基于python的木鸟民宿网热门城市数据分析可视化及推荐系统设计与实现
本系统采用前后端分离的架构设计,后端基于Flask框架构建RESTful API,前端使用Bootstrap和ECharts实现响应式界面和交互式图表。数据处理层使用pandas和numpy进行数据清洗和特征工程,可视化层集成matplotlib、seaborn等多种图表库,机器学习层基于scikit-learn实现价格预测和聚类分析功能。本项目成功构建了一个完整的木鸟民宿网数据分析及可视化系统,
1. 引言
1.1 项目背景
随着共享经济的快速发展,民宿行业已成为旅游住宿市场的重要组成部分。木鸟民宿作为国内领先的民宿预订平台,汇聚了全国各地的优质民宿资源。然而,面对海量的民宿数据,如何从中挖掘有价值的信息,为用户提供更好的住宿选择建议,成为了一个重要的研究课题。
本项目基于Python技术栈,构建了一个完整的木鸟民宿网热门城市数据分析及可视化系统。该系统通过爬取木鸟民宿网的真实数据,运用数据科学和机器学习技术,从市场宏观概况、房源属性特征、用户评价口碑等多个维度进行深度分析,并通过现代化的Web界面提供直观的数据可视化展示。
1.2 研究意义
数据驱动的决策已成为现代商业的核心竞争力。通过对民宿数据的深度分析,可以帮助平台运营者了解市场趋势,优化资源配置;帮助房东制定合理的定价策略,提升房源竞争力;帮助用户快速找到性价比最高的住宿选择。同时,本项目也为数据科学在旅游行业的应用提供了一个完整的实践案例。
1.3 技术架构概述
本系统采用前后端分离的架构设计,后端基于Flask框架构建RESTful API,前端使用Bootstrap和ECharts实现响应式界面和交互式图表。数据处理层使用pandas和numpy进行数据清洗和特征工程,可视化层集成matplotlib、seaborn等多种图表库,机器学习层基于scikit-learn实现价格预测和聚类分析功能。
2. 数据采集
2.1 爬虫系统设计
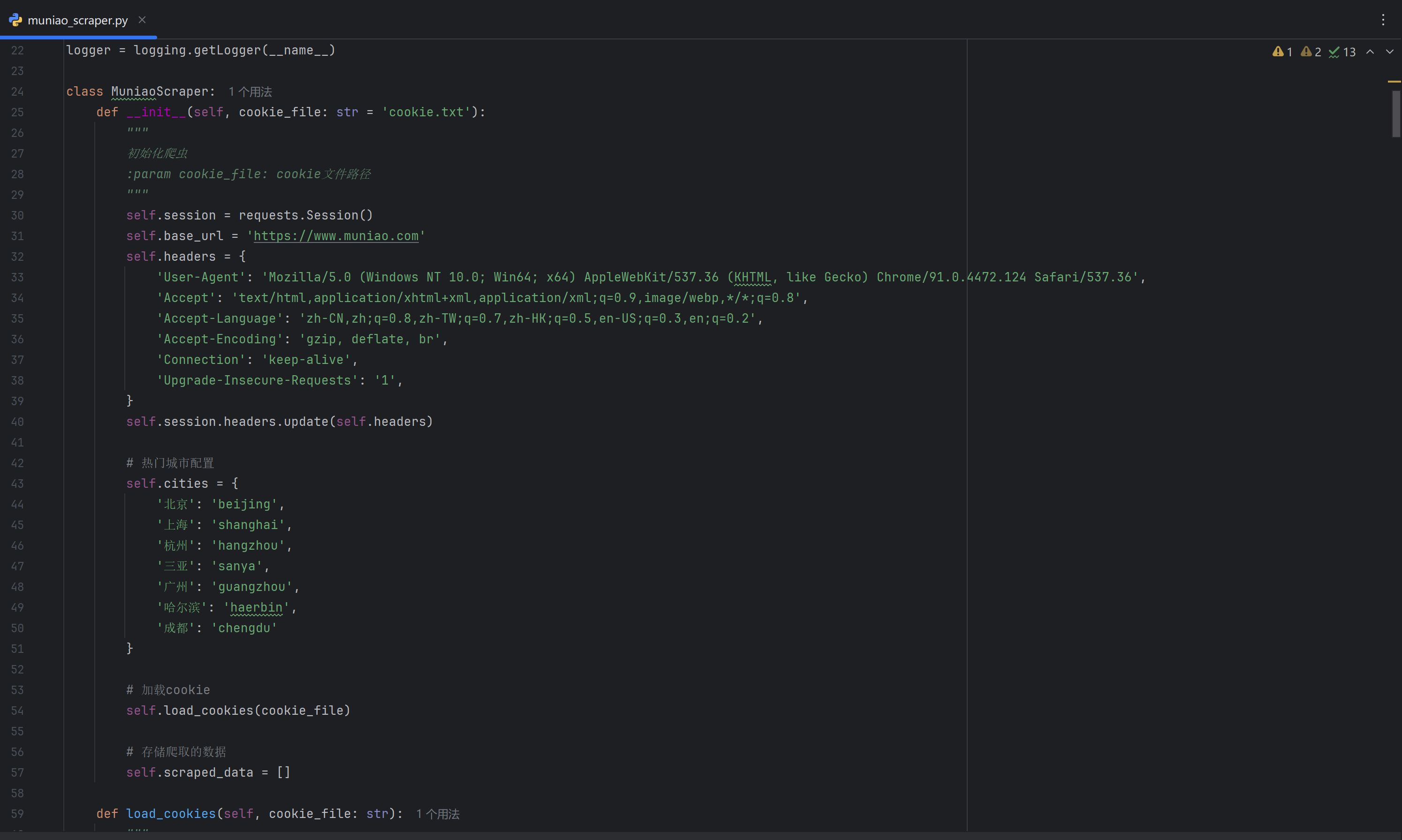
