HADOOP集群搭建及配置(大数据学习1)
4.1 HADOOP集群搭建4.1.1集群简介HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNodeYARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager(那mapred...
4.1 HADOOP集群搭建
4.1.1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
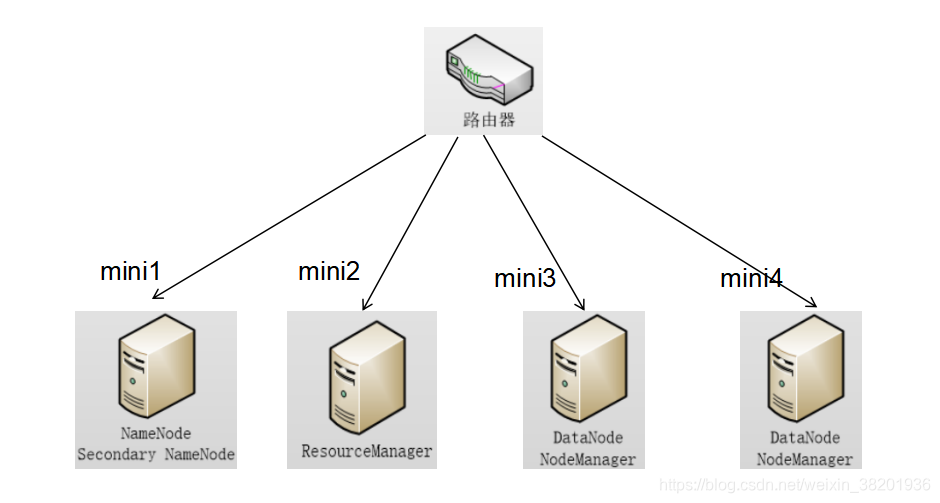
本集群搭建案例,以4节点为例进行搭建,角色分配如下:
| 节点 | 说明 | ip地址 |
|---|---|---|
| mini1 | 主节点 | 192.168.63.181 |
| mini2 | 从节点 | 192.168.63.182 |
| mini3 | 从节点 | 192.168.63.183 |
| mini4 | 从节点 | 192.168.63.184 |
部署图如下:
4.1.2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
- VMware® Workstation 12 Pro
- CentOS-6.9-x86_64-bin-DVD1.iso
4.1.3网络环境准备
- 采用NAT方式联网
- 网关地址:192.168.63.1
- 4个服务器节点IP地址:192.168.33.181、192.168.33.182、192.168.33.183、192.168.33.184
- 子网掩码:255.255.255.0
4.1.4服务器系统设置
- 添加HADOOP用户
1) 打开 xshell 先用root权限登录,为四个服务器同时添加hadoop 用户
在xshell 中任意地方点击右键 会看到 发送键输入到所有会话 选中它 这样就可以同时操作四台服务器。

2) 然后 关闭xshell 重新登录四个ipdi地址 用hadoop 用户登录
![]()
![]()
![]()
![]()
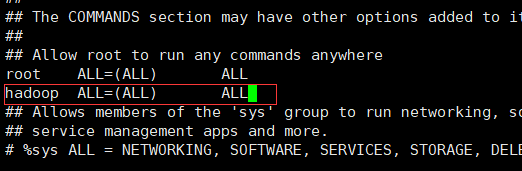
- 为HADOOP用户分配sudoer权限
1) su 执行su 输入密码 切换到root 权限

