scrapydweb:实现 Scrapyd 集群管理,Scrapy 日志分析和可视化
(点击上方公众号,可快速关注)来源:my8100juejin.im/post/5bb5d43ce51d450e616040c8功能特性Scrapyd 集群管理支持通过分组...
(点击上方公众号,可快速关注)
来源:my8100
juejin.im/post/5bb5d43ce51d450e616040c8
功能特性
-
Scrapyd 集群管理
-
支持通过分组和过滤选中特定服务器节点
-
一次点击,批量执行
-
-
Scrapy 日志分析
-
统计信息展示
-
爬虫进度可视化
-
关键日志分类
-
-
支持所有 Scrapyd API
-
Deploy project, Run Spider, Stop job
-
List projects/versions/spiders/running_jobs
-
Delete version/project
-
-
其他
-
web UI 支持 Basic Auth
-
支持访问启用 Basic Auth 保护的 Scrapyd 服务器
-
GitHub :my8100/scrapydweb
欢迎 Star 和提交 Issue
安装
通过 pip 安装:
pip install scrapydweb复制代码启动
通过命令行终端运行 "scrapydweb -h" 以查看帮助和选项. 第一次运行将在当前工作目录生成配置文件 "scrapydweb_settings.py",可用于自定义 Scrapyd 服务器列表等选项.