数据采集是整个系统的基础环节。本项目设计了一个高效稳定的爬虫系统,主要针对木鸟民宿网的7个热门城市进行数据采集,包括北京、上海、杭州、三亚、广州、哈尔滨、成都。
爬虫系统采用面向对象的设计模式,核心类MuniaoScraper封装了所有爬取逻辑。系统支持多种排序方式的数据获取,包括默认排序、价格排序、评分排序等,确保数据的全面性和代表性。为了应对网站的反爬虫机制,系统实现了智能的请求头管理、Cookie持久化、随机延时等策略。
2.2 数据字段设计
经过深入分析木鸟民宿网的页面结构,确定了以下核心数据字段:
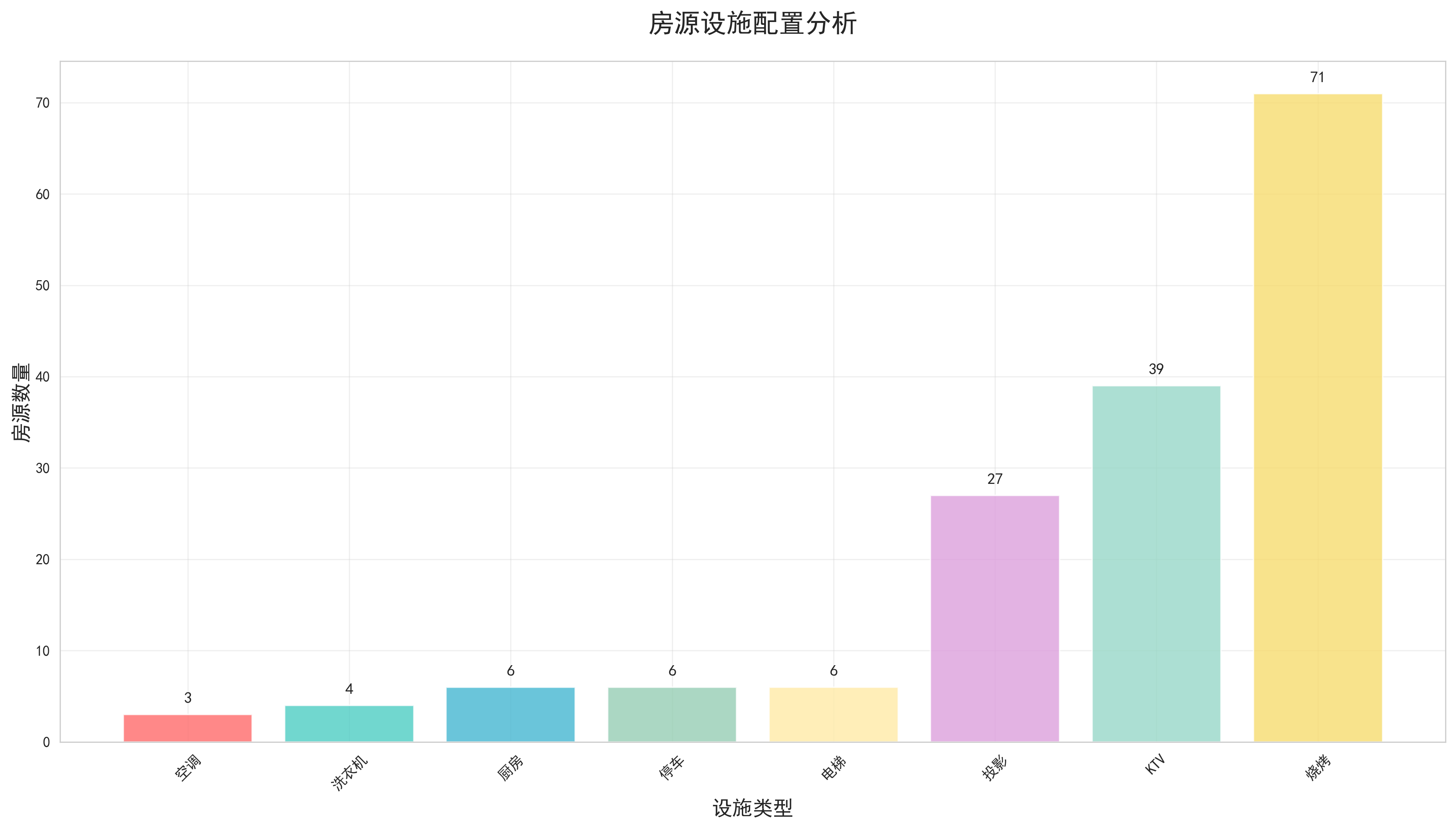
- 房源基础信息:包括房源ID、标题、城市、价格、户型、宜住人数、出租类型、房源类型、床型、面积、地址、图片链接等。这些字段构成了房源的基本画像,为后续的分析提供了丰富的维度。
- 评价相关信息:包括评论数量、好评率、综合评分、卫生状况评分、服务态度评分、图片吻合度评分、设施装潢评分等。这些字段反映了用户对房源的真实评价,是分析房源质量的重要指标。
2.3 爬取策略优化
为了提高爬取效率和数据质量,系统实现了多项优化策略。首先是分页爬取机制,通过解析页面的分页信息,实现对所有页面的完整遍历。其次是增量更新策略,通过记录已爬取的房源ID,避免重复爬取,提高系统效率。
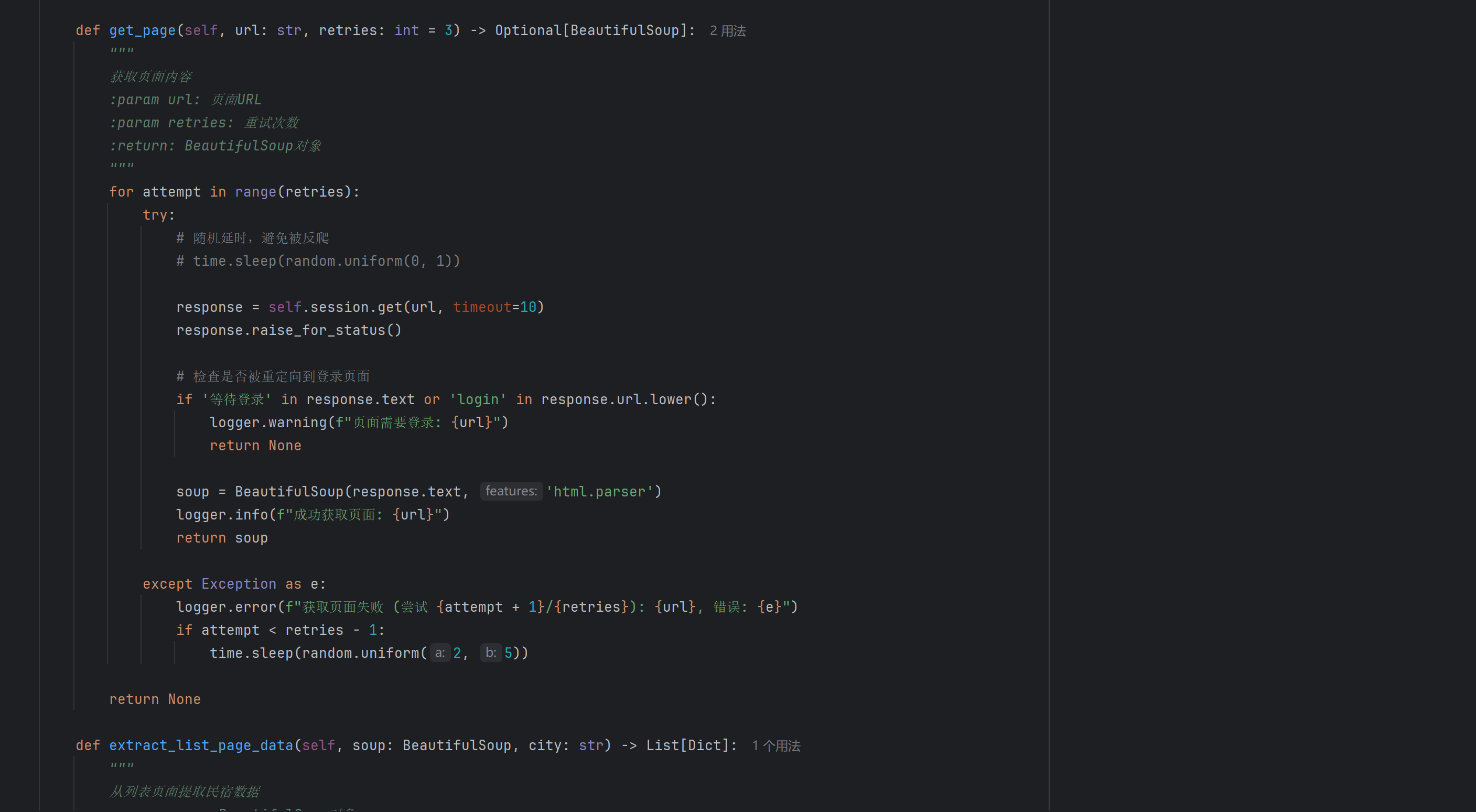
在数据质量控制方面,系统实现了多层次的数据验证机制。包括URL有效性检查、页面内容完整性验证、数据格式规范性校验等。对于爬取失败的页面,系统会自动进行重试,并记录详细的错误日志,便于问题排查和系统优化。
2.4 评论数据采集
除了房源基础信息,用户评论是反映房源质量和用户满意度的重要数据源。系统专门设计了评论爬取模块,通过解析房源详情页面的评论区域,获取用户的真实评价内容。
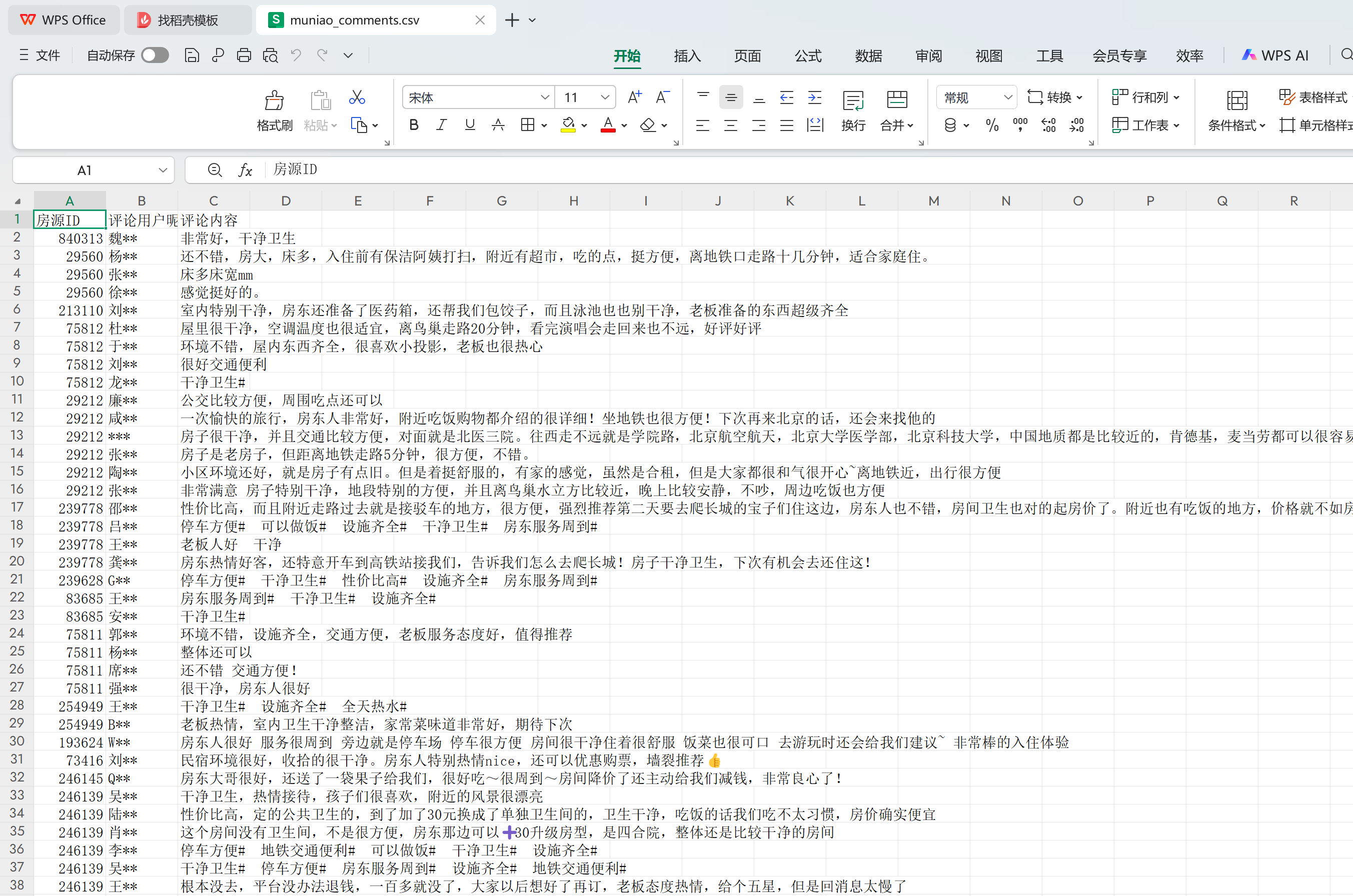
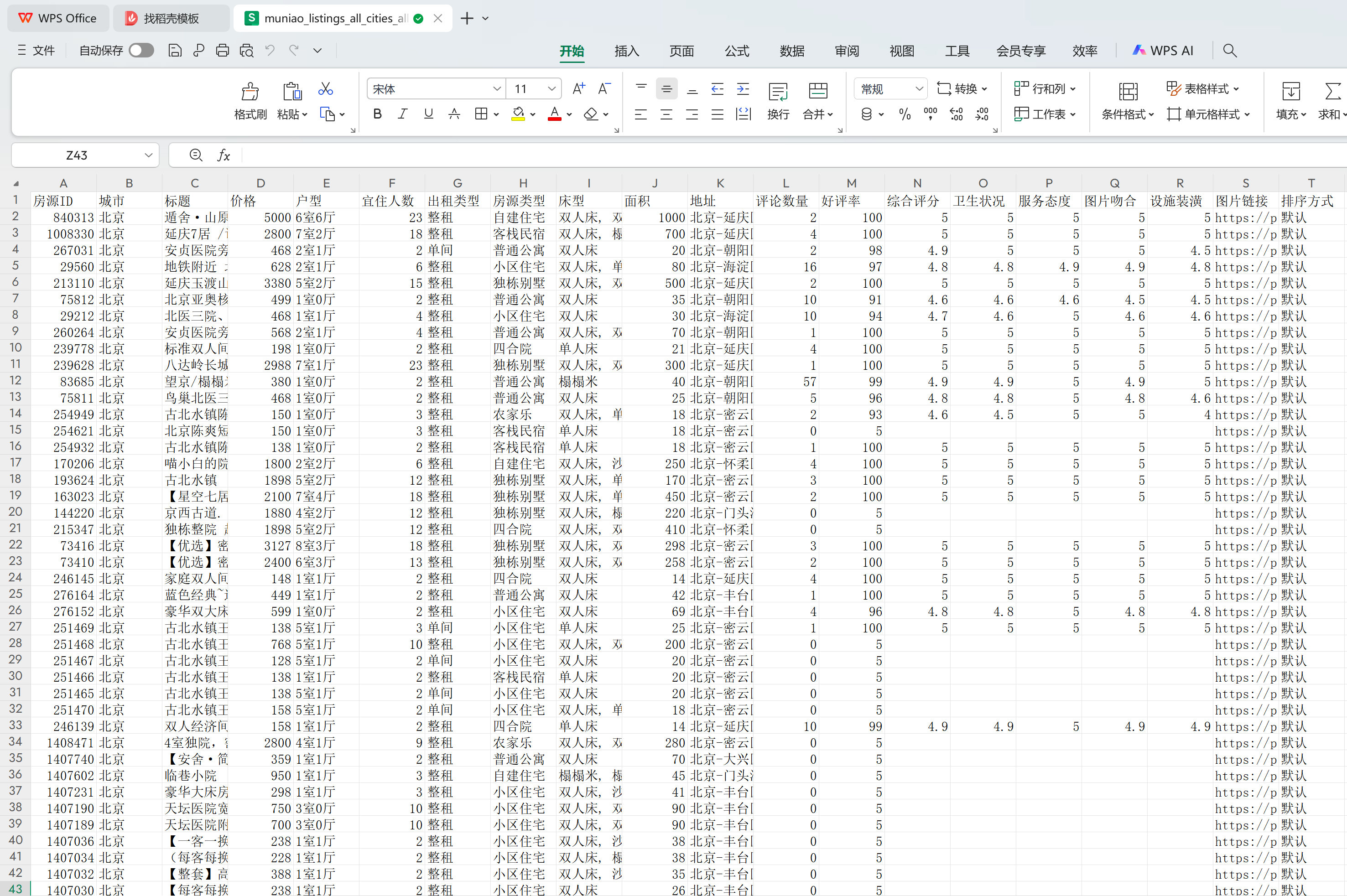
