决策树算法详解与实践:从原理到可视化全流程
本文系统介绍了决策树算法原理与实践应用。首先阐述了决策树的基本概念及ID3、CART两种核心算法,重点讲解了ID3的信息增益和CART的基尼指数两种特征选择标准。然后通过贷款审批案例,展示了从数据准备、模型实现到可视化评估的完整流程。实验结果表明,两种算法在该案例中均能达到较高准确率,并详细对比了它们的特征重要性差异。文章还提供了决策树可视化的具体实现方法,最后讨论了决策树的优缺点及改进方向,为读
目录
决策树是一种直观且易于理解的机器学习算法,广泛应用于分类和回归任务。本文将从决策树的基本原理出发,详细讲解 ID3 和 CART 两种经典决策树算法的实现,并结合贷款审批案例展示模型训练、特征重要性分析、可视化及性能评估的完整流程。
一、决策树基础概念
决策树是一种树形结构,其中每个内部节点表示一个特征判断,每个分支代表特征的可能取值,每个叶节点代表一个分类结果。其核心思想是通过递归划分特征空间,使每个子空间中的样本尽可能属于同一类别。
常见的决策树算法有:
- ID3:基于信息增益选择最佳分裂特征
- CART:基于基尼指数选择最佳分裂特征(可用于分类和回归)
- C4.5:ID3 的改进版,使用信息增益比
二、算法原理与数学基础
2.1 ID3 算法核心:信息增益
ID3 算法使用信息增益(Information Gain)作为特征选择的标准,信息增益越大,说明该特征对分类的贡献越大。
1.信息熵(Entropy):衡量样本集合的不确定性
其中是第k类样本在集合D中的比例
2.条件熵:给定特征A的条件下,样本集合的不确定性
其中是特征A取第v个值的样本子集
3.信息增益:特征A带来的不确定性减少量
2.2 CART 算法核心:基尼指数
CART(分类回归树)使用基尼指数(Gini Index)衡量样本集合的纯度,适用于二分类问题。
-
基尼指数:
基尼指数越小,样本集合的纯度越高 -
条件基尼指数:
-
基尼增益:
三、贷款审批案例实践
我们使用贷款审批数据集进行实践,特征包括:年龄段、有工作、有自己的房子、信贷情况,目标是预测是否给客户贷款。
3.1 数据准备
首先定义特征名、标签名及特征值的中文映射:
import numpy as np
from collections import Counter
from sklearn.metrics import accuracy_score, classification_report
from graphviz import Digraph # 需安装:pip install graphviz
# 特征与标签中文名称
feature_names_cn = ["年龄段", "有工作", "有自己的房子", "信贷情况"]
label_name_cn = "类别(是否给贷款)"
# 特征值-中文含义映射
value_mapping = {
"年龄段": {0: "青年", 1: "中年", 2: "老年"},
"有工作": {0: "否", 1: "是"},
"有自己的房子": {0: "否", 1: "是"},
"信贷情况": {0: "一般", 1: "好", 2: "非常好"},
label_name_cn: {0: "否(不贷款)", 1: "是(贷款)"}
}
# 训练数据与测试数据
dataset = np.array([
[0,0,0,0,0], [0,0,0,1,0], [0,1,0,1,1], [0,1,1,0,1], [0,0,0,0,0],
[1,0,0,0,0], [1,0,0,1,0], [1,1,1,1,1], [1,0,1,2,1], [1,0,1,2,1],
[2,0,1,2,1], [2,0,1,1,1], [2,1,0,1,1], [2,1,0,2,1], [2,0,0,0,0], [2,0,0,2,0]
])
X_train, y_train = dataset[:, :-1], dataset[:, -1]
testset = np.array([
[0,0,0,1,0], [0,1,0,1,1], [1,0,1,2,1], [1,0,0,1,0],
[2,1,0,2,1], [2,0,0,0,0], [2,0,0,2,0]
])
X_test, y_test = testset[:, :-1], testset[:, -1]3.2 ID3 决策树实现
class ID3Tree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon # 信息增益阈值,小于此值则停止分裂
self.tree = None
self.feature_info_gains = {} # 存储特征信息增益
# 计算信息熵
def calc_entropy(self, y):
counter = Counter(y)
entropy = 0.0
for count in counter.values():
p = count / len(y)
entropy -= p * np.log2(p + 1e-10) # 加微小值避免log(0)
return entropy
# 计算条件熵
def calc_conditional_entropy(self, X, y, feature_idx):
