大数据之数仓金融项目总结
统计指标:最低借款金额,最高借款金额,申请次数,提供薪资报告次数,提供薪资报告最早时间,提供薪资报告资产最晚时间,提供信用报告次数,提供信用报告最早时间,提供信用报告最晚时间。统计指标:提款申请量,提款申请人数,提款通过量,提款通过人数,协议签订量,协议签订人数,申请提款金额,协议签订金额,实际提款金额。统计指标:还款合同量,还款人数,还款金额,预期本金,预期利息,预期服务费,预期天数,预期次数,
数据仓库介绍:对数据进行提取计算总结,然后进行下一阶段的使用。
技术选型:
技术选型考虑因素:数据量,业务需求,工具类的熟练程度,以及维护成本和总预算。
数据采集:flume,sqoop,datax
数据存储:mysql,hdfs
数据计算:hive
数据可视化:datagrip,finebi
任务调度:dolphinScheduler
项目需求:
1、采集业务数据,包括用户管理、风险管理、核心系统等;
2、数据仓库维度建模;
3、分析用户注册、授信申请、风险审核、放款、还款、逾期等核心业务活动,完成指标统计计算;
4、采用即查询工具,随时对数据指标进行分析;
5、对集群性能进行监控,发生任务处理异常及时警告;
6、元数据管理;
7、质量监控;
8、数据可视化;
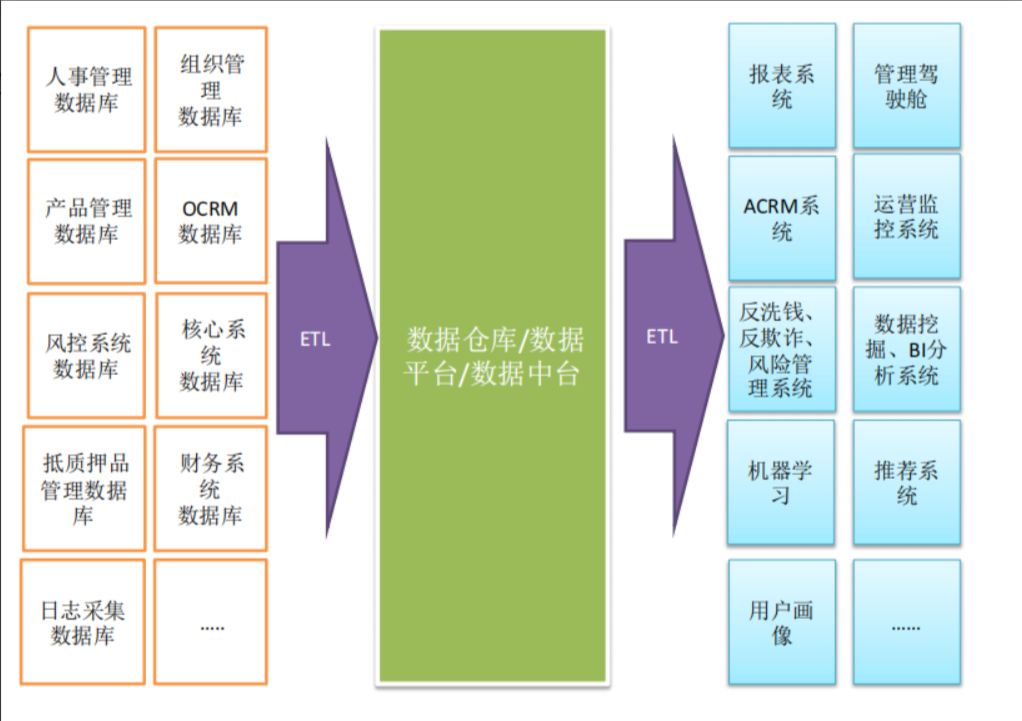
业务调研:
业务流程图: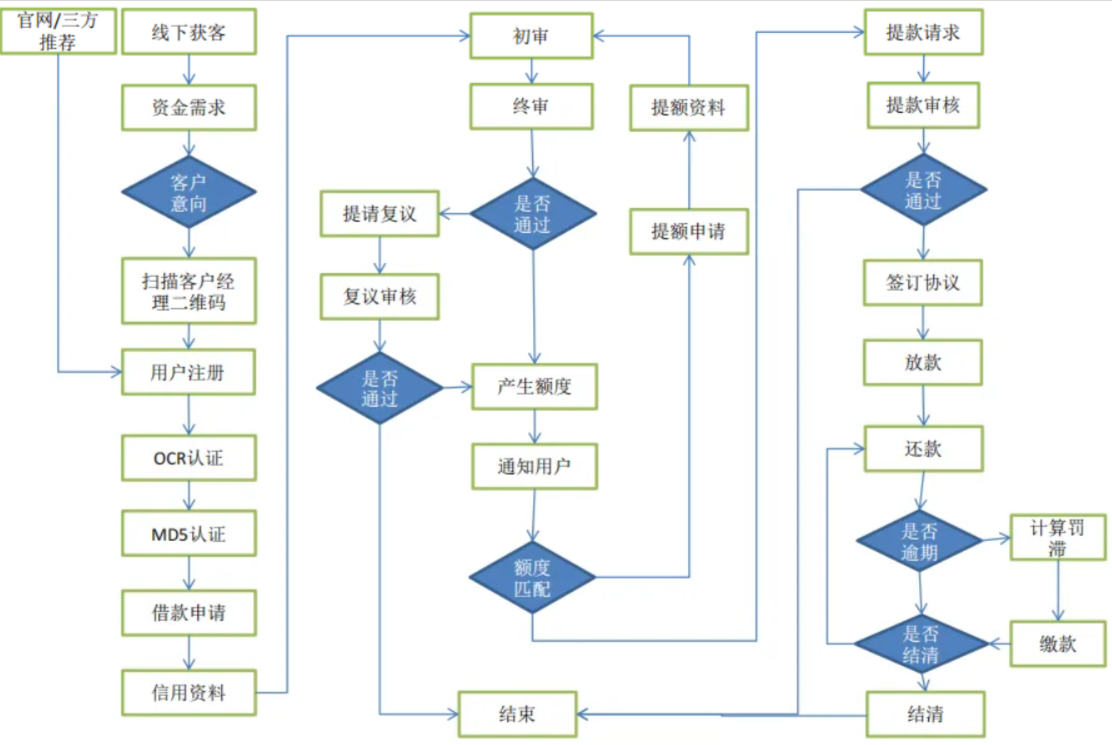
业务流程关键节点:
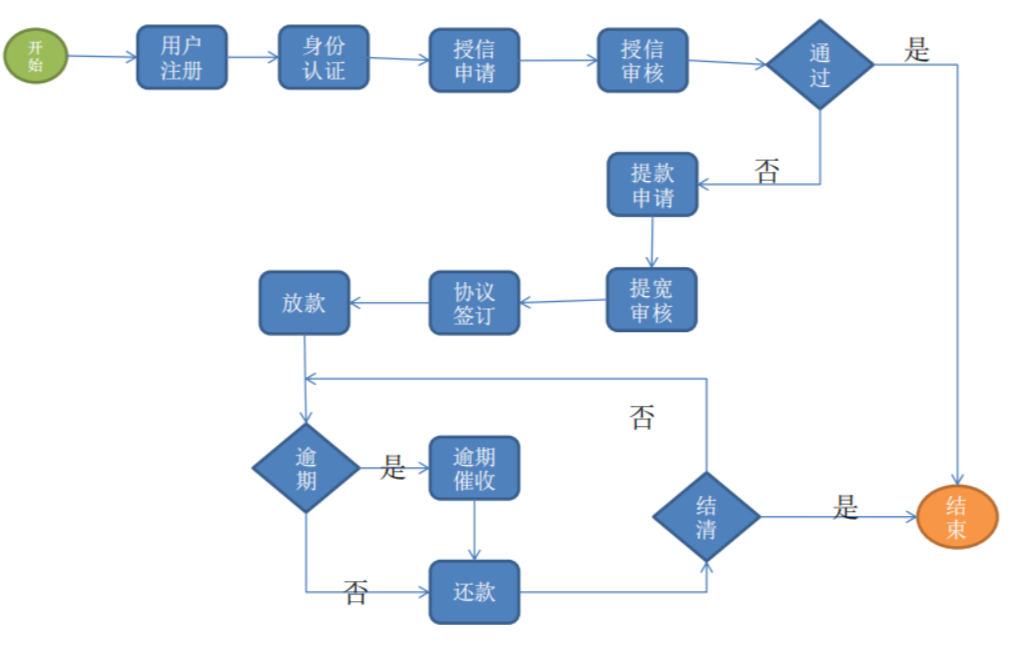
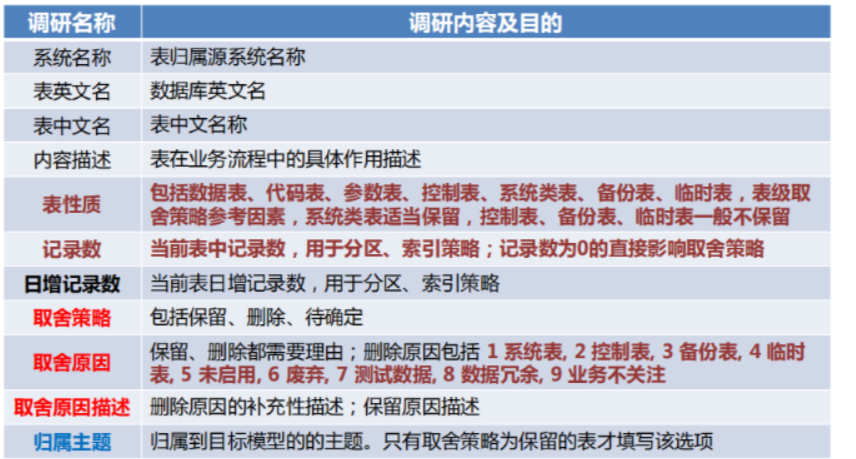
数据调研:
数据仓库架构:
数据仓库分层:
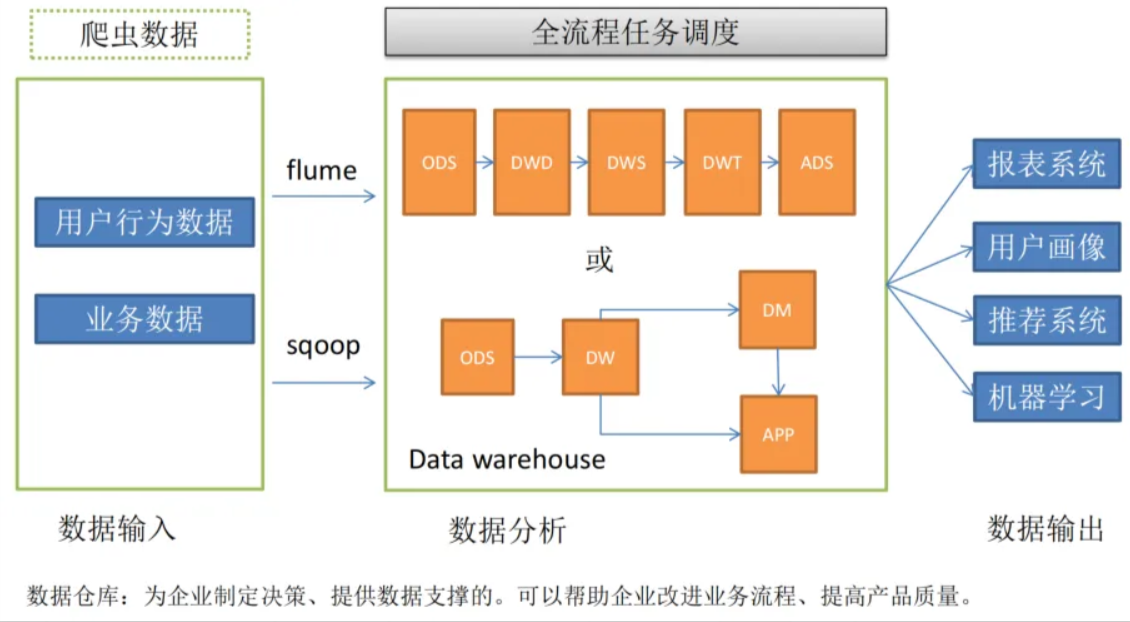
构建数据仓库的完整流程:
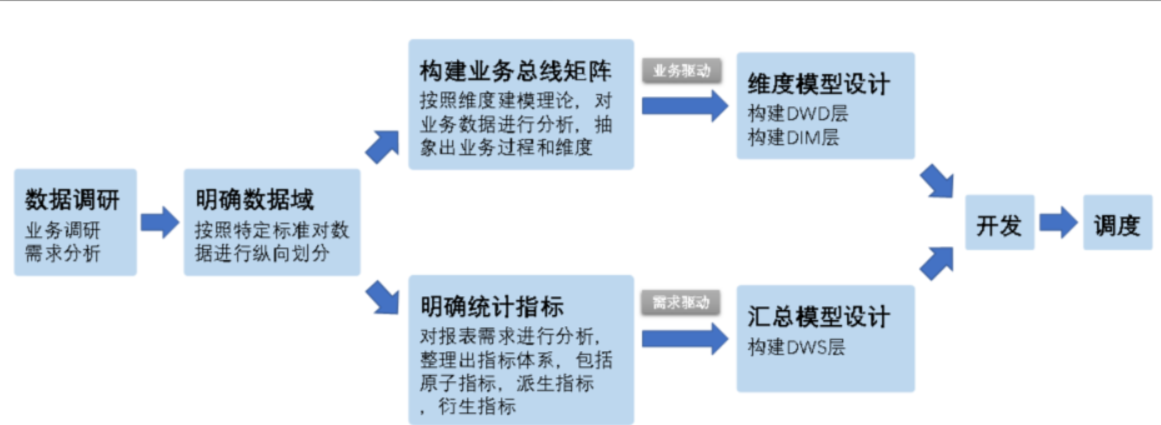
ODS层:贴源层(该层数据接近于原始数据,数据来源:业务库)