2) vi /etc/sudoers 修改sudoers文件 找到红框地方 加入 红框中的内容 然后强制保存 :wq!
- 同步时间
- 设置主机名
mini1
mini2
mini3
mini4
首先在root 权限下
vi /etc/hosts
配置内网域名映射 添加下面的四句
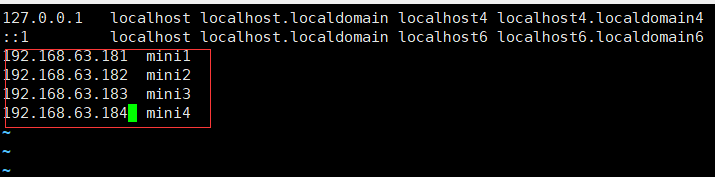
- 配置内网域名映射:
- 192.168.63.181 mini1
- 192.168.63.182 mini2
- 192.168.63.183 mini3
- 192.168.63.184 mini4
- 配置ssh免密登陆
打开下面网址 就可以看到四台服务器之间的免密登录
https://blog.csdn.net/weixin_38201936/article/details/85123014
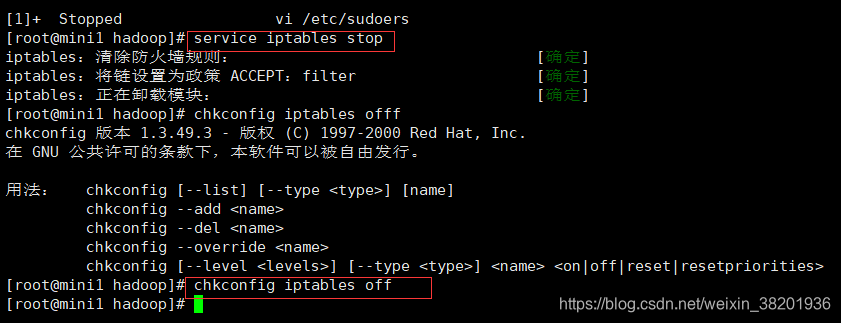
- 配置防火墙
1) service iptables stop 本次操作服务器的防火墙关闭
2) chkconfig iptables off 永久关闭防火墙
4.1.5 Jdk环境安装
4.1.6 HADOOP安装部署
- 上传HADOOP安装包 记得一定要在hadoop用户下上传安装包
安装包:https://pan.baidu.com/s/1gckS9wrDW0PILbHp2nlt3A 提取码:xl66

- 规划安装目录 /apps/hadoop-2.6.4
1) mkdir apps 新建一个文件夹 以后的安装文件都放入这个文件夹里

- 解压安装包
1) tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/ 解压安装包

- 修改配置文件
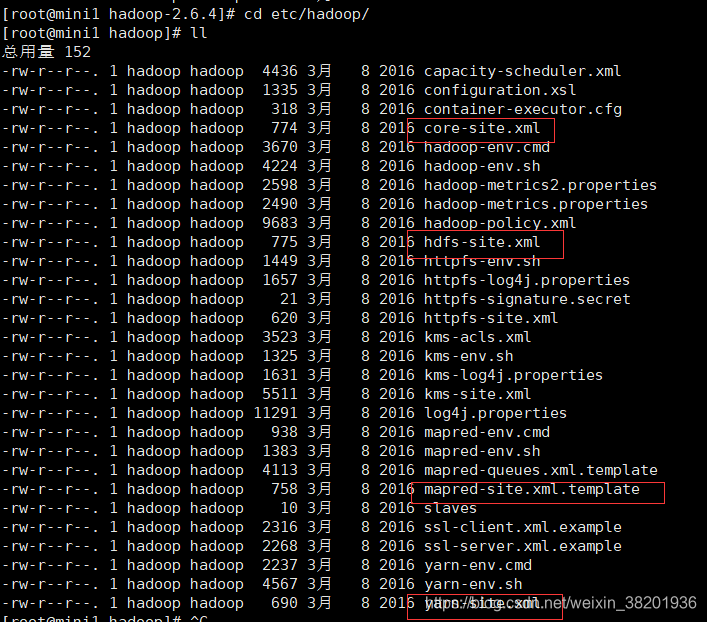
1) cd apps/hadoop-2.6.4/etc/hadoop/ ll 找到 hadoop-env.sh文件
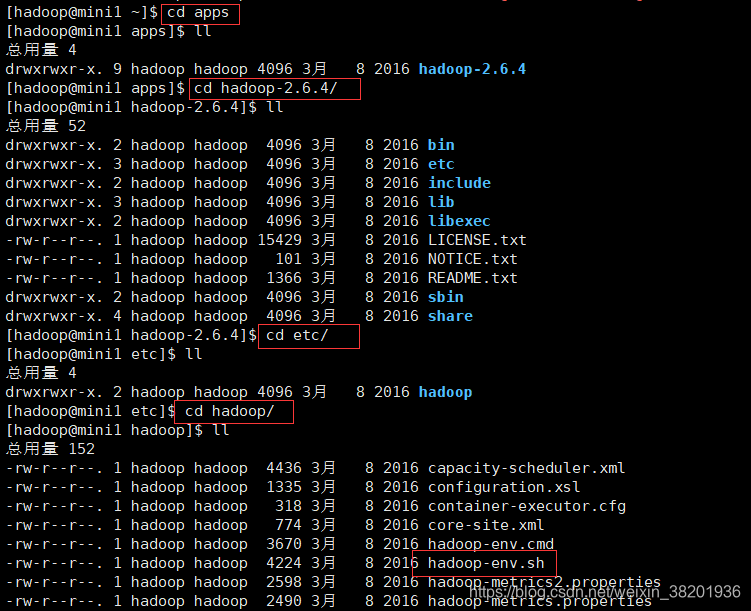
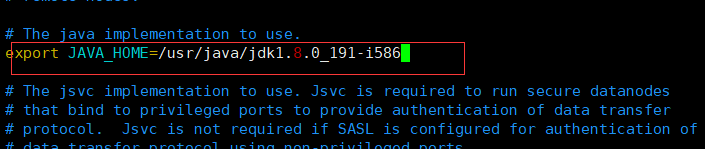
2) $JAVA_HOME 查看你的jdk 安装的路径 将路径复制