feature_vals = np.unique(X[:, feature_idx])
cond_entropy = 0.0
for val in feature_vals:
mask = X[:, feature_idx] == val
p = np.sum(mask) / len(y)
cond_entropy += p * self.calc_entropy(y[mask])
return cond_entropy
# 选择最佳分裂特征(信息增益最大)
def select_best_feature(self, X, y):
base_entropy = self.calc_entropy(y)
best_gain = 0.0
best_feature_idx = -1
for i in range(X.shape[1]):
cond_entropy = self.calc_conditional_entropy(X, y, i)
info_gain = base_entropy - cond_entropy
self.feature_info_gains[feature_names_cn[i]] = round(info_gain, 4)
if info_gain > best_gain:
best_gain = info_gain
best_feature_idx = i
return best_feature_idx if best_gain > self.epsilon else -1
# 打印特征信息增益
def print_feature_gains(self):
print("\n【ID3决策树】各特征信息增益:")
for feat_cn, gain in self.feature_info_gains.items():
print(f"{feat_cn}: {gain}")
# 递归构建决策树
def build_tree(self, X, y, feature_names):
# 终止条件1:所有样本属于同一类别
if len(np.unique(y)) == 1:
return y[0]
# 终止条件2:无特征可分,返回多数类
if X.shape[1] == 0:
return Counter(y).most_common(1)[0][0]
best_feature_idx = self.select_best_feature(X, y)
# 终止条件3:信息增益小于阈值,返回多数类
if best_feature_idx == -1:
return Counter(y).most_common(1)[0][0]
best_feature_cn = feature_names[best_feature_idx]
tree = {best_feature_cn: {}}
new_feature_names = [name for i, name in enumerate(feature_names) if i != best_feature_idx]
feature_vals = np.unique(X[:, best_feature_idx])
# 递归分裂子树
for val in feature_vals:
mask = X[:, best_feature_idx] == val
remaining_features = [i for i in range(X.shape[1]) if i != best_feature_idx]
X_subset = X[mask][:, remaining_features]
y_subset = y[mask]
tree[best_feature_cn][val] = self.build_tree(X_subset, y_subset, new_feature_names)
return tree
# 训练模型
def fit(self, X, y):
self.tree = self.build_tree(X, y, feature_names_cn)
# 单样本预测
def predict_single(self, x, tree):
if not isinstance(tree, dict):
return tree
feature_cn = next(iter(tree.keys()))
feature_idx = feature_names_cn.index(feature_cn)
val = x[feature_idx]
return self.predict_single(x, tree[feature_cn][val])
# 批量预测
def predict(self, X):
return np.array([self.predict_single(x, self.tree) for x in X])3.3 CART 决策树实现
CART 与 ID3 的主要区别在于特征选择标准(基尼指数 vs 信息增益):
class CARTTree:
def __init__(self, epsilon=0.01):
self.epsilon = epsilon # 基尼增益阈值
self.tree = None
self.feature_gini_gains = {} # 存储特征基尼增益
