#rest.port: 8081/rest.port: 8083/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/rest.address: localhost/rest.address: 0.0.0.0/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/rest.bind-address: localhost/rest.bind-address: 0.0.0.0/' /opt/flink-1.17.2/conf/flink-conf.yaml && \
sed -i 's/#rest.bind-port: 8080-8090/rest.bind-port: 8083-8090/' /opt/flink-1.17.2/conf/flink-conf.yaml对于端口8080-8090,这是让flink自己选择端口,为了避免冲突所以设置到了8083-8090。如果不这样设置flink可能会选择8080。在docker的配置中容器映射的端口是很重要的配置,如不能确定,则需要映射所有可能端口,因为容器在建立后映射的端口无法改变,只能删除容器重新配置端口映射
9-Flume
#配置Flume
RUN cp /opt/flume/conf/flume-env.sh.template /opt/flume/conf/flume-env.sh
RUN echo 'export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64' >> /opt/flume/conf/flume-env.sh
COPY conf/flume/* /opt/flume/conf/hdfs-avro.conf
#hdfs-avro.conf
# 定义这个agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 配置源,用于监控文件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/apache-flume-1.11.0-bin/test/1.log
a1.sources.r1.channels = c1
# 配置接收器,用于HDFS
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/events/%y-%m-%d/%H-%M
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 1024
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.channel = c1
# 配置通道,内存型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 绑定源和接收器到通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c110-1.Hive
#配置Hive
RUN rm /opt/hive/lib/log4j-slf4j-impl-2.18.0.jar
COPY conf/hive/* /opt/hive/conf/
RUN cp /install/mysql-connector-java-8.0.18.jar /opt/hive/lib
RUN cp /install/mysql-connector-java-8.0.18.jar $SPARK_HOME/jars/ hive-env.sh
#hive-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=/opt/hive/conf
export HIVE_AUX_JARS_PATH=/opt/hive/lib
export HADOOP_HOME=/opt/hadoopHive 依赖 Hadoop 的可执行文件,所以需要指定 Hadoop 安装目录
hive-site.xml
#hive-site.xml
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive/tmp/</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive/tmp/${hive.session.id}_resources</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hive/tmp/</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hive/tmp/root/operation_logs</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>最后两个配置*Username与*Password分别设置了hive登录mysql的用户和密码
yarn-site.xml
#yarn-site.xml
RUN sed -i '/<\/configuration>/i\ <property>\n\
<name>yarn.nodemanager.resource.memory-mb</name>\n\
<value>2548</value>\n\
<discription>每个节点可用内存,单位MB</discription>\n\
</property>\n\
<property>\n\
<name>yarn.scheduler.minimum-allocation-mb</name>\n\
<value>2048</value>\n\
<discription>单个任务可申请最少内存,默认1024MB</discription>\n\
</property>\n\
<property>\n\
<name>yarn.scheduler.maximum-allocation-mb</name>\n\
<value>8192</value>\n\
<discription>单个任务可申请最大内存,默认8192MB</discription>\n\
</property>' /opt/hadoop-3.3.6/etc/hadoop/yarn-site.xml
#这段在配置yarn时已同时配置,并不是到了Hive才依赖这个mapred-site.xml
#mapred-site.xml
RUN sed -i '/<\/configuration>/i\ <property>\n\
<name>yarn.app.mapreduce.am.env</name>\n\
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>\n\
</property>\n\
<property>\n\
<name>mapreduce.map.env</name>\n\
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>\n\
</property>\n\
<property>\n\
<name>mapreduce.reduce.env</name>\n\
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.6</value>\n\
</property>' /opt/hadoop-3.3.6/etc/hadoop/mapred-site.xml
#同上由于hadoop与hive都依赖slf4j绑定文件,因此同时安装会有slf4多重绑定问题,我们需要删除其中一个
RUN rm /opt/apache-hive-4.0.1-bin/lib/log4j-slf4j-impl-2.18.0.jarHive 使用 MySQL 作为其元数据存储数据库,而该 JAR 包是 MySQL 官方提供的 JDBC 驱动程序,用于 Hive 与 MySQL 之间的通信,在配置mysql前放入也没有关系,不对mysql的配置和路径有依赖
RUN cp /install/mysql-connector-java-8.0.18.jar /opt/apache-hive-4.0.1-bin/lib10-2.MySQL
在现在(2025-07-18)这个时间段安装的mysql中,/etc中有了my.cnf,故跟随原教程继续安装
值得注意的是,mysql的配置文件看似有许多,如my.cnf,mysqld.cnf等等,其中遵循一个关系,由代码
mysql --help | grep -A1 "Default options"查询,所得结果类似
Default options are read from the following files in the given order:
/etc/my.cnf /etc/mysql/my.cnf ~/.my.cnf该返回是一个倒序优先级序列,靠后的配置会覆盖前面的配置,可以看到有/etc/mysql/my。cnf,至于最后的~/.my.cnf是当前用户的配置文件,如果没有配置则参考靠前的两个,他们是全局配置文件
my.cnf
#my.cnf
RUN echo "[mysqld]">> /etc/mysql/my.cnf && \
echo "pid-file = /var/run/mysqld/mysqld.pid" >> /etc/mysql/my.cnf && \
echo "socket = /var/run/mysqld/mysqld.sock" >> /etc/mysql/my.cnf && \
echo "port = 3306" >> /etc/mysql/my.cnf && \
echo "datadir = /var/lib/mysql" >> /etc/mysql/my.cnf && \
echo "bind-address = 0.0.0.0" >> /etc/mysql/my.cnf && \
echo "mysqlx-bind-address = 0.0.0.0" >> /etc/mysql/my.cnf && \
echo "" >> /etc/mysql/my.cnf && \
echo "[client]" >> /etc/mysql/my.cnf && \
echo "port=3306" >> /etc/mysql/my.cnf && \
echo "socket = /var/run/mysqld/mysqld.sock" >> /etc/mysql/my.cnf
对于[mysqld]行,这是mysql配置的语法,不写会报错
对于原教程中的skip-grant-tables设置,在该版本mysql中配置skip-grant-tables会导致mysql拒绝监听网络端口,因而无法从3306访问,类似于skip_networking的设置,只允许本地的 Unix 套接字连接
mysql的配置并没有完全完成,接下来的部分需要到entrypoint脚本中继续,其中内容比较重要,也许在dockerfile中配置也可,但我并未尝试
11-Miniconda与 Jupyter
因为复杂的依赖冲突,使用miniconda管理python体系
Miniconda
#安装Miniconda3
RUN bash /install/Miniconda3-latest-Linux-x86_64.sh -b -p /opt/miniconda3 && \
ln -sf /opt/miniconda3/bin/python /usr/bin/python && \
/opt/miniconda3/bin/conda tos accept --channel https://repo.anaconda.com/pkgs/main && \
/opt/miniconda3/bin/conda tos accept --channel https://repo.anaconda.com/pkgs/rJupyter
#创建 py38 环境
RUN /opt/miniconda3/bin/conda create -n py38 python=3.8 -y
#安装jupyter等
RUN /opt/miniconda3/envs/py38/bin/pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --prefer-binary \
apache-flink==1.13.0 pyalink==1.6.2.post0 \
jupyterlab==3.6.7 notebook==6.5.7 ipykernel==6.27.1
RUN /opt/miniconda3/envs/py38/bin/pip install -i https://pypi.tuna.tsinghua.edu.cn/simple \
--prefer-binary -U typing_extensions
RUN /opt/miniconda3/envs/py38/bin/python -m ipykernel install \
--name py38 \
--display-name "Python 3.8" \
--prefix=/opt/miniconda3/envs/py38由于需要安装pyalink,能被pip拉下来的pyalink强制拉取专用的apache-flink 1.13,而flink1.13又锁jupyter-client < 7、 ipykernl < 6等版本,如果直接拉取jupyter则会造成版本冲突,pip会无限回溯,所以这里直接写死了安装的版本
同时这里不能一起安装pyspark3.2.0,因为apache-flink 1.13.3 和 pyalink 1.6.2.post0 都要求py4j==0.10.8.1,而 pyspark 3.2.0 要求 py4j==0.10.9.2,三者无法共存,需要构建完镜像后进入jupyter使用pip单独安装,虽然运行测试时没问题但是冲突依旧存在
#Jupyter启动命令
jupyter-notebook --ip=0.0.0.0 --port=8888 --no-browser --allow-root --NotebookApp.token='' --NotebookApp.password=''12-SSH
#配置SSH
RUN ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 0600 ~/.ssh/authorized_keys由于优化了构建阶段,请不要在build阶段编写该代码,在后文优化大小中会解释
生成SSH密钥并配置免密登录
对于hadoop namdenode等组件,SSH是必要服务,不同节点间需要通过SSH 22端口互相通信
对于命令的解释:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa功能:生成 RSA 密钥对(私钥 + 公钥)
-t rsa:指定密钥类型为 RSA
-P '':设置空密码(无需输入密码即可使用密钥)
-f ~/.ssh/id_rsa:将私钥保存到 ~/.ssh/id_rsa,公钥默认保存为 ~/.ssh/id_rsa.pub
效果:
生成两个文件(如下)
~/.ssh/id_rsa(私钥,需保密)
~/.ssh/id_rsa.pub(公钥,可分发)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
功能:将公钥追加到 authorized_keys 文件中。
authorized_keys 是 SSH 服务认可的免密登录公钥列表。
>> 表示追加(不覆盖原有内容)
效果:
当前用户可以通过 SSH 密钥免密登录本机(即 localhost)
chmod 0600 ~/.ssh/authorized_keys功能:设置 authorized_keys 文件的权限为 0600
0600 表示仅允许所有者读写(-rw-------)
SSH 服务对文件权限敏感,权限过宽(如 0644)会导致免密登录失效
13-最终配置
#添加启动脚本
COPY entrypoint.sh /
RUN chmod +x /entrypoint.sh
# 设置工作目录
WORKDIR /root
# 定义默认命令
ENTRYPOINT ["/entrypoint.sh"]引入启动脚本 entrypoint.sh 让后台程序自动化启动(如SSH,Hadoop,zookeeper)
14-优化镜像大小
对于上面所给出的代码,组合到一起形成dockefile能够完成基本工作,但是体积(8.7G)相对原本的压缩包(4.2G)来讲还是有点多了,需要引入多阶段构建来优化最后的大小
FROM ubuntu:22.04 AS builder
# 安装必要的工具和依赖
RUN apt-get update && apt-get install -y \
mysql-server && \
mkdir -p /opt && \
mkdir -p /install
# 设置环境变量
# 基础环境变量
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64\
HADOOP_HOME=/opt/hadoop-3.3.6 \
HIVE_HOME=/opt/apache-hive-4.0.1-bin \
FLUME_HOME=/opt/apache-flume-1.11.0-bin
# 其他组件
ENV JRE_HOME=$JAVA_HOME \
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop \
HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" \
HADOOP_PREFIX=$HADOOP_HOME \
ZOOKEEPER_HOME=/opt/apache-zookeeper-3.8.4-bin \
