Spring Boot通过EasyExcel异步多线程实现大数据量Excel导入,百万数据30秒
定义的线程池相当于是8个核心线程,任务队列是无界队列。线程数也是要在最后测试的时候取一个合适的值。/***/@Bean// 设置核心线程数// 设置最大线程数,当核心线程数满了且队列满了,会创建新的线程,直到达到最大线程数。而当前队列是无界队列,所以不会满,此处设置无效。直接使用默认值,无限大// 设置队列容量,默认为Integer.MAX_VALUE// 设置线程活跃时间(秒)// 设置默认线程
原创 小光xgblack IT小胡同 2023-02-19 12:24 发表于江苏
整体思路
整体思路很简单,就是在文件读取和数据多线程处理这两步发力
-
Excel数据分片读取
-
线程池异步处理数据
-
Mybatis-Plus批量存储
实现过程
使用EasyExcel分片读取Excel大文件
EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel
参照EasyExcel官方文档,实现自己的读文件监听器,只需要新建自己的监听器类并实现ReadListener 接口,为了通用性,可以使用泛型<T>,然后实现监听器方法。
其中BATCH_COUNT指定每个分片的数据条数,具体数值可以最后调试的时候自己测试,找到最佳的数据量,需要考虑到Mysql一条语句批量插入的数据条数太大也会影响速度。
invoke方法指定每个分片数据的处理方式,doAfterAllAnalysed方法与invoke 方法保持一致即可,它处理的就是文件最后剩余的不足一个分片的数据。
代码如下:
/*** @author xg BLACK* @date 2022/11/24 23:28* description: EXCEL页面读取监听器*/@Slf4jpublic class GeoPageReadListener<T> implements ReadListener<T> {/*** 单个处理数据量,经测试1000条数据效果较好*/public static int BATCH_COUNT = 1000;/*** 数据的临时存储*/private List<T> cachedDataList = new ArrayList<>(BATCH_COUNT);/*** consumer*/private final Consumer<List<T>> consumer;public GeoPageReadListener(Consumer<List<T>> consumer) {this.consumer = consumer;}@Overridepublic void invoke(T data, AnalysisContext context) {cachedDataList.add(data);if (cachedDataList.size() >= BATCH_COUNT) {log.info("读取数据量:{}", cachedDataList.size());consumer.accept(cachedDataList);cachedDataList = new ArrayList(BATCH_COUNT);}}/*** 所有数据读取完成之后调用** @param context*/@Overridepublic void doAfterAllAnalysed(AnalysisContext context) {if (CollectionUtils.isNotEmpty(cachedDataList)) {//处理剩余的数据log.info("读取数据量:{}", cachedDataList.size());consumer.accept(cachedDataList);}}}
定义线程池
定义的线程池相当于是8个核心线程,任务队列是无界队列。线程数也是要在最后测试的时候取一个合适的值。
/*** @author xg BLACK* @date 2022/11/25 03:18* description:*/@Configurationpublic class GeoAsyncConfiguration {@Beanpublic TaskExecutor taskExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();// 设置核心线程数executor.setCorePoolSize(8);// 设置最大线程数,当核心线程数满了且队列满了,会创建新的线程,直到达到最大线程数。而当前队列是无界队列,所以不会满,此处设置无效。直接使用默认值,无限大//executor.setMaxPoolSize(16);// 设置队列容量,默认为Integer.MAX_VALUE//executor.setQueueCapacity(10000);// 设置线程活跃时间(秒)executor.setKeepAliveSeconds(60);// 设置默认线程名称executor.setThreadNamePrefix("geo-admin-thread-");// 设置拒绝策略。无界队列不会出现满的情况,所以不配置存储策略。直接抛出 RejectedExecutionException 异常//executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());// 等待所有任务结束后再关闭线程池executor.setWaitForTasksToCompleteOnShutdown(true);return executor;}}
