轻量大数据架构(1):环境的搭建与配置
在windows里,spark-shell和pyspark的部分运行会因为环境不兼容而崩溃/报错,如使用:quit会因为删除失败报错;hadoop时,需要注意其与Windows环境兼容度问题,需要同时安装WinUtils和hadoop.dll,这里提供一个大佬的网址,里面有hadoop对应的dll和winutils,WSL系统在安装时,可采用图形化的安装方式,点开控制面板的“程序和功能”,然后再点
WSL系统的安装
WSL系统在安装时,可采用图形化的安装方式,点开控制面板的“程序和功能”,然后再点开“启用或关闭windows功能”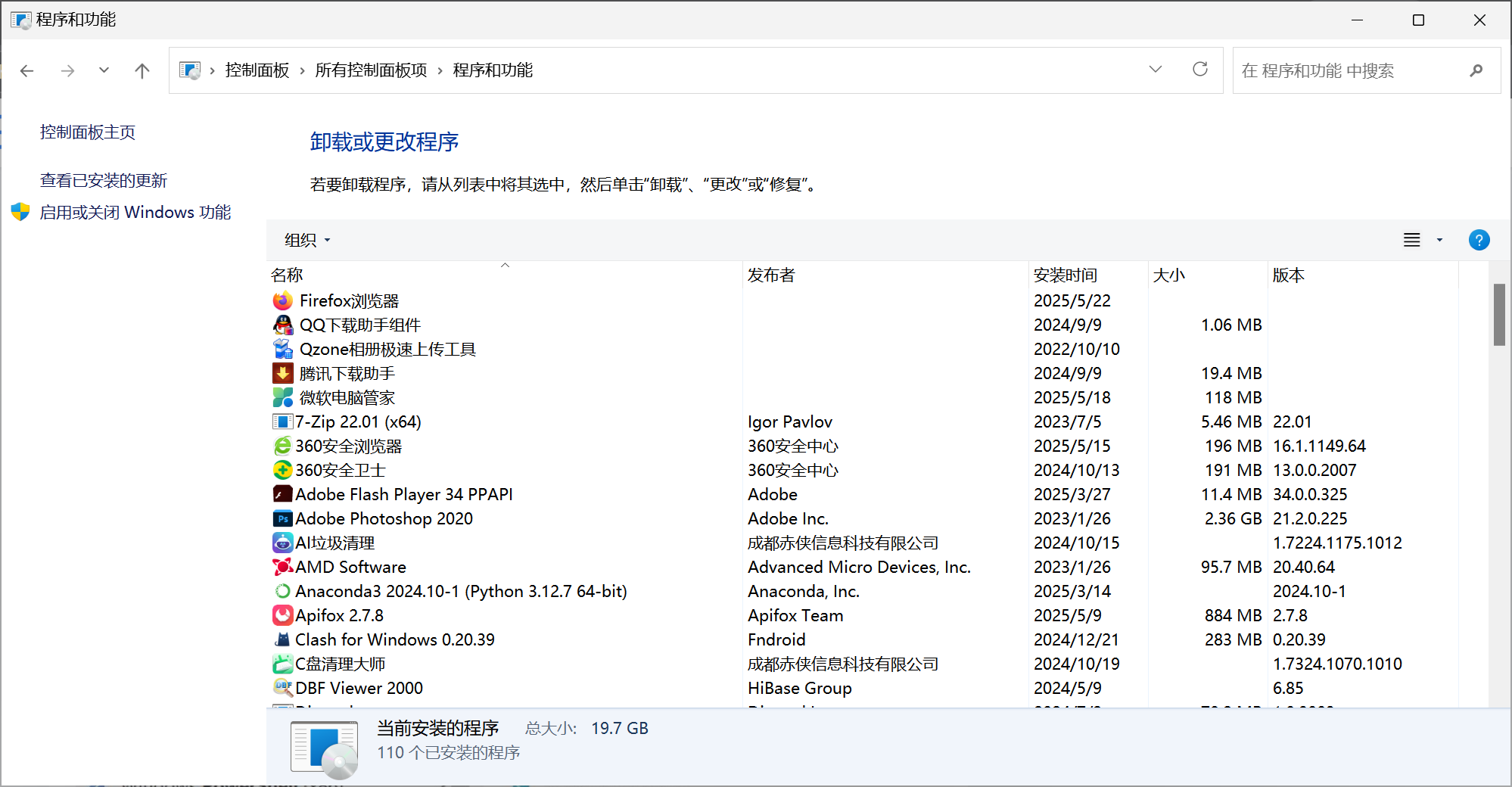
随后,点击进去后,找到“虚拟机平台”和“适用于Linux的windows子系统”两个功能。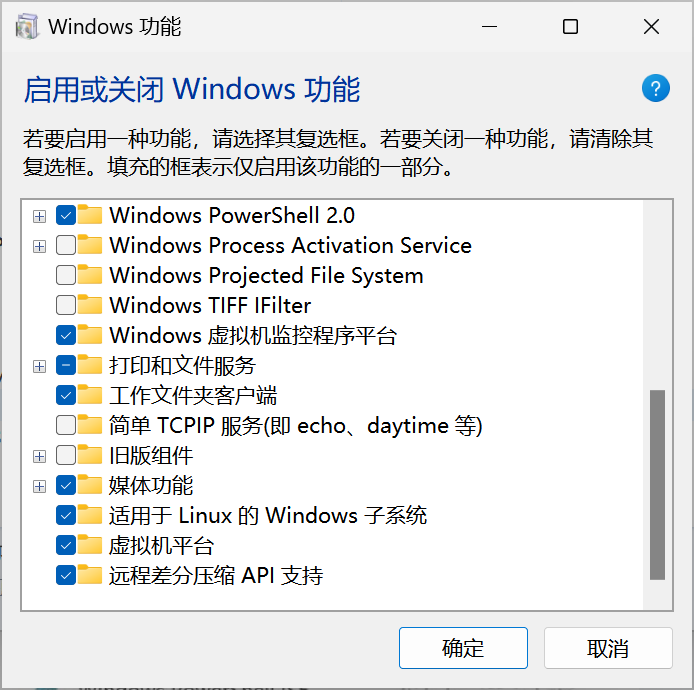
如果嫌麻烦,也可以直接在CMD里面输入:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart开启之后,点开cmd,输入:
wsl --list随后将获得支持的版本如ubuntu,debian等,选择一个安装:
wsl --install <分发的Linux版本>安装后如果怕安在C盘占空间,可选择蒸馏;先关闭wsl所有版本,
wsl --shutdown然后选择将C盘里安装到的Linux导出,这里默认Ubuntu。
wsl --export Ubuntu-24.04 D:/wsl_ubuntu_24.04/Ubuntu-24.04.tar
wsl --unregister Ubuntu-24.04 #卸载C盘上的
wsl --import D:/wsl_ubuntu_24.04 D:/wsl_ubuntu_24.04/Ubuntu-24.04.tar然后打开Ubuntu-24.04或者输入
wsl -d Ubuntu-24.04看到如下链接,便是安装完成。
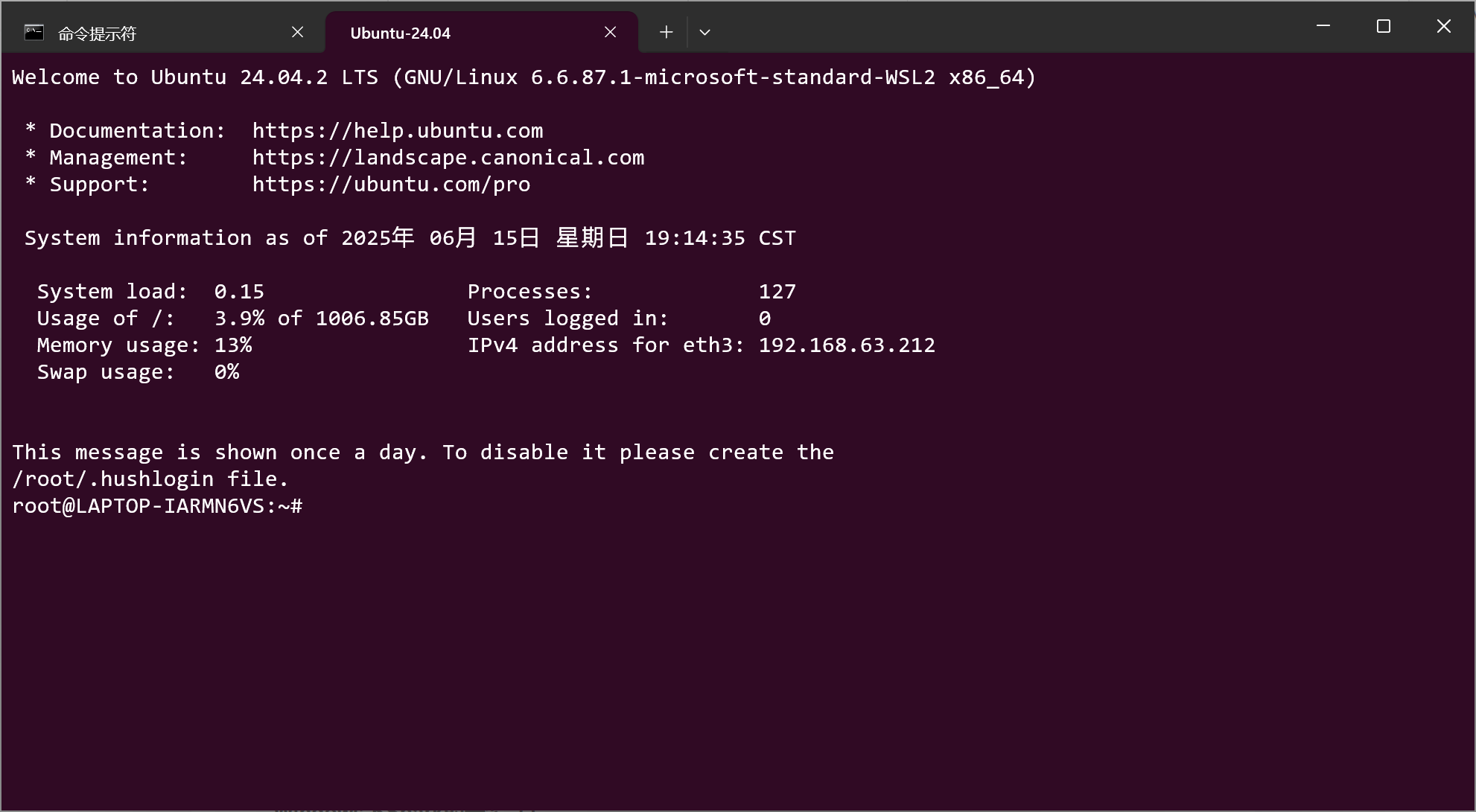
