基于大数据的YOLOv5算法垃圾检测分类系统 深度学习 垃圾分类检测 ✅
基于大数据的YOLOv5算法垃圾检测分类系统 深度学习 垃圾分类检测 ✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、YoloV5深度学习算法、pyqt图形模块、注册登录、训练集测试集、深度学习
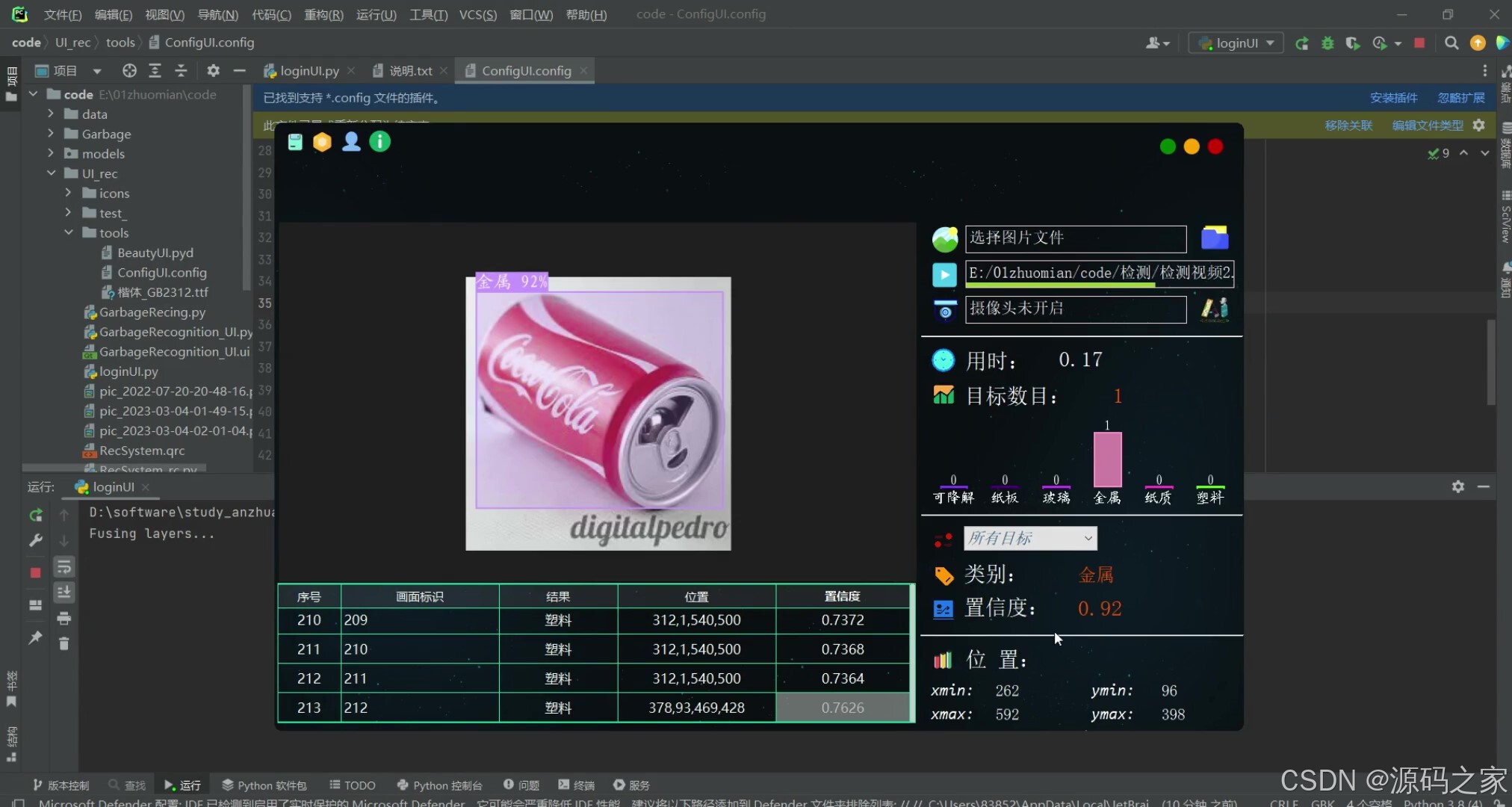
本系统基于YOLOv5算法进行垃圾检测分类,对于图片、视频和摄像头捕获的实时画面,系统可检测画面中的垃圾类型和位置,支持结果记录、展示和保存,每次检测的结果记录在表格中。
1、技术特点
(1)YoloV5算法实现,模型一键切换更新;
(2)检测图片、视频等图像中的各目标数目并可视化;
(3)摄像头监控实时检测,便携展示、记录和保存;
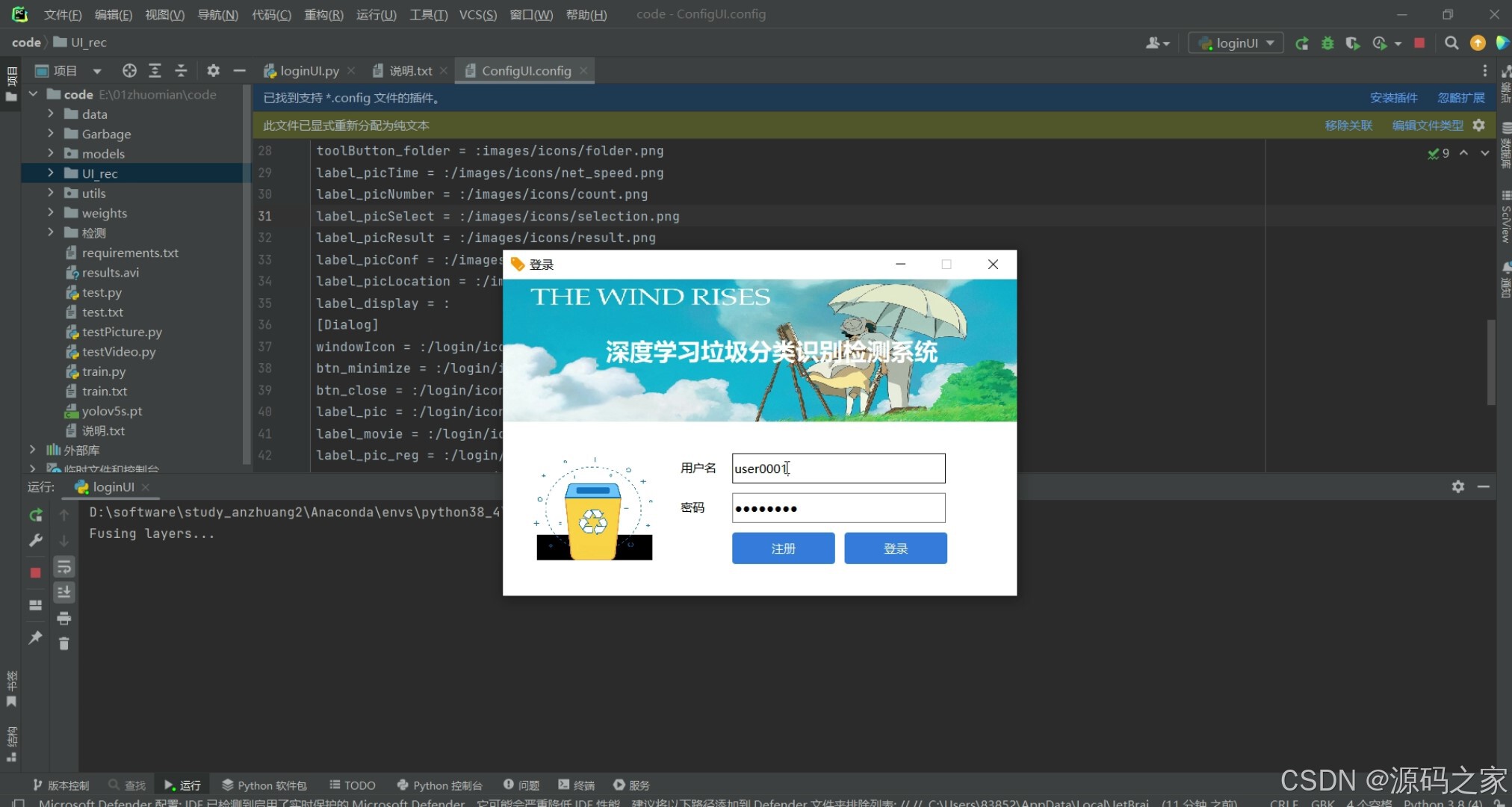
(4)支持用户登录、注册,检测结果可视化功能;
(5)提供完整训练数据集,可重新训练模型;
对常见的:可降解、纸板、玻璃、金属、纸质、塑料 (6类)等类别垃圾进行检测和计数