scrapydweb复制代码通过浏览器访问 http://127.0.0.1:5000
运行界面截图
-
集群管理
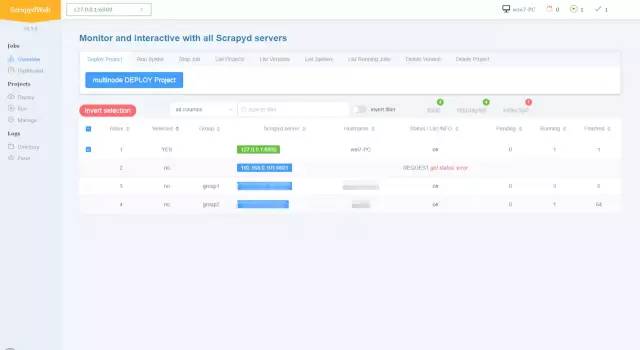
-
当前节点任务列表
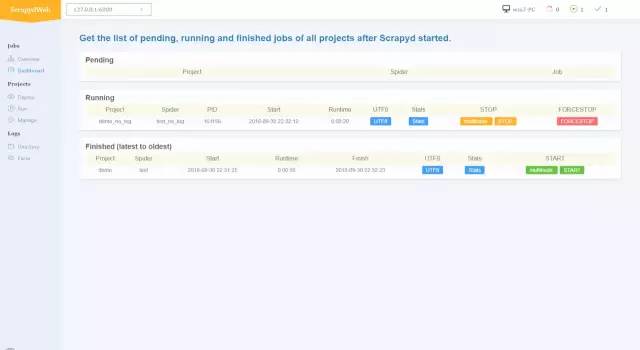
-
日志分析
-
统计信息输出
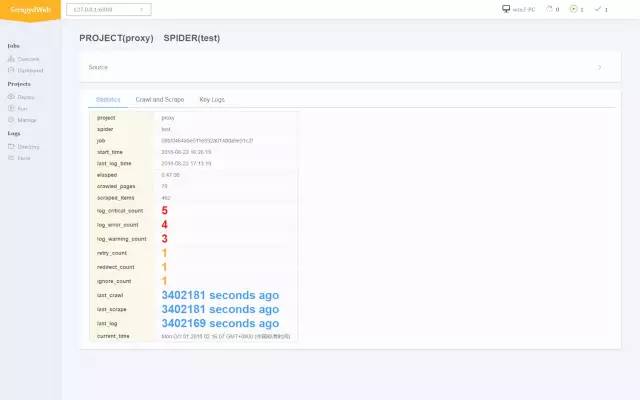
-
爬虫进度可视化
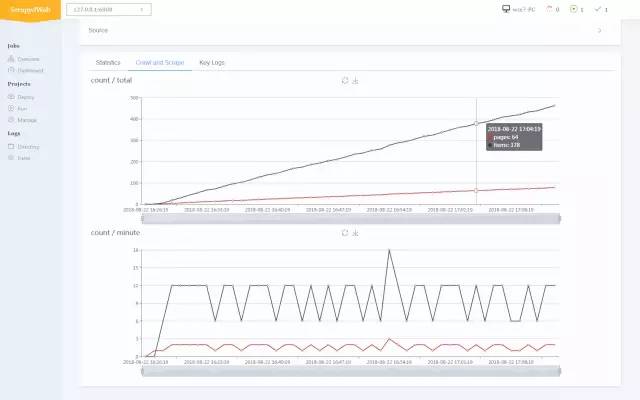
-
关键日志分类
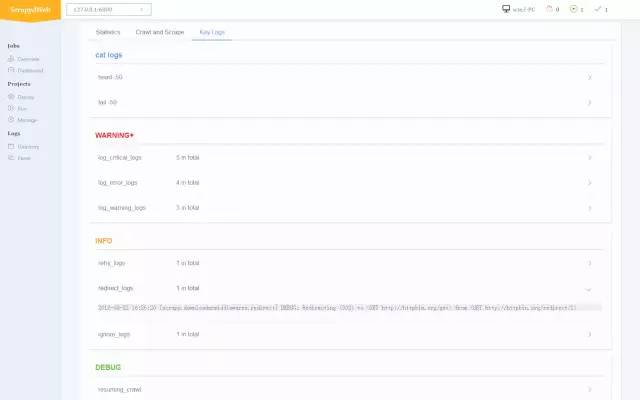
-
-
部署项目
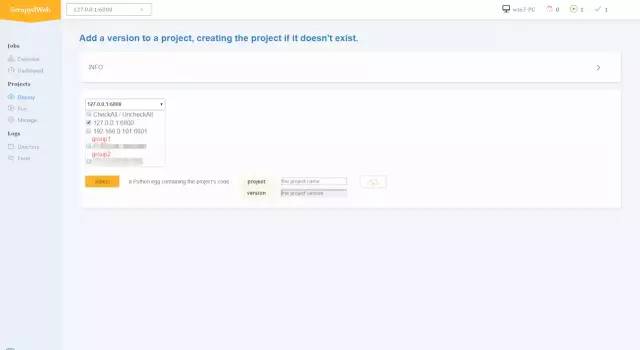
-
运行爬虫
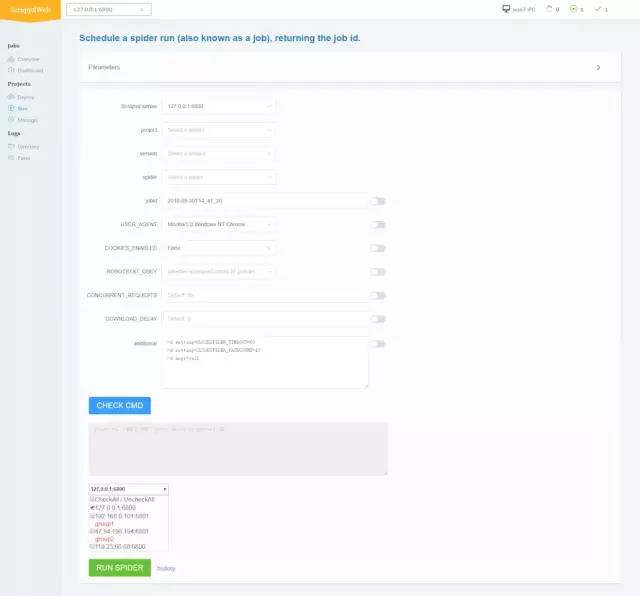
-
管理项目
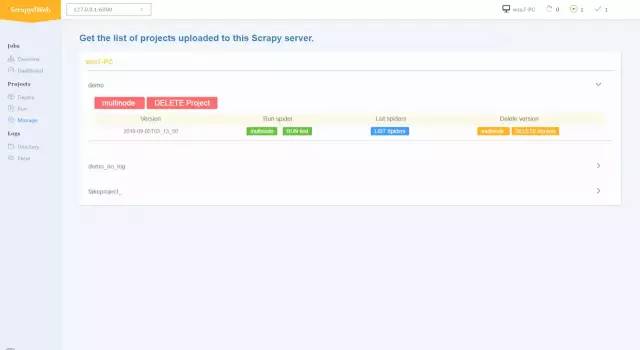
【关于投稿】
如果大家有原创好文投稿,请直接给公号发送留言。
① 留言格式:
【投稿】+《 文章标题》+ 文章链接
② 示例:
【投稿】《不要自称是程序员,我十多年的 IT 职场总结》:
http://blog.jobbole.com/94148/
③ 最后请附上您的个人简介哈~
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能



永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)