实现真正的批量插入
经过查看日志发现Mybatis-Plus的saveBatch在最后还是循环调用的INSERT INTO语句,这种情况下,测试多线程速度和单线程相差不大,所以需要实现真正的批量插入语句,两种方式,一种是在xml文件中自己拼接SQL语句,一种是通过给Mybatis-Plus注入器,增强批量插入。
这里是用的是增强注入器的方式,最后执行批量插入的时候是将所有数据拼接到一条SQL里面了。
/*** @author xg BLACK* @date 2022/11/25 11:00* description: mybatis-plus SQL注入器,增强批量插入*/@Componentpublic class BatchSqlInjector extends DefaultSqlInjector {@Overridepublic List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {//MyBatis-Plus默认方法List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo);//注入InsertBatchSomeColumn。官方标注此处只通过MySQL测试,其他数据库未测试 <https://gitee.com/baomidou/mybatis-plus/blob/3.0/mybatis-plus-extension/src/main/java/com/baomidou/mybatisplus/extension/injector/methods/InsertBatchSomeColumn.java>//在当前当前项目中,pg库测试可用//例1: t -> !t.isLogicDelete() , 表示不要逻辑删除字段//例2: t -> !t.getProperty().equals("version") , 表示不要字段名为 version 的字段//例3: t -> t.getFieldFill() != FieldFill.UPDATE) , 表示不要填充策略为 UPDATE 的字段methodList.add(new InsertBatchSomeColumn(t -> !t.getProperty().equals("version")));return methodList;}}
自定义SpiceBaseMapper,并继承BaseMapper,这样在BaseMapper功能都能实现的基础上,在SpiceBaseMapper上增加新的批量插入方法。
/*** @author xg BLACK* @date 2022/11/25 11:06* description:*/@Service@Componentpublic interface SpiceBaseMapper<T> extends BaseMapper<T> {/*** 批量插入* @param entityList* @return*/int insertBatchSomeColumn(List<T> entityList);}接下来,像使用BaseMapper一样使用就可以/*** @author xg BLACK* @date 2022/11/25 11:08* description:*/@Mapper@Componentpublic interface DataSwMbqcdssBatchInsertMapper extends SpiceBaseMapper<DataSwMbqcdssDO> {}整体流程Controller中接口@PostMapping("/create-sw-mbqcdss")//@ApiOperation("创建数据源并导入密闭墙点实时数据")//swagger注解,可以删掉//@PreAuthorize("@ss.hasPermission('geo:function-datasource:create')")//校验接口权限,可以删掉public CommonResult<DataExcelImportRespVO> createFunctionDatasourceAndSwMbqcdss(@Valid FunctionDatasourceCreateReqVO createReqVO, @RequestParam("file") MultipartFile file) throws IOException, ExecutionException, InterruptedException {long filesize = file.getSize();log.info("导入文件大小:{}k",filesize / 1024);return success(functionDatasourceService.createFunctionDatasourceAndSwMbqcdss(createReqVO,file));}Service接口/*** 创建数据源密闭墙点实时数据** @param createReqVO 创建信息* @param file 要保存的数据* @return 