民宿的房源数据共采集12569条。
用户评论数据共采集7920条。
3. 数据预处理
3.1 数据清洗策略
原始爬取的数据往往存在各种质量问题,需要通过系统性的数据清洗来提升数据质量。本项目设计了一套完整的数据清洗流程,主要包括以下几个方面:
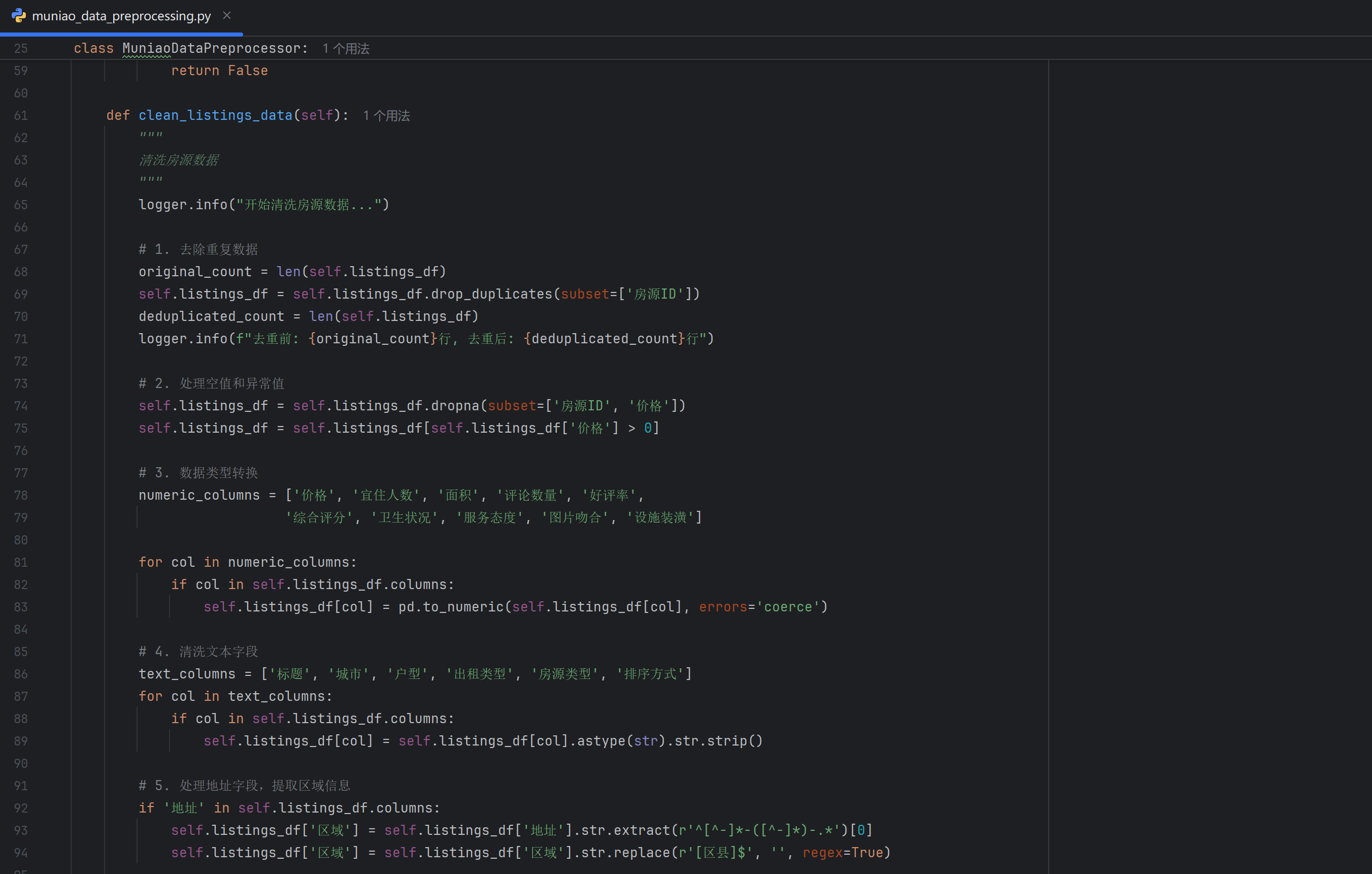
- 重复数据处理:是数据清洗的首要任务。由于爬取过程中可能存在重复访问同一房源的情况,系统基于房源ID进行去重处理,保留最新的数据记录。经过去重处理,数据集的质量得到了显著提升。
- 缺失值处理:采用了多种策略相结合的方法。对于关键字段如房源ID、价格等,采用删除策略,确保核心数据的完整性。对于非关键字段,根据字段特性采用不同的填充策略,如数值型字段使用均值填充,分类型字段使用众数填充。
- 异常值检测与处理:通过统计学方法识别数据中的异常值。例如,价格字段中明显不合理的极值,面积字段中的负数等。对于这些异常值,系统会根据业务逻辑进行修正或删除。
3.2 数据类型转换
原始数据通常以字符串形式存储,需要根据字段的语义进行适当的类型转换。价格、面积、评分等数值型字段转换为浮点数类型,便于后续的数值计算和统计分析。日期时间字段转换为标准的datetime格式,支持时间序列分析。
对于包含中文的文本字段,系统进行了编码规范化处理,确保中文字符的正确显示和处理。同时,对文本字段进行了去除首尾空格、统一大小写等标准化操作。
3.3 特征工程
特征工程是提升数据分析效果的关键环节。本项目基于业务理解和数据特点,设计了多个衍生特征:
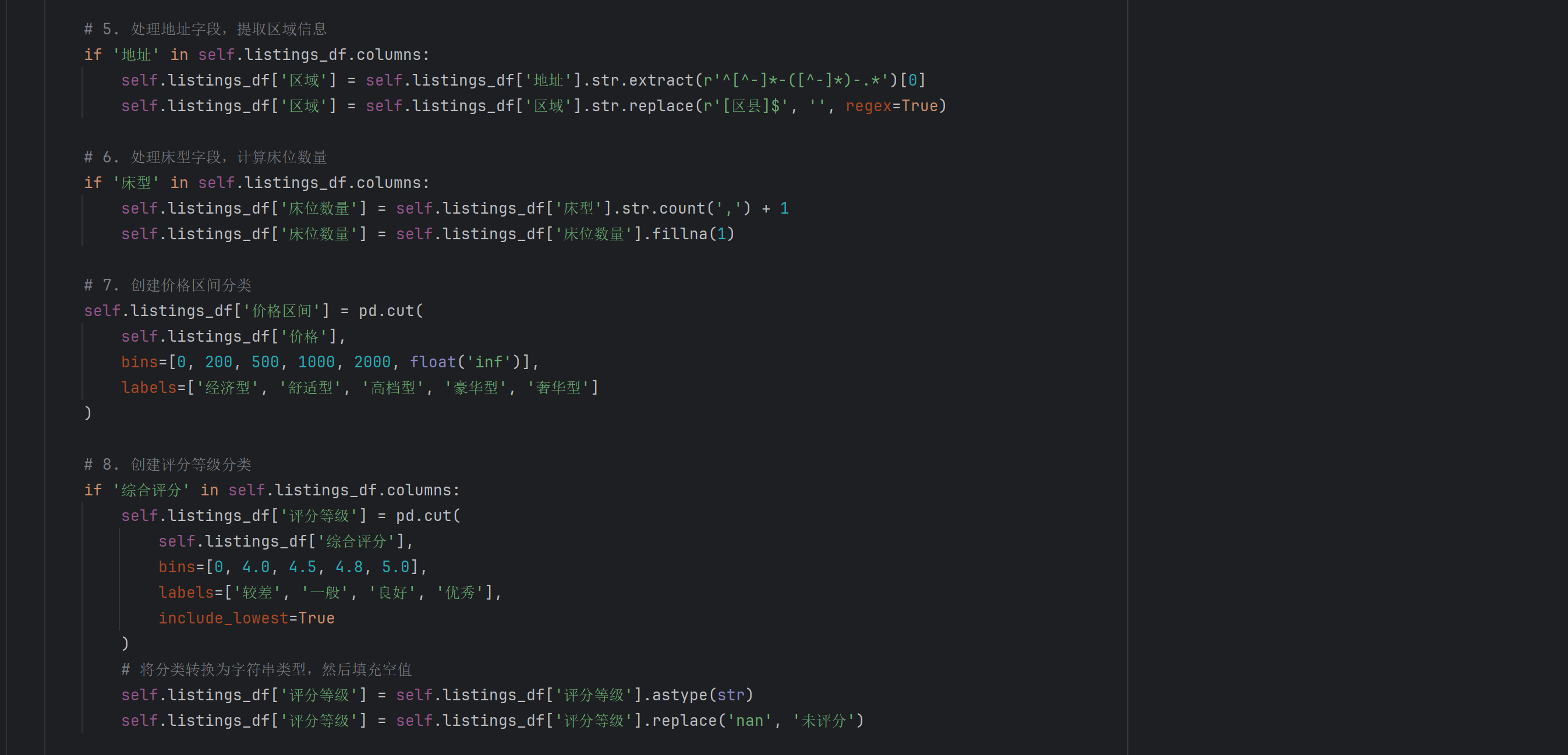
- 地理特征提取:从地址字段中提取区域信息,将详细地址解析为区县级别的地理标识。这为后续的地理分析和区域对比提供了基础。通过正则表达式匹配,成功提取了大部分房源的区域信息。
- 价格区间分类:将连续的价格数值转换为离散的价格区间,如经济型(0-200元)、舒适型(200-500元)、豪华型(500元以上)等。这种分类方式更符合用户的认知习惯,便于进行分组分析。