DWD层:数据明细层(数据来源于ODS,事实表作为数据仓库维度建模的核心)
DIM层:维度层
DWS层:数据汇总层
ADS层:数据应用层
数据开发命名规范:
ods:层级+源库库名+表名 例如ods_jrxd_user_det
dwd:dwd_fact_主题_table_name 例如dwd_fact_cus_regeste_detail
dim层:dim_table_name 例如dim_product
dws层:dws_fact_市集名_table_name 例如dws_fact_risk_cus_first_overdue
ads层:ads_fact_table_name
ods层数据开发
1、mysql上创建数据库,将源数据导入到mysql中
2、sqoop导入业务数据到ods层(选择sqoop的原因是,datax不能直接将mysql数据导入到hive,需要提前创建表,然后将数据导入表对应的hdfs上)
关于数仓数据抽取思考:
如果业务系统已经上线一段时间了,第一次加载数据需要考虑之前所有的流水(事实)数据,需要把之前业务系统的数据写入各个不同的时间分区,后续只需要做增量抽取即可
(1)在hive中创建一个数据仓库
(2)编写sqoop脚本,完成数据导入hive数仓
sqoop在进行数据抽取,即mysql导入hive,mysql中关于时间的数据类型是timestamp,hive的表是sqoop创建的,它的时间类型是string(created_at没有指定,所以是string)
数据仓库建模:
范式建模 维度建模(选取维度建模)
维度建模过程:
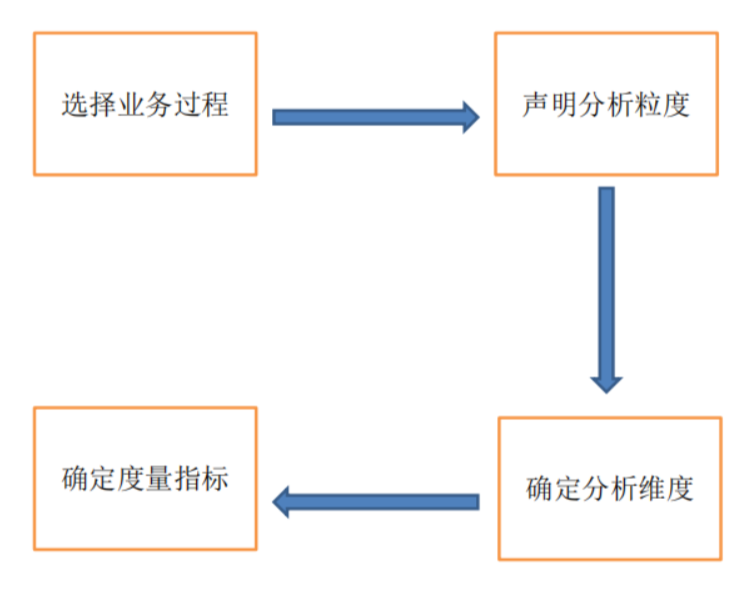
第一步 选取业务过程
即业务活动(一个业务过程对应一个事务型事实表,多个义务过程对应一张累计型快照事实表)
第二步 定义粒度
如何描述事实表的单行都表示什么,尽量选择最小颗粒度
第三步 确认维度
即业务人员将如何描述从业务过程得到数据?每个业务过程均需要一个日期维度