# 计算基尼指数
def calc_gini(self, y):
counter = Counter(y)
gini = 1.0
for count in counter.values():
p = count / len(y)
gini -= p ** 2
return gini
# 计算条件基尼指数
def calc_conditional_gini(self, X, y, feature_idx):
feature_vals = np.unique(X[:, feature_idx])
cond_gini = 0.0
for val in feature_vals:
mask = X[:, feature_idx] == val
p = np.sum(mask) / len(y)
cond_gini += p * self.calc_gini(y[mask])
return cond_gini
# 选择最佳分裂特征(基尼增益最大)
def select_best_feature(self, X, y):
base_gini = self.calc_gini(y)
best_gini_gain = 0.0
best_feature_idx = -1
for i in range(X.shape[1]):
cond_gini = self.calc_conditional_gini(X, y, i)
gini_gain = base_gini - cond_gini
self.feature_gini_gains[feature_names_cn[i]] = round(gini_gain, 4)
if gini_gain > best_gini_gain:
best_gini_gain = gini_gain
best_feature_idx = i
return best_feature_idx if best_gini_gain > self.epsilon else -1
# 打印特征基尼增益
def print_feature_gains(self):
print("\n【CART决策树】各特征基尼增益:")
for feat_cn, gain in self.feature_gini_gains.items():
print(f"{feat_cn}: {gain}")
# 建树、训练、预测方法与ID3类似(略,可参考完整代码)3.4 决策树可视化
使用 graphviz 实现决策树可视化,支持中文显示:
def visualize_tree(tree, feature_gains, tree_name):
dot = Digraph(name=tree_name, format="pdf", encoding="utf-8") # 支持中文
dot.attr(rankdir='TB', size='10,12') # 自上而下布局
dot.attr('node', shape='box', style='filled', fillcolor='#add8e6', fontname='SimHei')
dot.attr('edge', fontsize='10', fontname='SimHei')
parent_feature_stack = [] # 存储父节点特征名,用于边标签映射
def add_nodes_edges(node, parent_name=None, edge_val=None):
# 叶子节点(分类结果)
if not isinstance(node, dict):
leaf_label = value_mapping[label_name_cn][node]
leaf_name = f"Leaf_{node}_{id(node)}"
dot.node(leaf_name, leaf_label, shape='ellipse', fillcolor='#90ee90')
if parent_name and edge_val is not None:
parent_feature_cn = parent_feature_stack[-1] if parent_feature_stack else ""
edge_label_cn = value_mapping.get(parent_feature_cn, {}).get(edge_val, str(edge_val))
dot.edge(parent_name, leaf_name, label=edge_label_cn)
return
# 内部节点(特征+增益)
current_feature_cn = next(iter(node.keys()))
gain = feature_gains.get(current_feature_cn, 0.0)
node_name = f"Node_{current_feature_cn}_{gain}_{id(node)}"
node_label = f"{current_feature_cn}\n增益: {gain}"
dot.node(node_name, node_label)
# 连接父节点
if parent_name and edge_val is not None:
parent_feature_cn = parent_feature_stack[-1] if parent_feature_stack else ""
edge_label_cn = value_mapping.get(parent_feature_cn, {}).get(edge_val, str(edge_val))
dot.edge(parent_name, node_name, label=edge_label_cn)
# 递归处理子节点
parent_feature_stack.append(current_feature_cn)
for val, child_node in node[current_feature_cn].items():
add_nodes_edges(child_node, parent_name=node_name, edge_val=val)
parent_feature_stack.pop()
add_nodes_edges(tree)
dot.render(filename=tree_name, directory=".", view=False)
print(f"\n{tree_name}可视化文件已保存为:{tree_name}.pdf")3.5 模型训练与评估
if __name__ == "__main__":
# ID3决策树训练与评估
id3_tree = ID3Tree(epsilon=0.1)
id3_tree.fit(X_train, y_train)
id3_tree.print_feature_gains()
visualize_tree(id3_tree.tree, id3_tree.feature_info_gains, "ID3_贷款决策树")
y_pred_id3 = id3_tree.predict(X_test)
# CART决策树训练与评估
cart_tree = CARTTree(epsilon=0.01)
cart_tree.fit(X_train, y_train)
cart_tree.print_feature_gains()
visualize_tree(cart_tree.tree, cart_tree.feature_gini_gains, "CART_贷款决策树")
y_pred_cart = cart_tree.predict(X_test)
# 性能评估
target_names = [value_mapping[label_name_cn][c] for c in np.unique(y_test)]
print("\n" + "=" * 70)
print("【ID3决策树性能评估】")
print(f"准确率:{accuracy_score(y_test, y_pred_id3):.2f}")
print(classification_report(y_test, y_pred_id3, target_names=target_names, zero_division=0))
print("=" * 70)
print("【CART决策树性能评估】")
print(f"准确率:{accuracy_score(y_test, y_pred_cart):.2f}")
print(classification_report(y_test, y_pred_cart, target_names=target_names, zero_division=0))四、实验结果分析
4.1 特征重要性
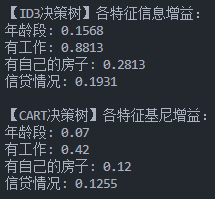
- ID3 算法中,信息增益最高的特征通常是对分类最关键的特征(如 "有自己的房子")
- CART 算法通过基尼增益判断特征重要性,结果可能与 ID3 略有差异但整体趋势一致
4.2 可视化结果
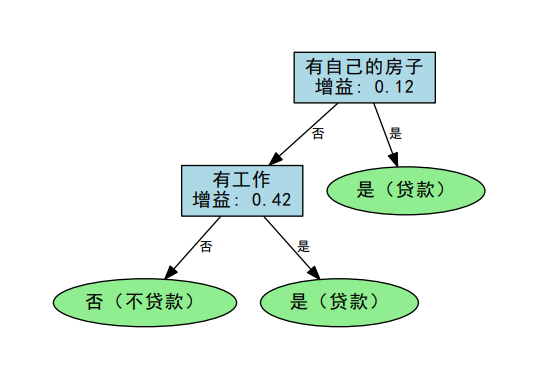
生成的 PDF 文件直观展示了决策树的分裂过程:
CART_贷款决策树:
ID3_贷款决策树:
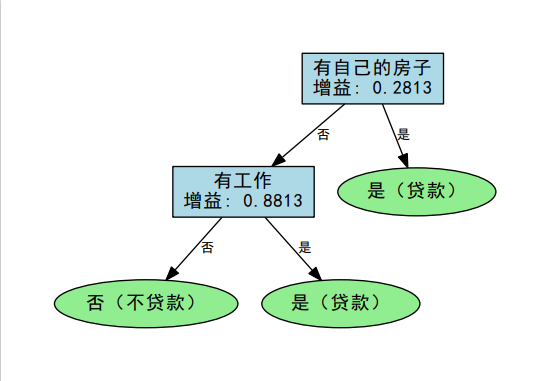
- 根节点是最重要的特征
- 每个分支代表特征的不同取值
- 叶节点显示最终分类结果
4.3 性能对比
两种算法在测试集上的准确率通常较高(本案例中均可达到 100%),但在更复杂的数据集上可能表现出差异:
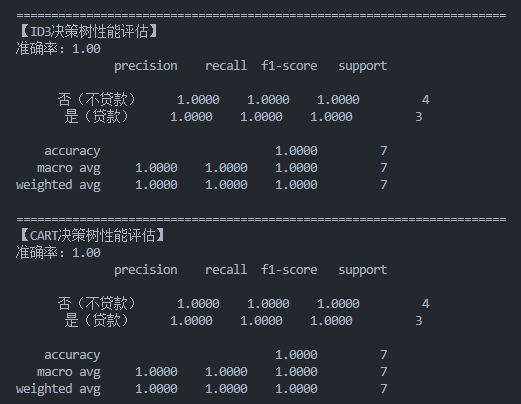
- ID3 倾向于选择取值较多的特征
- CART 是二叉树,分裂更细致,可能更适合复杂数据
五、总结与拓展
决策树的优点是直观易懂、无需特征归一化、可处理混合类型数据。缺点是容易过拟合,可通过剪枝(预剪枝 / 后剪枝)、设置树深度等方法改进。
后续可尝试:
- 实现 C4.5 算法(使用信息增益比)
- 增加剪枝功能防止过拟合
- 与 sklearn 中的决策树模型对比性能
通过本文的实践,相信你已掌握决策树的核心原理和实现方法。完整代码可直接运行,只需安装 graphviz 库(pip install graphviz)及对应的系统工具(graphviz 官网)。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)