- 床位容量计算:从床型字段中解析出具体的床位配置,计算总的床位数量。这个特征反映了房源的实际容纳能力,是影响价格的重要因素。
3.4 数据聚合与统计
为了支持多维度的数据分析,系统对清洗后的数据进行了多层次的聚合统计。城市维度的统计包括各城市的房源数量、平均价格、评分分布等。房型维度的统计包括不同户型的价格分布、受欢迎程度等。
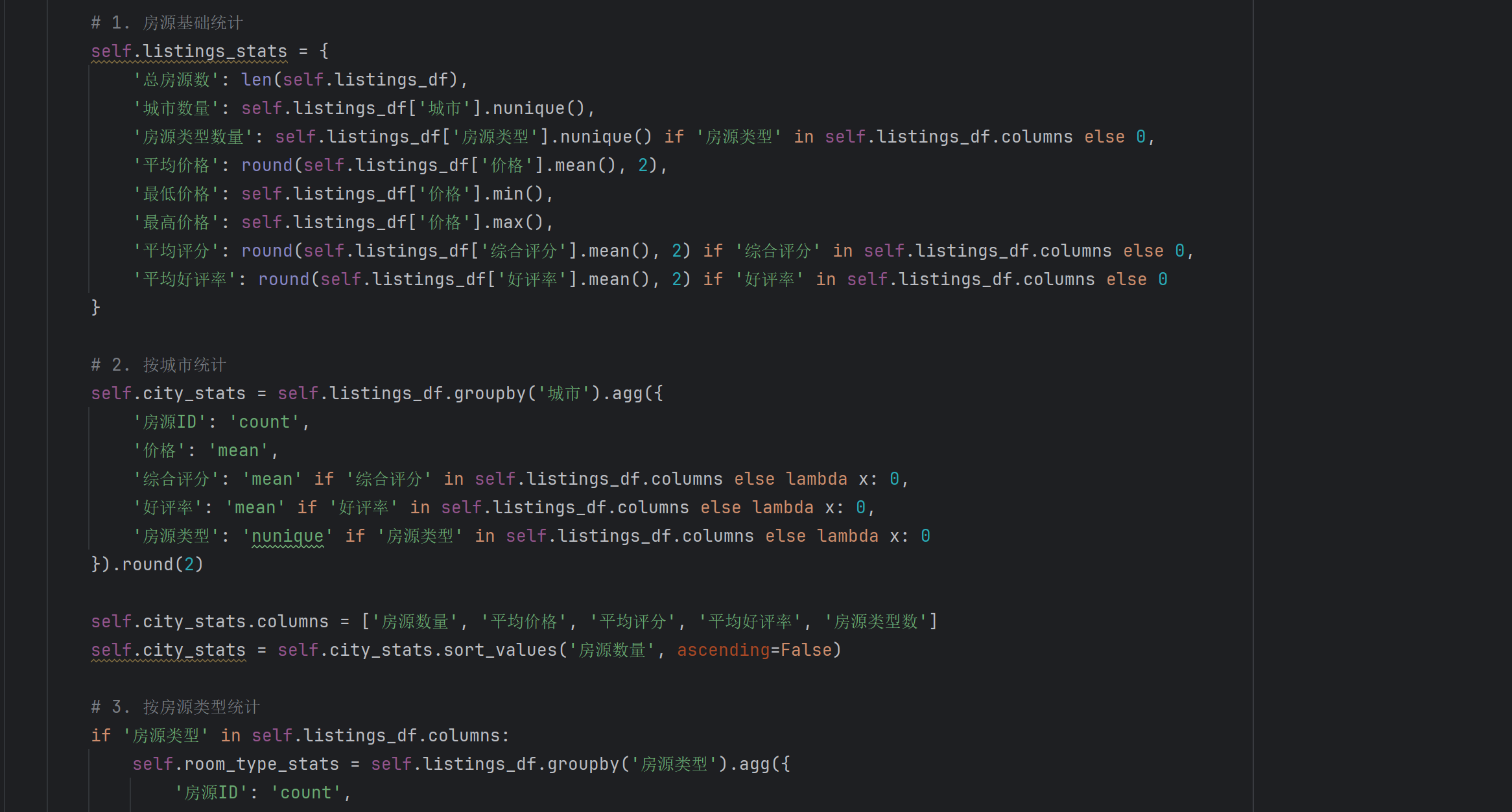
这些聚合统计结果以独立的CSV文件形式保存,形成了一个结构化的数据仓库。这种设计不仅提高了数据访问效率,也为后续的可视化分析提供了便利。
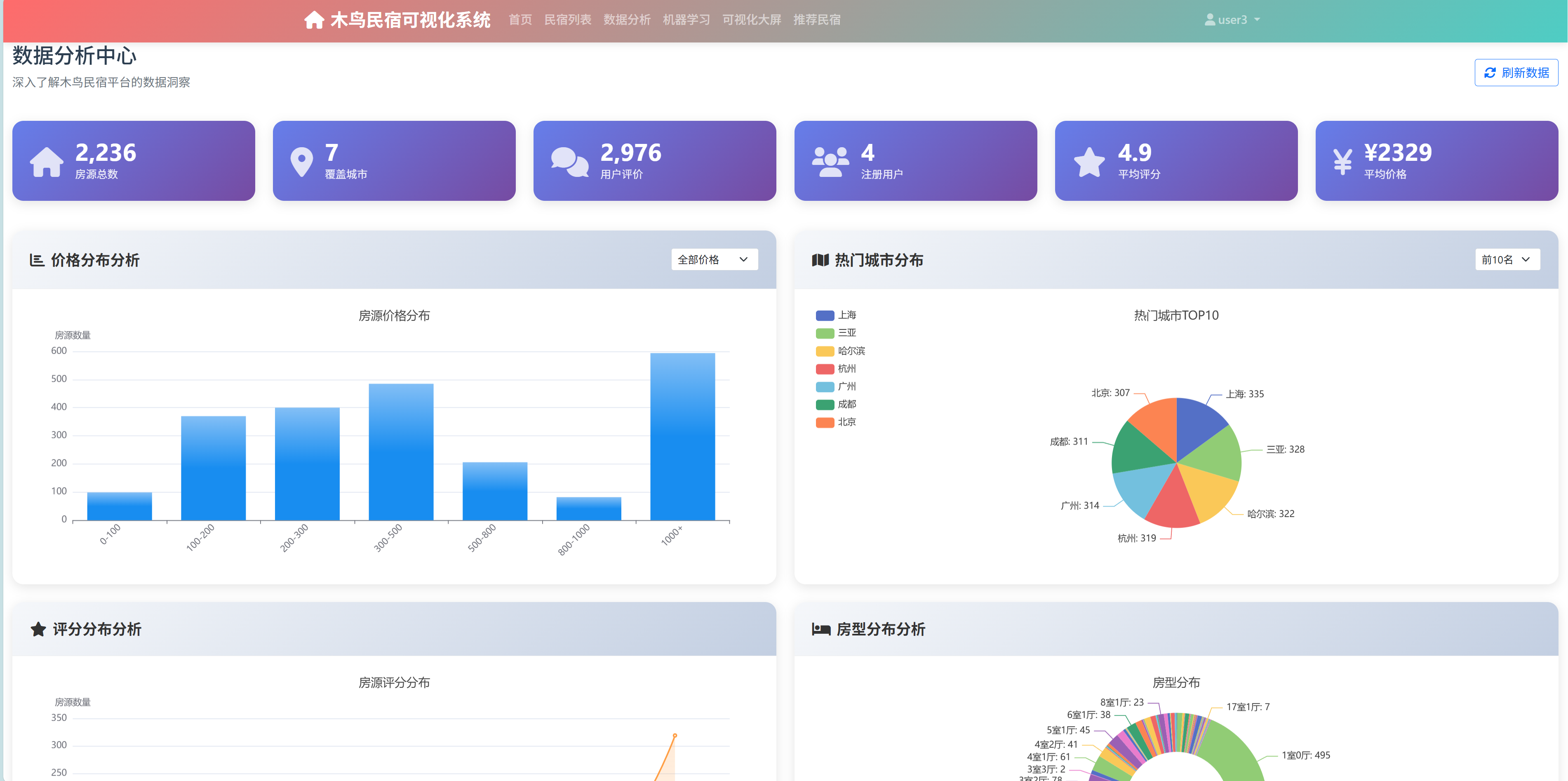
4. 数据可视化
4.1 可视化框架设计
数据可视化是将复杂数据转化为直观洞察的重要手段。本项目构建了一个多层次的可视化框架,支持静态图表生成和动态交互展示两种模式。
静态可视化基于matplotlib和seaborn库实现,主要用于深度分析和报告生成。系统预设了统一的图表样式和色彩方案,确保所有图表的视觉一致性。动态可视化基于ECharts库实现,集成在Web界面中,支持用户交互和实时数据更新。
4.2 市场宏观概况分析
市场宏观概况分析从整体视角展现民宿市场的基本特征和发展趋势。
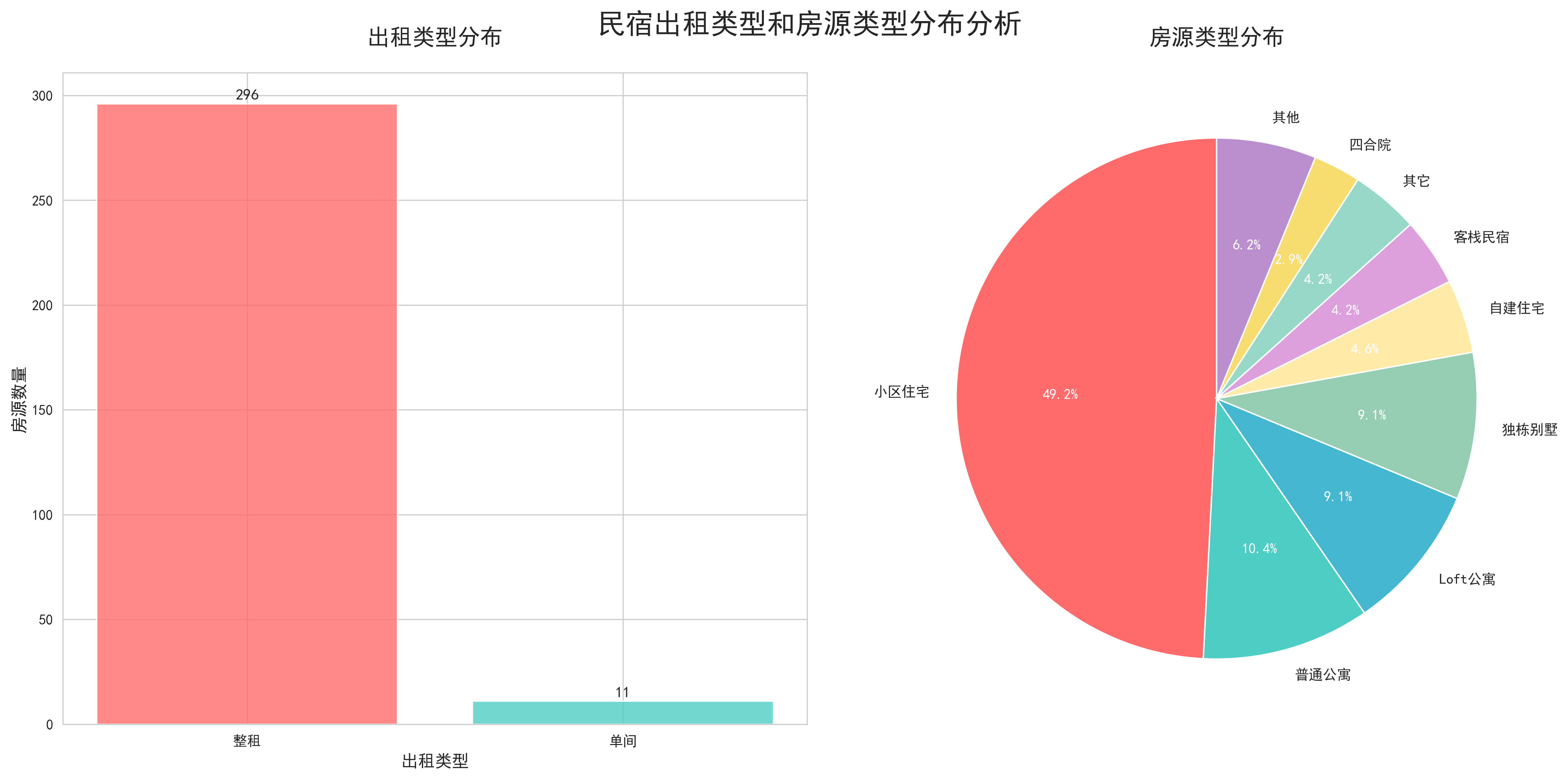
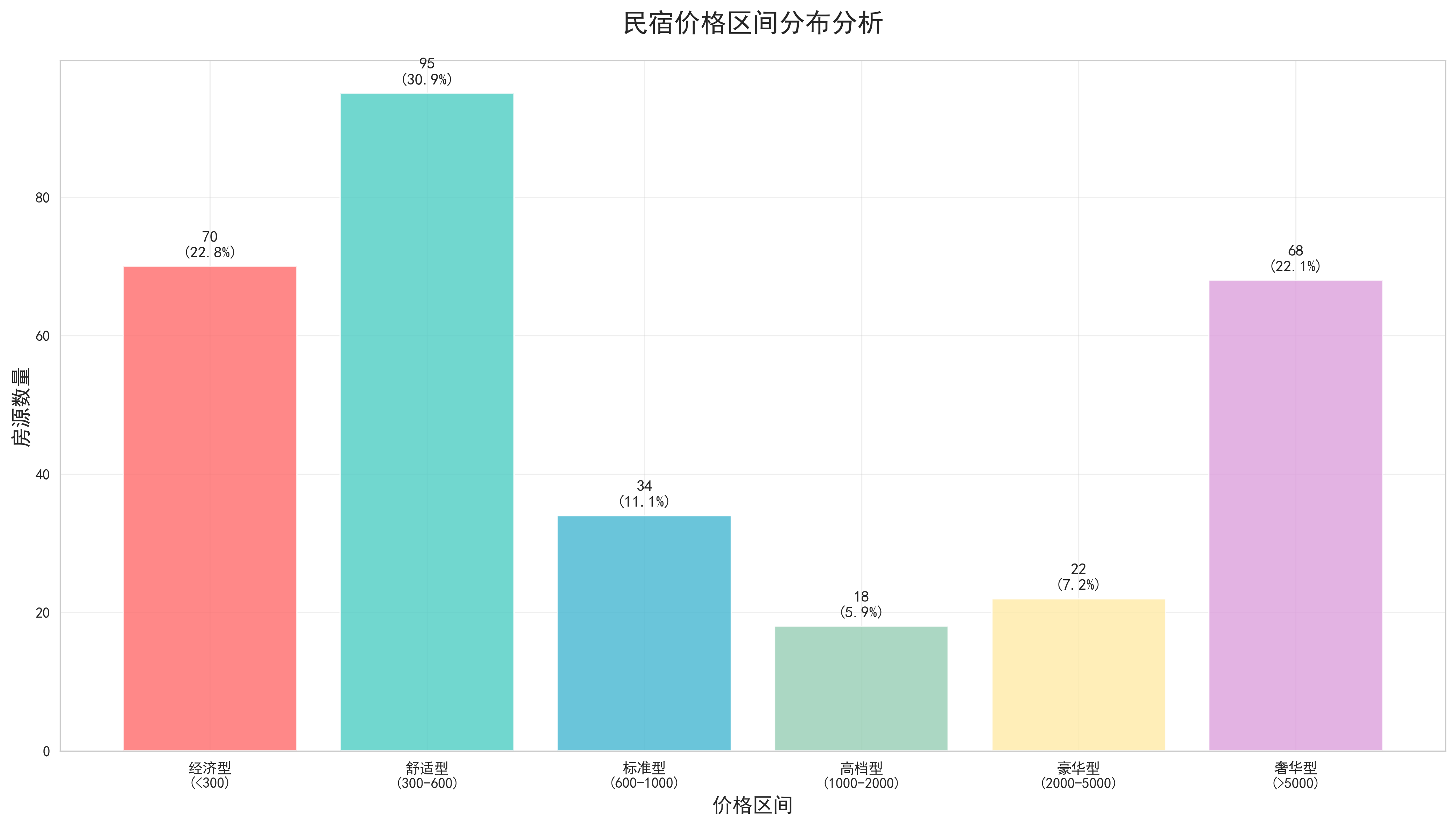
- 出租类型与房源类型分布分析:通过组合柱状图和饼图的形式,展示了不同出租类型(整租、合租)和房源类型(公寓、别墅、民宿等)的分布情况。分析发现,整租类型占据主导地位,公寓类房源最受欢迎,这反映了用户对私密性和便利性的偏好。
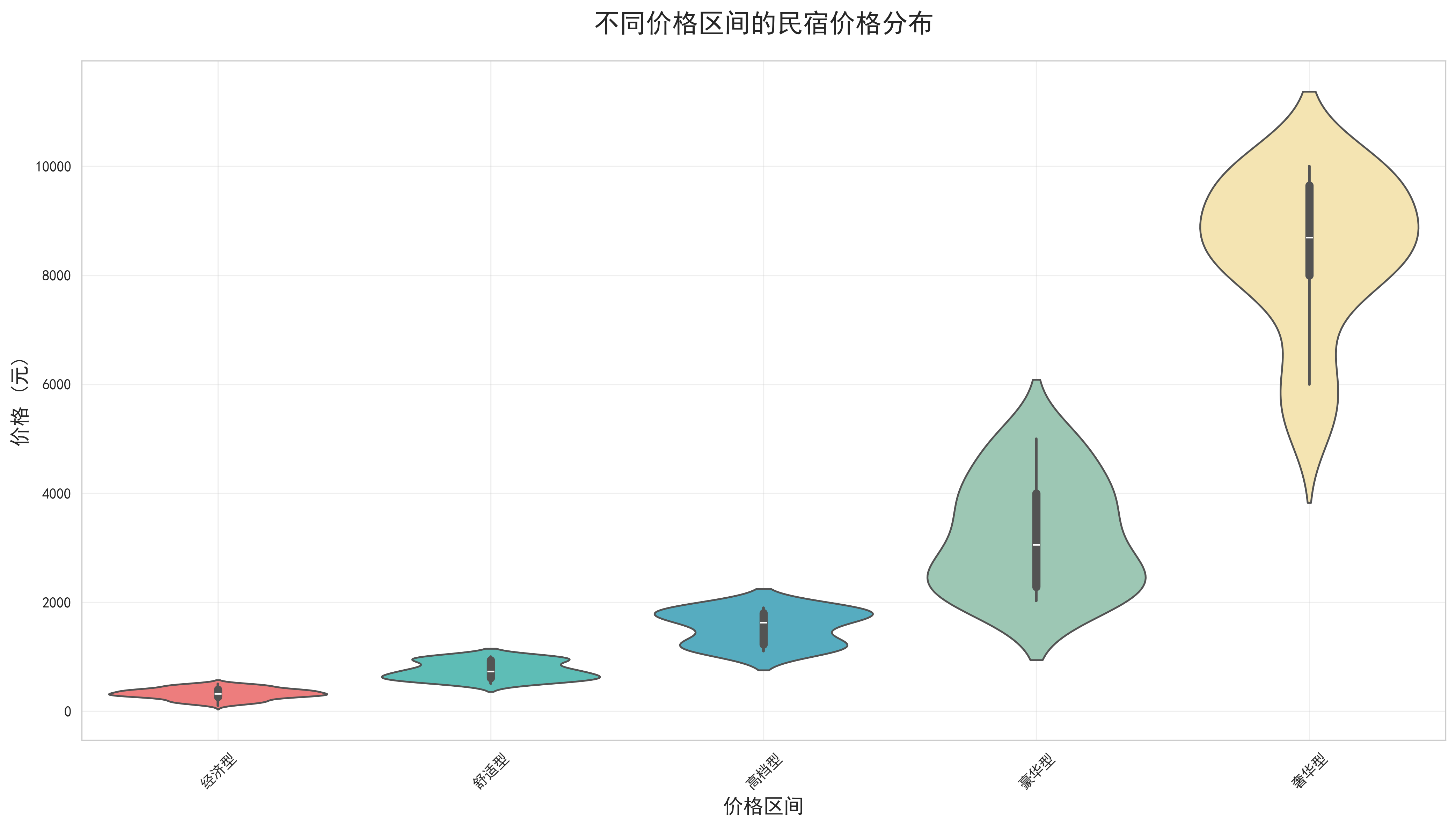
- 城市价格分布对比:采用小提琴图的可视化方式,直观展示了不同城市民宿价格的分布特征。小提琴图不仅显示了价格的中位数和四分位数,还展现了价格分布的密度特征。分析结果显示,一线城市如北京、上海的价格分布更加分散,价格区间更广;而二三线城市的价格分布相对集中。