导出响应对象*/DataExcelImportRespVO createFunctionDatasourceAndSwMbqcdss(@Valid FunctionDatasourceCreateReqVO createReqVO, MultipartFile file) throws IOException, ExecutionException, InterruptedException;ServiceImpl实现类@Override@Transactional(rollbackFor = Exception.class) // 添加事务,异常则回滚所有导入public DataExcelImportRespVO createFunctionDatasourceAndSwMbqcdss(FunctionDatasourceCreateReqVO createReqVO, MultipartFile file) throws IOException, ExecutionException, InterruptedException {//新增数据源,或者idFunctionDatasourceDO functionDatasource = FunctionDatasourceConvert.INSTANCE.convert(createReqVO);functionDatasourceMapper.insert(functionDatasource);Long id = functionDatasource.getId();//获取当前登录用户Long loginUserId = SecurityFrameworkUtils.getLoginUserId();//开始计时TimeInterval timer = DateUtil.timer();//DataExcelImportRespVO respVO = readExcelAndSave(DataSwMbqcdssImportExcelVO.class, file, data -> DataSwMbqcdssConvert.INSTANCE.convert(data).setDsId(id), dataSwMbqcdssInsertMapper::saveBatch);DataExcelImportRespVO respVO = readExcelAndSaveAsync(DataSwMbqcdssImportExcelVO.class,file,data -> {DataSwMbqcdssDO newDo = DataSwMbqcdssConvert.INSTANCE.convert(data).setDsId(id);//数据预处理,因为目前的批处理方法不会再自动填充数据,所以这里手动填充newDo.setCreator(String.valueOf(loginUserId));newDo.setUpdater(String.valueOf(loginUserId));newDo.setDeleted(false);return newDo;},dataSwMbqcdssBatchInsertMapper::insertBatchSomeColumn);//结束计时long interval = timer.interval();log.info("导入数据共花费:{}s", interval / 1000);respVO.setTime(interval);// 存储文件saveDsFile(id,file);return respVO;}
只关注开始计时到计时结束中间的部分即可,其他都是一些业务需要的处理。
因为需要大数据量导入的数据类不止一个,所以将异步多线程导入数据readExcelAndSaveAsync单独提取出来封装了一个方法。参数分别为hea:Excel导入实体类的class;file:要导入的Excel文件;function:函数型函数式接口,数据处理函数,对数据加工操作(除了业务相关的数据处理操作,如果原本有使用Mybatis-Plus的自动填充,此时需要手动填充,因为自定义注入器实现的批量插入不会自动填充);dbFunction:函数型函数式接口,数据库操作方法,即上面定义的批量插入方法;
泛型<T> Excel导入实体类 例如DataSwMbqcdssImportExcelVO
泛型<R> 数据库实体类 例如DataSwMbqcdssDO
/*** 异步多线程导入数据* 采用自定义注入mybatis-plus的SQL注入器,实现真正的BatchInsert,但是需要注意的是项目配置文件需要在jdbc的url后面加上rewriteBatchedStatements=true* @param head Excel导入实体类的class* @param file 要导入的Excel文件* @param function 数据处理函数,对数据加工* @param dbFunction 数据库操作* @return 导入结果* @param <T> Excel导入实体类 例如DataSwMbqcdssImportExcelVO* @param <R> 数据库实体类 例如DataSwMbqcdssDO* @throws IOException* @throws ExecutionException* @throws InterruptedException*/private <T,R> DataExcelImportRespVO readExcelAndSaveAsync(Class<T> head, MultipartFile file, Function<T,R> function, Function<List<R>,Integer> dbFunction) throws IOException, ExecutionException, InterruptedException {Integer successCount = 0;Integer failCount = 0;//存储异步线程的执行结果Collection<Future<int[]>> futures = new ArrayList<Future<int[]>>();EasyExcel.read(file.getInputStream(), head, new GeoPageReadListener<T>(dataList -> {//转换DO,并设置数据源idList<R> list = dataList.parallelStream().map(function).collect(Collectors.toList());//异步批量插入futures.add(functionDatasourceAsyncService.saveAsyncBatch(list,dbFunction));})).sheet().doRead();//等待异步线程执行完毕for (Future<int[]> future : futures) {int[] counts = future.get();successCount += counts[0];failCount += counts[1];}log.info("存储成功总数据量:{},存储失败总数据量:{}", successCount,failCount);DataExcelImportRespVO respVO = DataExcelImportRespVO.builder().successCount(successCount).failCount(failCount).build();return respVO;}
DataExcelImportRespVO是导入结果类,里面存储成功数量和失败数量
/*** @author xg BLACK* @date 2022/11/1 15:20* description:*/@ApiModel("管理后台 - 数据导入 Response VO")@Data@Builderpublic class DataExcelImportRespVO {@ApiModelProperty(value = "导入成功的数量")private Integer successCount;@ApiModelProperty(value = "导入失败的数量")private Integer failCount;@ApiModelProperty(value = "导入用时")private Long time;}
异步存储,使用@Async 异步存储,主线程通过Future<int[]>等待线程返回结果
/*** 批量插入* @param list 要分批处理的数据* @param dbFunction 数据库操作的方法* @param <T> 数据库实体类* @return 返回处理结果*/@Asyncpublic <T> Future<int[]> saveAsyncBatch(List<T> list, Function<List<T>,Integer> dbFunction) {int size = list.size();int[] result = new int[2];log.info("saveAsyncBatch当前数据分片大小 size:{}",size);try {if (dbFunction.apply(list) > 0) {result[0] = size;log.info("{} 分片存储数据成功,数据量:{}",Thread.currentThread().getName(), size);} else {result[1] = size;log.info("{} 分片存储数据失败:{}",Thread.currentThread().getName(), size);}}catch (Exception e){result[1] = size;log.error("{} 分片存储数据出现异常,{}",Thread.currentThread().getName(),e.getMessage());}return new AsyncResult<int[]>(result);}
其他优化
需要根据测试结果慢慢的调整,需要优化的点如下:
-
分片数据大小
-
线程数
-
数据库连接池的连接数
-
数据库和程序之间的网络通信情况
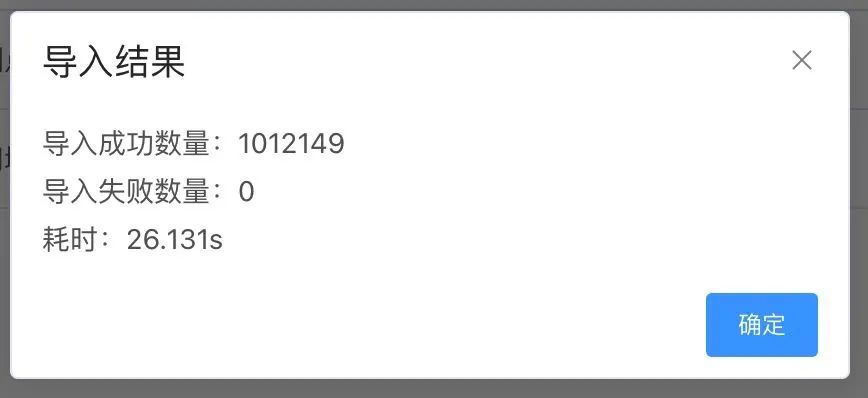
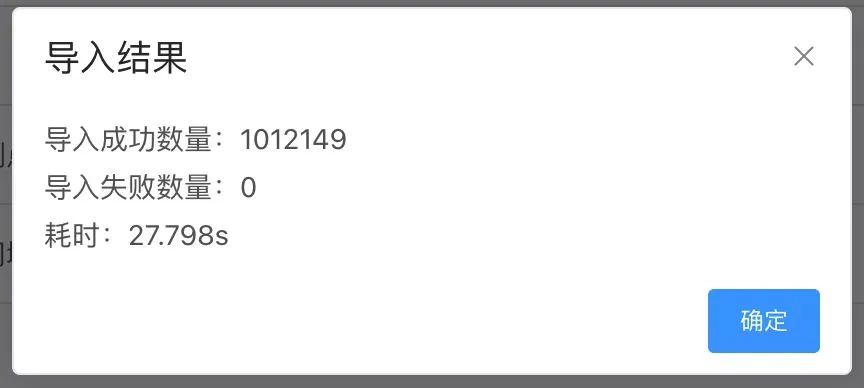
总结
其实整体思路很简单,其中几个关键点就是多线程和实现真正的批量插入。线程也不是越多越好,过犹不及,合适的才是最好的。

小光xgblack

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)