SCALA_HOME=/opt/scala-2.12.0 \
SPARK_HOME=/opt/spark-3.5.6-bin-hadoop3 \
HBASE_HOME=/opt/hbase-2.5.11 \
HIVE_CONF_DIR=$HIVE_HOME/conf \
KAFKA_HOME=/opt/kafka_2.12-3.7.2 \
FLINK_HOME=/opt/flink-1.17.2 \
FLUME_CONF_DIR=$FLUME_HOME/conf
# 统一 PATH 配置
ENV PATH=$PATH:\
$JAVA_HOME/bin:\
$HADOOP_HOME/bin:\
$HADOOP_HOME/sbin:\
$ZOOKEEPER_HOME/bin:\
$SCALA_HOME/bin:\
$SPARK_HOME/bin:\
$SPARK_HOME/sbin:\
$HBASE_HOME/bin:\
$HIVE_HOME/bin:\
$KAFKA_HOME/bin:\
$FLINK_HOME/bin:\
$FLUME_HOME/bin上面是一部分优化后的代码,虽然可以不用在该阶段设置环境变量,但是以防后续设置时用到带环境变量的路径,可以提前设置方便使用。对于ENV命令,可以看到在基础环境变量中有三个HOME环境变量,这是因为后面用到了由该环境变量组成的新环境变量,而在同一个ENV中定义的环境变量不能互相调用,需要被提取出来
这段代码在 FROM行 后加了一个 AS builder,这是多阶段构建的标志性语法,类似于一个临时镜像。builder可以被任意重命名,只需要在后面的复制阶段从对应名称的镜像中复制即可
很明显的一点,我删除了很多在构建阶段并没有用的工具,这将极大的优化构建阶段的时间,构建阶段与后面的编辑阶段直接绑定,而最终镜像是平行于构建阶段同时生成的,并行构建十分高效(即使mysql依旧是整个安装过程中唯一没有被离线化的安装包且占用了最长的时间)
每多一个RUN,COPY命令都会有一层历史层留在镜像中,所以这个操作减少了命令的同时保持了可读性。即使构建阶段会被完全抛弃,该优化也能作为基本命令用在前文的dockerfile中
在上述代码之后,加入前文中从
#配置Hadoop#开始
到#配置MySQL#的所有配置代码
全部复制即可
接下来是最终镜像
FROM ubuntu:22.04
RUN echo "Acquire::https::Verify-Peer \"false\";" >> /etc/apt/apt.conf.d/99verify-peer.conf && \
echo "Acquire::https::Verify-Host \"false\";" >> /etc/apt/apt.conf.d/99verify-host.conf
# 更换为阿里云源
RUN sed -i 's|http://.*ubuntu.com|https://mirrors.aliyun.com|g' /etc/apt/sources.list
# 安装最小必要的运行时依赖
RUN apt-get update && apt-get install -y \
openjdk-8-jdk \
wget \
curl \
net-tools \
ssh \
gcc \
python2 \
vim \
mysql-server && \
rm -rf /var/lib/apt/lists/*
# 从构建阶段复制已安装和配置的软件
COPY --from=builder /opt /opt
COPY --from=builder /etc/mysql/my.cnf /etc/mysql/my.cnf
# 设置环境变量
# 基础环境变量
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 \
HADOOP_HOME=/opt/hadoop \
HBASE_HOME=/opt/hbase \
HIVE_HOME=/opt/hive \
KAFKA_HOME=/opt/kafka \
FLINK_HOME=/opt/flink \
SCALA_HOME=/opt/scala \
SPARK_HOME=/opt/spark \
ZOOKEEPER_HOME=/opt/zookeeper \
JUPYTER_HOME=/opt/miniconda3/envs/jup \
CONDA_HOME=/opt/miniconda3 \
FLUME_HOME=/opt/flume
# 其他组件
ENV JRE_HOME=$JAVA_HOME \
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop \
HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" \
SPARK_DIST_CLASSPATH=$HBASE_HOME/lib/* \
HBASE_CONF_DIR=$HBASE_HOME/conf \
HIVE_CONF_DIR=$HIVE_HOME/conf \
FLUME_CONF_DIR=$FLUME_HOME/conf \
PYSPARK_PYTHON=/opt/miniconda3/envs/py38/bin/python
# 统一 PATH 配置
ENV PATH=$PATH:\
$CONDA_HOME/bin:\
$JAVA_HOME/bin:\
$HADOOP_HOME/bin:\
$HADOOP_HOME/sbin:\
$ZOOKEEPER_HOME/bin:\
$SCALA_HOME/bin:\
$SPARK_HOME/bin:\
$SPARK_HOME/sbin:\
$HBASE_HOME/bin:\
$HIVE_HOME/bin:\
$KAFKA_HOME/bin:\
$FLINK_HOME/bin:\
$FLUME_HOME/bin:\
$JUPYTER_HOME/bin
# 配置SSH
RUN ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 0600 ~/.ssh/authorized_keys
#添加启动脚本
COPY entrypoint.sh /
RUN chmod +x /entrypoint.sh
# 设置工作目录
WORKDIR /root
# 定义默认命令
ENTRYPOINT ["/entrypoint.sh"]其中最重要的就是:
COPY --from=builder /opt /opt
COPY --from=builder /etc/mysql/my.cnf /etc/mysql/my.cnf两行命令,我们将前文那么多的配置代码转化为了两行COPY,极大的减少了历史层数
--from=* 与前文的AS builder相对应,如果有其他阶段也可以通过修改名称来复制文件
四、entrypoint.sh配置
1.entrypoint.sh概念
entrypoint.sh作为全容器唯一的启动脚本,担任自动化服务的功能,但在将他人配置完成的docker镜像作为模板重新配置镜像时,如果已经存在entrypoint.sh脚本,再在自己的镜像中配置脚本可能会导致原本的脚本失效,因此需要在更改原脚本与将自己的脚本实现原脚本功能中二选一
如前文所述,如果在dockerfile中执行ENTRYPOINT命令定义启动脚本,则docker容器会在脚本执行完毕后关闭,现象为点击启动按钮后无变化,容器无法启动,这时就需要:
tail -f /dev/null指令来维持容器运行,命令解释如下:
tail -f
tail:默认输出文件的末尾内容(查看日志的常用命令)
-f(follow):持续跟踪文件变化,实时输出新增内容(常用于监控日志文件)
/dev/null
Linux 的特殊设备文件,所有写入它的内容会被丢弃
读取 /dev/null 会立即返回 EOF(文件结束符),不会输出任何内容
tail会永远尝试读取/dev/null,而/dev/null永远不会产生新的数据,因此命令会永远挂起,但不占用cpu资源,docker容器也能持续运行
entrypoint.sh脚本有一个极为严格的检查,首行必须为:
#!/bin/bash无论在首行写什么都不行,即使是被注释的命令也会导致enrtypoint.sh无法执行
2.entrypoint.sh示例
日志函数 log()
#!/bin/bash
# 定义日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1"
}
获取时间,并将第一个获取的参数接在其后方,作为输出返回,方便查看报错
服务函数 start_service()
# 检查并启动服务函数
start_service() {
local service_name=$1
local start_command=$2
local max_retries=3
local retry_delay=5
log "Starting ${service_name}..."