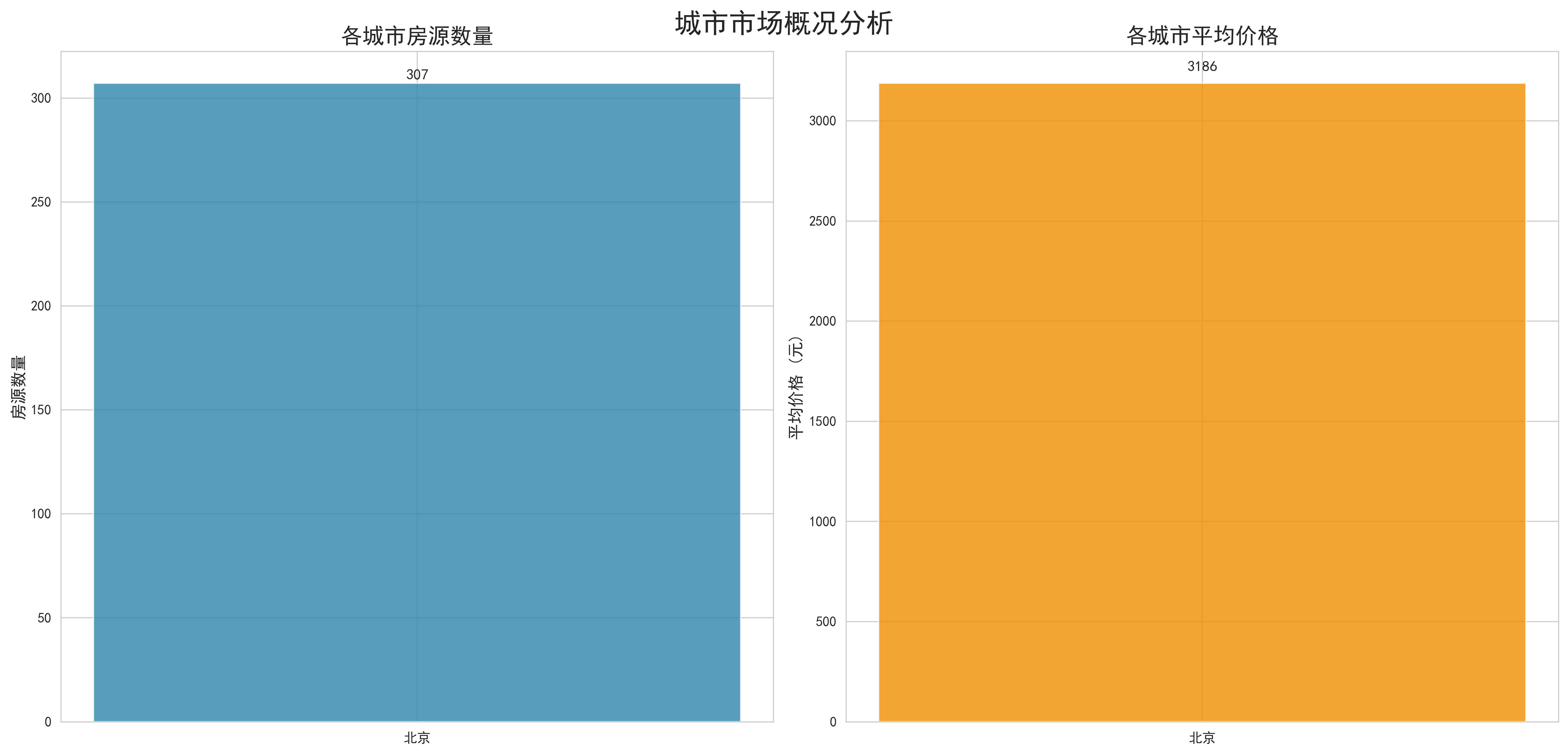
- 城市市场规模对比:通过双轴柱状图同时展示各城市的房源数量和平均价格,揭示了市场规模与价格水平的关系。数据显示,房源数量与城市规模基本呈正相关,但平均价格受多种因素影响,不完全与城市等级对应。
4.3 房源属性特征分析
房源属性分析深入挖掘影响房源价格和受欢迎程度的关键因素。
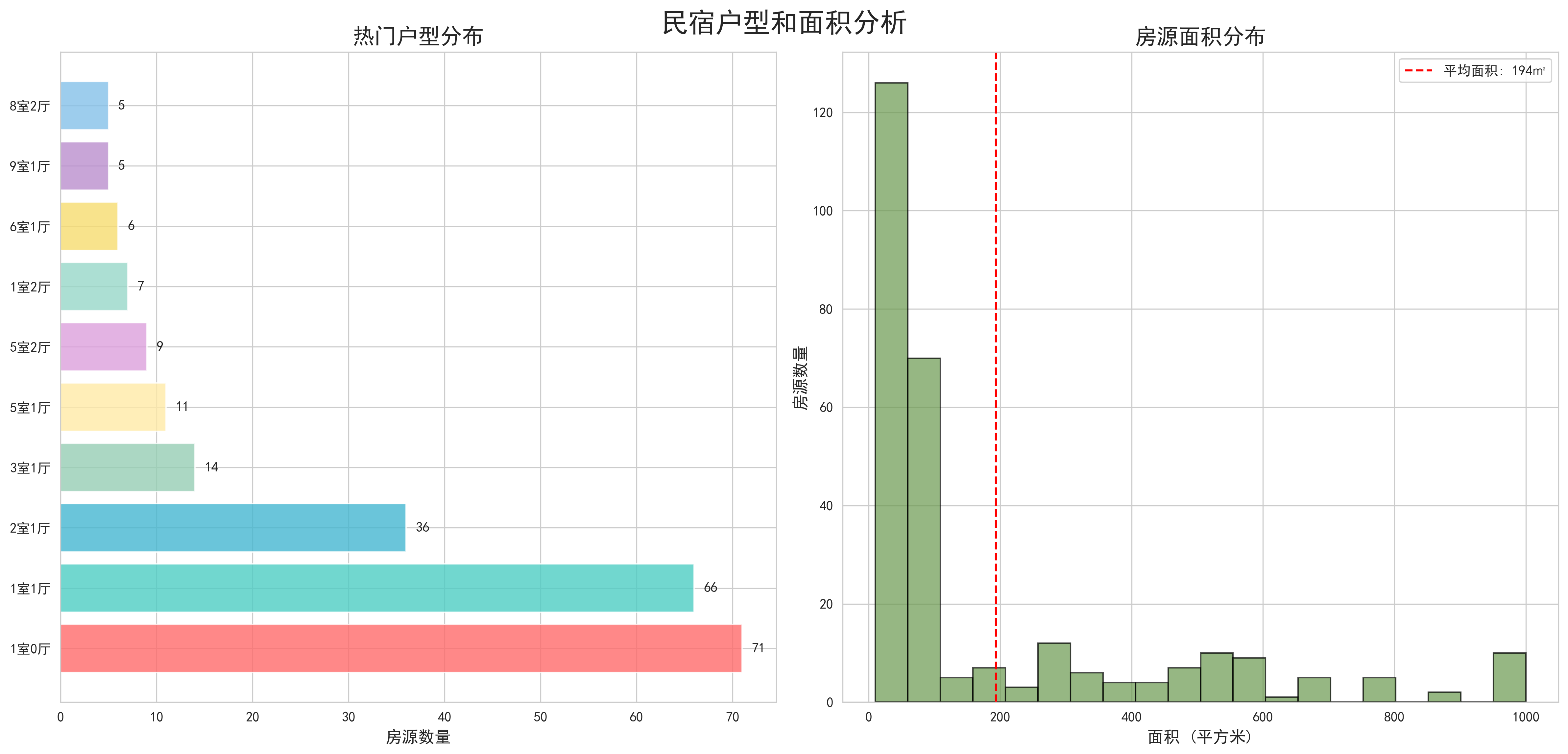
- 户型面积关系分析:通过散点图展示了房源面积与价格的关系,并按户型进行了分类着色。分析发现,面积与价格总体呈正相关关系,但不同户型的价格敏感度存在差异。一居室的价格主要受地段影响,而多居室的价格与面积关联度更高。
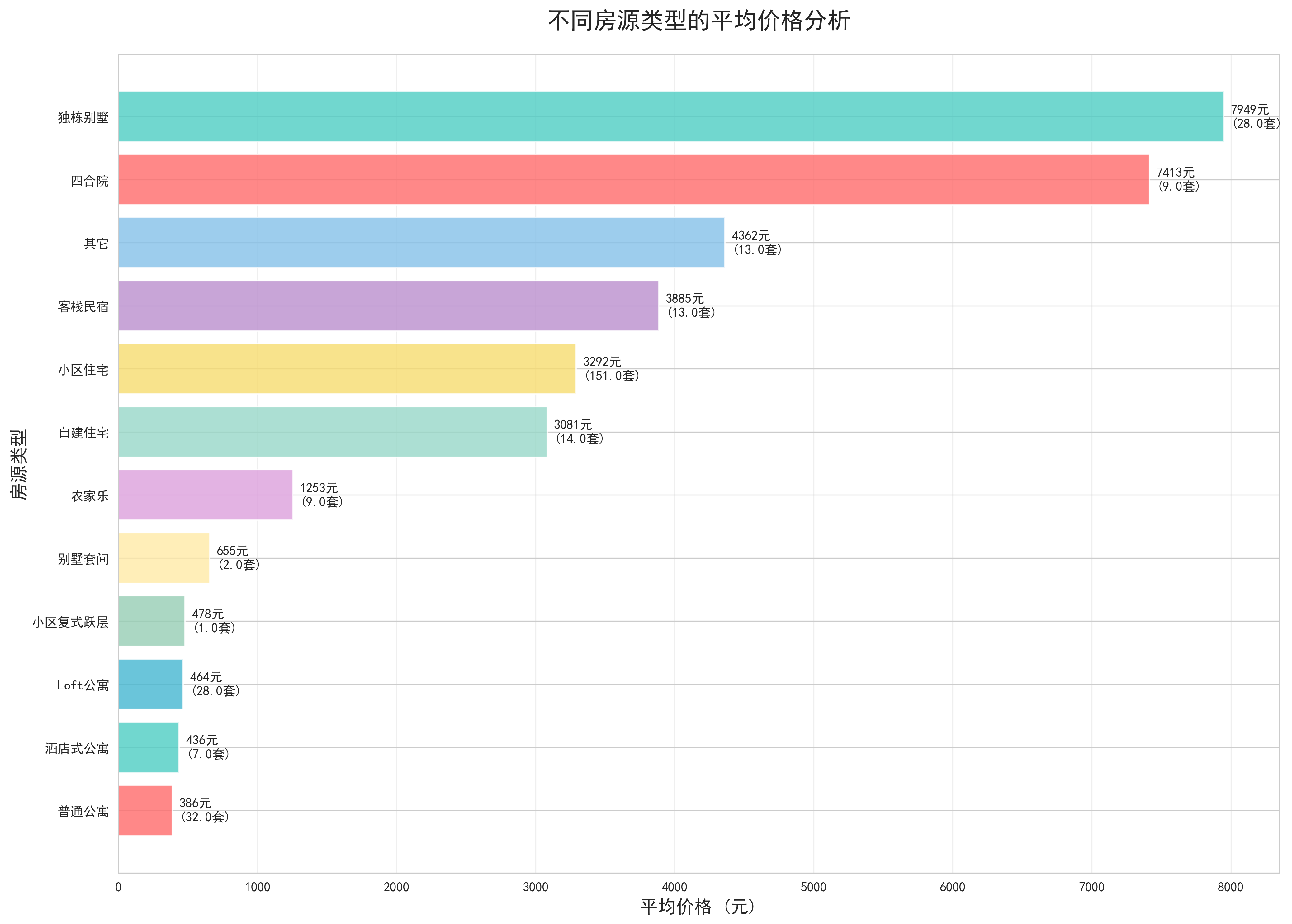
- 房源类型价格对比:采用箱线图展示了不同房源类型的价格分布特征。别墅类房源价格最高但分布最分散,公寓类房源价格适中且分布相对集中,民宿类房源价格偏低但具有较好的性价比。
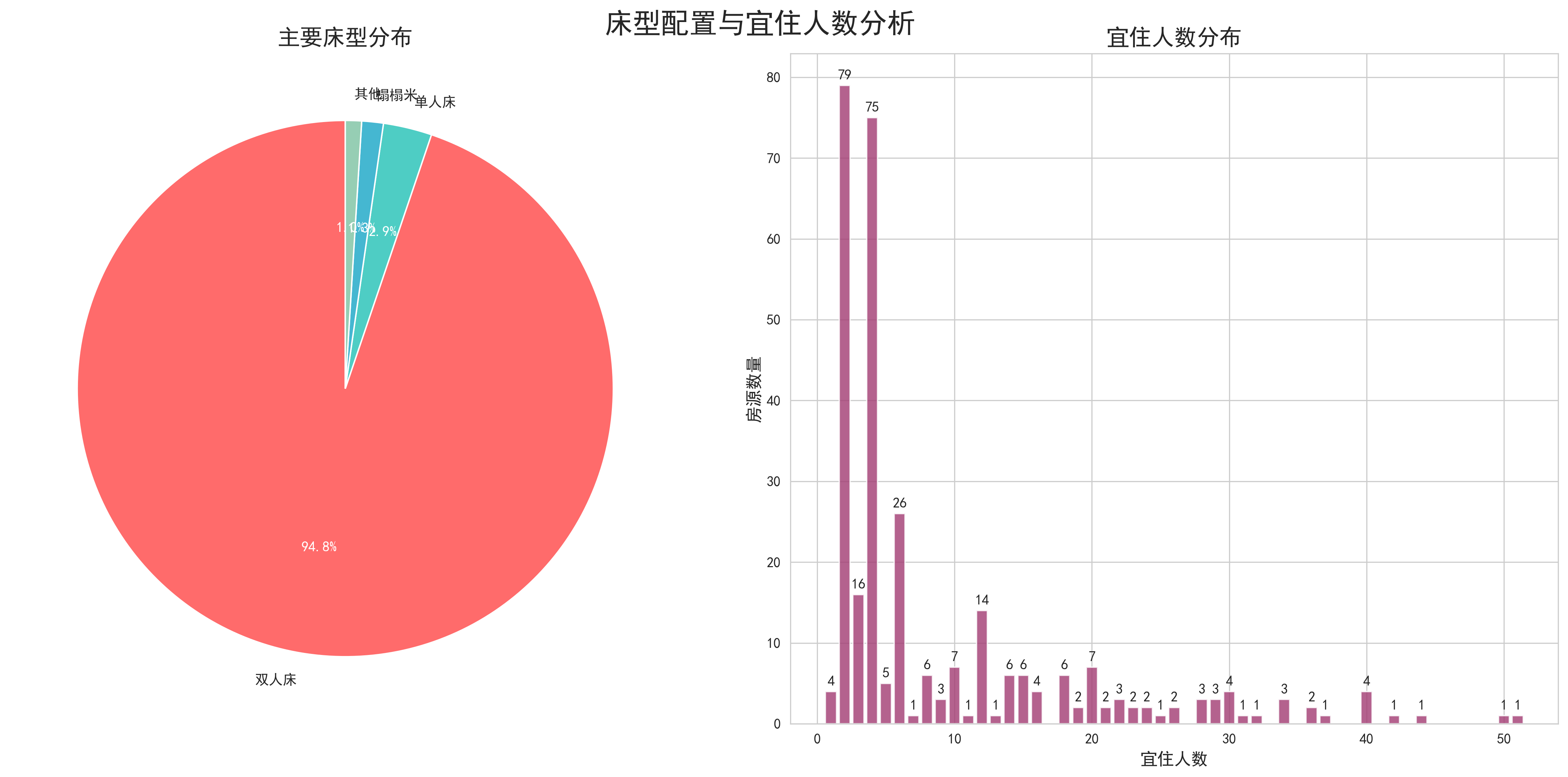
- 床型容量分析:通过堆叠柱状图分析了不同床型配置的受欢迎程度和价格特征。数据显示,标准双人床配置最受欢迎,多床位配置适合家庭出行,价格也相应较高。
4.4 用户评价口碑分析
用户评价是反映房源真实质量的重要指标,也是用户选择的重要参考。
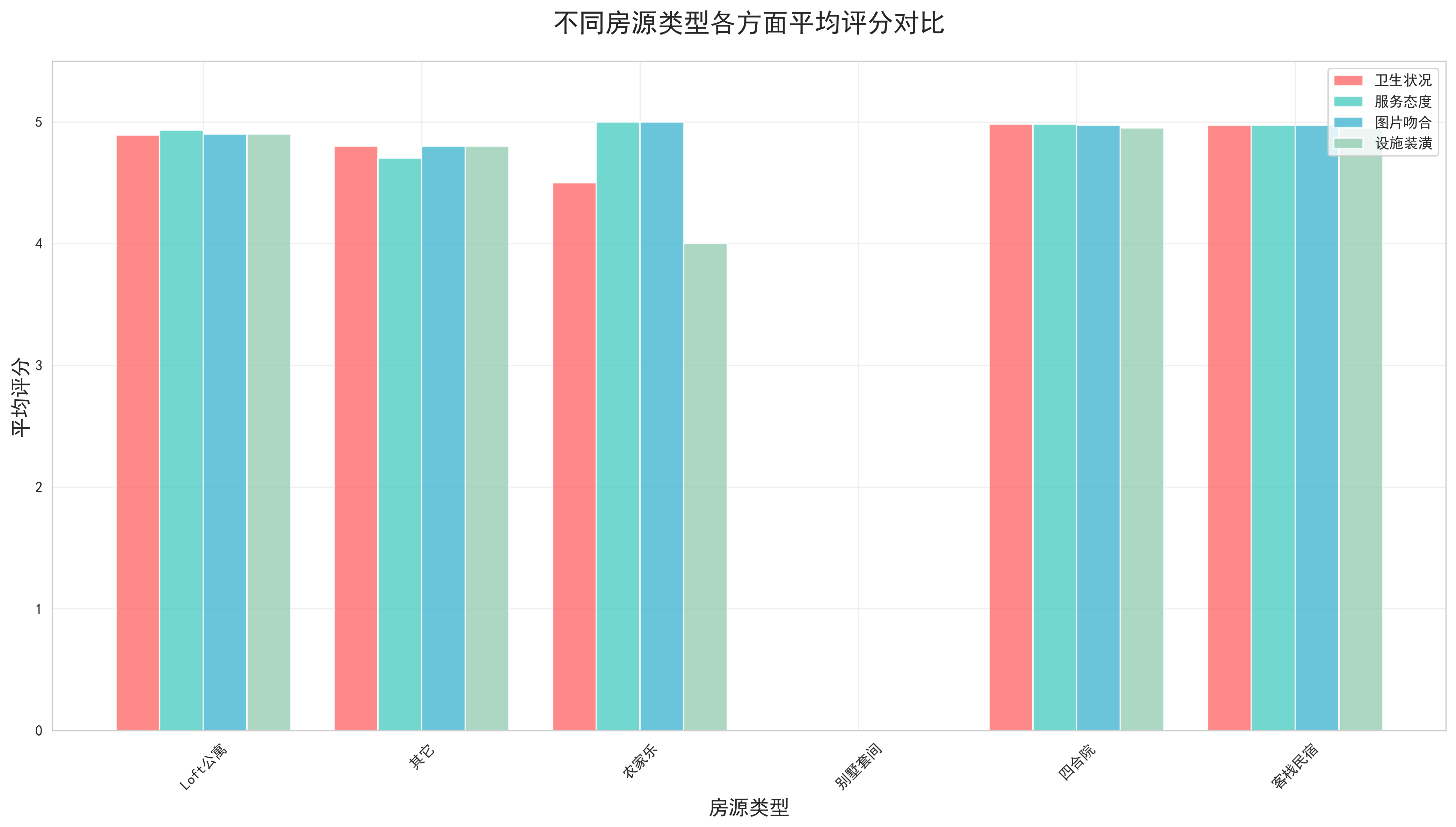

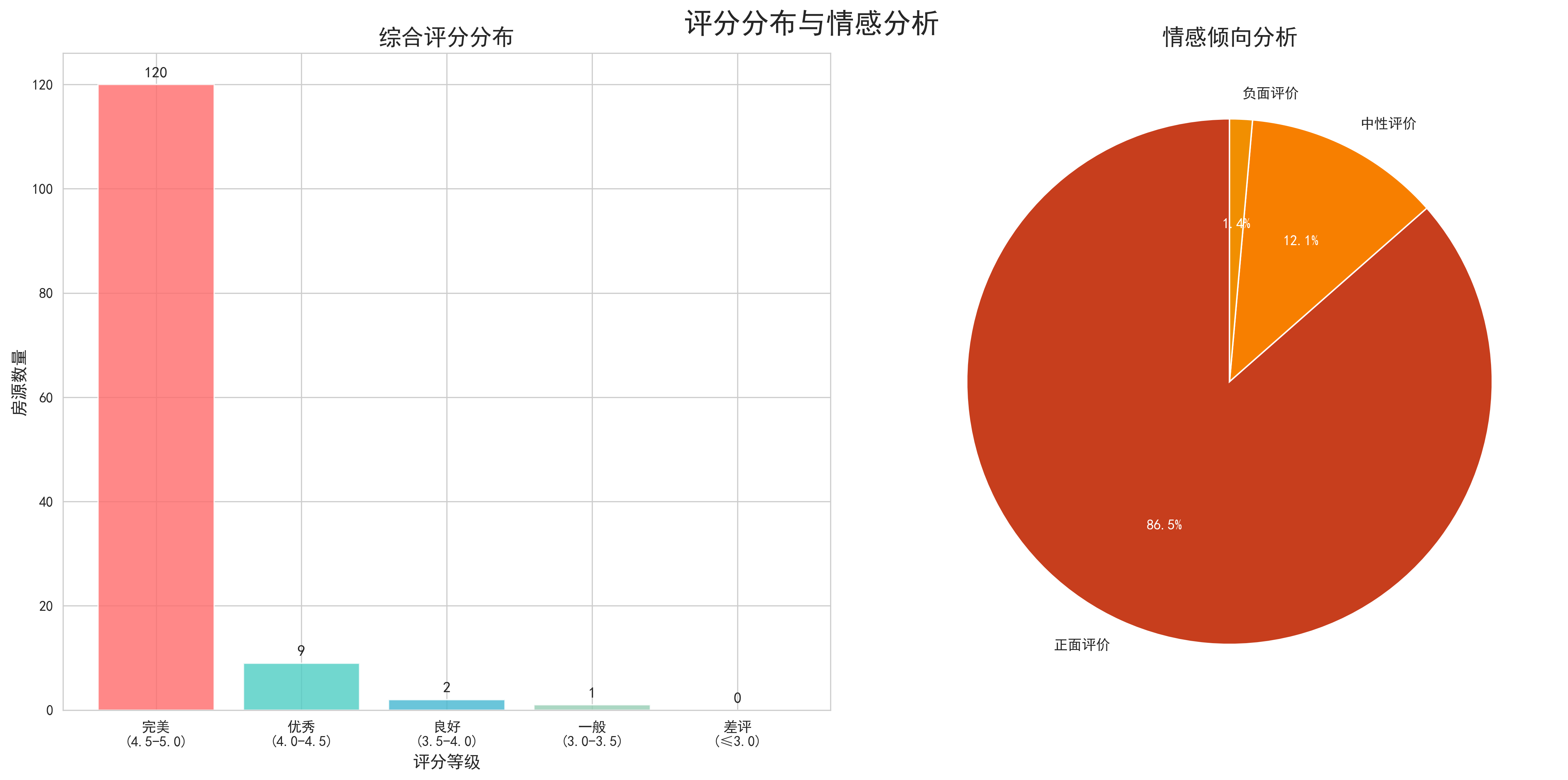
- 城市评分对比分析:通过雷达图展示了不同城市在各个评价维度上的表现。评价维度包括综合评分、卫生状况、服务态度、图片吻合度、设施装潢等。分析发现,各城市在不同维度上的表现存在差异,这为平台的差异化运营提供了数据支撑。