3) vi hadoop-env.sh 进入到文件中 将原来红框中的路径修改成你复制的路径 然后保存退出
现在要配置四个核心文件
4) vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mini1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
</configuration>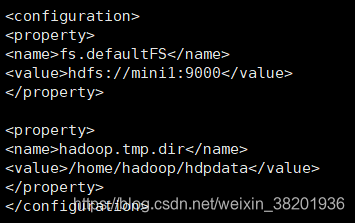
5) vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>mini1:50070</value>
</property>
</configuration> 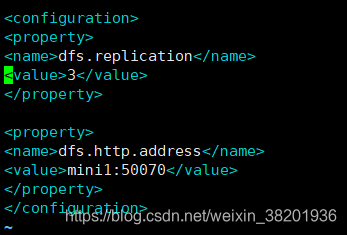
6) vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 7) vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mini1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>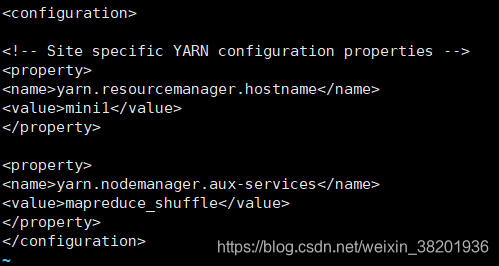
上面的四个文件配置完之后 ,然后 sudo vi /etc/profile 修改这个文件

修改内容为红框所示: 然后保存
export JAVA_HOME=/usr/java/jdk1.8.0_191-i586
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"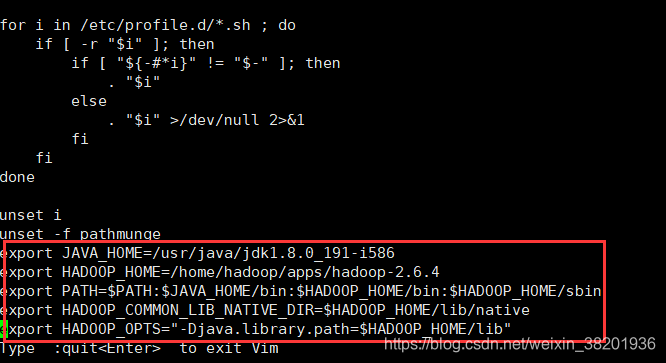
上面的操作执行完之后 在根目录下 将apps 问件 复制 全部拷贝到其他三台虚拟机上
![]()
后面的hadoop 指的是你创建的用户
scp -r apps mini2:/home/hadoop/
scp -r apps mini3:/home/hadoop/
scp -r apps mini4:/home/hadoop/ 4.1.7 启动集群
- 初始化HDFS
source /etc/profile 先刷新
hadoop namenode -format 对配置的hadoop 进行初始化 最后提示初始化成功
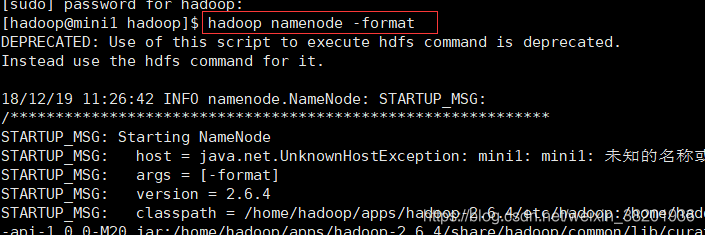

