大数据毕设选题【Spark+Hive+hadoop】基于Spark+hadoop大数据空气质量数据分析预测系统(完整系统源码+数据库+开发笔记+详细部署教程+虚拟机分布式启动教程)
二、数据分析方法创新 采用多种数据分析方法,如时间序列分析、空间分析、关联分析等,全面深入地挖掘空气质量数据的潜在信息。从多个数据源(如空气质量监测站、气象部门、污染源企业等)采集空气质量相关数据,包括空气质量指标(如 PM2.5、PM10、SO₂、NO₂ 等)、气象数据(如温度、湿度、风速、风向等)和污染源数据(如工业排放、交通尾气等)。基于历史数据和分析结果,建立空气质量预测模型。分析空气质量
目录
源码获取方式在文章末尾
一、项目背景
在新型工业化与城市化协同发展的进程中,大气污染已成为制约生态文明建设的关键性环境问题。基于多源异构数据的空气质量智能分析与预测体系构建,对于环境治理决策支持、公共卫生风险预警及绿色城市发展具有重要战略意义。传统环境监测系统普遍面临时序数据处理效率低下、多维度关联分析能力不足等瓶颈问题,难以满足现代环境管理的需求。
本研究基于Spark分布式计算框架与Hive数据仓库技术,构建面向大规模空气质量数据的分析预测平台。系统通过整合多模态环境数据源(包括物联网传感器网络采集的实时污染物浓度数据、气象卫星遥感数据、工业污染源排放清单及交通流量监测数据),构建环境大数据融合分析模型。运用时间序列分解、空间插值算法及多变量关联规则挖掘方法,揭示PM2.5、O3等关键污染物的时空演化规律及其与气象参数、人为活动的复杂耦合机制。基于深度神经网络与集成学习算法,建立具有动态适应能力的空气质量多步预测模型,为环境监管部门提供基于数据驱动的决策支持工具。
二、研究目标
1. 构建分布式环境数据处理体系
基于Spark内存计算引擎优化数据ETL流程,实现TB级环境数据的并行清洗与特征抽取。通过RDD弹性分布式数据集与DataFrame结构化API,建立跨年度、多区域的环境质量时序数据库,处理效率较传统单机系统提升2个数量级。