- 评论词云分析:通过jieba分词技术对用户评论进行文本分析,生成词云图展示高频词汇。正面评价中,"干净"、"方便"、"舒适"等词汇出现频率最高;负面评价中,"噪音"、"设施"、"服务"等问题被频繁提及。这为房东改善服务质量提供了明确的方向。
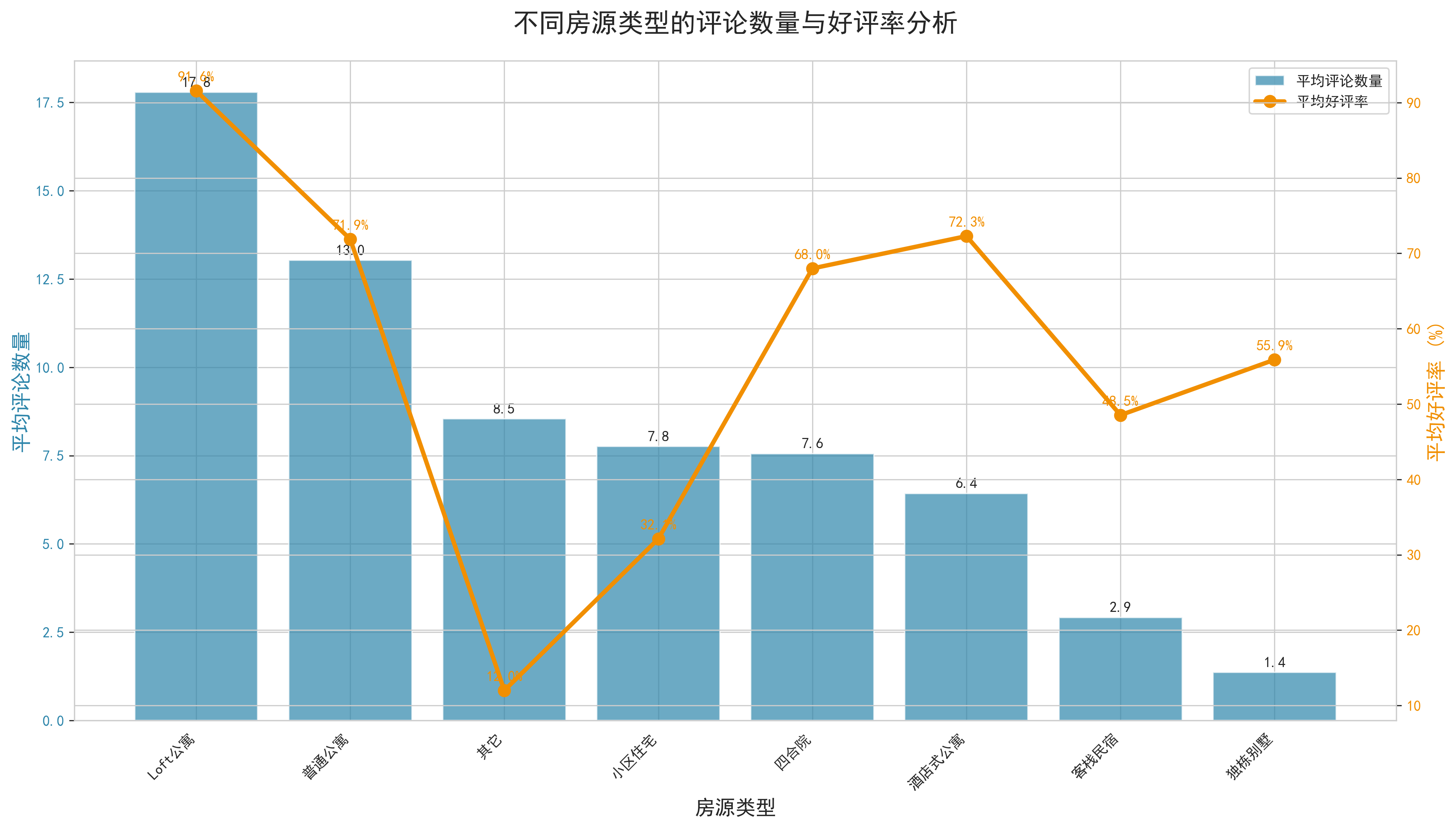
- 评论数量与好评率关系分析:通过散点图分析了评论数量与好评率的关系。数据显示,评论数量适中的房源往往具有较高的好评率,而评论数量过少或过多的房源好评率相对较低。这反映了用户评价的真实性和可信度问题。
4.5 可视化技术实现
在技术实现层面,系统采用了多种优化策略提升可视化效果。中文字体配置确保了图表中中文文字的正确显示。色彩方案设计兼顾了美观性和可读性,支持色盲用户的正常使用。图表尺寸和布局经过精心设计,适配不同屏幕尺寸的设备。
所有静态图表都以高分辨率PNG格式保存,支持在报告和演示中使用。动态图表支持多种交互操作,如缩放、筛选、钻取等,提升了用户的探索体验。
5. 系统设计与实现
5.1 系统架构设计
本系统采用经典的MVC(Model-View-Controller)架构模式,结合现代Web开发的最佳实践,构建了一个可扩展、可维护的系统架构。
- 数据层(Model):基于SQLAlchemy ORM框架设计,定义了用户、房源、评论、评分、收藏等核心数据模型。数据模型之间通过外键关系建立了完整的关联关系,支持复杂的查询操作。数据库设计遵循第三范式,确保数据的一致性和完整性。
- 业务逻辑层(Controller):基于Flask框架实现,提供了完整的RESTful API接口。业务逻辑层负责处理用户请求、数据验证、业务规则执行等核心功能。通过蓝图(Blueprint)机制实现了模块化的路由管理,提高了代码的组织性和可维护性。
- 表现层(View):采用Jinja2模板引擎和Bootstrap前端框架实现,提供了响应式的用户界面。前端采用Ajax技术实现异步数据交互,提升了用户体验。
5.2 核心功能模块
- 用户管理模块:实现了完整的用户注册、登录、个人资料管理功能。基于Flask-Login扩展实现会话管理,支持记住登录状态功能。密码采用Werkzeug提供的哈希算法进行加密存储,确保用户信息安全。