- 启动Hadoop
cd apps/hadoop-2.6.4/sbin/
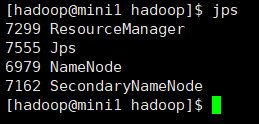
hadoop-daemon.sh start namenode 启动mini1服务器的主节点之后 查看jps 是否有NameNode 主节点

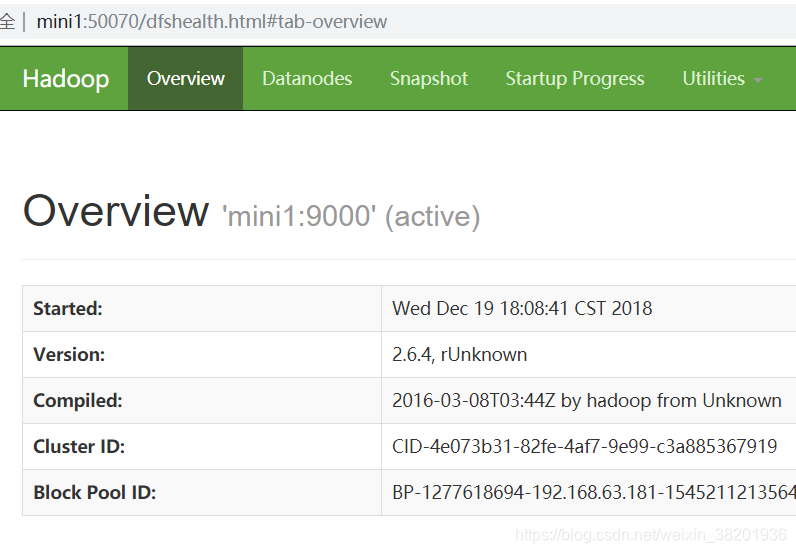
然后输入网址 http:192.168.63.181:50070 端口号默认是50070 前面的ip地址是你服务器的地址
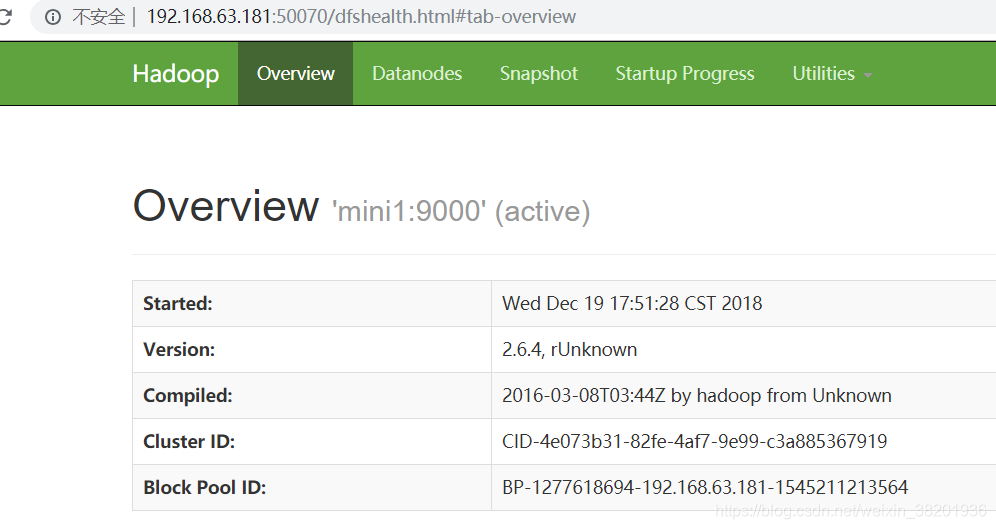
或者 输入主机名 http:mini1:50070 端口号默认是50070 前面的ip地址是你服务器的地址
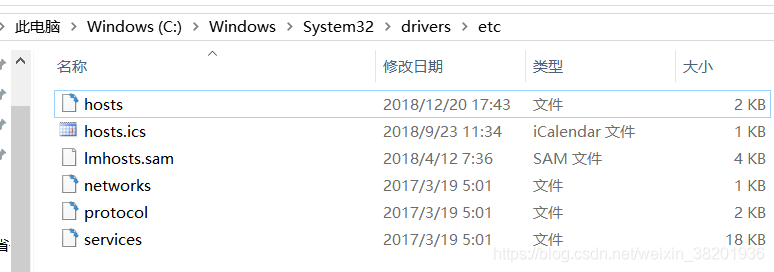
如果输入主机名+端口号登录不成功
在window端 C:\Windows\System32\drivers\etc添加ip地址映射