2、项目界面
(1)垃圾分类—纸质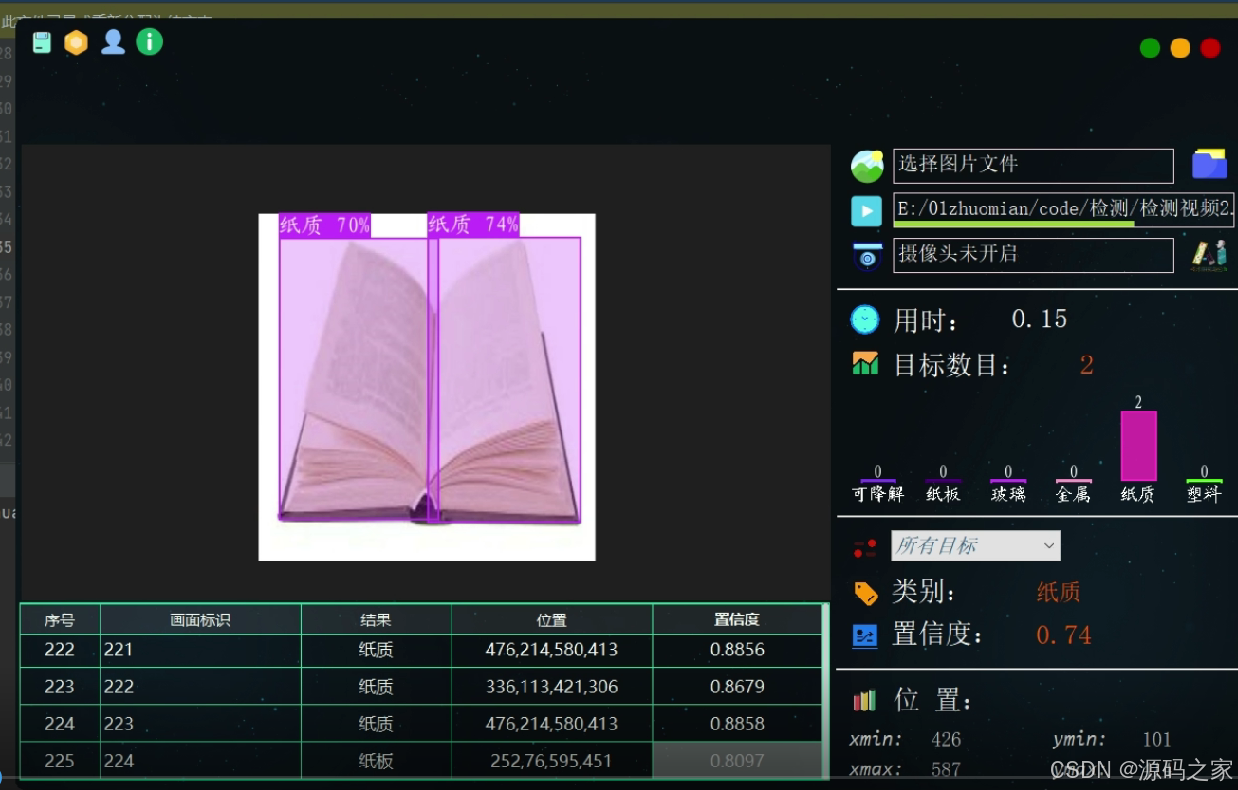
(2)垃圾分类—金属
(3)垃圾分类—塑料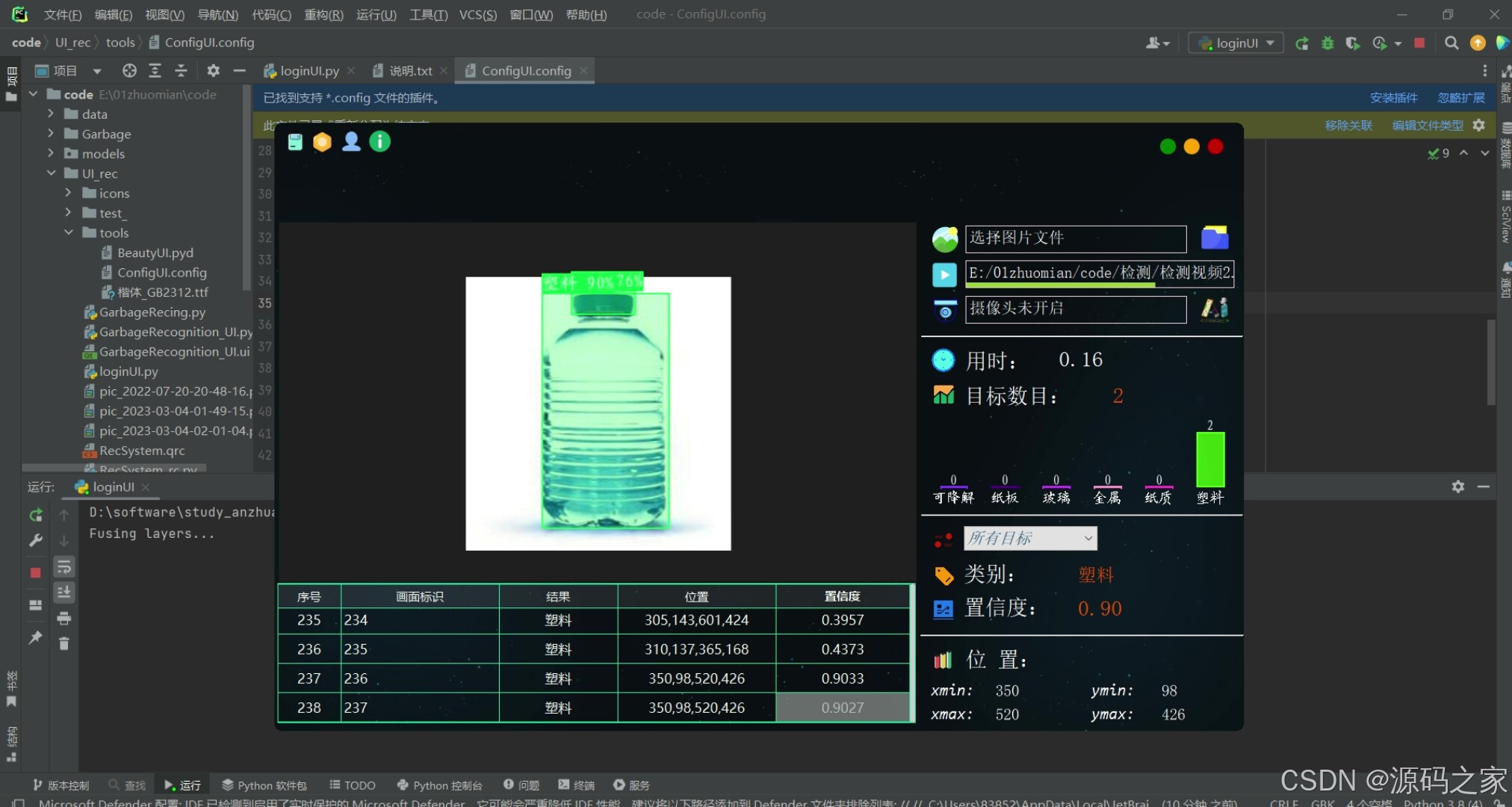
(4)注册登录界面
3、项目说明
训练的具体参数需要具体配置,配置数据集的训练集路径、验证集路径、测试集路径,类别nc设置为6,包括’BIODEGRADABLE’, ‘CARDBOARD’, ‘GLASS’, ‘METAL’, ‘PAPER’, 'PLASTIC’这6类,配置好这些就可运行train.py训练了。
train: ./Garbage/images/train
val: ./Garbage/images/val
test: ./Garbage/images/test
nc: 6
names: ['BIODEGRADABLE', 'CARDBOARD', 'GLASS', 'METAL', 'PAPER', 'PLASTIC']
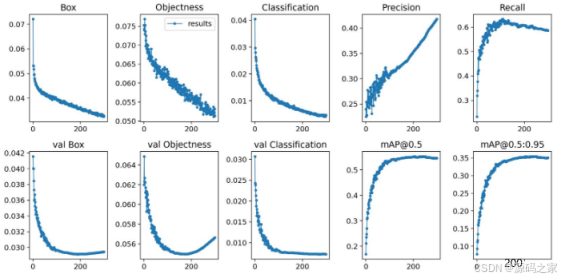