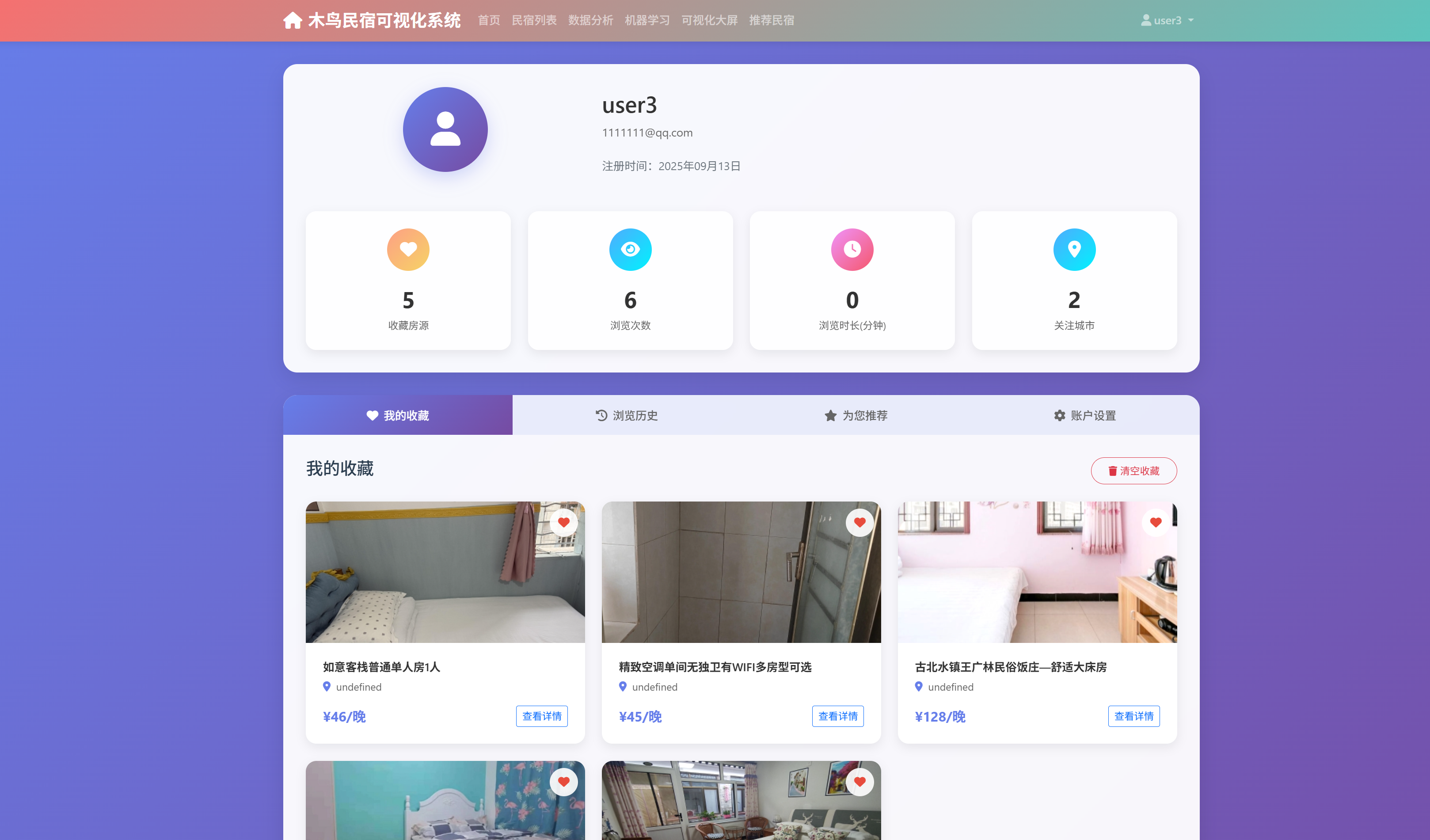
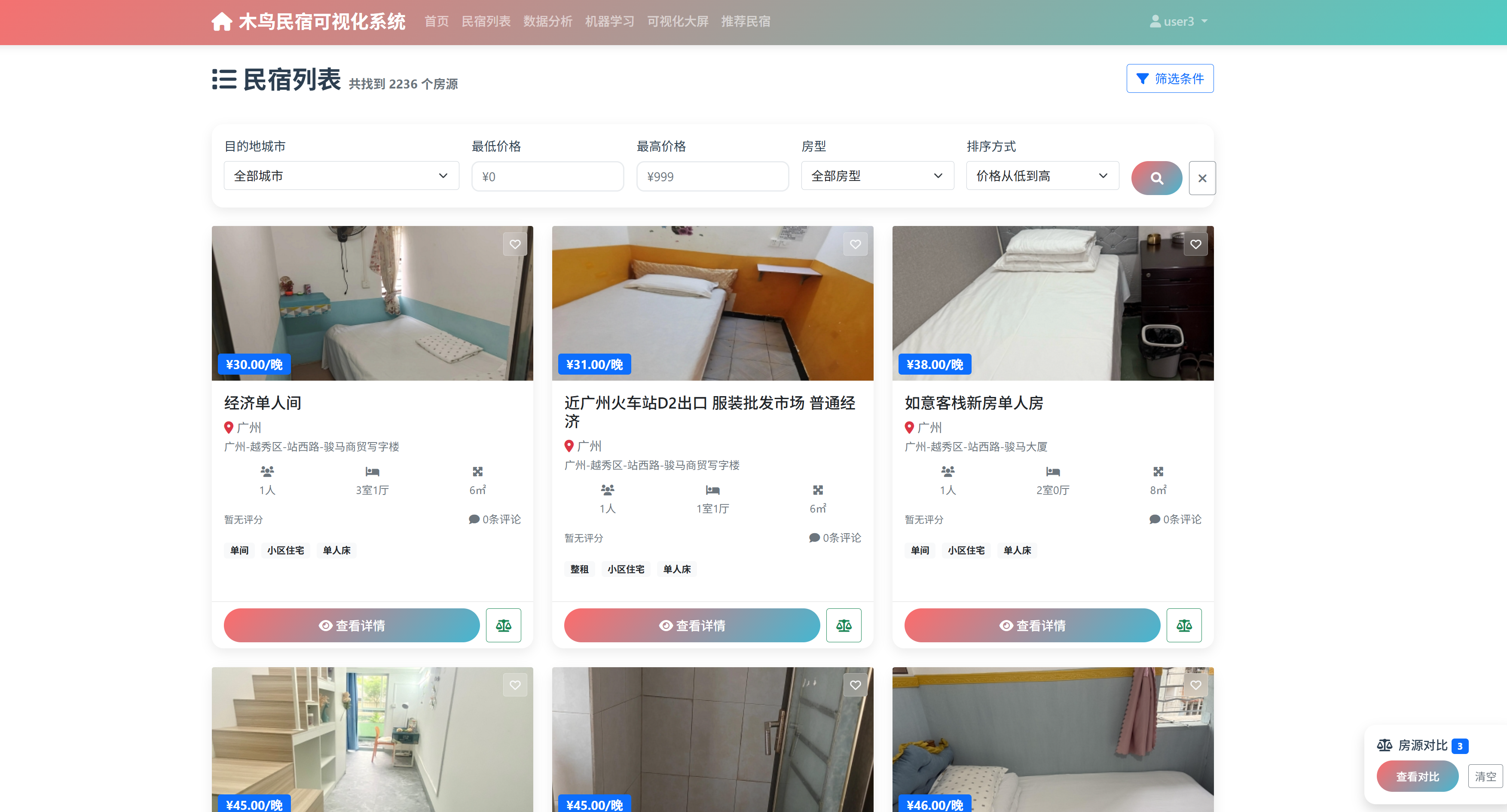
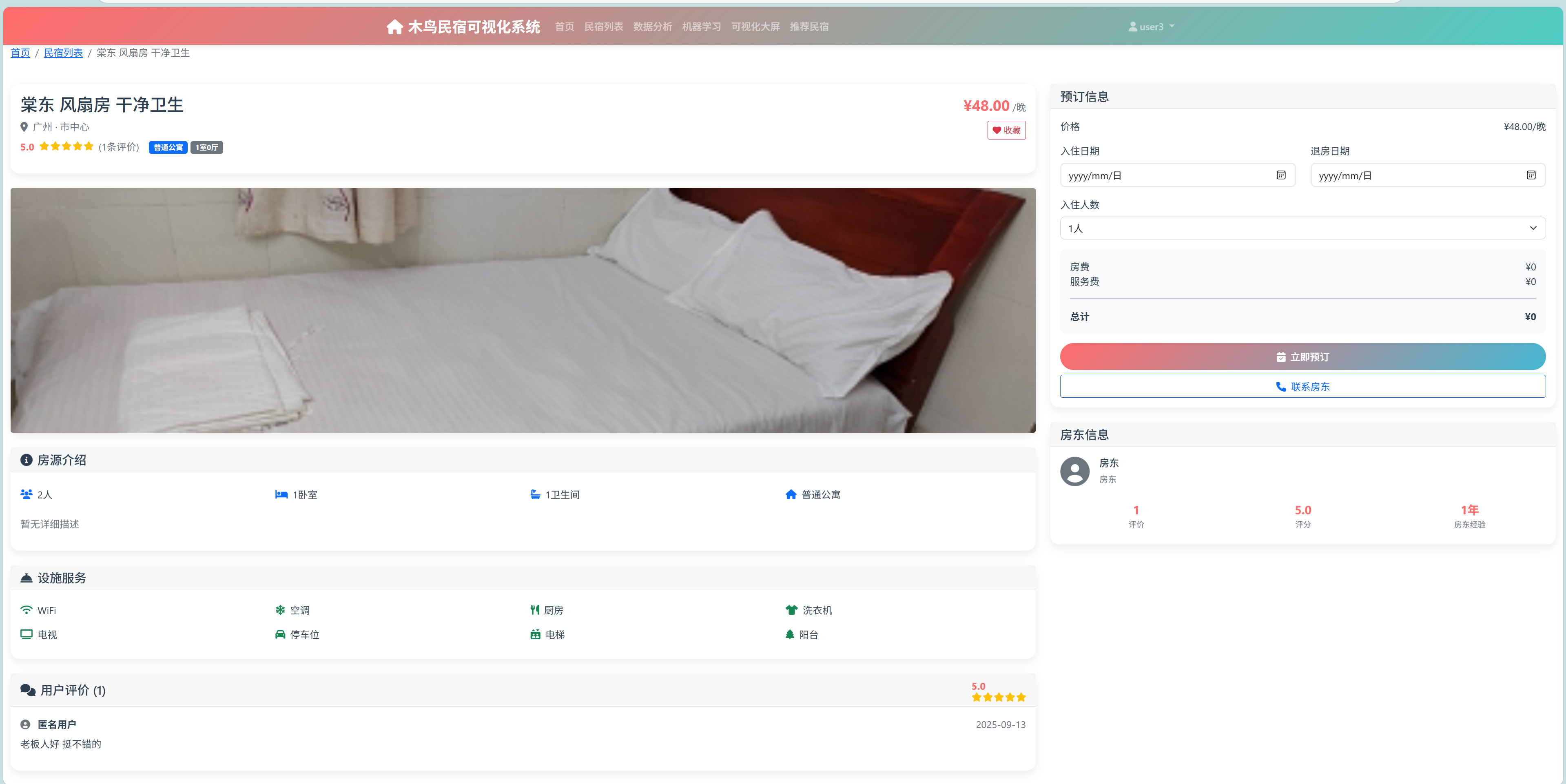
- 房源展示模块:提供了房源列表展示、详情查看、搜索筛选等功能。支持多维度的排序和筛选,包括价格、评分、地理位置等。房源详情页面集成了图片展示、评价统计、位置地图等丰富信息。
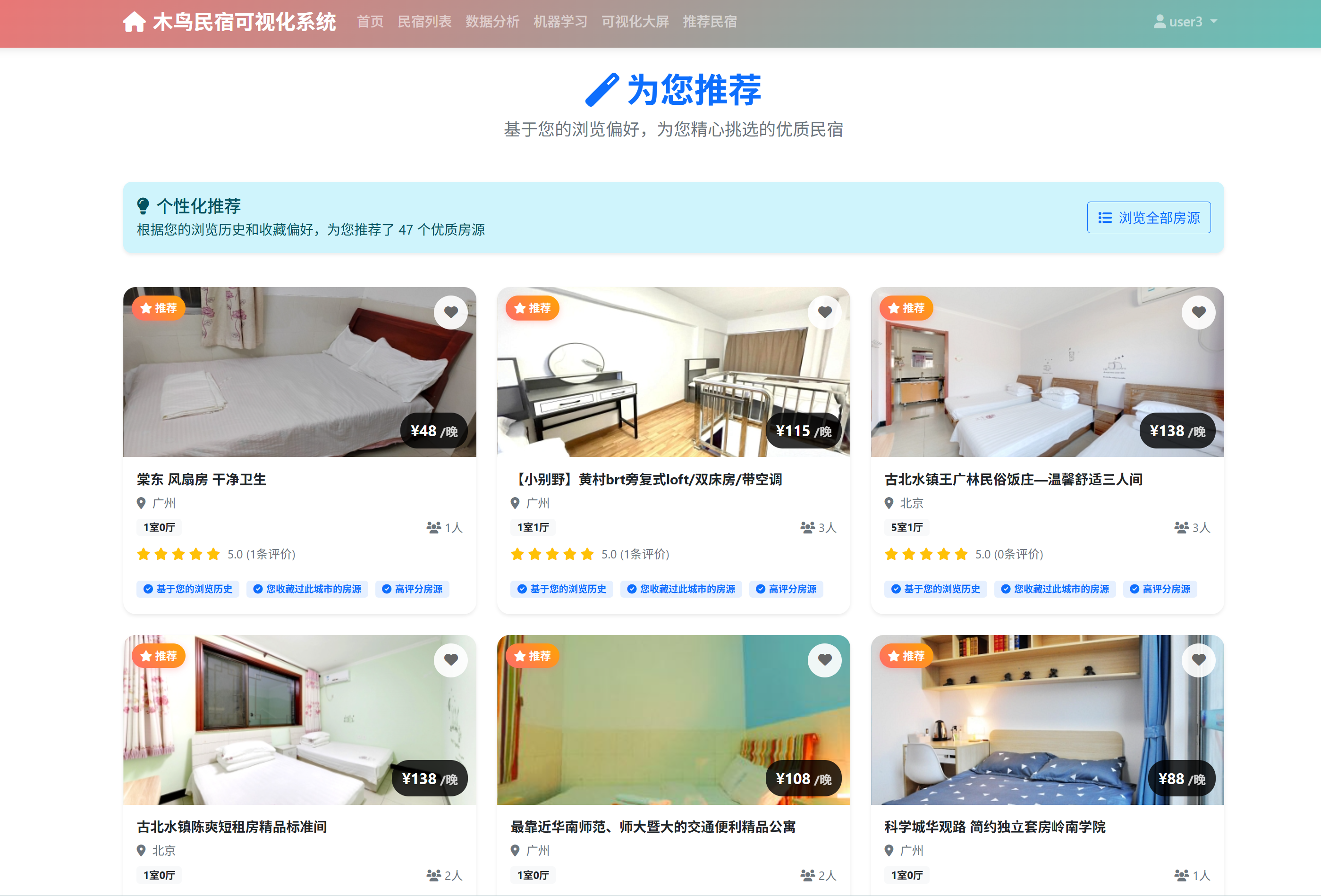
- 个性化推荐模块:基于协同过滤算法实现了智能推荐功能。系统分析用户的浏览历史、收藏记录等行为数据,结合房源的属性特征,为用户推荐可能感兴趣的房源。推荐算法支持实时更新,随着用户行为的变化动态调整推荐结果。
- 数据分析模块:提供了多维度的数据分析功能,包括市场概况分析、价格趋势分析、用户行为分析等。分析结果通过交互式图表的形式展示,支持用户自定义查询条件和时间范围。
5.3 机器学习集成
系统集成了多种机器学习算法,为用户提供智能化的数据分析服务。
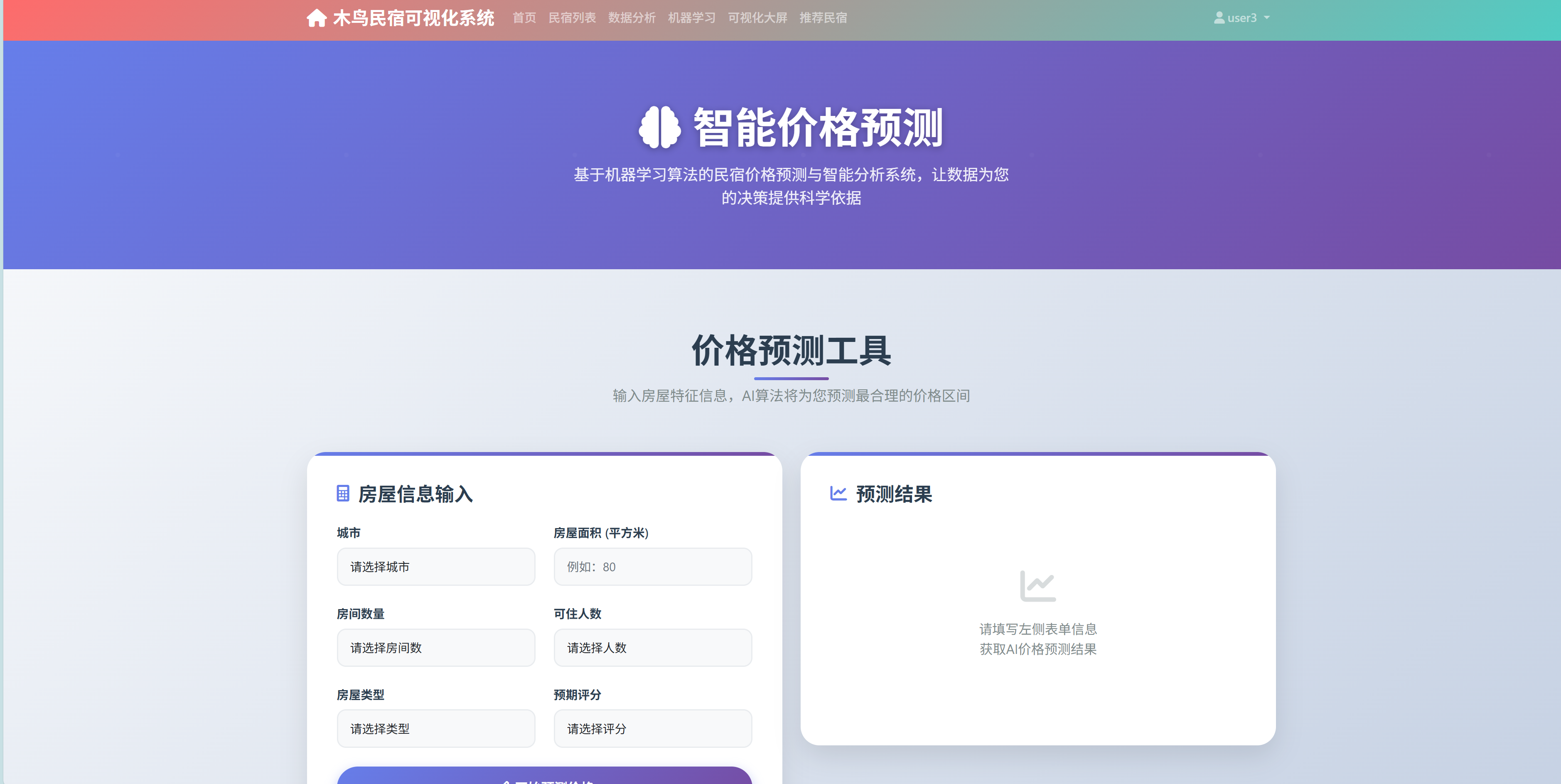
- 价格预测模型:基于随机森林和线性回归算法实现,能够根据房源的属性特征预测合理的价格区间。模型训练使用了历史房源数据,特征包括地理位置、房源类型、面积、设施配置等。模型性能通过交叉验证进行评估,R²值达到0.85以上,具有较好的预测准确性。
- 聚类分析功能:基于K-means算法对房源进行聚类分析,识别不同类型的房源群体。聚类结果可以帮助平台运营者了解市场细分情况,为精准营销提供数据支撑。聚类特征的可视化展示帮助用户理解不同房源群体的特点。
- 主成分分析(PCA):用于降维分析和特征重要性评估。通过PCA分析,识别出影响房源价格和受欢迎程度的关键因素,为房东优化房源配置提供指导。
5.4 数据可视化大屏