第四步 确认事实
即要对什么内容进行评测
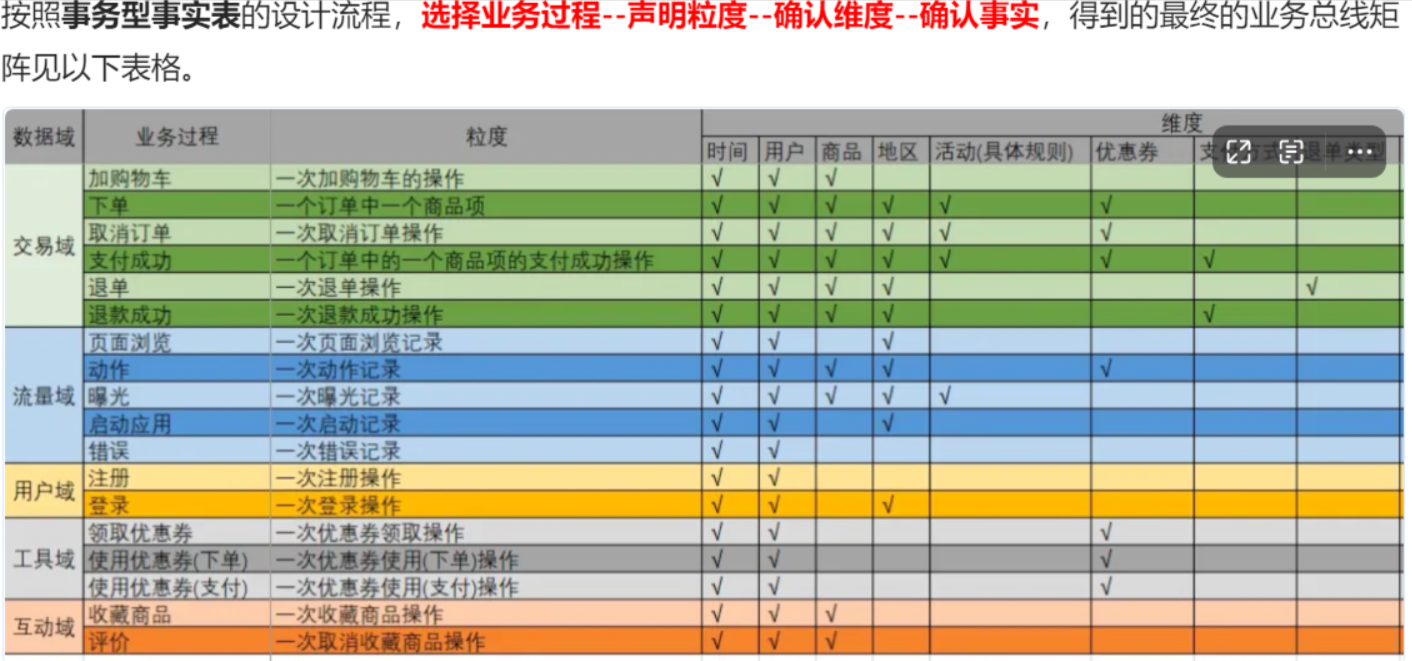
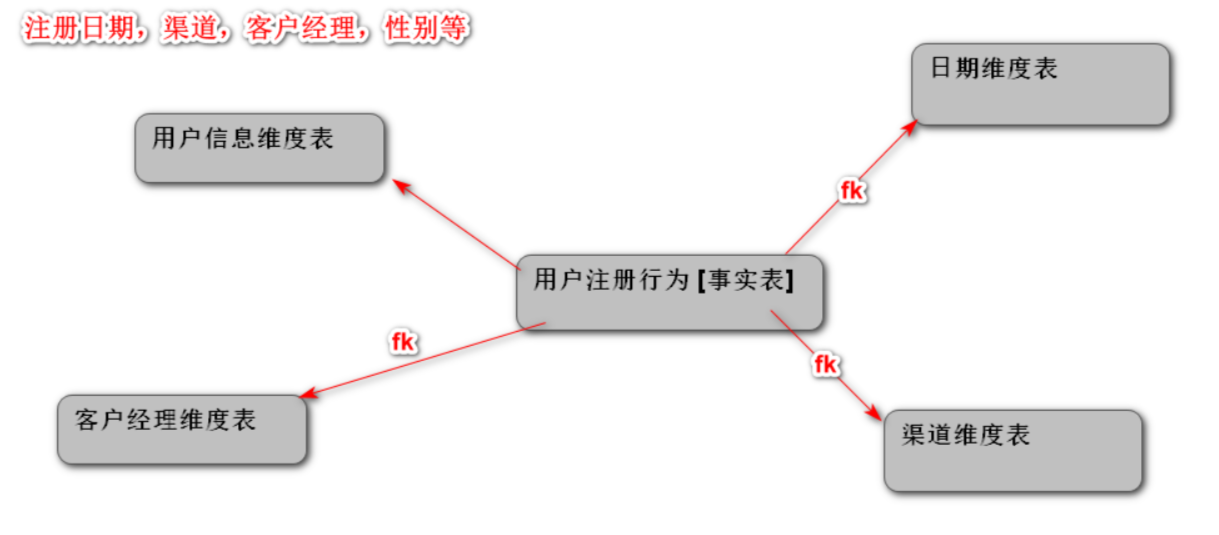
用户注册【用户主题域】
需求:统计客户的注册行为
统计指标:注册量、OCR认证量、MD5申请量、MD5通过量
分析维度:注册日期、渠道、客户经理、性别等
信贷申请【业务过程】
统计指标:最低借款金额,最高借款金额,申请次数,提供薪资报告次数,提供薪资报告最早时间,提供薪资报告资产最晚时间,提供信用报告次数,提供信用报告最早时间,提供信用报告最晚时间
统计粒度:用户的一次申请一条记录
分析维度:申请日期,最短期数,最长期数,证件类型,性别,渠道,客户经理,用户类型
信贷审核【业务过程】
统计指标:审核通过金额,信用审核分数,通过申请量,拒绝申请量,通过人数,拒绝人数
统计粒度:用户的一次审核记录为一条数据
分析维度:审核日期,证件类型,性别,渠道,客户经理,用户类型,审核人
提款【业务过程】
统计指标:提款申请量,提款申请人数,提款通过量,提款通过人数,协议签订量,协议签订人数,申请提款金额,协议签订金额,实际提款金额
统计粒度:用户一次提款请求作为一条记录
分析维度:提款日期,产品,证件类型,性别,渠道,用户类型,客户经理,借款期限
还款【业务过程】
统计指标:还款合同量,还款人数,还款金额,预期本金,预期利息,预期服务费,预期天数,预期次数,预期状态
统计粒度:用户一次还款请求作为一条记录
分析维度:还款日期、产品、证件类型,性别,渠道,用户类型,客户经理
员工分析【员工主题域】
统计指标:入职人数,离职人数,在职天数,在职月份数
统计粒度:每天的入职人数和离职人数
分析维度:离职日期或入职日期,年龄(段),性别,部门
小结:
宽表:一个表字段很多,就是宽表。
为什么使用宽表?
假如一个指标经常关联好几个表,那么干脆建立一个宽表,把这几个表的字段都放在一个表中。提高查询效率,数据可以重复利用。
一般在数仓的哪一层建立宽表?