for ((i=1; i<=$max_retries; i++)); do
eval "$start_command"
if [ $? -eq 0 ]; then
log "${service_name} started successfully."
return 0
else
log "Attempt ${i} failed to start ${service_name}. Retrying in ${retry_delay} seconds..."
sleep $retry_delay
fi
done
log "Failed to start ${service_name} after ${max_retries} attempts."
return 1
}接受第一个参数为service_name,第二个参数为start_command(具体指令 start / stop 等)
循环max_retries次,通过eval执行字符串形式的命令,如果启动失败则等待retry_delay秒
如果有执行失败则报错并return 1
主函数 main()
# 主执行流程
main() {
# 启动SSH服务
start_service "SSH" "service ssh start" || exit 1
# 格式化HDFS并启动Hadoop
if [ ! -f /tmp/hadoop-formatted ]; then
log "Formatting HDFS..."
hdfs namenode -format && touch /tmp/hadoop-formatted
fi
start_service "Hadoop" "start-all.sh" || exit 1
# 启动Zookeeper
start_service "Zookeeper" "zkServer.sh stop" || exit 1
sleep 2
zkServer.sh start || exit 1
# 启动Spark
start_service "Spark" "/opt/spark/sbin/start-all.sh" || exit 1
# 预上传Spark依赖
hdfs dfs -mkdir -p /user/spark/directory
hdfs dfs -put /opt/spark/jars/* /user/spark/directory
# 启动HBase
if ! pgrep -f "hbase.master.HMaster"; then
start_service "HBase" "/opt/hbase/bin/start-hbase.sh" || exit 1
fi
start_service "thrift" "/opt/hbase/bin/hbase-daemon.sh start thrift" || exit 1
# 启动Flink
start_service "Flink" "/opt/flink/bin/start-cluster.sh" || exit 1
# 启动Phoenix Query Server
start_service "Phoenix Query Server" "python2 /opt/phoenix-queryserver/bin/queryserver.py start > /dev/null 2>&1 &" || exit 1
# 启动Kafka
start_service "Kafka" "nohup /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties > /var/log/kafka-server.log 2>&1 &" || exit 1
# 配置MySQL并初始化Hive元数据
start_service "MySQL" "service mysql start" || exit 1
log "Configuring MySQL..."
mysql -u root -proot -e "ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root';"
mysql -u root -proot -e "CREATE USER IF NOT EXISTS 'root'@'%' IDENTIFIED BY 'root';"
mysql -u root -proot -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;"
mysql -u root -proot -e "FLUSH PRIVILEGES;"
if [ ! -f /tmp/metastore_initialized ]; then
echo "Initializing Hive metastore database..."
schematool -dbType mysql -initSchema \
-verbose
touch /tmp/metastore_initialized
echo "Hive metastore initialized"
fi
# 配置hdfs
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod -R 777 /user/hive/warehouse
hadoop fs -mkdir -p /tmp/hive/
hadoop fs -chmod -R 777 /tmp/hive
# 启动Hive
start_service "HiveMetastore" "nohup hive --service metastore > hiveserver2.log 2>&1 &" || exit 1
start_service "Hive" "hive --service hiveserver2 > hiveserver2.log 2>&1 &" || exit 1
# 启动Jupyter Notebook
start_service "Jupyter" \
"nohup jupyter-notebook \
--ip=0.0.0.0 --port=8888 --no-browser --allow-root \
--NotebookApp.token='' --NotebookApp.password='' \
> /var/log/jupyter.log 2>&1 &" || exit 1
log "All services started successfully!"
# 保持容器运行
tail -f /dev/null
}
# 执行主函数
main对于hadoop启动部分,检查/tmp/hadoop-formatted是否存在,如果不存在则说明是首次启动,需要格式化hdfs,由
hdfs namenode -format格式化hdfs,如果格式化成功,由
touch /tmp/hadoop-formatted创建文件hadoop-formatted表示已经格式化成功
对于mysql部分,前文提到mysql未配置完成,在这继续配置,对于原教程的
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';命令,在该版本中执行并没有效果,需改为代码所示:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root';大意为为root用户添加从localhost连接的权限,对于bash命令
mysql -u root -proot -e原本是无密钥登录,但是在第二次启动时因为设置了密钥为root所以需要通过密钥root登录
暂不清楚这样改动会对第一次启动有何影响
对于命令
mysql -u root -proot -e "CREATE USER IF NOT EXISTS 'root'@'%' IDENTIFIED BY 'root';"
mysql -u root -proot -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;"
mysql -u root -proot -e "FLUSH PRIVILEGES;"加入系列命令是因为如果需要通过localhost以外的地方访问,需要给予权限,而MySQL8.0以后不再允许GRANT...IDENTIFIED BY语法,需要先创建/修改用户再授权
对于命令
# 启动Zookeeper
start_service "Zookeeper" "zkServer.sh stop" || exit 1
sleep 2
zkServer.sh start || exit 1
# 启动HBase
if ! pgrep -f "hbase.master.HMaster"; then
start_service "HBase" "/opt/hbase-2.5.11/bin/start-hbase.sh" || exit 1
fi
start_service "thrift" "/opt/hbase-2.5.11/bin/hbase-daemon.sh start thrift" || exit 1
这两个命令不同于其他直接启动的命令,一个先关闭再启动,一个做了检查判断再启动,因为这两个软件在容器关闭后,莫名其妙的留下进程,原因不明,导致后续启动失败,故添加上述代码
对于命令
if [ ! -f /tmp/metastore_initialized ]; then
echo "Initializing Hive metastore database..."