在深度学习中,我们通常通过损失函数下降的曲线来观察模型训练的情况。而YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),在训练结束后,我们也可以在logs目录下找到生成对若干训练过程统计图。下图为博主训练生活垃圾类识别的模型训练曲线图。
一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值。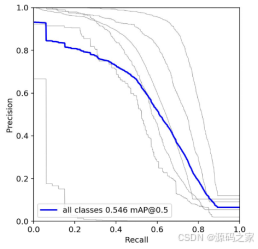
以PR-curve为例,可以看到我们的模型在验证集上的均值平均准确率为0.546。从训练结果和数据集进行分析,存在一定干扰样本,部分数据集图像中的垃圾相互遮盖,垃圾存在的环境复杂多变,很容易造成模型误检。
4、核心代码
在训练完成后得到最佳模型,接下来我们将帧图像输入到这个网络进行预测,从而得到预测结果,预测方法(predict.py)部分的代码如下所示:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='./weights/garbage-best.pt',
help='model.pt path(s)') # 模型路径仅支持.pt文件
parser.add_argument('--img-size', type=int, default=480, help='inference size (pixels)') # 检测图像大小,仅支持480
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold') # 置信度阈值
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS') # NMS阈值
# 选中运行机器的GPU或者cpu,有GPU则GPU,没有则cpu,若想仅使用cpu,可以填cpu即可
parser.add_argument('--device', default='',
help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--save-dir', type=str, default='inference', help='directory to save results') # 文件保存路径
parser.add_argument('--classes', nargs='+', type=int,
help='filter by class: --class 0, or --class 0 2 3') # 分开类别
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS') # 使用NMS
opt = parser.parse_args() # opt局部变量,重要
out, weight, imgsz = opt.save_dir, opt.weights, opt.img_size # 得到文件保存路径,文件权重路径,图像尺寸
device = select_device(opt.device) # 检验计算单元,gpu还是cpu
half = device.type != 'cpu' # 如果使用gpu则进行半精度推理
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)