可以放在 dwd 层 、dws 层,也可以将宽表单独创建一层:dwt 层
拉链表:记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期。(适用于变化频率不高的维度)
每日拉链表数据=昨日新增数据+昨日拉链表数据(左连接)
任务调度:使用dolphineScheduler
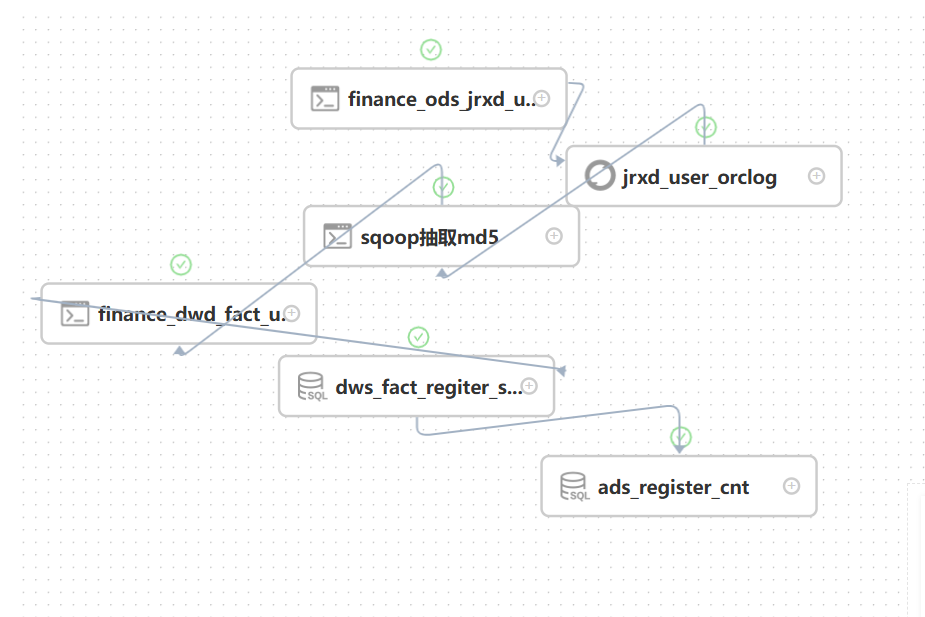
将ads层数据导入到mysql中进行可视化
在数据库中创建一个数据库专门进行可视化(避免和业务库放在一起,影响业务数据库的性能)
利用datax将hive数据导入到mysql
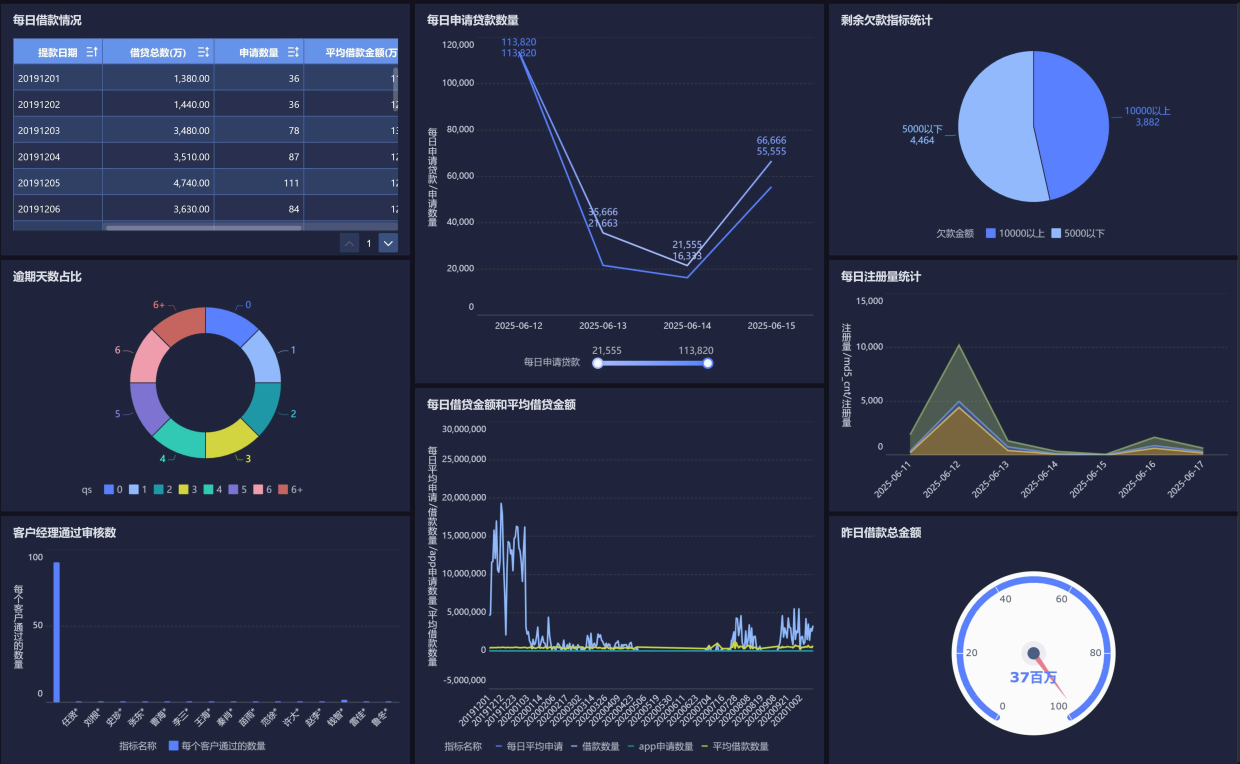
可视化
使用datagrea或者finebi

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)