配置成功后 先关闭 hadoop-daemon.sh stop namenode
在重启 hadoop-daemon.sh start namenode 就OK 了
接下来讲一下 NameNode 和DataNode 的关系
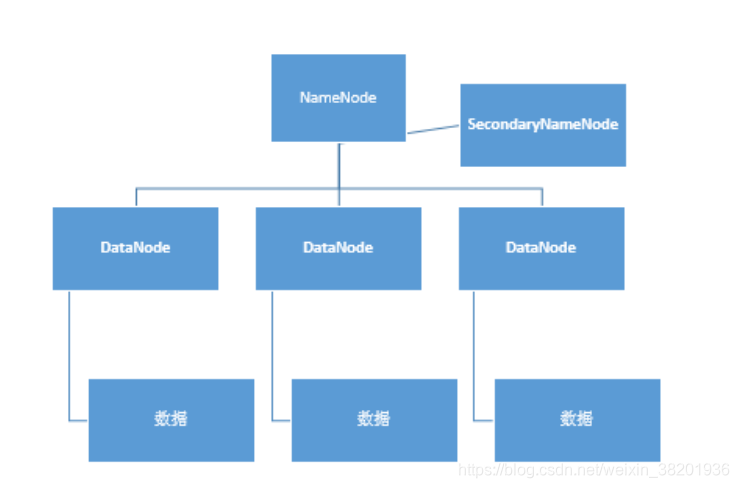
如上图所示,HDFS基本结构分NameNode、SecondaryNameNode、DataNode这几个。
NameNode:是Master节点,有点类似Linux里的根目录。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:保存着NameNode的部分信息(不是全部信息NameNode宕掉之后恢复数据用),是NameNode的冷备份;合并fsimage和edits然后再发给namenode。(防止edits过大的一种解决方案)
DataNode:负责存储client发来的数据块block;执行数据块的读写操作。是NameNode的小弟。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits
所以在主服务器mini1 启动之后 我们可以看到他里面的资源全部都是空的
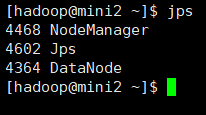
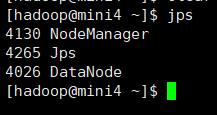