一般在安装好后,默认以Root用户开启
此时,便可执行下一步:图形化页面的安装。
sudo apt update && sudo apt install xfce4 xfce4-terminal -y
sudo apt install xrdp -y
sudo adduser xrdp ssl-cert
sudo systemctl restart xrdp
sudo systemctl enable xrdp
安装完后,点开远程桌面连接。
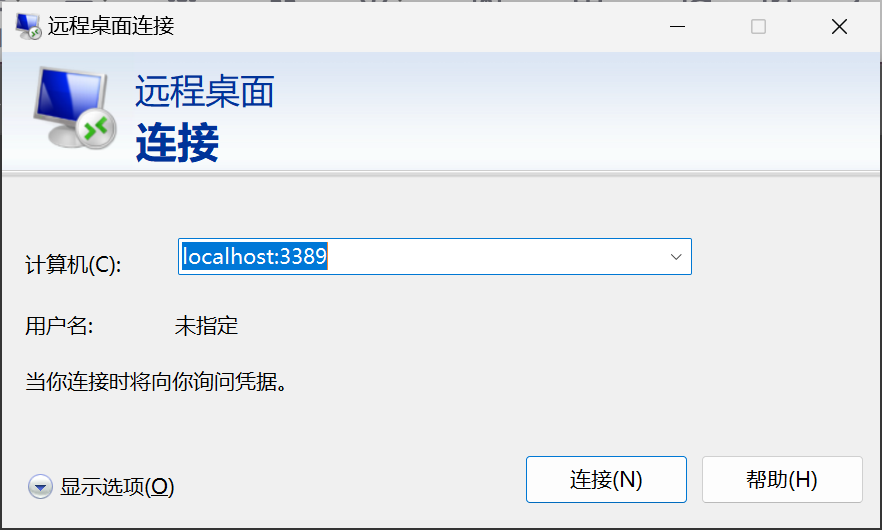
显示如下界面,便是安装成功。
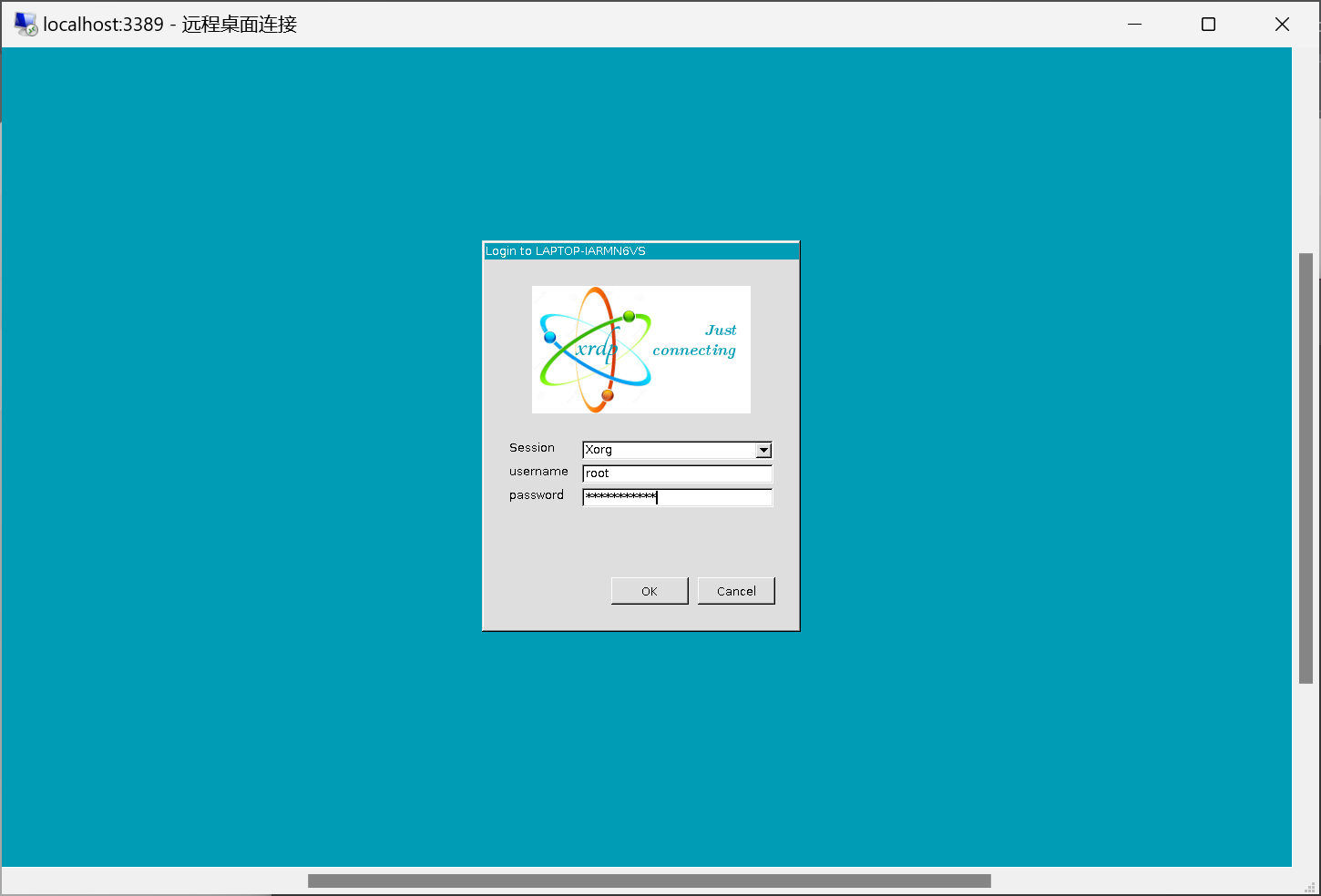
输入密码后便可看到对应页面。
除此之外,在wsl上面安装MySQL、Pycharm与Intellij idea,并开启SSH。
安装MySQL时,
sudo apt-get install mysql-server-8.0 mysql-client-8.0
如果安装时有错误发生,很可能是在windows安装了mysql。
此时,输入:
vi /etc/mysql/mysql.conf.d/mysqld.cnf调整参数:
port=3308
mysqlx=1
mysqlx-port=33080此时MySQL可正常启动。
MySQL成功启动后,开始安装Python,Pycharm和Intellij idea以及Java包。
安装Python时,输入:
sudo apt-get install python3
sudo apt-get install python3-pip随后安装Pycharm。
比较可行的方案是:
sudo snap install pycharm-community --classic随后在搜索栏中看到Pycharm Community Edition,打开后便能进入Pycharm界面。
当打开如下页面时,便安装成功。
紧接着是安装Java和Intellij Idea;
安装Java时,参考:
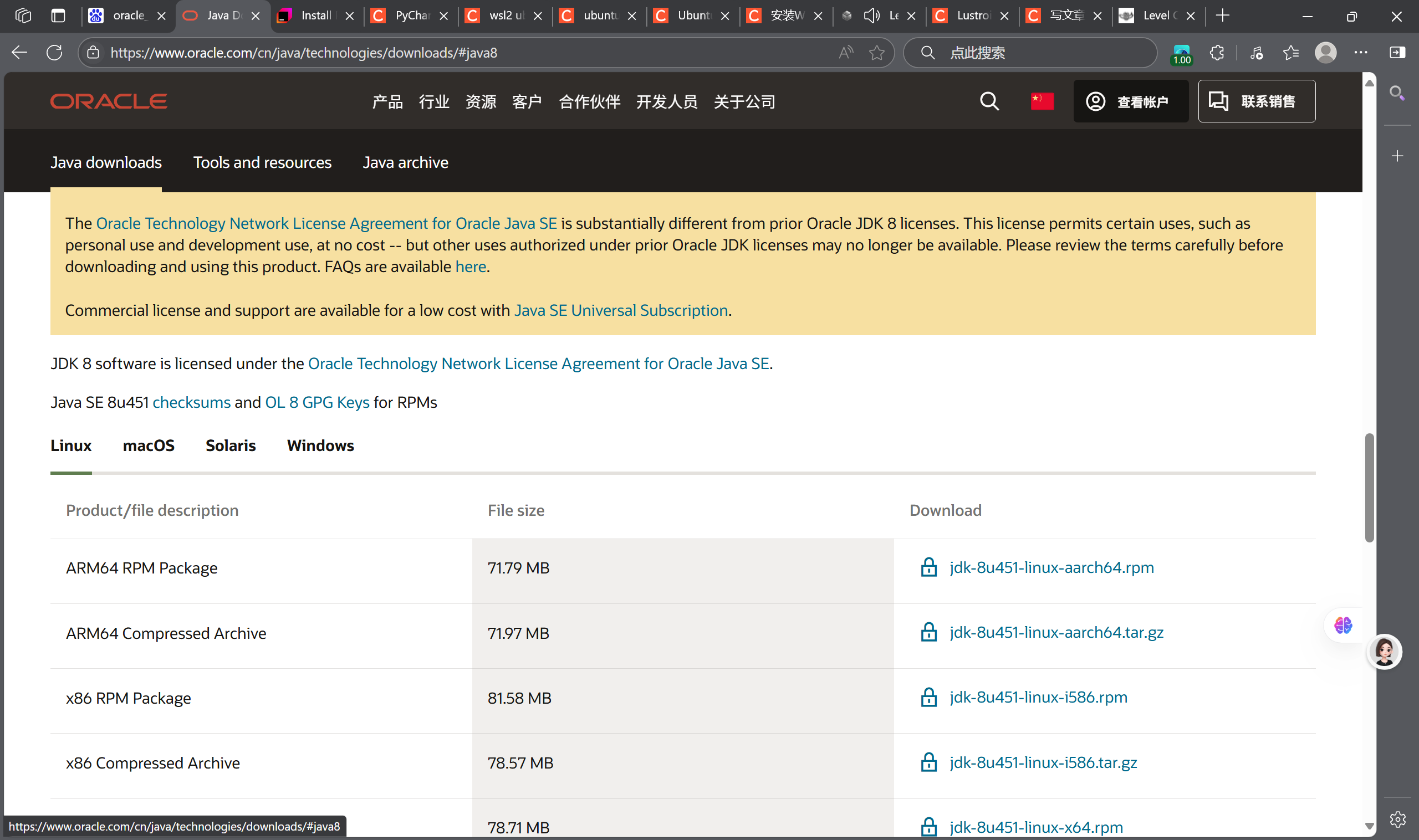