schematool -dbType mysql -initSchema \
-verbose
touch /tmp/metastore_initialized
echo "Hive metastore initialized"
fi该段实现了Hive初始化后不再初始化的需求,具体方法为生成一个标志物空文件,如果存在说明已经初始化,反之则初始化hive并生成文件
对于命令
start_service "HiveMetastore" "nohup hive --service metastore > hiveserver2.log 2>&1 &" || exit 1
start_service "Hive" "hive --service hiveserver2 > hiveserver2.log 2>&1 &" || exit 1在后台启动了hive的两个进程,我在实践中的需求为:调试所有程序,同时需要在终端中操作。故作为后台启动,我能够通过脚本判断功能是否完全,如果需要拉回前台,关闭进程再重启即可
对于命令
start_service "Jupyter" \
"nohup jupyter-notebook \
--ip=0.0.0.0 --port=8888 --no-browser --allow-root \
--ServerApp.token='' --ServerApp.password='' \
> /var/log/jupyter.log 2>&1 &" || exit 1无密码启动Jupyter,如果宿主机安装了Jupyter,前文中提到要删除安装Jupyter的代码,这段启动Jupyter的代码也需要删除
五、docker-compose配置
1.docker-compose概念
在单节点中docker-compose的配置相对简单,且用处不大,这里结合docker命令来解释
先给出docker命令,他是如何创建docker容器与镜像的
#在Dockerfile同级目录下打开cmd
#通过目录中的Dockerfile创建镜像
#镜像名为bigdata-docker,版本为v1.0
docker build -t bigdata-docker:v1.0 .
#通过docker镜像bigdata-docker,版本为v1.0,在前台创建容器并启动
#容器名为bigdata-container
#映射端口 -p *:*
docker run -it --name bigdata-container -p 2181:2181 -p 16010:16010 -p 16020:16020 -p 16030:16030 -p 8080:8080 -p 8085:8085 -p 9090:9090 -p 9095:9095 -p 16000:16000 -p 2222:22 -p 8040:8040 -p 8042:8042 -p 9870:9870 -p 9868:9868 -p 60010:60010 -p 2888:2888 -p 3888:3888 -p 8083:8083 bigdata-docker:v1.0
#假设返回容器id为:e14514
#连接docker容器
docker exec -it e14 /bin/bash对于镜像的创建:
docker build -t bigdata-docker:v1.0 .- docker build:创建镜像
- -t *:% :指定镜像名称 * 与版本 % ,无指定版本则默认设置为latest
- . :在本地目录中寻找 Dockerfile (D的大小写敏感,只能大写)并安装
对于容器的创建:
docker run -it --name bigdata-container -p 2181:2181 -p 16010:16010 -p 16020:16020 -p 16030:16030 -p 8080:8080 -p 8085:8085 -p 9090:9090 -p 9095:9095 -p 16000:16000 -p 2222:22 -p 8040:8040 -p 8042:8042 -p 9870:9870 -p 9868:9868 -p 60010:60010 -p 2888:2888 -p 3888:3888 -p 8083:8083 bigdata-docker:v1.0- docker run :创建容器
- -it :组合参数,i 保证能与容器输入交互,t 负责分配终端,保证能在cmd中进行终端交互
- -p *:* :将 [ 宿主机端口 ] 映射到 [ 容器端口 ],冒号前为宿主机,后为容器
- bigdata-docker:v1.0 :镜像名称与版本
对于连接容器:
docker exec -it e14 /bin/bash- docker exec :在正在运行的容器中执行额外命令(容器是可以不进去交互的)
- e14 :假设的容器id,也可以设置为容器名称
- /bin/bash :启动Bash Shell进行终端交互
/bin/bash参数其实是一个传入的命令,如同前文中指定命令的ENTRYPOINT与CMD一样,会被加在这两个命令的末尾,如:CMD [ " ps " ] / docker exec -it e14 -- -a ,-a会被拼接在ps之后,两段代码会组合为 " ps -a " ,从而列出正在运行的所有进程
2.docker-compose示例
现在给出dockercompose
services:
bigdata-container:
container_name: bigdata-container
build: .
image: bigdata-docker:v1.0
ports:
#Hadoop相关端口
- "9870:9870" # NameNode Web UI
- "9868:9868" # DataNode Web UI
- "8088:8088" # ResourceManager Web UI
- "8042:8042" # NodeManager Web UI
- "8085:8085" # MapReduce JobHistory Server Web UI
- "9000:9000" # NameNode RPC 端口
- "9864:9864" # DataNode data transfer
- "9866:9866" # DataNode IPC
- "8040:8040" # NodeManager localizer RPC 端口
- "2222:22" # SSH 端口
#Zookeeper相关端口
- "2181:2181" # Zookeeper 端口
#Spark相关端口
- "8080:8080" # Spark Master Web UI
- "8081:8081" # Spark Worker Web UI
- "8082:8082" # Spark Worker Web UI(第二实例)
- "7077:7077" # Spark Standalone Master
#Hbase相关端口
- "16010:16010" # HBase Master Web UI
- "16030:16030" # RegionServer Web UI
- "16000:16000" # HBase Master RPC 端口
- "16020:16020" # HBase RegionServer RPC 端口
- "8765:8765" # Phoenix QueryServer (thin-client)
#Flink相关端口
- "6123:6123" # Flink JobManager RPC
#Kafka相关端口
- "9092:9092" # Kafka Broker 端口