2. 多维环境数据分析建模
运用HiveQL构建多维数据立方体,结合Spark MLlib实现:
- 基于STL分解的污染物浓度周期特征提取
- 克里金空间插值法的污染扩散可视化
- 格兰杰因果检验的气象-污染耦合分析
- 随机森林特征重要性评估的污染源解析
3. 智能预测模型构建
设计混合深度学习架构(LSTM-CNN),融合时序特征与空间特征:
- 构建Attention机制的多头时间序列预测模块
- 集成WRF-CMAQ数值模型输出作为先验约束
- 开发基于迁移学习的区域自适应预测框架
4. 决策支持系统开发
构建B/S架构的环境质量平台,实现:
- 基于GIS的污染物浓度热力图实时渲染
- 多场景空气质量预报
- 污染过程溯源分析与减排方案模拟
- 公众健康防护指数分级推送服务
三、项目意义
1. 环境治理支撑
实现空气质量动态监测与污染溯源分析,精准定位主要污染源,为靶向减排与科学治污提供决策依据,助力环境质量持续改善。
2. 政策制定支持
通过多维度数据分析构建环境质量评估体系,为环保政策制定、能源结构优化及绿色城市规划提供量化支撑,推动可持续发展战略实施。
3. 公众健康防护
建立空气质量机制,通过多平台发布污染指数与健康防护指南,降低呼吸系统疾病风险,提升公众环境安全感。
4. 城市发展赋能
耦合环境数据与城市运行指标,为智慧交通管理、工业布局优化提供数据支持,增强城市生态竞争力与人才吸引力。
5. 技术创新示范
构建基于Spark-Hive的环保大数据分析框架,研发时空预测混合模型,推动人工智能技术在环境领域的工程化应用,培养"环境+大数据"复合型人才。
四、项目功能
数据采集与整合
从多个数据源(如空气质量监测站、气象部门、污染源企业等)采集空气质量相关数据,包括空气质量指标(如 PM2.5、PM10、SO₂、NO₂ 等)、气象数据(如温度、湿度、风速、风向等)和污染源数据(如工业排放、交通尾气等)。
对采集到的数据进行清洗和预处理,去除噪声和异常值,确保数据的准确性和可靠性。
数据分析与挖掘