选择jdk8的Linux包下载,创建一个Java文件夹,并安装Java。
mkdir /usr/java
tar -zxvf /mnt/d/systemDir/Downloads jdk-xxxx.tar.gz -C /usr/java随后加入以下两句进入/etc/profile配置环境变量:
echo 'export $JAVA_HOME=/usr/java/jdk1.8.0_xxx' >>/etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin'>> /etc/profile使环境变量生效:
source /etc/profile
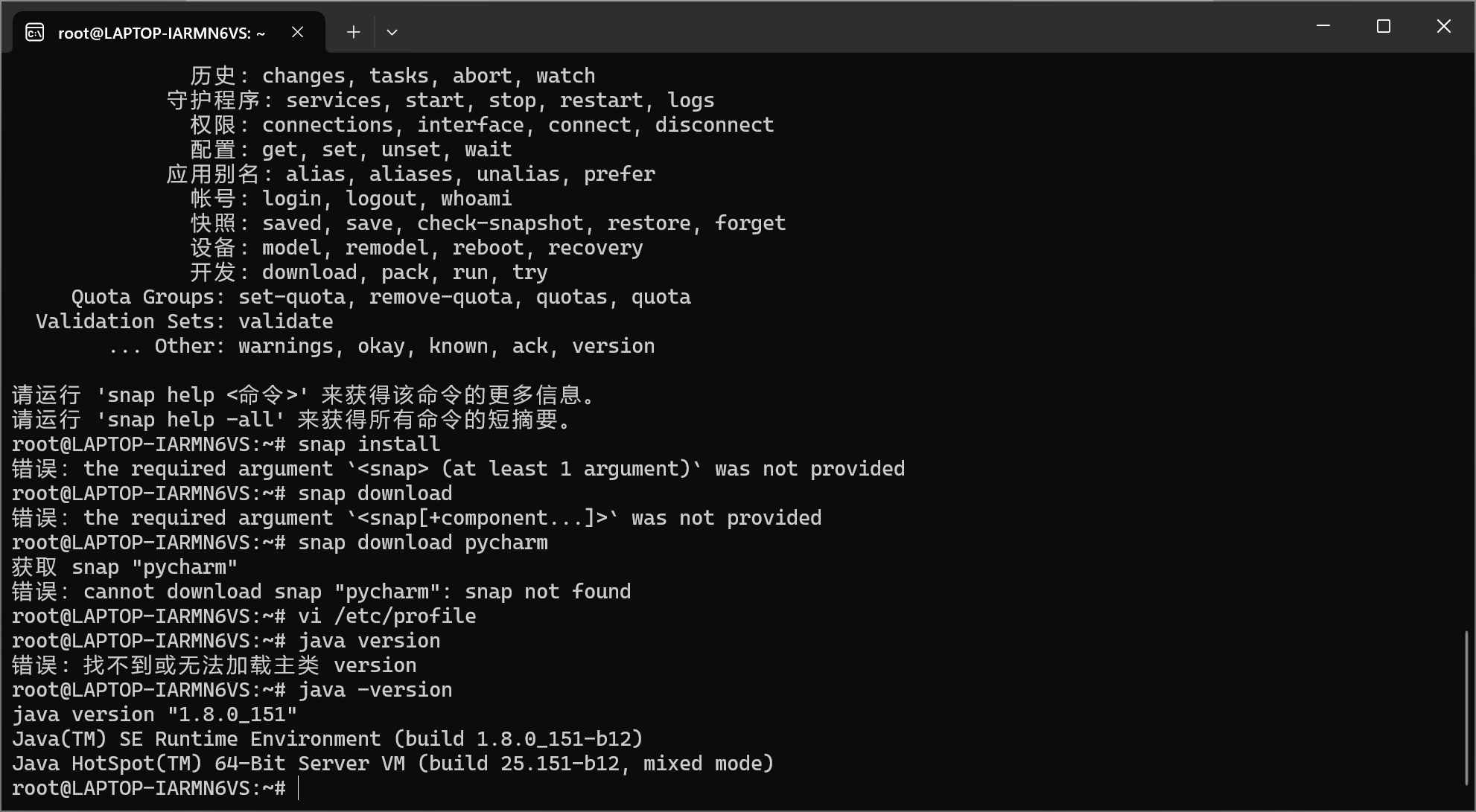
查看java版本:
java -version
看到如下页面则安装成功。
紧接着是加入Intellij idea。
sudo snap install intellij-idea-community --channel=2023.3/stable --classic安装完成后,点击Ubuntu版本的intellij idea。
当进入对应页面后,便得以安装成功。
由于Spark的原生语言是Scala,所以在intellij IDEA里面需要点开settings->plugins->并安装maven插件和scala插件。
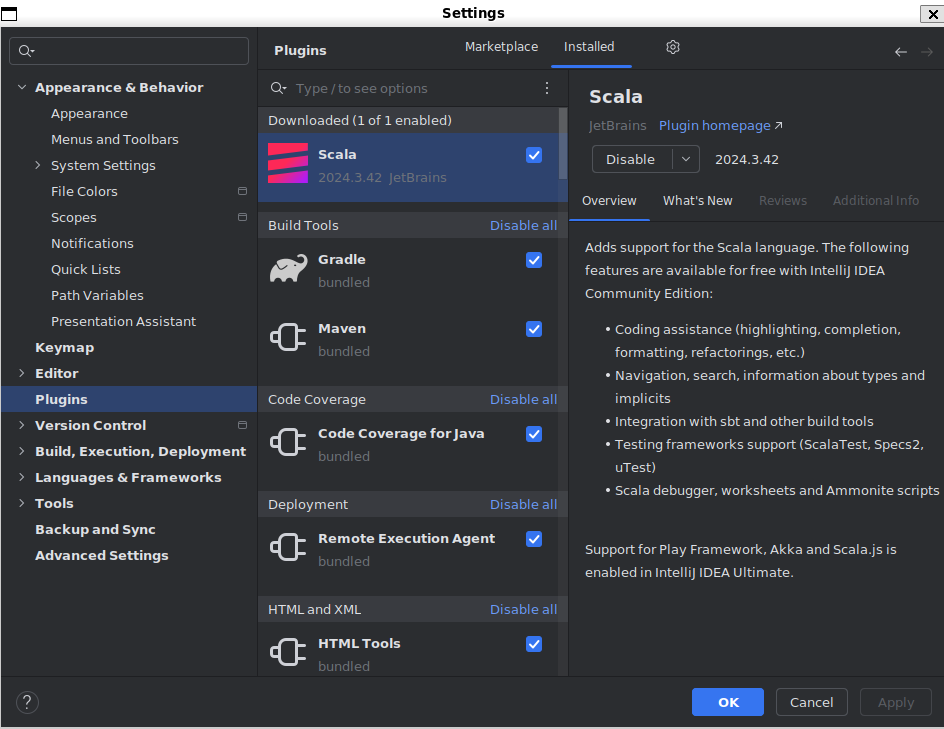
然后在一个新建Project里面出现scala,则插件安装成功。
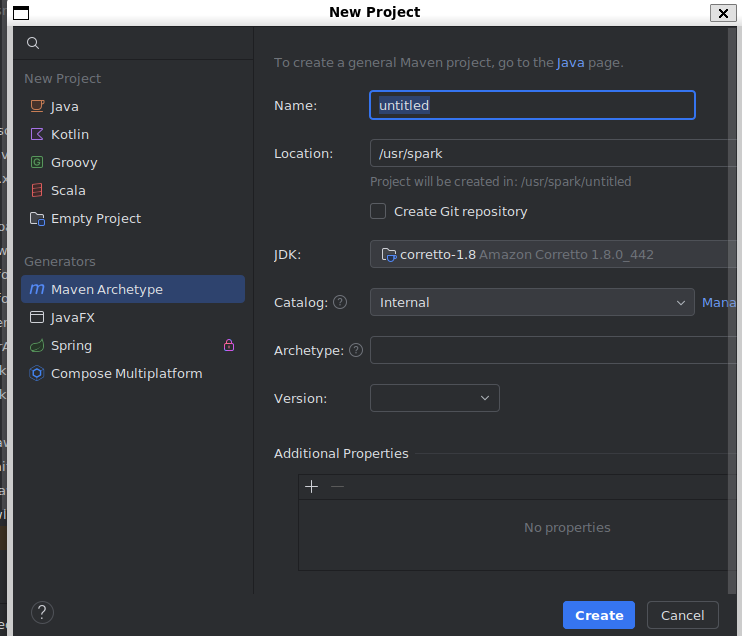
SSH的安装
众所周知,ubuntu默认的openssh-server通常都有问题,所以需要卸了重装。
sudo apt-get remove openssh-server
sudo apt-get update
sudo apt-get install openssh-server同时尽量选择其他的ssh端口,可打开/etc/ssh/sshd_config.d/*.conf
port去掉注释,写上
port 2222
当然这里也可以选择其他你喜欢的端口。