系统设计了专业的数据可视化大屏,适用于会议展示和监控中心场景。大屏采用深色主题设计,具有科技感和专业性。布局采用网格系统,合理分配各个图表的展示区域。
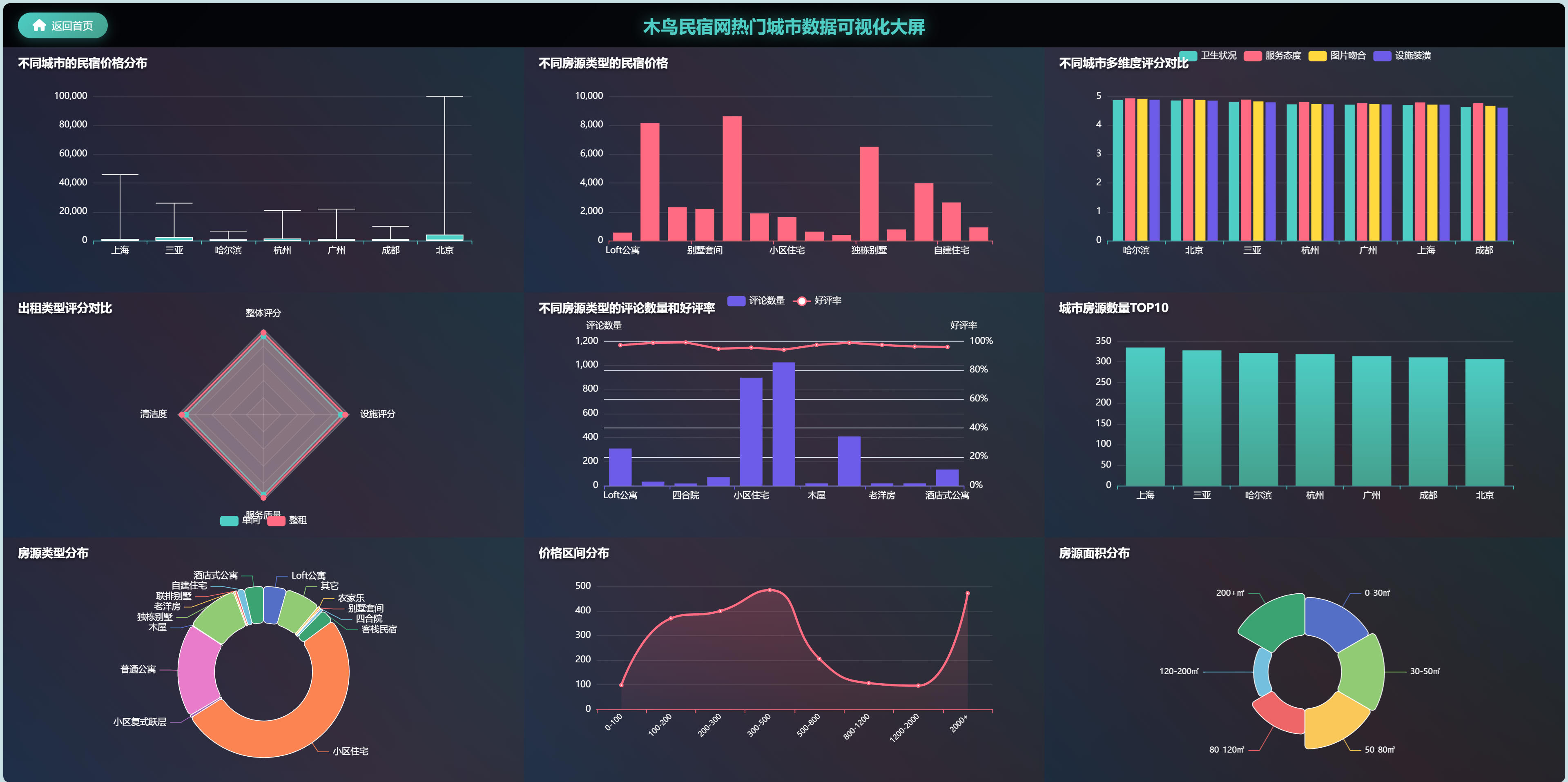
大屏集成了实时数据更新功能,能够展示最新的市场动态和用户行为数据。图表支持自动轮播和交互操作,适应不同的展示需求。响应式设计确保大屏在不同尺寸的显示设备上都能正常展示。
6. 总结与展望
6.1 项目成果
本项目成功构建了一个完整的木鸟民宿网数据分析及可视化系统,实现了从数据采集到智能分析的全流程自动化。系统共采集了7个热门城市的数万条房源数据和用户评论,生成了20余个维度的数据分析图表,为民宿行业的数据化运营提供了有力支撑。
技术层面,项目展现了Python在数据科学领域的强大能力,从网络爬虫到机器学习,从数据可视化到Web开发,形成了完整的技术栈应用案例。系统架构设计合理,代码结构清晰,具有良好的可扩展性和可维护性。
6.2 应用价值
对于平台运营者,系统提供的市场分析报告可以帮助制定更精准的运营策略,优化资源配置,提升平台竞争力。对于房东用户,价格预测和市场分析功能可以帮助制定合理的定价策略,提升房源的市场表现。对于租客用户,个性化推荐和数据对比功能可以帮助快速找到最适合的住宿选择。
6.3 技术创新点
项目在多个方面体现了技术创新。爬虫系统的反反爬虫策略确保了数据采集的稳定性;多维度的特征工程提升了数据分析的深度;机器学习算法的集成为系统增加了智能化特性;可视化大屏的设计提供了专业的数据展示方案。
6.4 未来发展方向
未来可以从以下几个方向进一步完善系统功能。首先是扩大数据采集范围,覆盖更多城市和平台,形成更全面的市场视图。其次是引入更先进的机器学习算法,如深度学习、自然语言处理等,提升分析的准确性和智能化水平。
在用户体验方面,可以开发移动端应用,提供更便捷的访问方式。在数据分析方面,可以引入实时数据流处理技术,实现真正的实时分析和预警功能。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)