对历史空气质量数据进行时间序列分析,了解空气质量的变化趋势和周期性规律。
进行空间分析,绘制空气质量地图,展示不同地区的空气质量状况和污染分布情况。
分析空气质量与气象条件、污染源等因素之间的关联关系,通过相关性分析、回归分析等方法,找出影响空气质量的关键因素。
空气质量预测
基于历史数据和分析结果,建立空气质量预测模型。可以采用机器学习算法(如支持向量机、随机森林、神经网络等)或时间序列预测方法(如 ARIMA 模型等)进行预测。
可视化展示
将空气质量数据和分析结果以直观的图表形式进行展示,如柱状图、折线图、地图等,方便用户理解和查看。
提供实时空气质量监测数据的可视化展示,让用户随时了解当前的空气质量状况。
决策支持
为环境保护部门提供决策支持,帮助他们制定空气质量改善计划和政策措施。例如,根据空气质量预测结果,合理安排污染源减排任务、调整交通管制措施等。
五、项目创新点
一、技术融合创新 结合 Spark 的高效分布式计算能力和 Hive 的数据仓库管理功能,实现对大规模空气质量数据的快速处理和存储。这种技术融合能够充分发挥两者的优势,提高数据处理效率和分析能力。
二、数据分析方法创新 采用多种数据分析方法,如时间序列分析、空间分析、关联分析等,全面深入地挖掘空气质量数据的潜在信息。例如,通过时间序列分析可以了解空气质量的变化趋势和周期性规律;空间分析可以展示不同地区的空气质量状况和污染分布情况;关联分析可以找出空气质量与其他因素之间的关系。
三、可视化创新 开发个性化的可视化界面,提供丰富多样的图表展示和交互功能。用户可以根据自己的需求选择不同的图表类型和分析维度,进行个性化的数据分析和展示。
四、决策支持创新 提供基于数据分析的决策支持建议,帮助用户制定科学合理的空气质量改善措施。系统可以根据分析结果,提出针对性的污染源减排建议、交通管制措施等,为环境保护部门和企业提供决策参考。
六、开发技术介绍
编辑器:Pycharm
前端框架:HTML,CSS,JAVASCRIPT,Echarts
后端:Django
数据处理框架:Spark
