《大数据之路1》笔记1:总述和数据技术篇
OneData是数据整合及管理的方法体系和工具,在这一体系下,构建统一、规范、可共享的全域数据体系,避免数据的冗余和重复建设,规避数据烟囱和不执行,充分发挥阿里巴巴在大数据海量、多样性的独特优势。从计算频率角度:数仓分为离线数仓和实时数仓从数据加工链路角度:ODS\DWD\DWS\ADS元数据模型整合及应用: 数据源元数据、数据仓库元数据、数据链路元数据、工具类元数据、数据质量类元数据等 元数据应
一 阿里巴巴大数据体系架构图
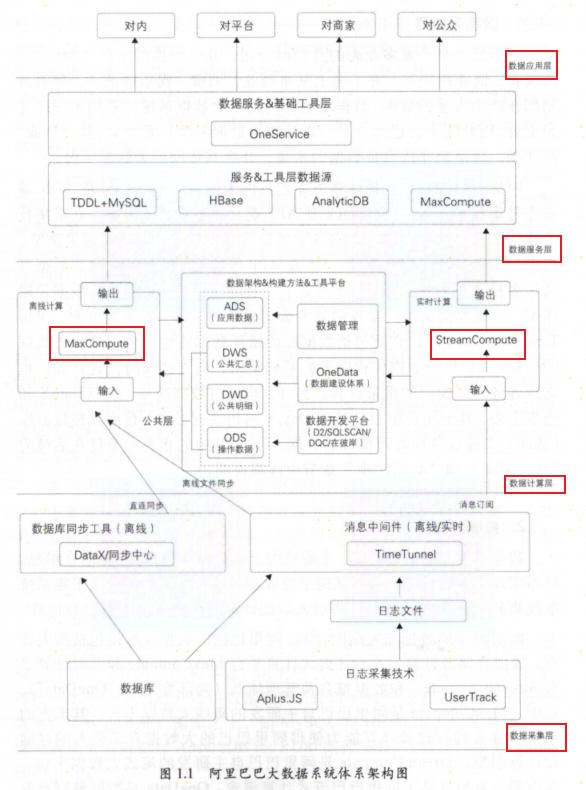
OneData是数据整合及管理的方法体系和工具,在这一体系下,构建统一、规范、可共享的全域数据体系,避免数据的冗余和重复建设,规避数据烟囱和不执行,充分发挥阿里巴巴在大数据海量、多样性的独特优势。
从计算频率角度:数仓分为离线数仓和实时数仓
从数据加工链路角度:ODS\DWD\DWS\ADS
元数据模型整合及应用: 数据源元数据、数据仓库元数据、数据链路元数据、工具类元数据、数据质量类元数据等 元数据应用主要面向数据发现、数据管理
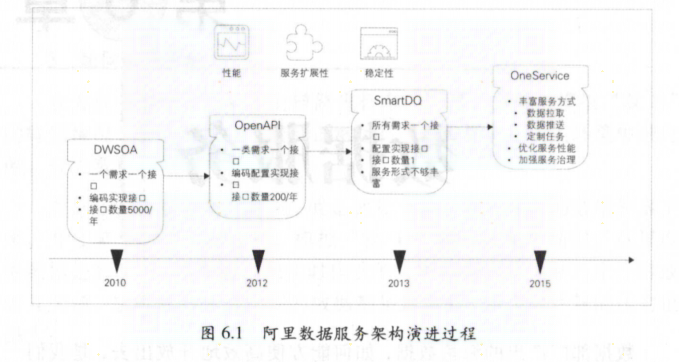
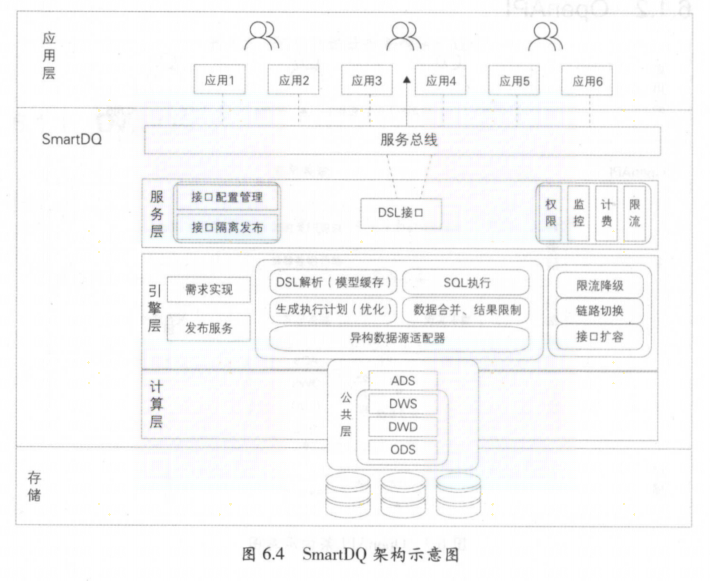
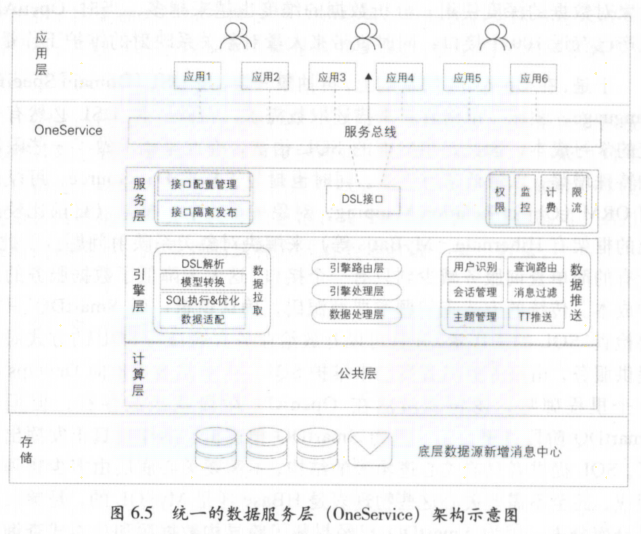
数据服务由于每天有大量的数据调用,如何在性能、稳定性、扩展性等方面更好服务用户
数据服务主要通过接口的方式对外提供数据服务,主要是简单数据查询服务、复杂数据查询服务、实时推送
二 数据技术
2.1 日志采集
日志采集两大方案:
- AplusJS: Web端
- UserTrack: APP端
采集步骤: 采集–发送–收集–解析
日志传输:
无线客户端日志上传,不是产生一条上传一条,而是生产后先存在客户端,再伺机上传
问题:什么条件下上传是非常重要的,要考虑间隔时间、日志大小、网络情况等
日志传输挑战: 挑战不是技术本身,而是如何实现日志数据的机构化和规范化组织,以及为算法提供便捷
解决方案:1. 日志分流与定制处理 根据日志类型、日志规模、业务特点实现定制处理;2. 采集与计算一体化设计
2.2 数据同步
这里考虑的是数据同步过程中,数据能否兼容的问题,源业务系统数据类型多种多样,数据有结构化数据、非结构化数据,来源有关系型数据库、非关系型数据库、文件系统
2.2.1 问题
数据通过如何针对不同的数据类型及业务场景选择不同的同步方式