- "9095:9095" # Kafka Broker(第二实例或外部映射)
#MySQL相关端口
- "3307:3306" # MySQL Server(与宿主机端口不同)
#Hive相关端口
- "9083:9083" # Hive Metastore
- "8083:8083" # HiveServer2 Web UI
#Jupyter相关端口
- "8888:8888" # Jupyter Notebook配置解读如下:
- services:该代码下一个缩进的参数会被认为是一个镜像
- bigdata-*:镜像名称,该代码下一个缩进的参数会被认为是对该镜像的配置
- container_name:指定容器名称,不然docker会以自己的命名方式对容器进行重命名,适用于多节点情况下通过容器名来互相访问
- build:表示dockerfile的路径,类同docker build
- image:指定镜像名称,适用于该节点被依赖的情况下固定被调用时的名称,不指定的情况下docker会在镜像名前加上dockercompose目录的文件夹名
- ports:端口映射,类同docker run命令的 -p 参数
值得一提的是,docker compose和python一样遵循严格的缩进,一次缩进为两个空格,而对于port参数下的 " - ",他的前后都应该有一个空格,同时把三个字符视作一个配置,再进行缩进
对于从docker-compose安装docker镜像,在文章的开头已经给出命令,照做即可
对于命令 docker-compose 与命令 docker compose( - 号变为空格),前者为老版本命令,后者为新版本命令,对于该文章所构筑的小体量docker,使用体验差别不大
3.进阶知识
以上是对一个简单的docker compose的解读,接下来会以一个大数据多节点docker的部分
docker compose 为模板介绍docker compose的其他设置,仅作参考
version: '3.8'
networks:
bigdata-net:
driver: bridge
ipam:
config:
- subnet: 172.20.0.0/16
services:
base:
container_name: base
build: ./base
image: base
# ZooKeeper集群
zookeeper1:
container_name: zookeeper1
image: zookeeper1
build:
context: ./zookeeper
dockerfile: zookeeper.Dockerfile
environment:
MY_ID: 1
networks:
bigdata-net:
ipv4_address: 172.20.0.11
depends_on:
- base
ports:
- "2181:2181"
- "2888:2888"
- "3888:3888"
配置解读如下:
- network:docker网络,在同一网络下的docker容器可以互相通信(不依赖本地hadoop的hbase)
- context:指定安装路径,告诉Docker Dockerfile在哪
- dockerfile:指定docker file名称,适用于一个目录下有多个docker file的情况
- depends_on:该镜像依赖的镜像,在生成时会先等待依赖镜像生成完毕
- networks:指定接入哪个docker网络 并分配ip
六、测试脚本
ai生成了一份测试脚本,基本都是验证端口什么的,尤其是flume,我在专门测试phoenix的容器中开了flume的端口也能测试成功,仅作参考,如果后面写了一份新的基于操作的测试脚本我会再更新
import socket
import time
import traceback
from hdfs import InsecureClient
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import NoBrokersAvailable
from pyhive import hive
from phoenixdb import connect
import pymysql
import happybase
import requests
import warnings
# 忽略一些不重要的警告
warnings.filterwarnings("ignore")
class BigDataComponentTester:
def __init__(self, host='localhost', timeout=10):
self.host = host
self.timeout = timeout
self.hdfs_client = None
self.hive_conn = None
self.mysql_conn = None
self.phoenix_conn = None
self.hbase_conn = None
def test_port(self, port, service_name):
"""测试端口是否可用"""
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(self.timeout)
result = sock.connect_ex((self.host, port))
sock.close()
if result == 0:
print(f"✅ {service_name} 端口 {port} 连接成功")
return True
else:
print(f"❌ {service_name} 端口 {port} 连接失败")
return False
except Exception as e:
print(f"❌ 测试 {service_name} 端口时出错: {e}")
return False
def test_hadoop(self):
"""测试Hadoop HDFS"""
print("\n=== 测试Hadoop HDFS ===")
try:
self.hdfs_client = InsecureClient(f'http://{self.host}:9870', user='root', timeout=self.timeout)
contents = self.hdfs_client.list('/')
print(f"✅ HDFS 连接成功,根目录内容: {contents}")
return True
except Exception as e:
print(f"❌ HDFS 连接失败: {e}")
return False
def test_spark(self):
"""测试Spark"""
print("\n=== 测试Spark ===")
try:
response = requests.get(f'http://{self.host}:8081/api/v1/applications', timeout=self.timeout)
if response.status_code == 200:
print("✅ Spark 连接成功")
return True
else:
print(f"❌ Spark 连接失败,状态码: {response.status_code}")
return False
except Exception as e:
print(f"❌ Spark 连接失败: {e}")
return False
def test_hbase(self):
"""测试HBase"""
print("\n=== 测试HBase ===")
try:
self.hbase_conn = happybase.Connection(self.host, port=9090, timeout=self.timeout * 1000) # happybase使用毫秒
tables = self.hbase_conn.tables()
print(f"✅ HBase 连接成功,现有表: {tables}")
return True
except Exception as e:
print(f"❌ HBase 连接失败: {e}")
return False
def test_kafka(self):
"""测试Kafka"""
print("\n=== 测试Kafka ===")
test_topic = "test_topic_py"
try:
# 测试生产者
producer = KafkaProducer(
bootstrap_servers=f'{self.host}:9092',
request_timeout_ms=self.timeout * 10
)
future = producer.send(test_topic, b'test_message_py')
future.get(timeout=self.timeout)
# 测试消费者
consumer = KafkaConsumer(
test_topic,
bootstrap_servers=f'{self.host}:9092',
auto_offset_reset='earliest',
consumer_timeout_ms=self.timeout * 100
)
for msg in consumer:
if msg.value == b'test_message_py':
print("✅ Kafka 生产消费测试成功")
consumer.close()
return True
print("❌ Kafka 测试失败,未收到测试消息")
return False
except NoBrokersAvailable:
print("❌ Kafka 连接失败: 没有可用的broker")
return False
except Exception as e:
print(f"❌ Kafka 测试失败: {e}")
return False
finally:
try:
producer.close()
except:
pass
def test_flink(self):
"""测试Flink"""
print("\n=== 测试Flink ===")
try:
response = requests.get(f'http://{self.host}:8081/taskmanagers', timeout=self.timeout)
if response.status_code == 200:
print("✅ Flink 连接成功")
return True
else:
print(f"❌ Flink 连接失败,状态码: {response.status_code}")
return False
except Exception as e:
print(f"❌ Flink 连接失败: {e}")
return False
def test_zookeeper(self):
"""测试Zookeeper"""
print("\n=== 测试Zookeeper ===")
return self.test_port(2181, "Zookeeper")
def test_hive(self):
"""测试Hive"""
print("\n=== 测试Hive ===")
try:
self.hive_conn = hive.Connection(
host=self.host,
port=10000,
username='hive',
#timeout=self.timeout
)
cursor = self.hive_conn.cursor()
cursor.execute('SHOW DATABASES')
results = cursor.fetchall()
print(f"✅ Hive 连接成功,数据库列表: {results}")
return True
except Exception as e:
print(f"❌ Hive 连接失败: {e}")
return False
def test_phoenix(self):
"""测试Phoenix"""
print("\n=== 测试Phoenix ===")
try:
self.phoenix_conn = connect(
f'http://{self.host}:8765/',
autocommit=True,
)
cursor = self.phoenix_conn.cursor()
cursor.execute("SELECT CURRENT_DATE()")
results = cursor.fetchall()
print(f"✅ Phoenix 连接成功,查询结果: {results}")
return True
except Exception as e:
print(f"❌ Phoenix 连接失败: {e}")
traceback.print_exc()
return False
def test_flume(self):
"""测试Flume"""
print("\n=== 测试Flume ===")
# Flume通常没有直接的API接口,可以通过端口测试
return self.test_port(41414, "Flume")
def test_mysql(self):
"""测试MySQL"""
print("\n=== 测试MySQL ===")
try:
self.mysql_conn = pymysql.connect(
host="127.0.0.1",
user='root',
password='root',
database='mysql',
port=3307,
connect_timeout=self.timeout
)
cursor = self.mysql_conn.cursor()
cursor.execute("SHOW DATABASES")
results = cursor.fetchall()
print(f"✅ MySQL 连接成功,数据库列表: {results}")
return True
except Exception as e:
print(f"❌ MySQL 连接失败: {e}")
return False
def run_all_tests(self):
"""运行所有测试"""
tests = [
('Hadoop', self.test_hadoop),
('Spark', self.test_spark),
('HBase', self.test_hbase),
('Kafka', self.test_kafka),
('Flink', self.test_flink),
('Zookeeper', self.test_zookeeper),
('Hive', self.test_hive),
('Phoenix', self.test_phoenix),
('Flume', self.test_flume),
('MySQL', self.test_mysql)
]
results = {}
for name, test_func in tests:
start_time = time.time()
results[name] = test_func()
elapsed = time.time() - start_time
print(f"测试耗时: {elapsed:.2f}秒")