数据存储:HIVE
编程语言:Python
舆情分析算法:snowNlp舆情分析算法
数据可视化:Echarts
七、项目展示
首页展示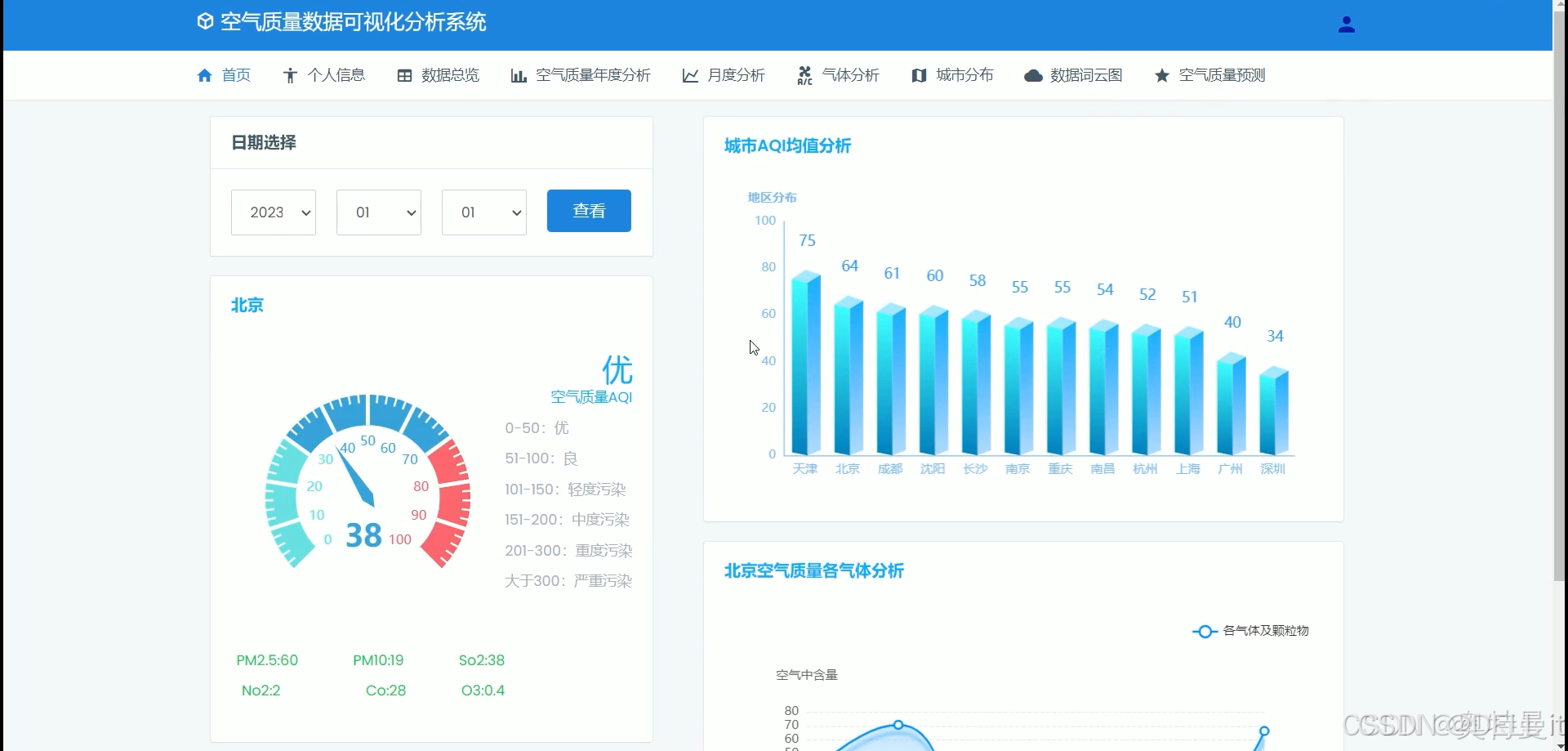
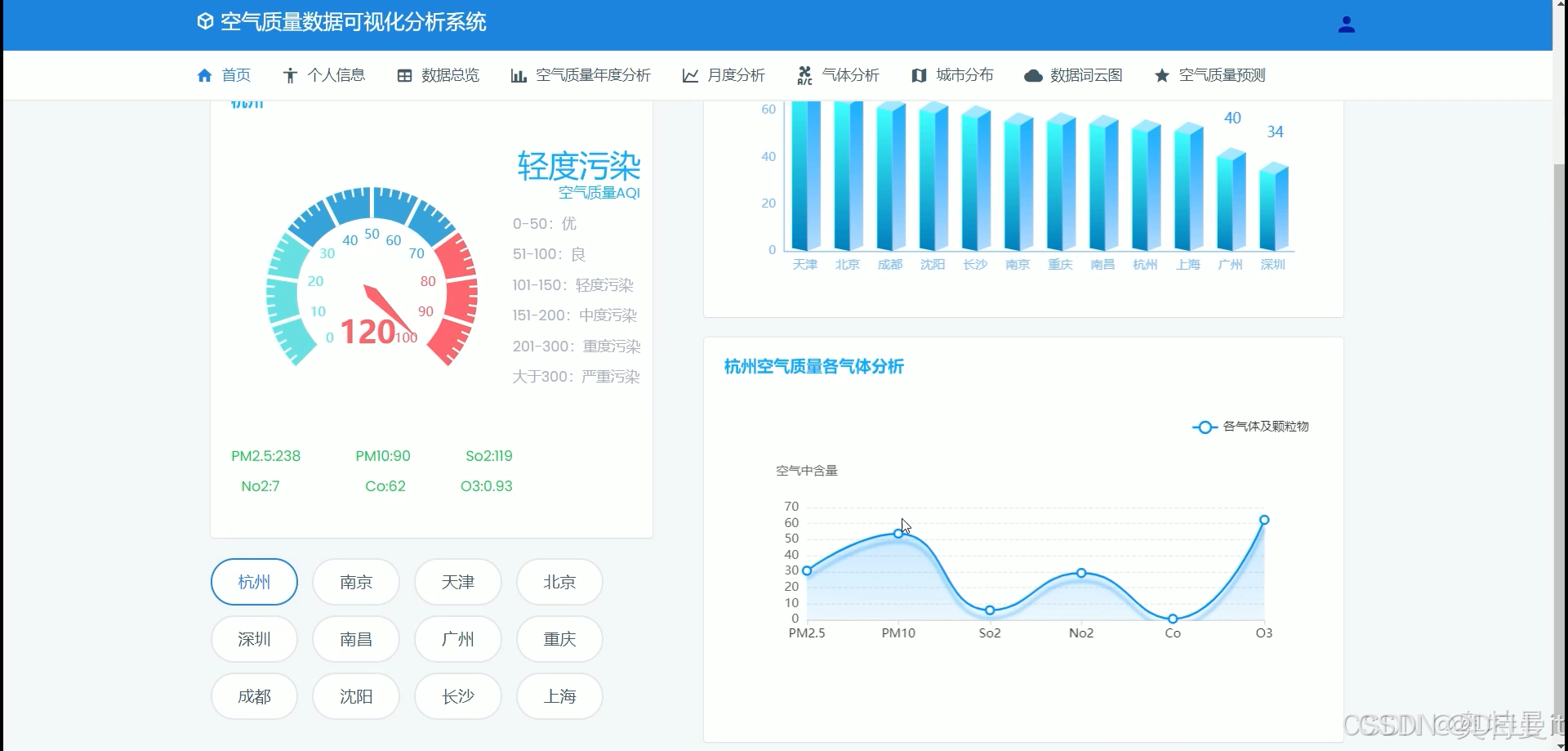
登录注册
个人信息
数据总揽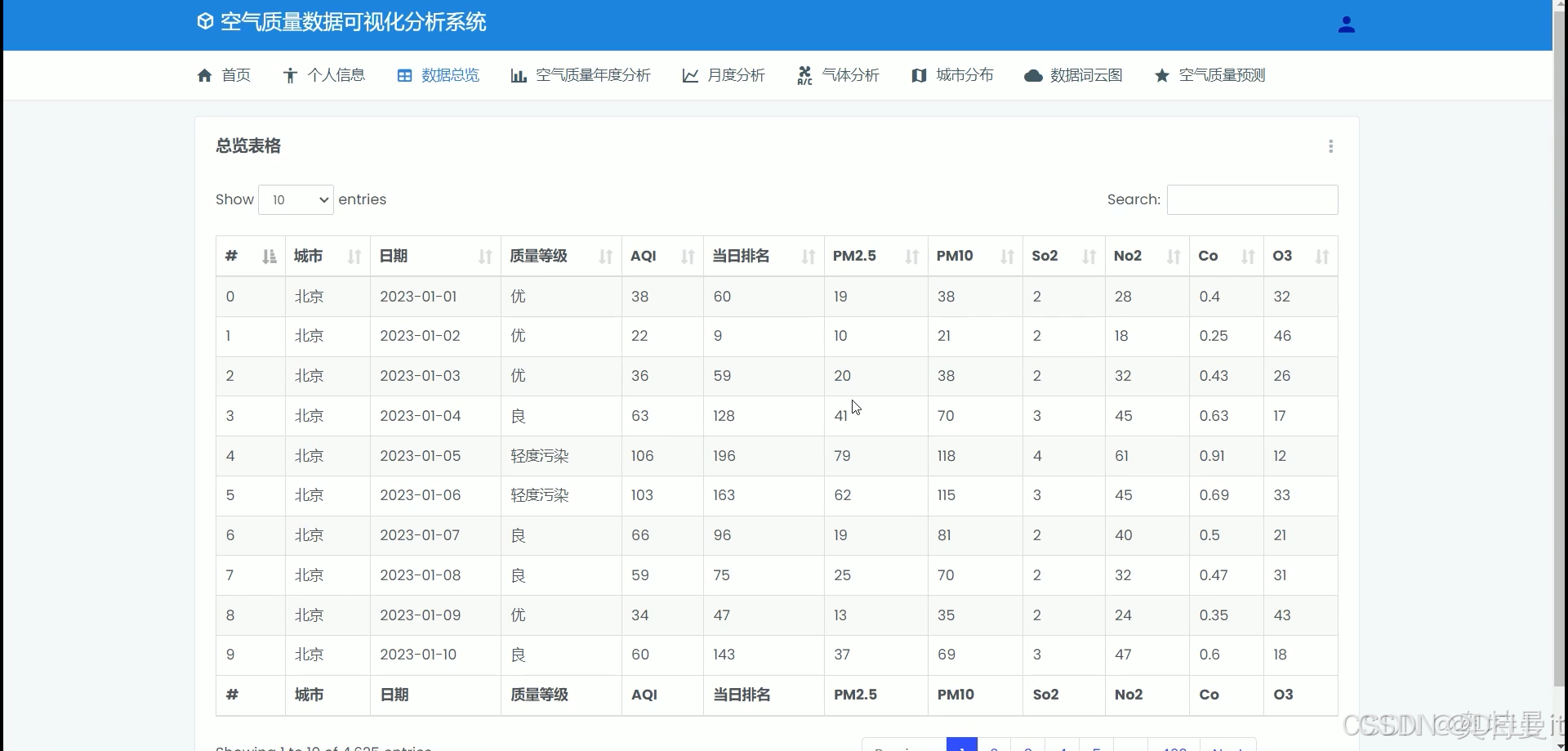
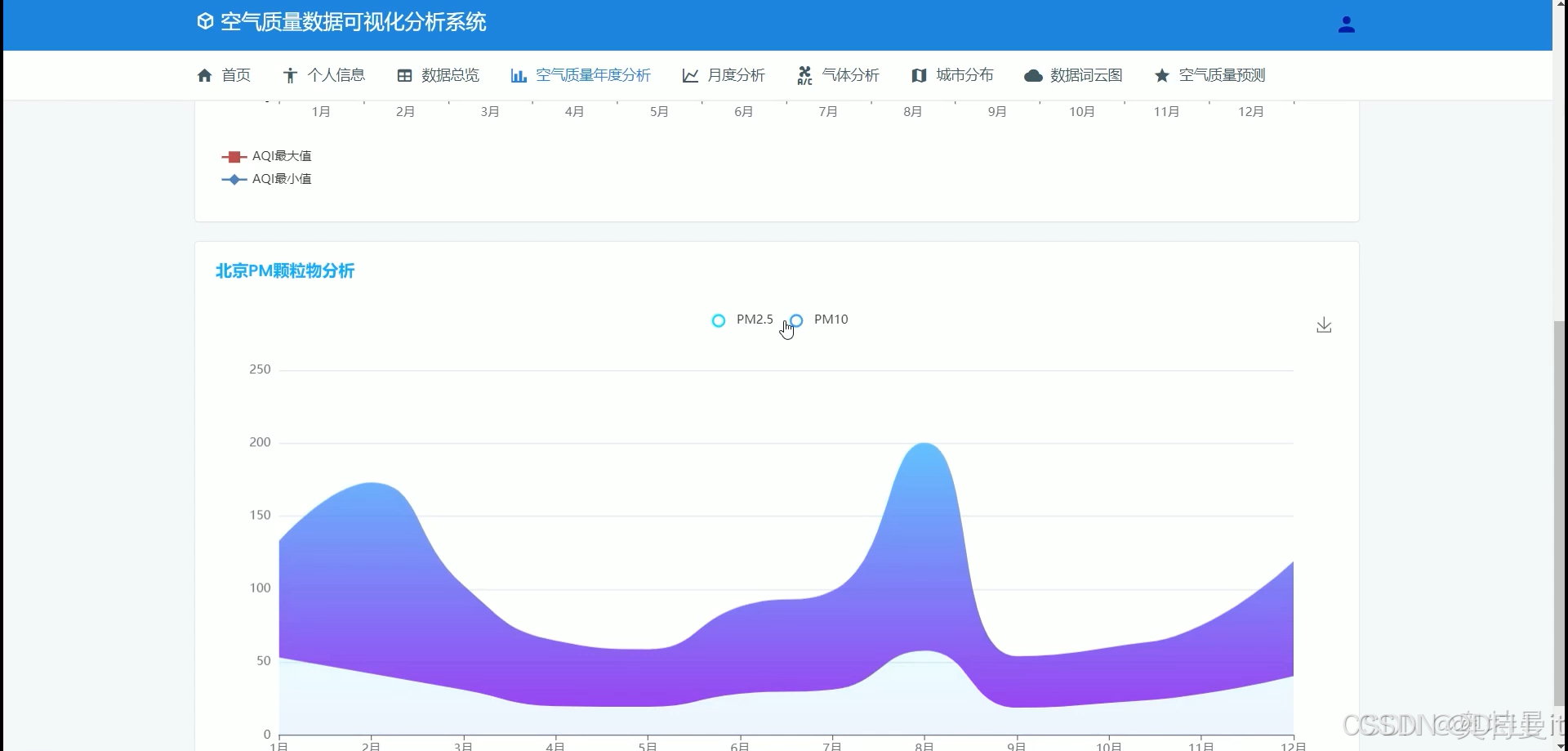
空气质量年度分析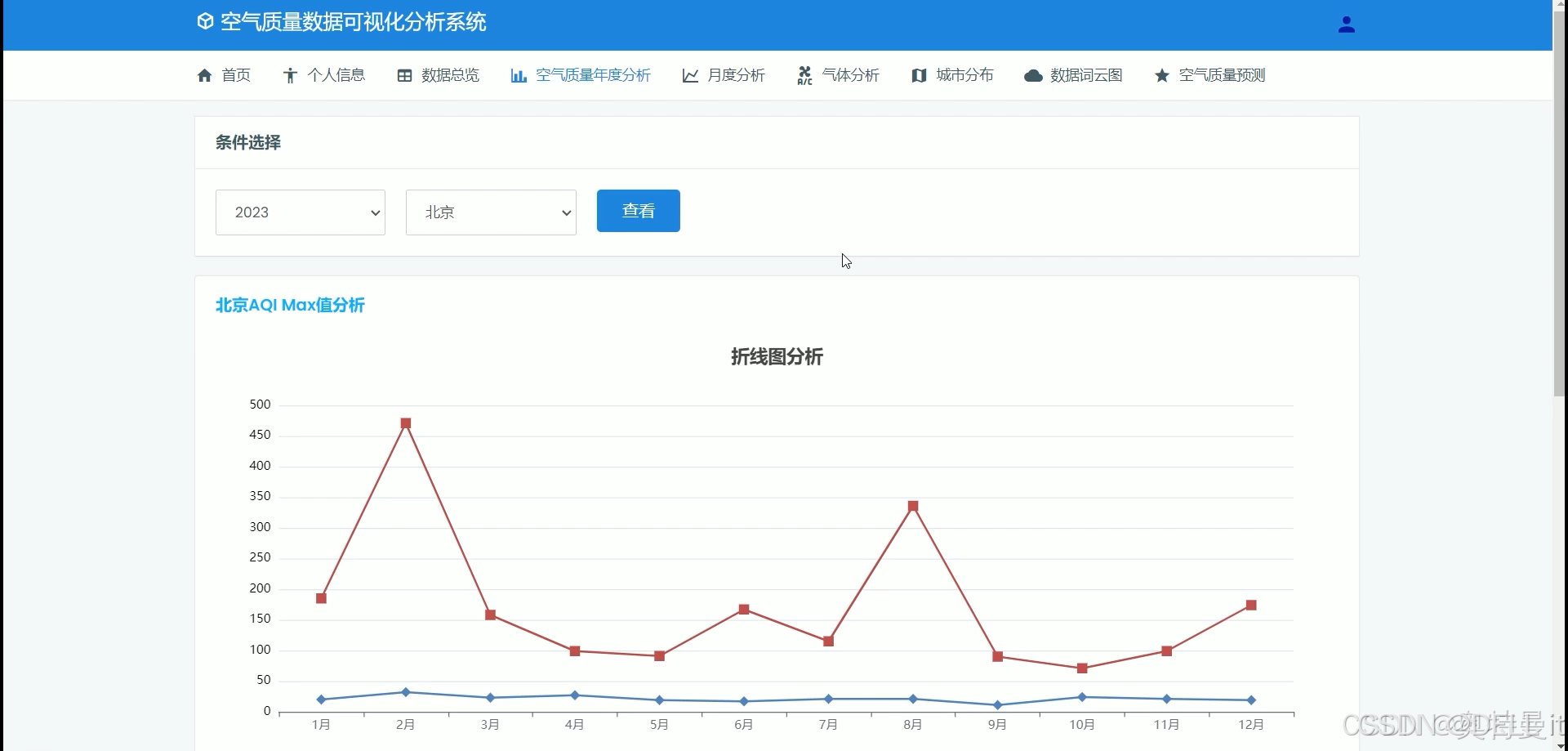
月度分析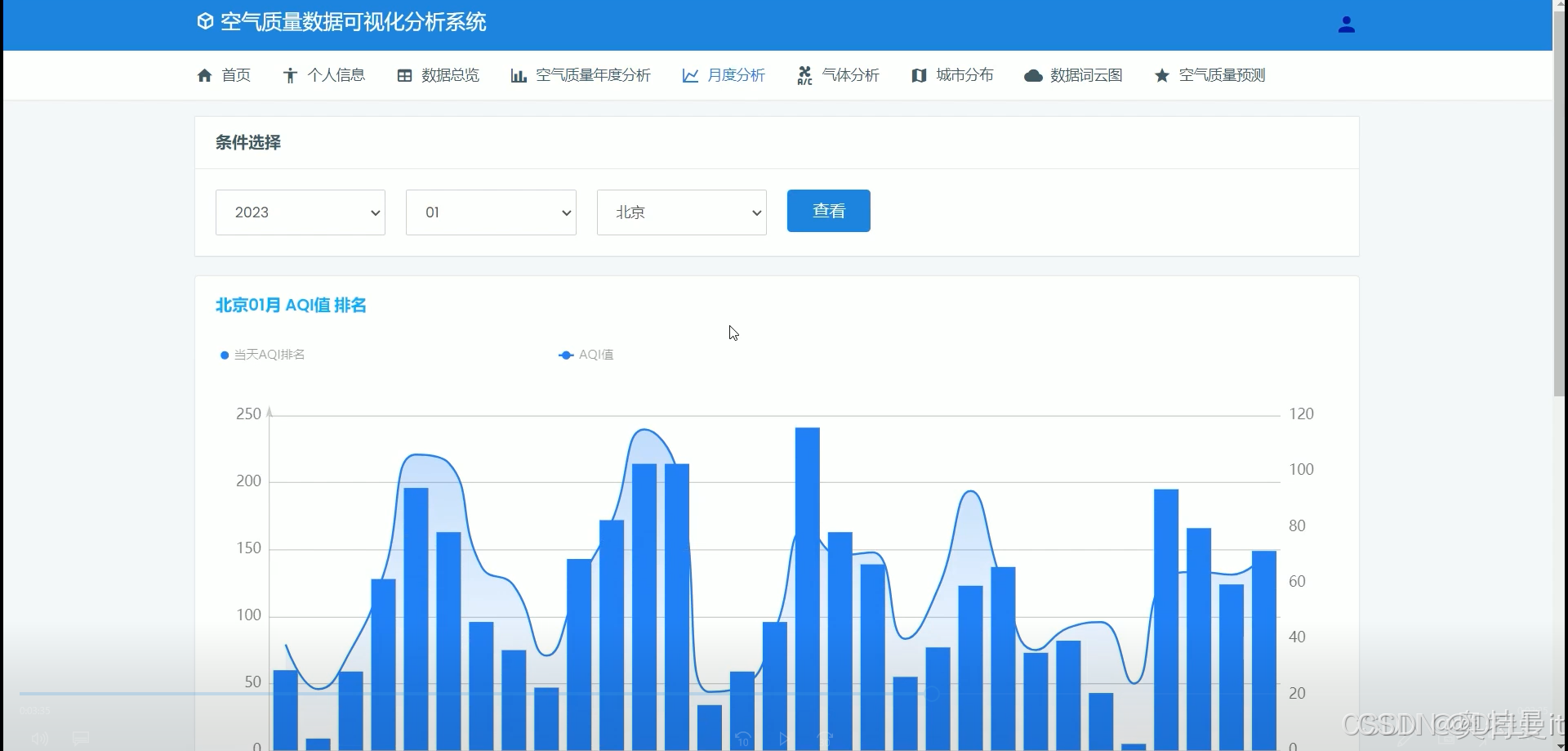
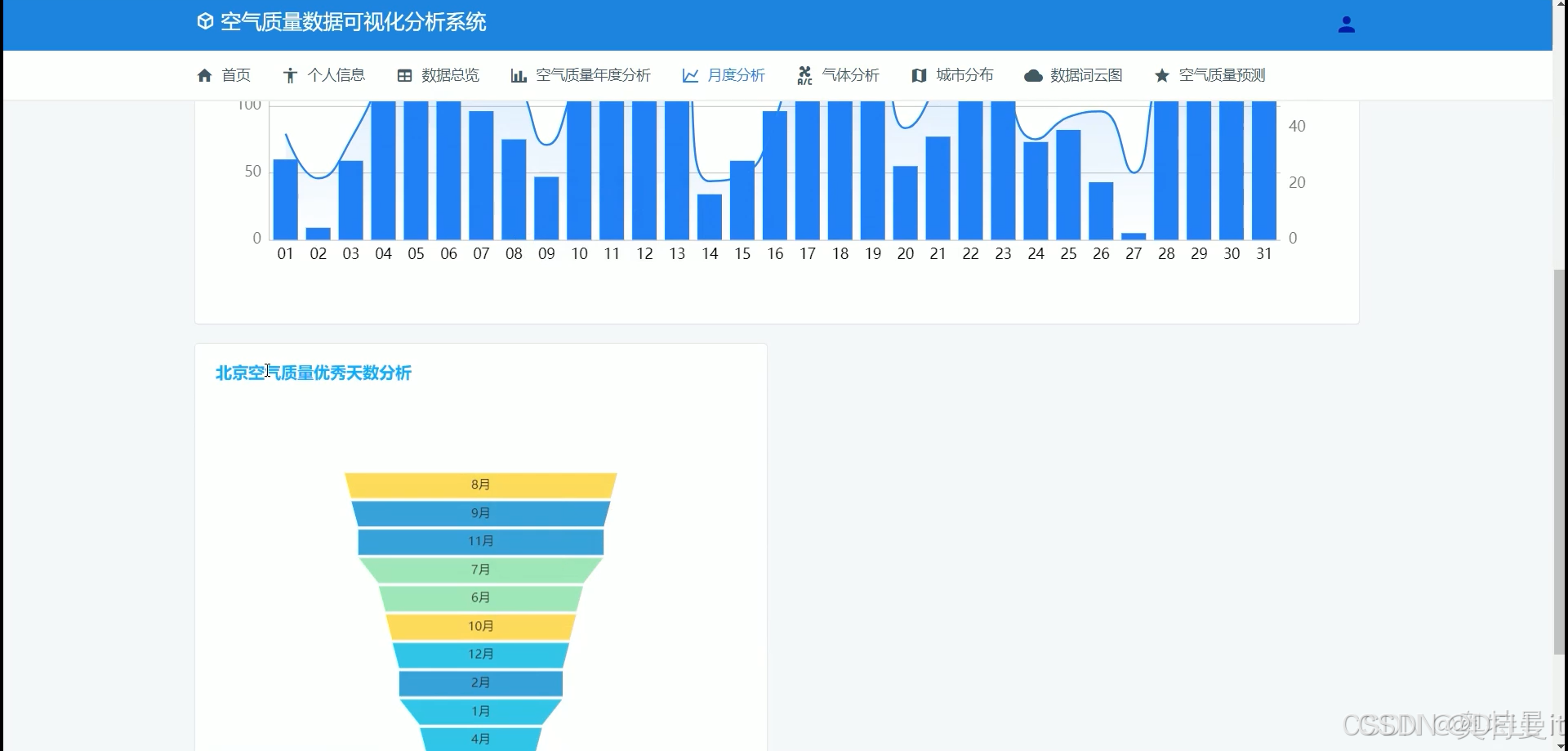
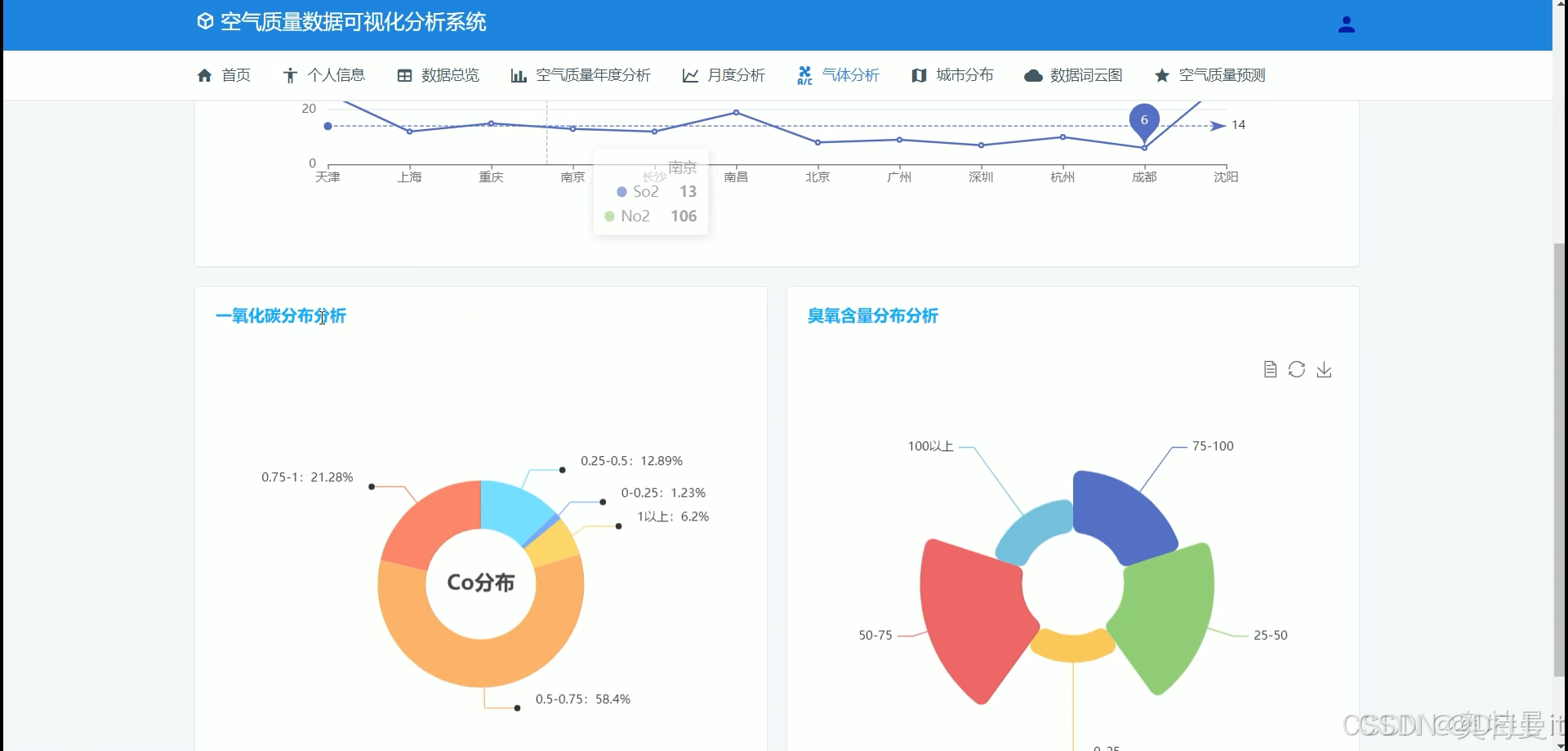