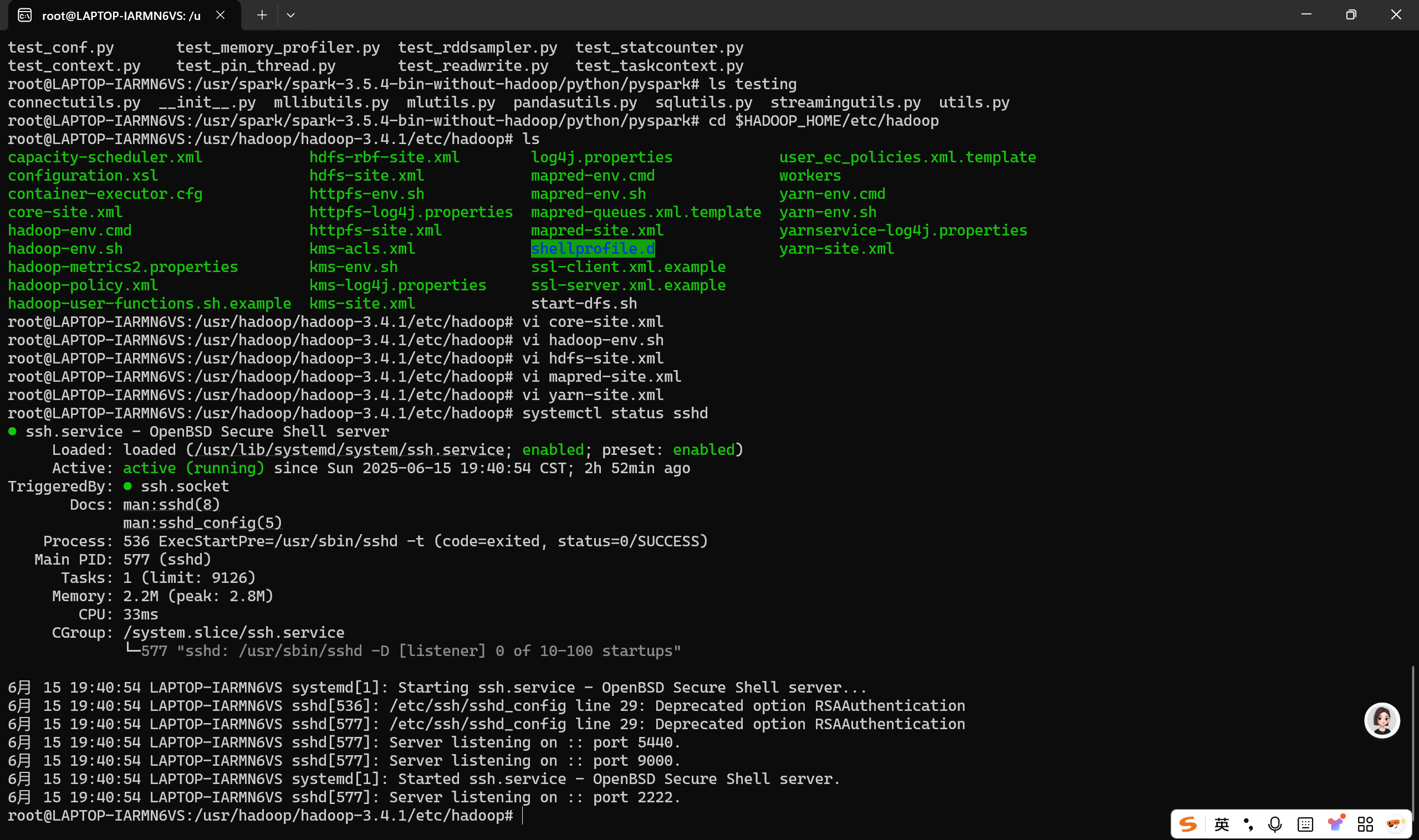
重装后检验状态:
systemctl status openssh-server
systemctl restart ssh
若状态是Active,则安装成功。
WSL下Spark的安装(推荐)
Spark是一款非常全能的大数据框架,支持Python/Scala/Java三种语言调用其API,支持批处理、流处理和数据分析、机器学习。
安装时点开官网下载链接:https://spark.apache.org/downloads.html
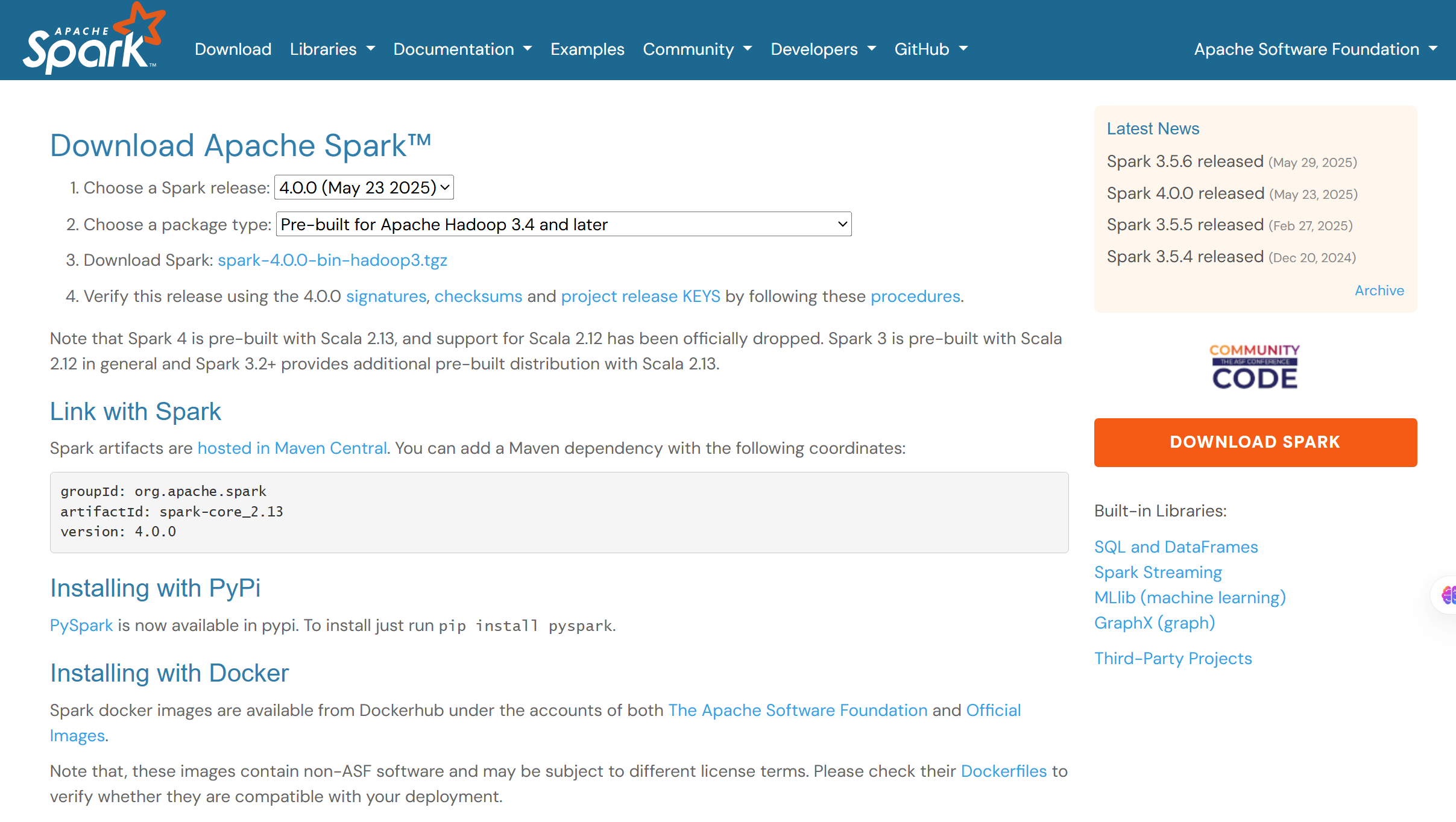
点开一个下载链接,其中“Pre-built for Apache Hadoop 3.4 and later”是根据hadoop3.4以后版本进行编译的;而“Pre-built for User-Provided Apache Hadoop”则无Hadoop硬性要求,根据开发者提供的Hadoop运行。
下载完对应的版本后,进行解压:
mkdir /usr/spark
tar -zxvf /mnt/d/systemDir/Downloads spark-3.5.4-bin-without-hadoop.tgz -C /usr/spark
#当然也可以考虑Spark 4.0,支持向量化查询和Kryo加速
加入环境变量:
echo 'export $SPARK_HOME=/usr/spark/spark-3.5.4-bin-without-hadoop' >>/etc/profile
echo 'export PATH=$PATH:$SPARK_HOME/bin'>> /etc/profile令环境变量生效:
source /etc/profile进行简单测试:
在命令行中输入:
spark-shell当弹出了如下内容,显示spark版本和scala版本的时候,则说明安装成功。
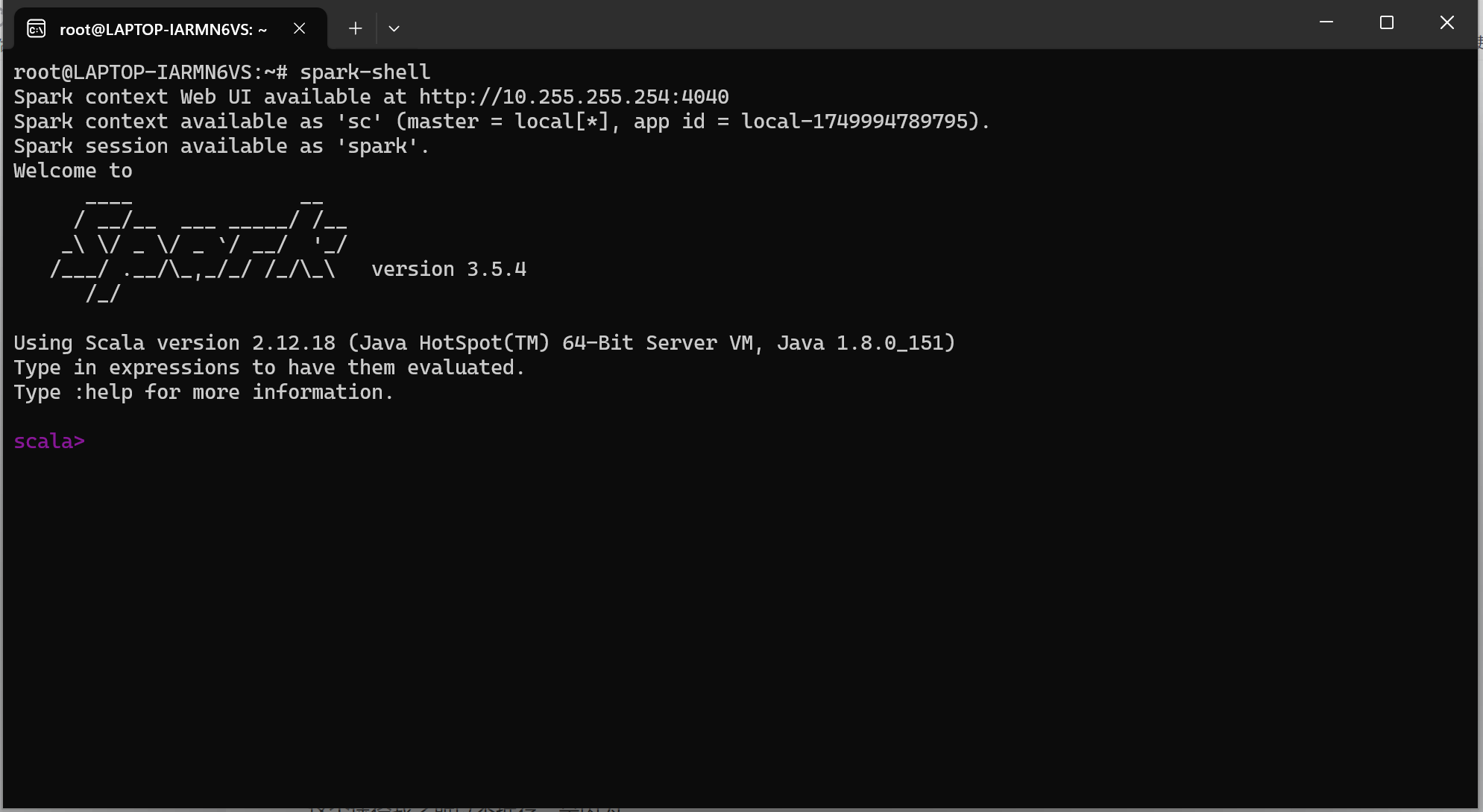
另一种方式是做提交测试:
spark-submit local[1] spark-submit /$SPARK_HOME/python/pyspark/find_spark_home.py若显示出spark环境的具体位置,则安装成功。
Windows下Spark的安装(不推荐,官方推荐Linux)
这个途径我之所以不推荐,原因之一是在windows下安装Spark必先安装Hadoop,在Spark里面会读取HDFS文件。一旦未安装Hadoop而提前安装Spark,会有所提示:“系统找不到指定的路径”;安装Java和前面一样,不过进入的是系统环境变量。
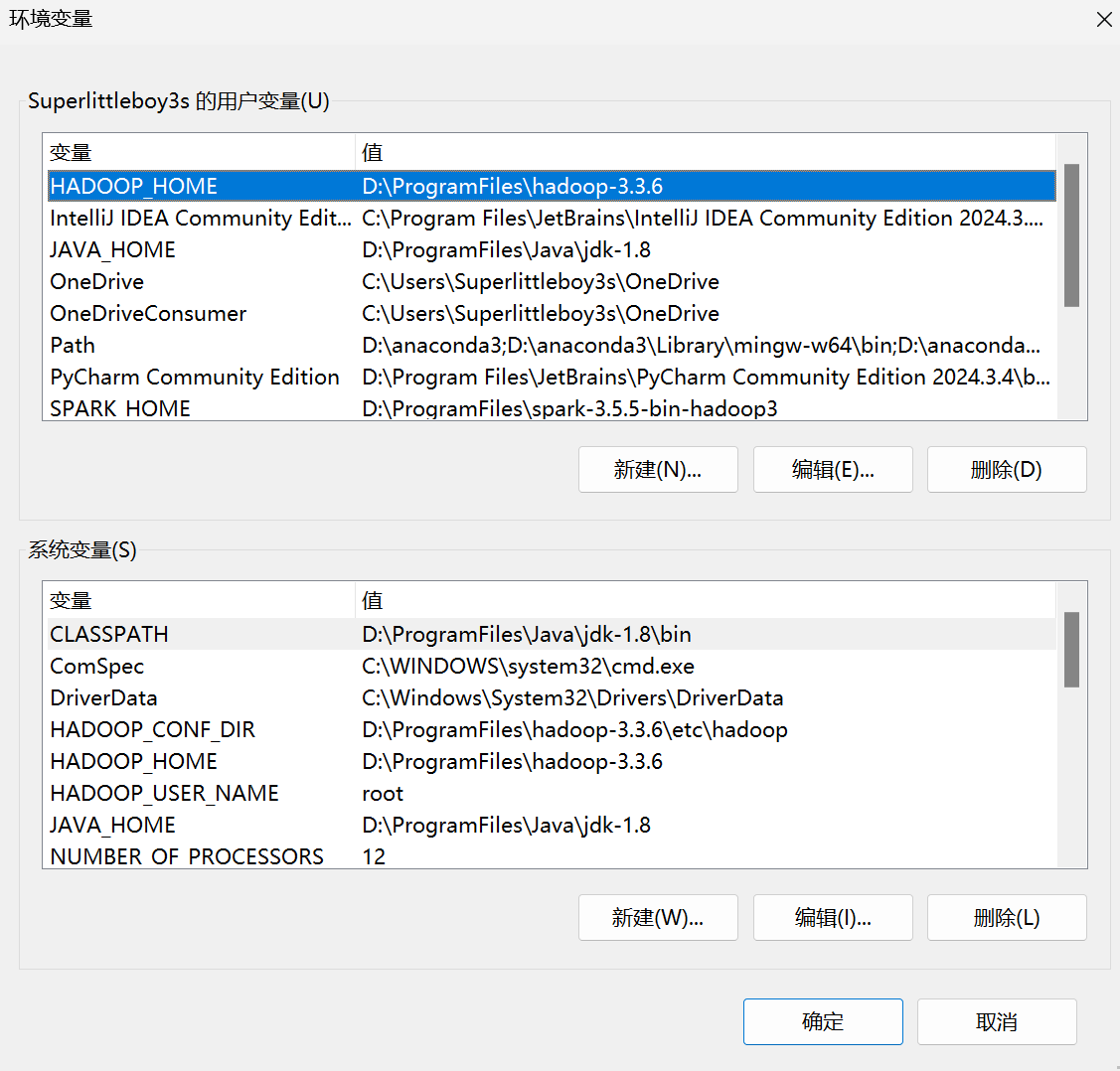
该处需要保证系统变量和用户变量的JAVA_HOME和JAVA_PATH是一致的,环境PATH设置成%JAVA_HOME%/bin。
而Hadoop安装时默认下来的是tar.gz,所以需要解压:
tar -zxvf /mnt/d/systemDir/Downloads/hadoop-3.3.6.tar.gz -C /mnt/d/ProgramFiles 在安装hadoop时,需要注意其与Windows环境兼容度问题,需要同时安装WinUtils和hadoop.dll,这里提供一个大佬的网址,里面有hadoop对应的dll和winutils,https://github.com/cdarlint/winutils
在里面找一个对应的winutil.exe和hadoop.dll
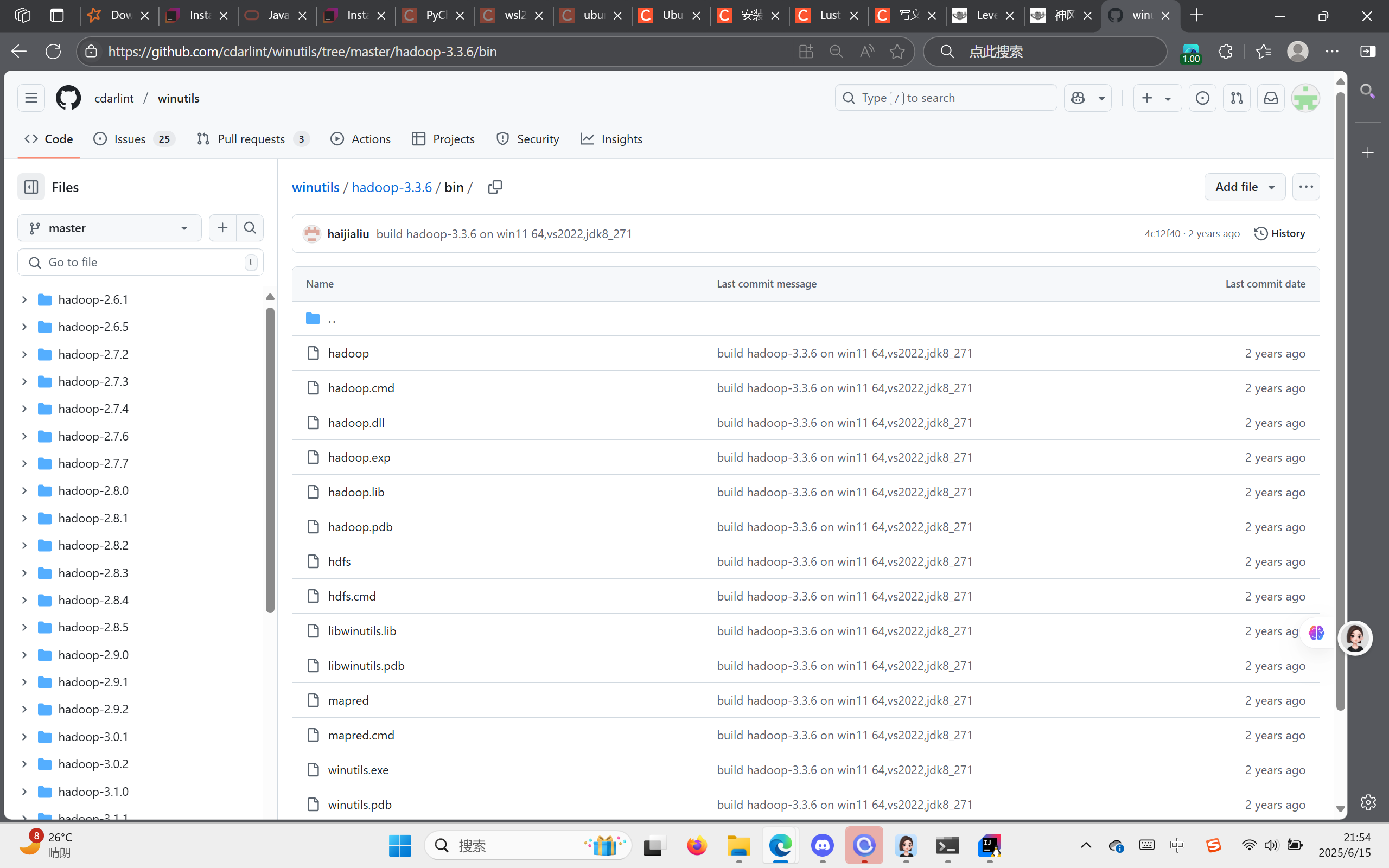
找到hadoop文件夹并打开,将下载来的hadoop.dll和winutils.exe都拖入你的bin文件夹。
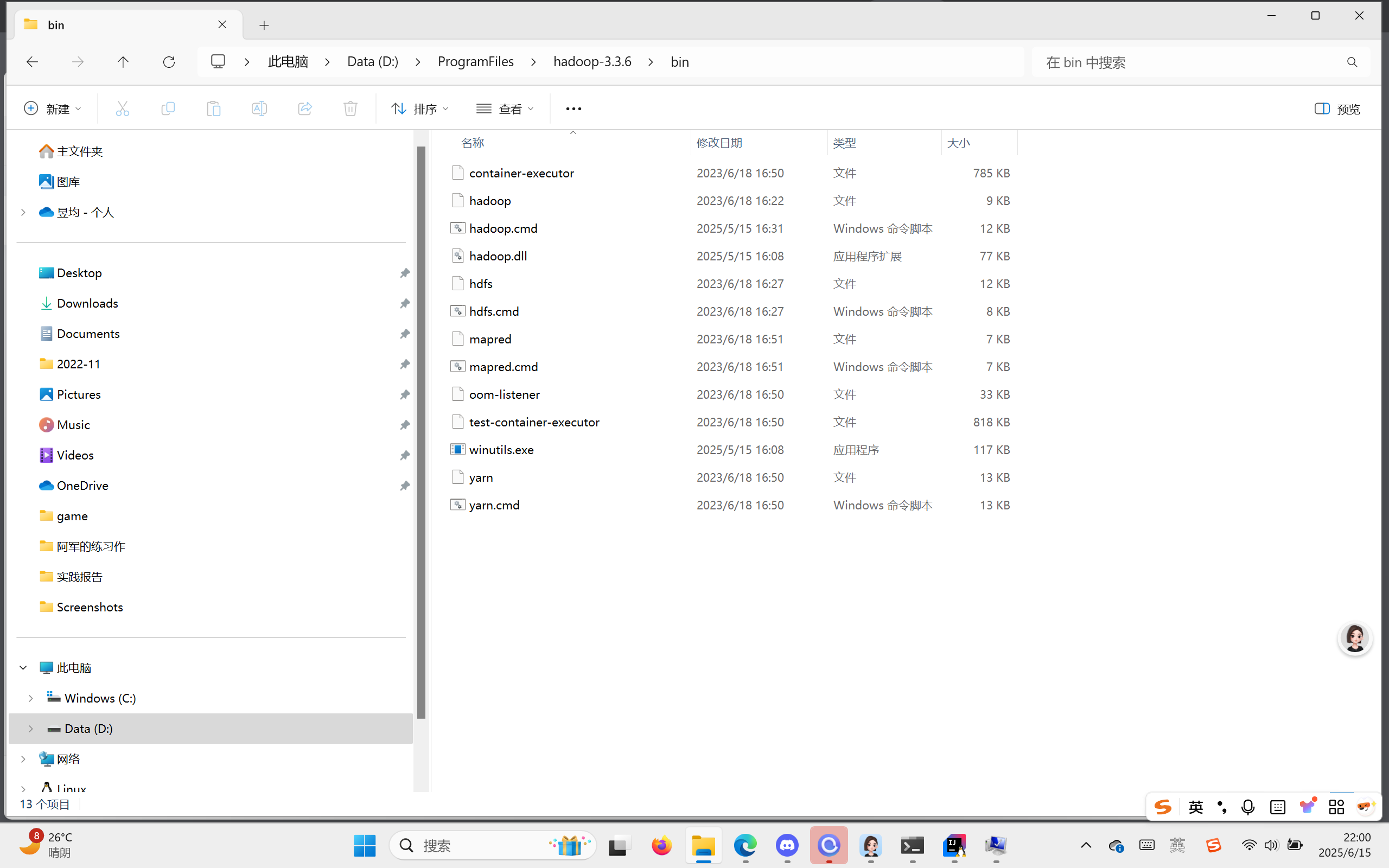
打开环境变量再设置,同样保证系统与环境变量双一致:
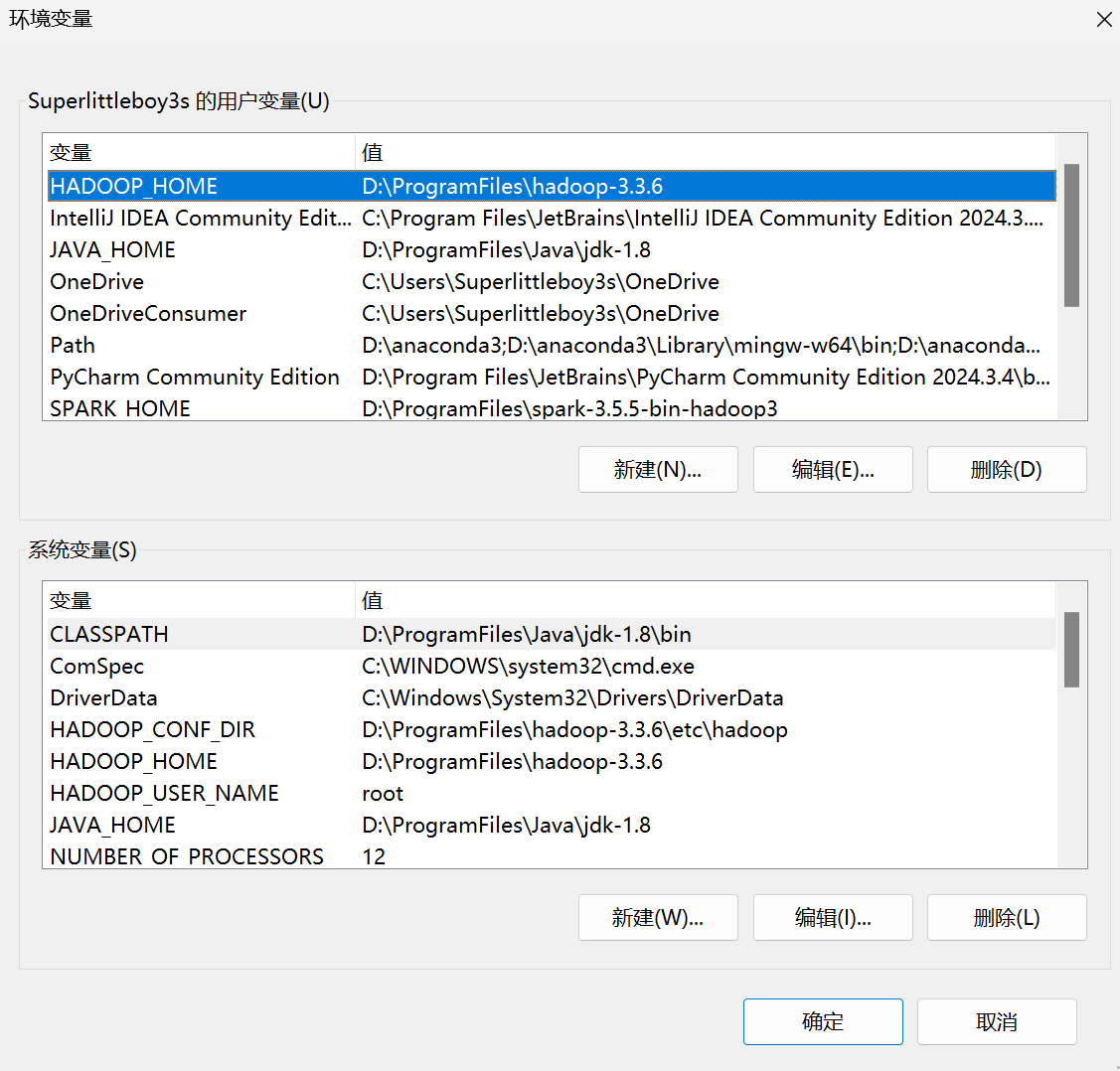
设置好之后,在cmd输入:
hadoop version如果看到以下界面,则安装成功:
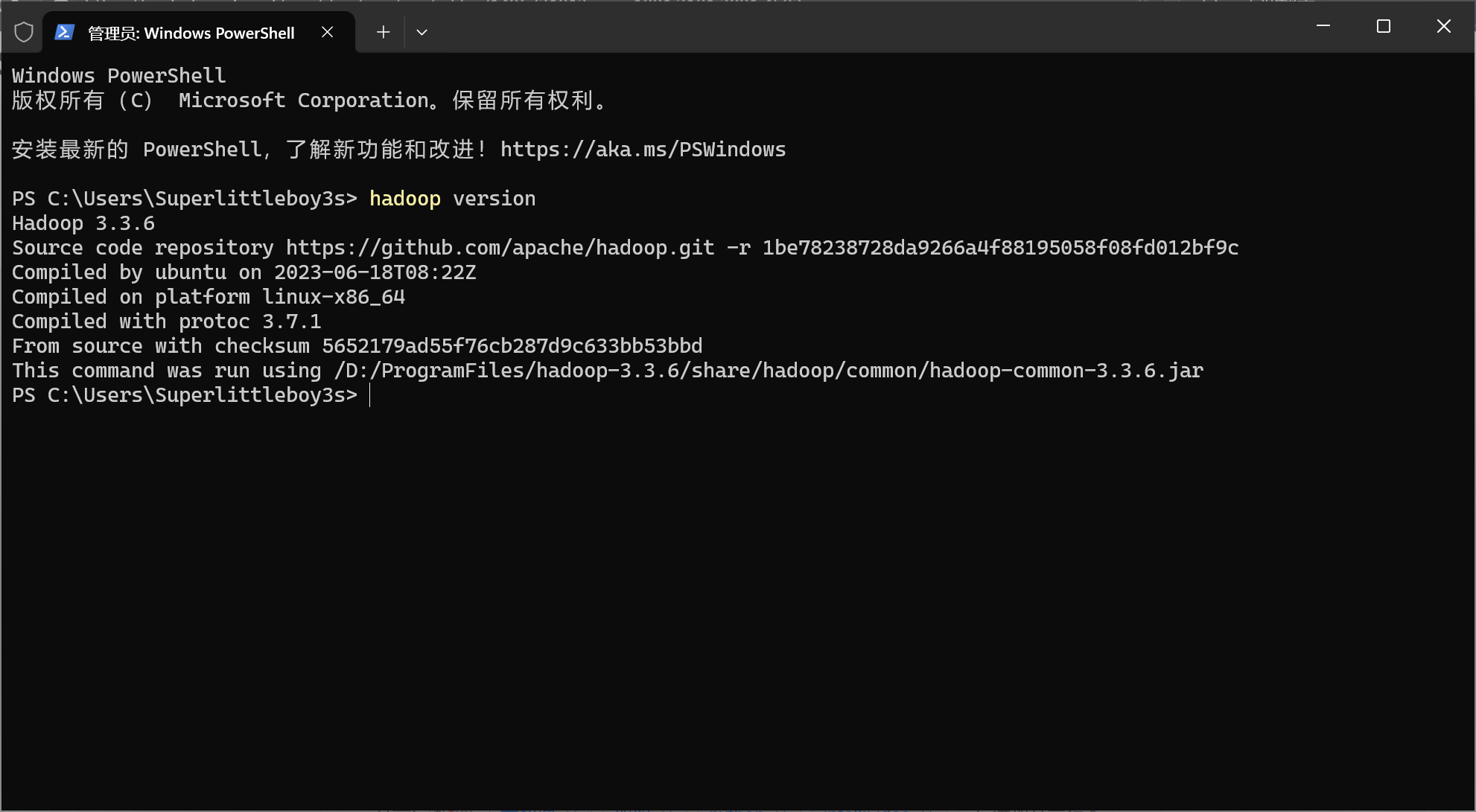
下面这几步可以不做,但最好先配置:
打开etc/hadoop/core-site.xml,加入:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-3.4.1/tmp</value>
<description>Hadoop临时目录</description>
</property>
<!-- Hadoop文件系统的默认名称空间 -->
<property>
<name>fs.defaultFS</name>
<value>file:///</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>localhost:2181</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>由于是单机,所以配置为伪分布,文件系统是file:///;hdfs即本地文件系统。
打开hadoop-env.sh,加入:
export HADOOP_HOME=/usr/hadoop/hadoop-3.4.1
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/hdfs/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_SSH_OPTS="-p 2222"因为在Hadoop 3.x及以上版本中,加了安全权限认证,禁止未被指定的root用户直接登录。
随后打开hdfs-site.xml,加入:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value></value>
</property>
<property>
<name>dfs.namenode.edits.journal-plugin</name>
<value>qjournal://localhost.hadoop:8485</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://$HADOOP_HOME/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://$HADOOP_HOME/data/datanode</value>
</property>
</configuration>
打开mapred-site.xml,加入:
<configuration>
<!-- 指定 JobTracker 的地址和端口号,用于 MapReduce 作业的跟踪和管理 -->
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<!-- 指定本地模式运行时的临时文件目录,用于存储本地模式下生成的临时数据和输出 -->
<property>
<name>mapreduce.application.classpath</name>
<value>/$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<!-- 指定使用的 MapReduce 框架的名称,这里设置为 YARN,表示使用 Hadoop 的资源管理器 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>打开yarn-site.xml,加入:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux -services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.ha-rm.ids</name>
<values>rm1</values>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8280</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>localhost</value>
</property>
<property>
<name>yarn.resourcemanager.principal</name>
<value>localhost/_HOST@YOUR.REALM</value>