这时 你可以操作你的mini2 服务器 在上面启动dataNode 从结点
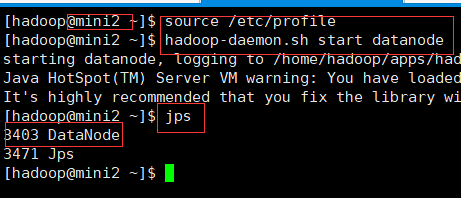
启动完之后 刷新页面会看到DataNode 被加载进来
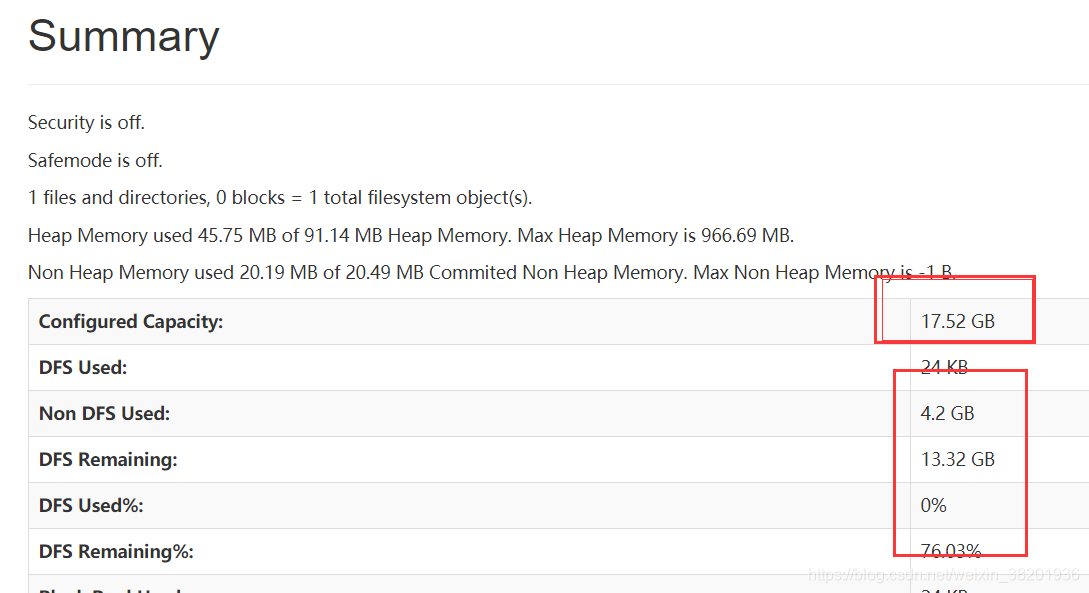
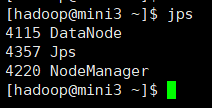
当三台服务器的从节点全部启动之后 加载页面
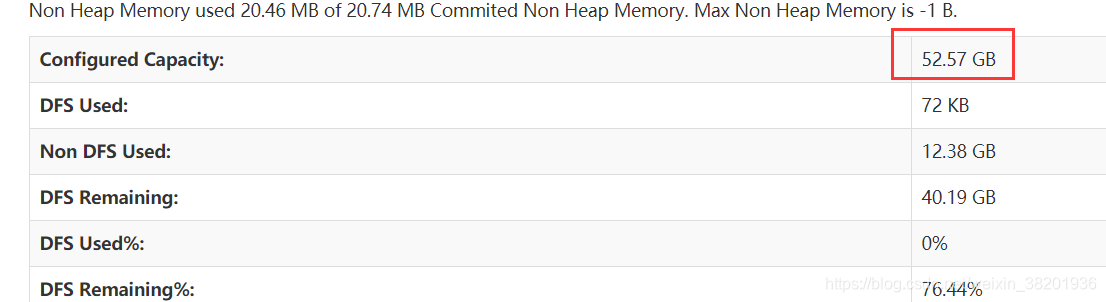
上面的就算安装部署成功了 ! 但是现在我们要配置一个文件,让四台服务器一起性启动,实现自动化!
cd etc/hadoop 查看slaves 文件
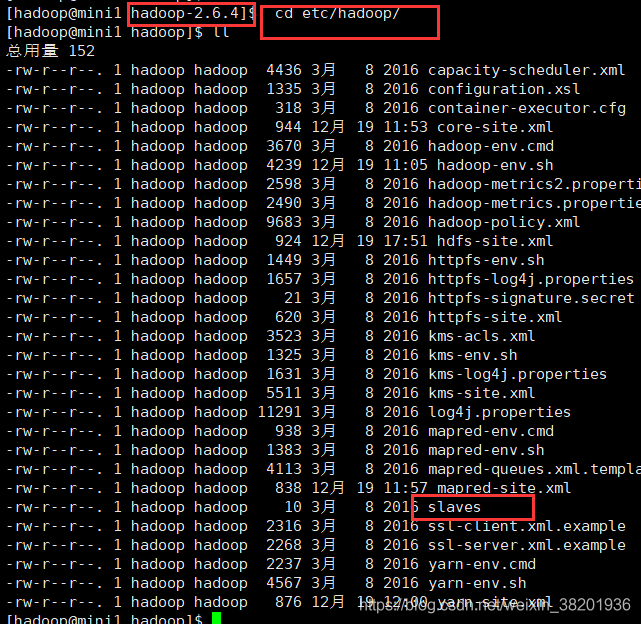
vi slaves 编辑文件 刚打开时 显示localhost
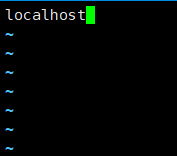
在里面将localhost 删除 然后 添加 mini2、mini3、mini4
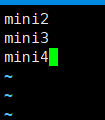
保存之后 然后输入 start-all.sh 然后四台服务器就全部启动

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)