气体分析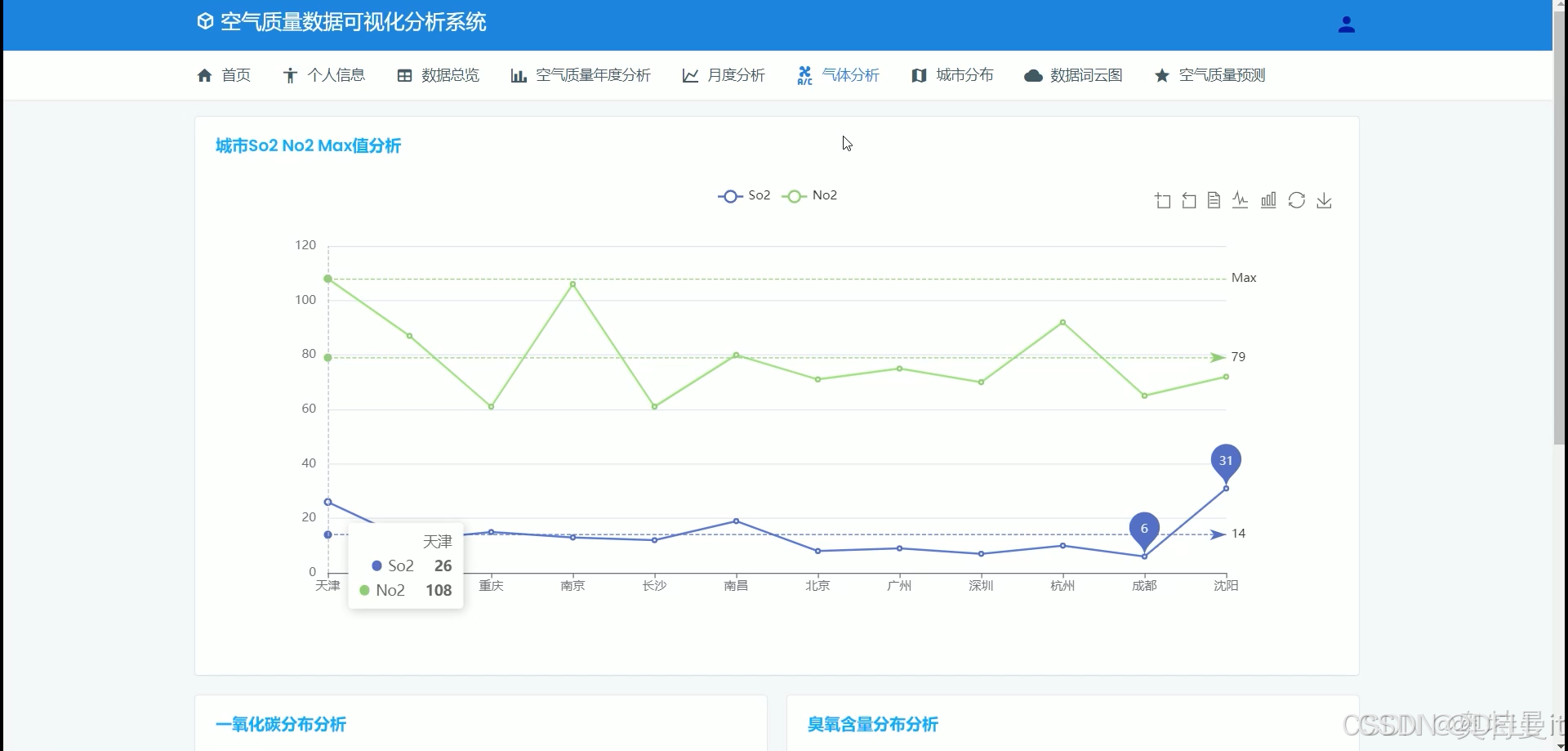
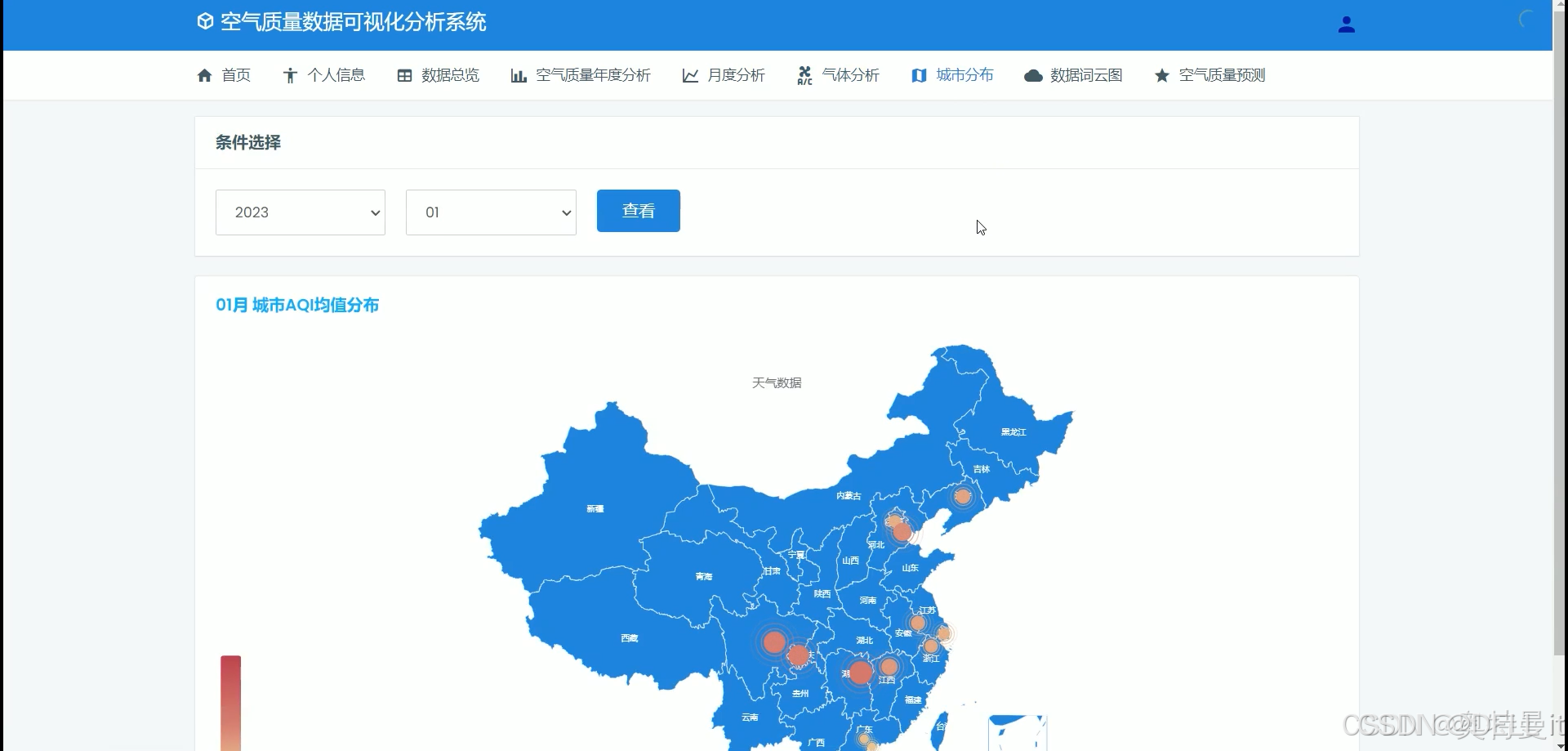
空气质量预测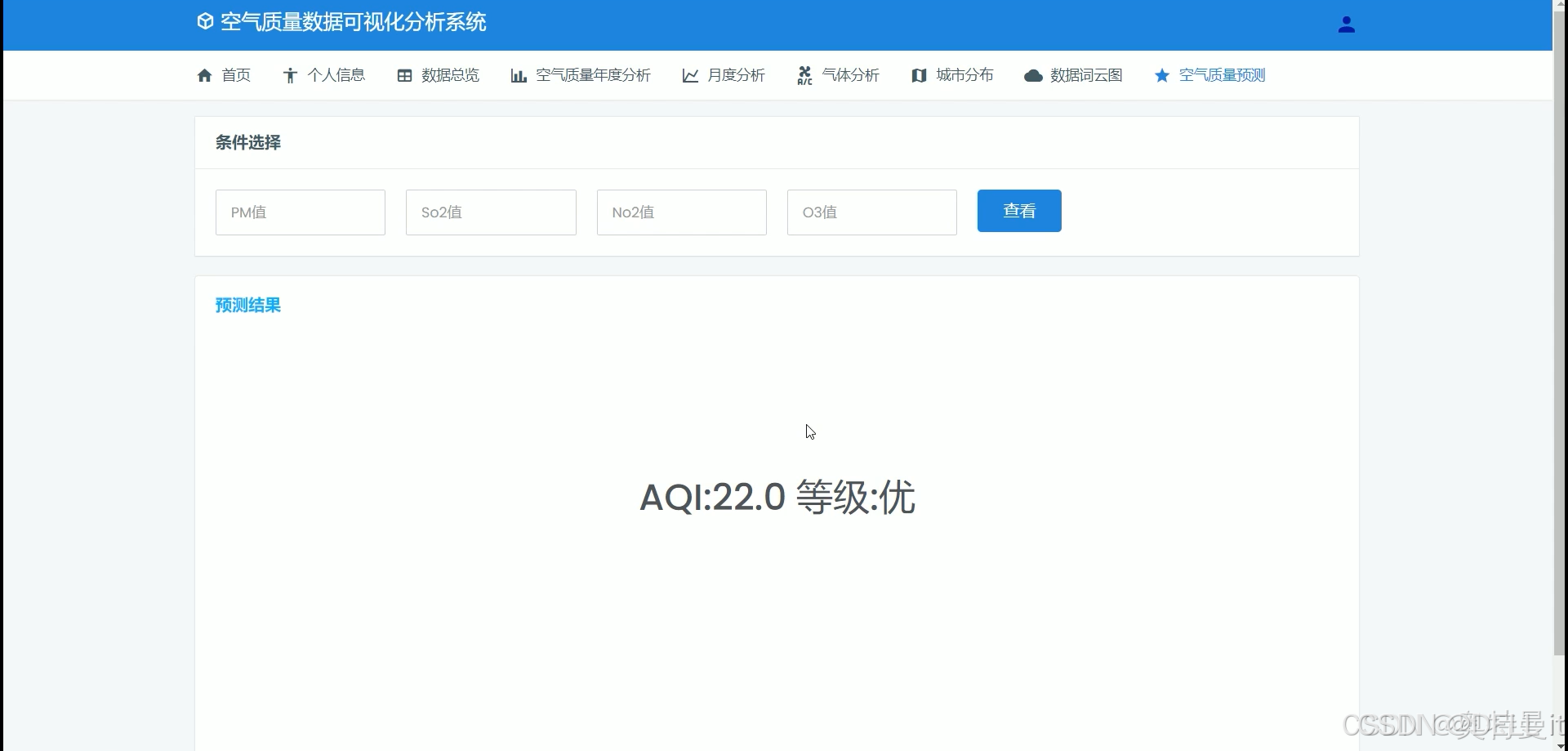
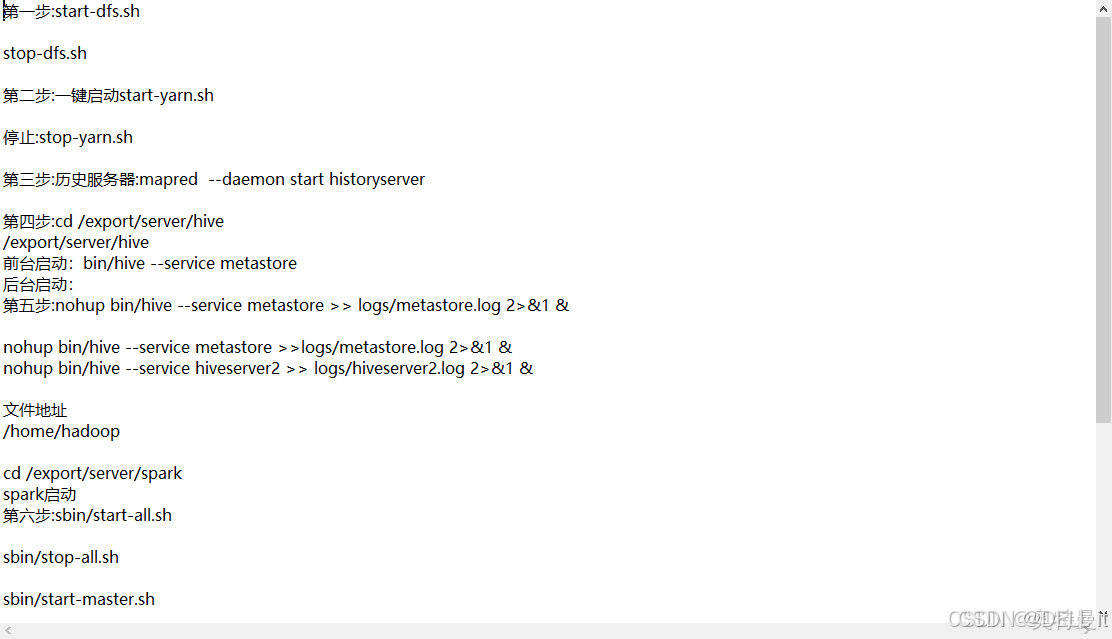
启动文档
开发笔记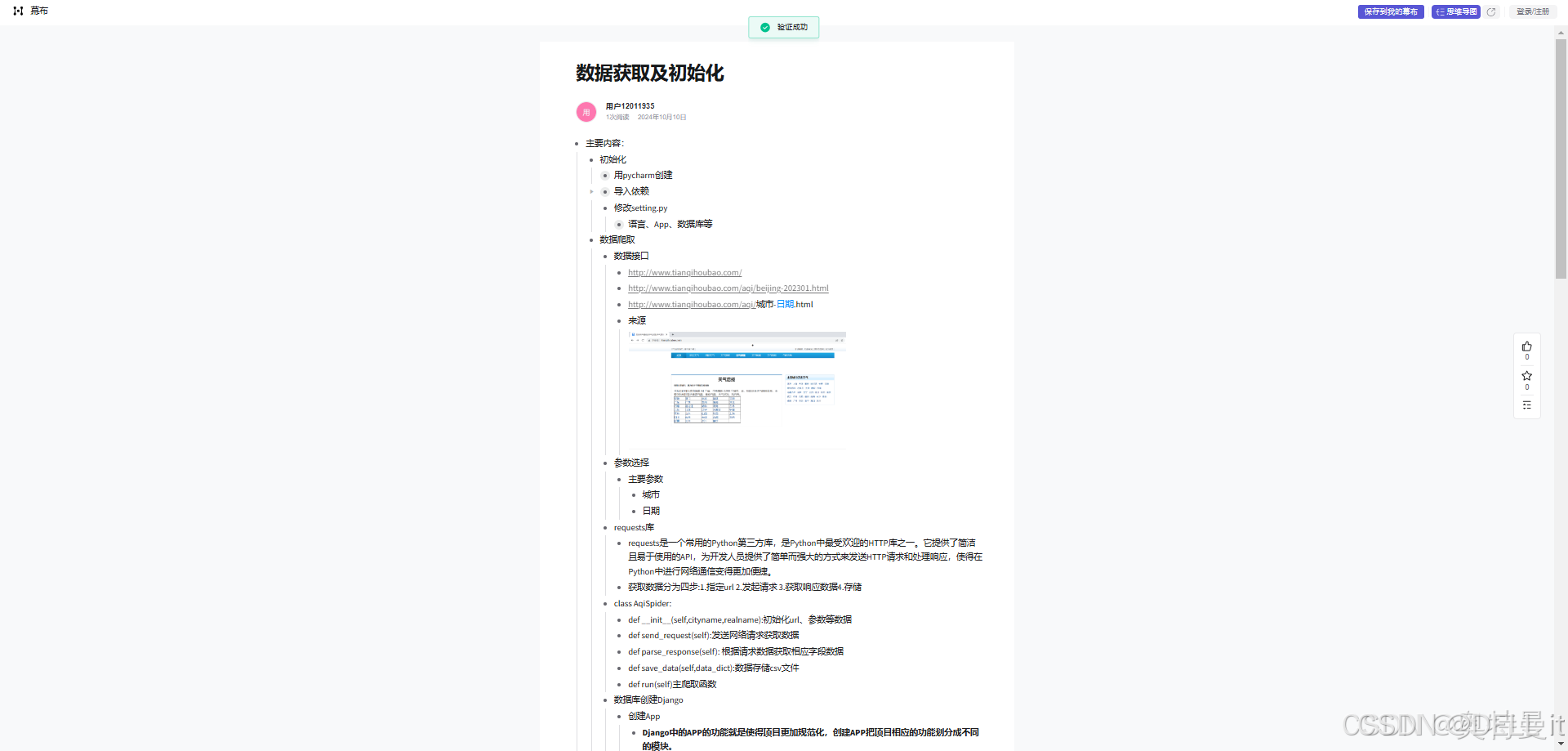
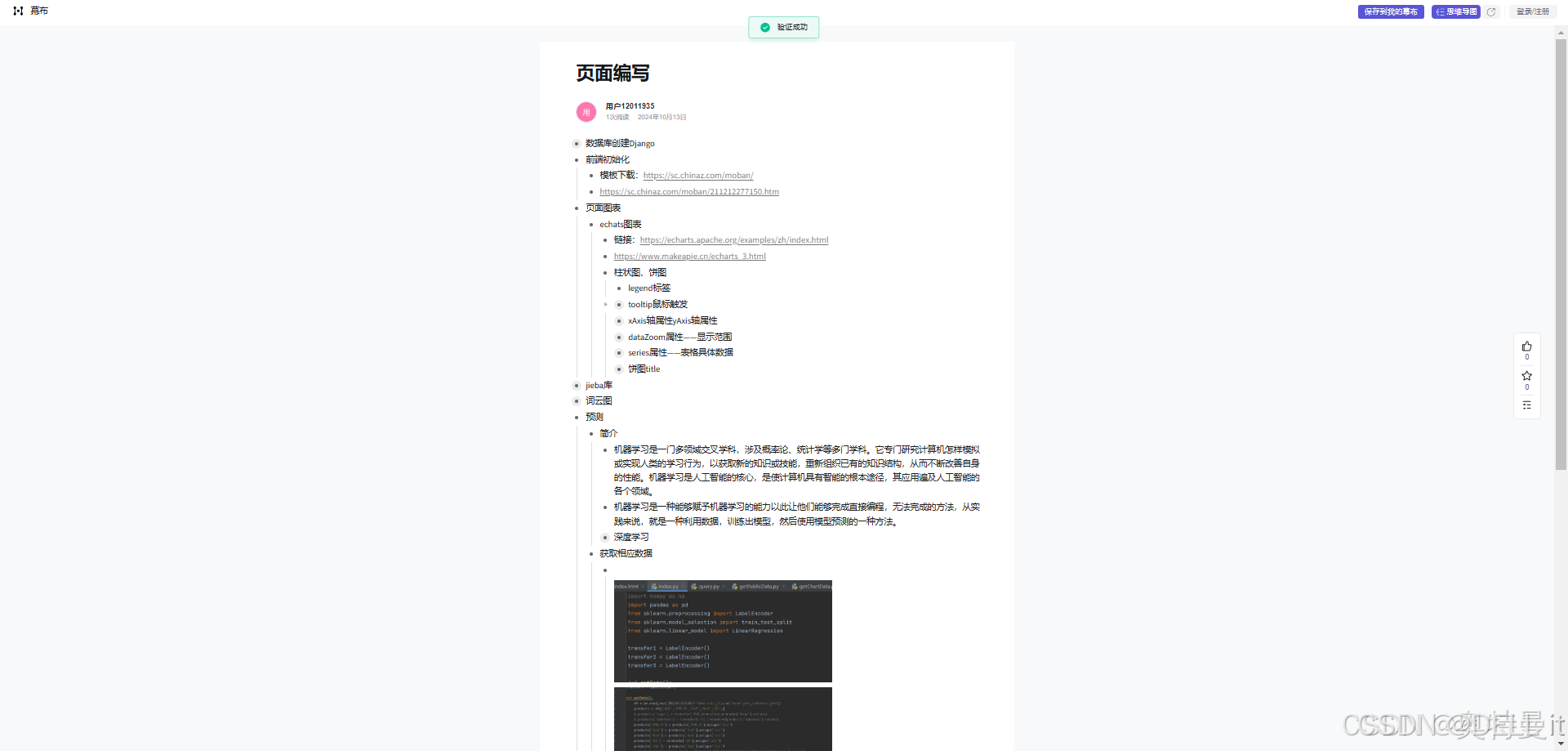
八、权威视频链接
【Spark+Hive+hadoop】基于spark+hadoop大数据空气质量数据分析预测系统 大数据毕设 计算机毕业设计—免费完整实战教学视频
源码获取方式在作者主页!!!
源码获取方式在作者主页!!!
源码获取方式在作者主页!!!

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)