print("\n=== 测试结果汇总 ===")
success_count = 0
for name, result in results.items():
status = "✅ 成功" if result else "❌ 失败"
print(f"{name.ljust(10)}: {status}")
if result:
success_count += 1
total = len(tests)
print(f"\n测试完成: {success_count}/{total} 个组件测试成功")
return all(results.values())
if __name__ == "__main__":
import os
# 从环境变量获取主机地址,默认为localhost
host = os.getenv('BIGDATA_HOST', 'localhost')
timeout = int(os.getenv('TEST_TIMEOUT', '10'))
print(f"开始测试大数据组件,目标主机: {host},超时设置: {timeout}秒")
tester = BigDataComponentTester(host=host, timeout=timeout)
tester.run_all_tests()
照着需求安装可能会少依赖,这里给出部分
pip install hdfs kafka-python PyHive phoenixdb pymysql happybase requests
pip install cryptography
pip install thrift-sasl再给出一点调试过程中使用的命令
ps aux | grep java
#查看所有java进程,然后丢给ai
jps
#看起了多少进程,少了的就是没启动
netstat -lptn
#查端口,没监听就是没启动,监听本地可能设置错误
ifconfig
#查询IP地址
!{sys.executable} --version
#jupyter正在使用的python版本
conda init bash
exec bash
#进入bash
conda activate py38
#进入conda环境七、公开至局域网方法
一般来讲,docker的端口映射会默认映射到 localhost 127.0.0.1,即无法直接通过宿主机以外的设备访问。想要使得在同一网络下的其他设备也能访问到docker内的软件,可以通过映射到0.0.0.0并添加防火墙入站规则来做到
1.docker-compose
services:
bigdata-container:
container_name: bigdata-container
build: .
image: bigdata-docker:v1.0
ports:
#Hadoop相关端口
- "0.0.0.0:9870:9870" # NameNode Web UI
- "0.0.0.0:9868:9868" # DataNode Web UI
- "0.0.0.0:8088:8088" # ResourceManager Web UI
- "0.0.0.0:8042:8042" # NodeManager Web UI
- "0.0.0.0:8085:8085" # MapReduce JobHistory Server Web UI
- "0.0.0.0:9000:9000" # NameNode RPC 端口
- "0.0.0.0:9864:9864" # DataNode data transfer
- "0.0.0.0:9866:9866" # DataNode IPC
- "0.0.0.0:8040:8040" # NodeManager localizer RPC 端口
- "0.0.0.0:2222:22" # SSH 端口
#Zookeeper相关端口
- "0.0.0.0:2181:2181" # Zookeeper 端口
#Spark相关端口
- "0.0.0.0:8080:8080" # Spark Master Web UI
- "0.0.0.0:8081:8081" # Spark Worker Web UI
- "0.0.0.0:8082:8082" # Spark Worker Web UI(第二实例)
- "0.0.0.0:7077:7077" # Spark Standalone Master
#Hbase相关端口
- "0.0.0.0:16010:16010" # HBase Master Web UI
- "0.0.0.0:16030:16030" # RegionServer Web UI
- "0.0.0.0:16000:16000" # HBase Master RPC 端口
- "0.0.0.0:16020:16020" # HBase RegionServer RPC 端口
- "0.0.0.0:8765:8765" # Phoenix QueryServer (thin-client)
#Flink相关端口
- "0.0.0.0:6123:6123" # Flink JobManager RPC
#Kafka相关端口
- "0.0.0.0:9092:9092" # Kafka Broker 端口
- "0.0.0.0:9095:9095" # Kafka Broker(第二实例或外部映射)
#MySQL相关端口
- "0.0.0.0:3307:3306" # MySQL Server(与宿主机端口不同)
#Hive相关端口
- "0.0.0.0:9083:9083" # Hive Metastore
- "0.0.0.0:8083:8083" # HiveServer2 Web UI
#Jupyter相关端口
- "0.0.0.0:8888:8888" # Jupyter Notebook通过在映射的端口前增加0.0.0.0使其绑定到所有网络接口
2.防火墙入站规则
通过控制面板找到 系统和安全 里的 Windows Defender 防火墙,点击左侧 高级设置 ,选择入站规则 ,新建规则 BigData-Docker
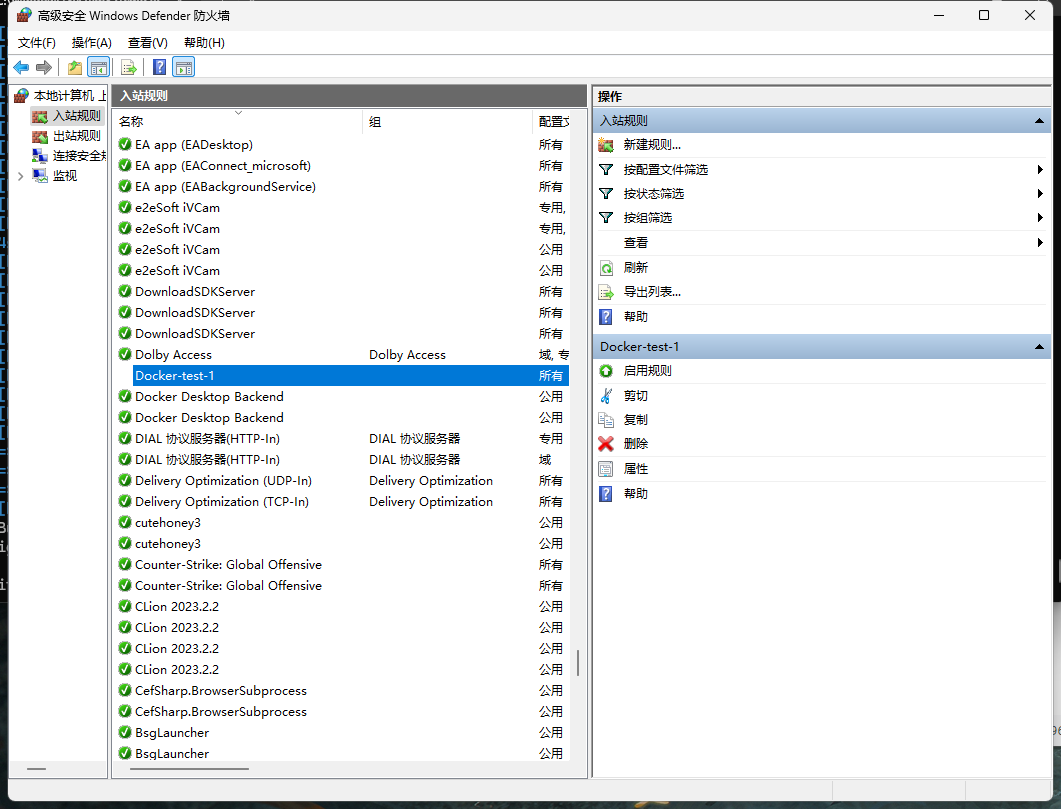
选择端口
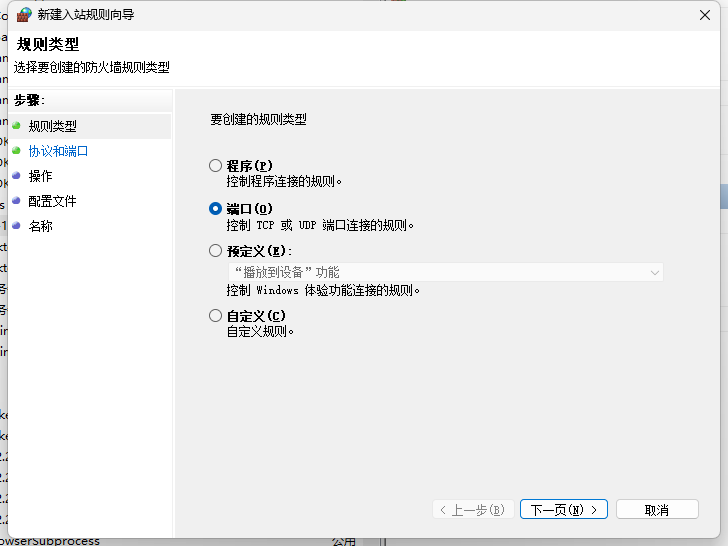
在特定本地端口中输入
2181, 2222, 2888, 3307, 3888, 7077, 8032, 8040, 8042, 8080, 8081, 8082, 8083, 8085, 8088, 8888, 9090, 9092, 9095, 8765, 9864, 9868, 9870, 10000, 16000, 16010, 16020, 16030, 41414, 60010 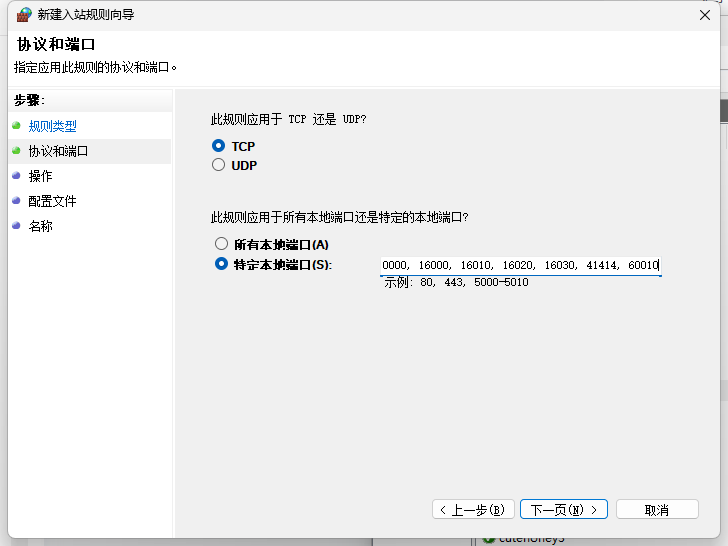
允许连接
全选
重命名,并在描述中写入刚刚的端口,方便以后有需要复制(可选)
完成即可
总结
以上是关于单节点大数据处理网络整合docker的详细配置演示,从0摸索大约80小时,趟过无数坑,如有错误请指正
在最后顺便谈一下在编写过程中ai的使用体验,dockerfile的编写基本离不开ai,重复性高且枯燥无味,里面各种各样的奇怪问题更是能对着ai问上十几个对话,在最后的脚本检验阶段就对着d和k两个ai问了三十个对话,但是硬骨头只有kafka,hive,queryserver,mysql这四个,原本在整体编写阶段d的使用体验要明显优于k的老模型,但是最后的测试阶段k的新模型解决了许多d有误区导致的问题,不过可惜有限额

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)