</property>
<property>
<name>yarn.resourcemanager.connect-timeout.ms</name>
<value>80000</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>localhost:9350</value>
</property>
</configuration>需要保证端口之间不相冲突。而WSL上若要装Hadoop,则可能需要考虑ssh这一步。
验证时,打开D:\ProgramFiles\hadoop-3.3.6\sbin,运行.\start-all.cmd
若看到以下内容,则安装成功: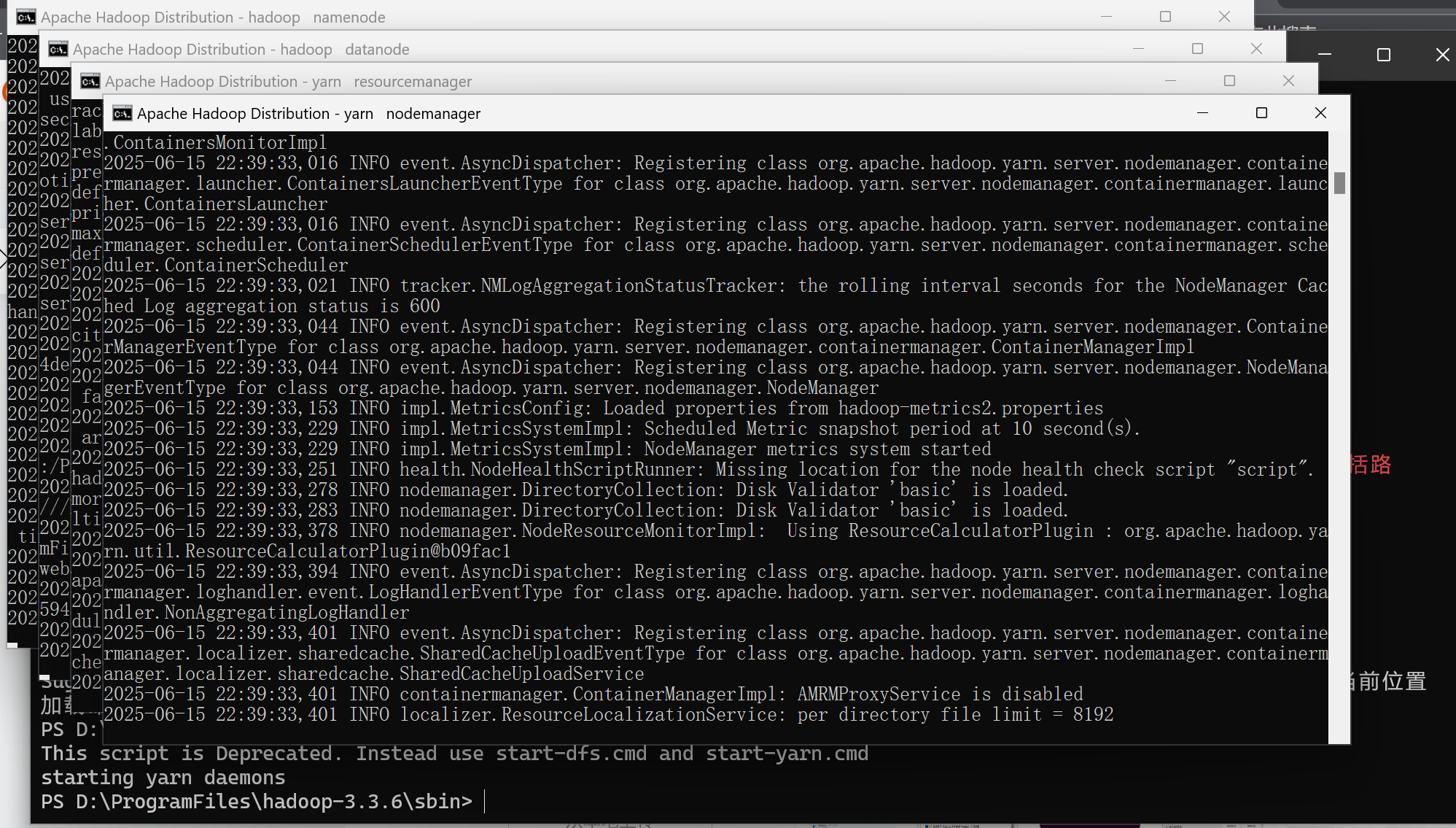
在使用spark时,不需要hadoop的启动。
随后再下载spark并解压,解压后依旧放在ProgramFile文件夹里,我用的是3.5.5版本。
然后加入环境变量:
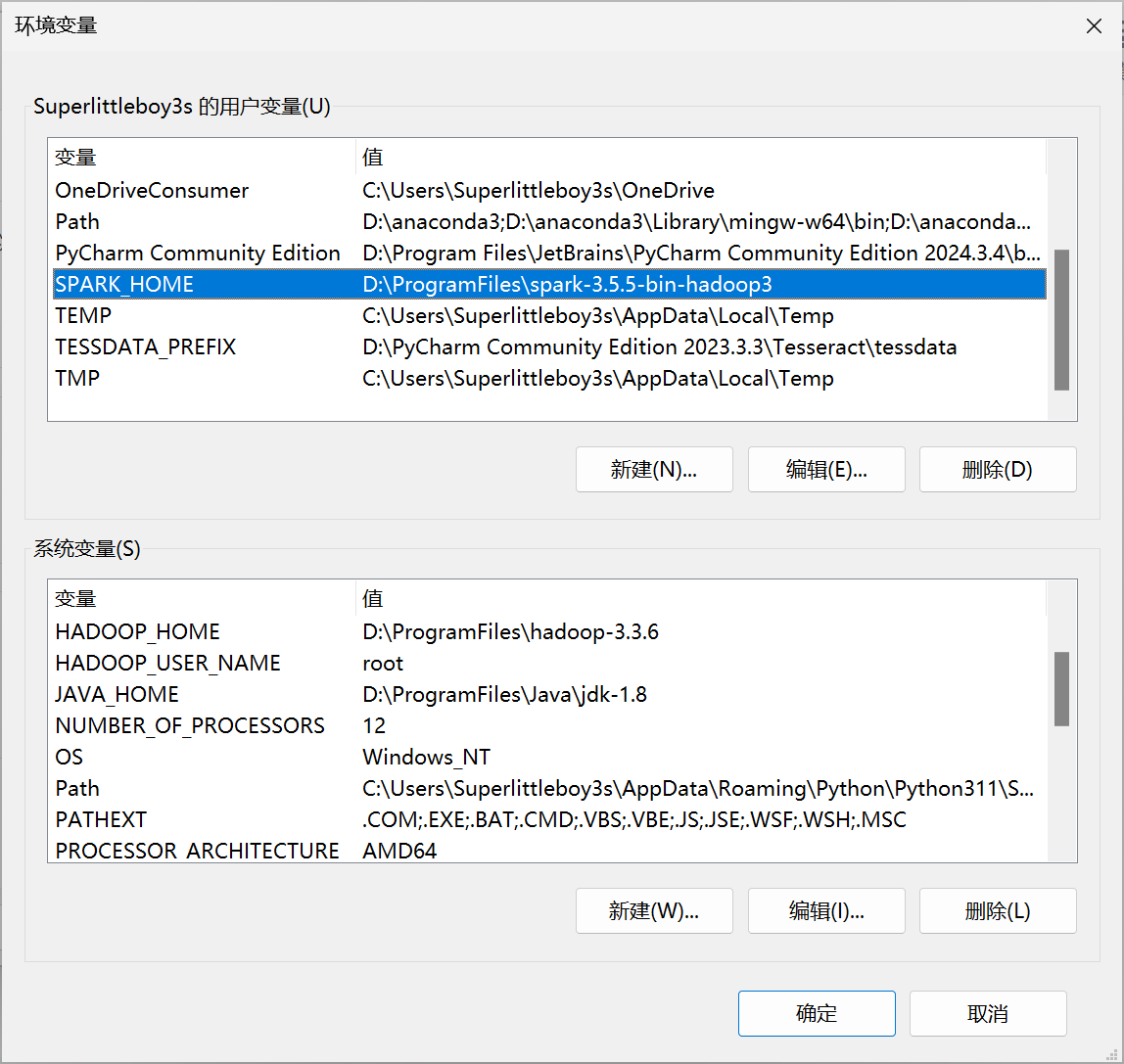
系统变量和用户变量都选择D:\ProgramFiles\spark-3.5.5-bin-hadoop3
Path中输入:%SPARK_HOME%\bin
随后打开cmd,输入Spark-Shell,若输出以下页面则安装成功。
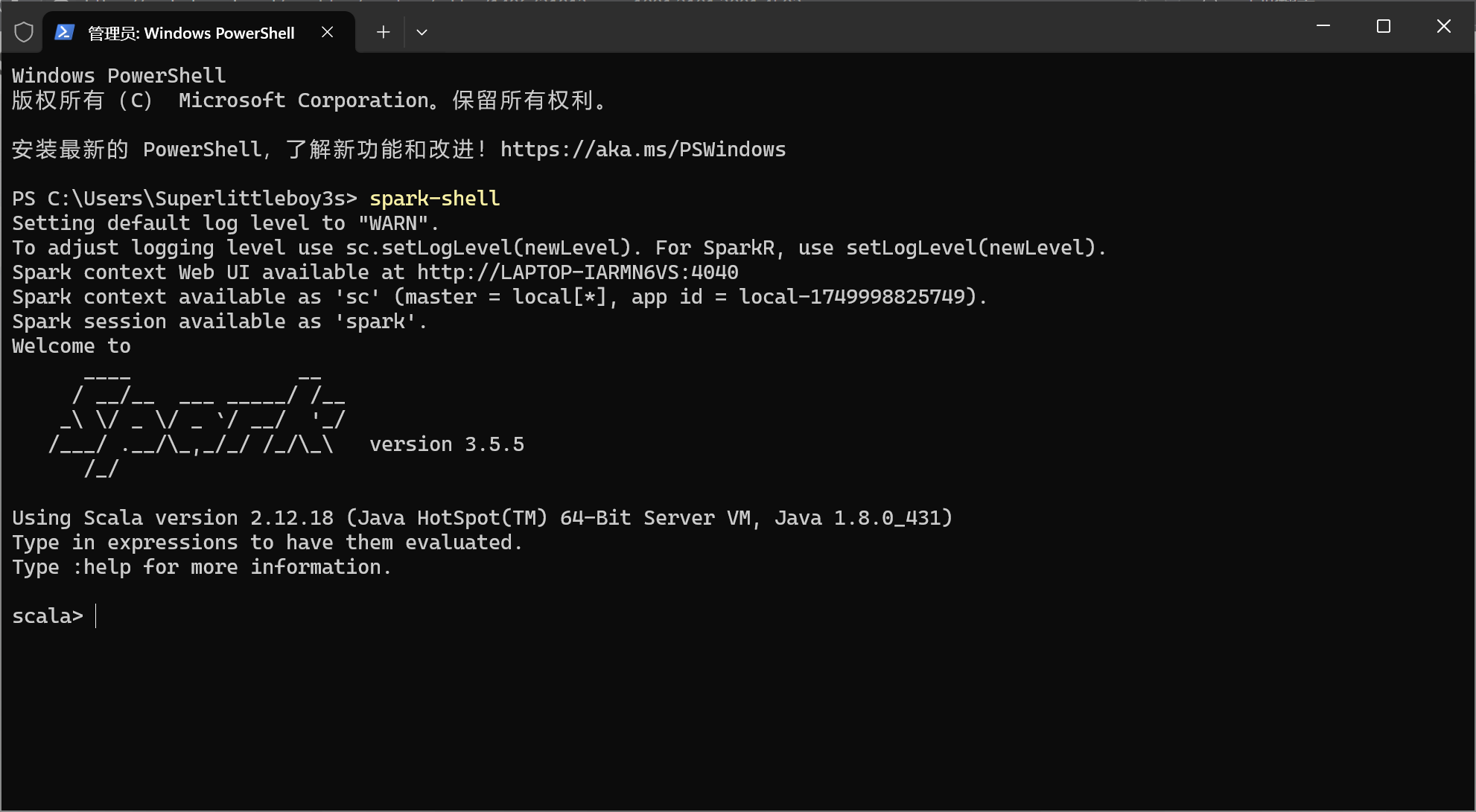
说到这里,便是我不推荐在Windows安装spark的第二个原因——迷之环境——spark环境防踩坑细节
在windows里,spark-shell和pyspark的部分运行会因为环境不兼容而崩溃/报错,如使用:quit会因为删除失败报错;pyspark里转dataframe为pandas以及dataframe.show()时,也会各种报错。因此这种情况下还是乖乖在WSL里安装吧~
从下一期开始,将开始提及到轻量大数据架构的采集层架构,环境配置先告一段落~

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)