2.2.2 解决方案
-
直连同步

定义: 直连同步是指通过定义好的规范接口 API 和基于动态链接库的方式直接连接业务库,如 BC/JD BC 等规定了统一规范的标准接口,不同的数据库基于这套标准接口提供规范的驱动,支持完全相同的函数用和 SQL 实现优点: 配置简单、实现容易,适合操作性业务系统的数据同步
缺点: 当大批量数据同步会降低甚至拖垮业务系统,不适合从业务系统到数据仓库系统的同步
-
数据文件同步
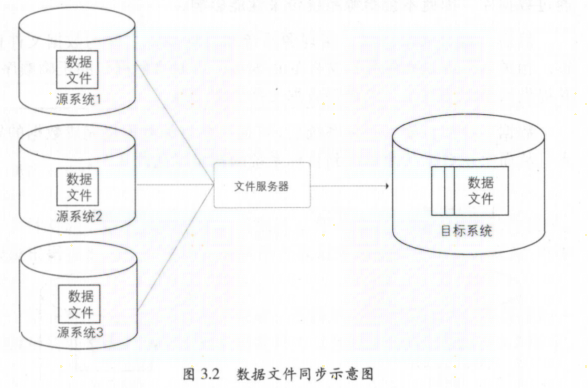
定义: 数据文件同步通过约定好的文件编码、大小、格式等,直接从源系统生成数据的文本文件,由专门的文件服务器,如 FTP 服务器传输到目标系统后,加载到目标数据库系统中
优点: 适合用于数据源包含多个异构数据库系统;互联网日志类数据,以文本方式存储的文件
缺点: 上传下载可能造成丢包或错误,一般为了解决这种问题,需要上传校验文件 -
数据库日志解析同步
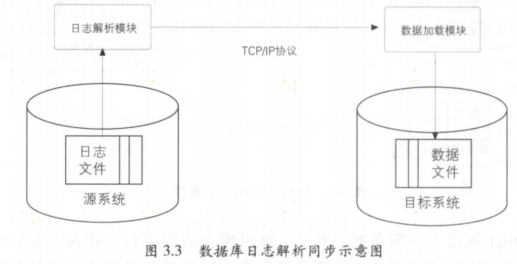
数据库日志解析同步方式实现了实时与准实时同步的能力,延迟以控制在毫秒级别,并且对业务系统的性能影响也比较小,目前广泛应用于从业务系统到数据仓库系统的增量数据同步应用之中。
缺点: 数据延迟;投入较大; 数据漂移和遗漏。
2.2.3 阿里数仓同步方式
- 批量数据同步:datax实现异构数据库或文件系统之间的高速数据交换。
- 实时数据同步: 具体是建立一个日志数据交换中心,通过专门的模块从每台服务器源源不断地读取日志数据,或这解析业务数据库系统的binglog或归档日志,将增量数据以数据流的方式不断同步到日志交换中心,然后通知所有订阅了这些数据的数据仓库系统来获取。 阿里巴巴的TimeTunnel系统就是这样的实时数据传输平台,具有高性能、实时性、顺序性、高可靠性、高可用性、可扩展性等特点
2.2.4 数据同步遇到的问题与解决方案
- 分库分表处理
为了应对业务系统产生的大量数据,需要系统具备灵活的扩展能力和高并发大数据量的处理能力,所以提出此解决方案。 从而是实现物理层将数据分布在不同数据库中的不同表,逻辑层是一张表 - 高效同步和批量同步
- 增量与全量同步的合并
- 同步性能的处理
阿里巴巴数据团队实践出了一套基于负载均衡思想的新型数据同步方案。该方案的核心思想是通过目标数据库的元数据估算同步任务的总线程数,以及通过系统预先定义的期望同步速度估算首轮同步的线程数,同时通过数据同步任务的业务优先级决定同步线程的优先级,最终提升同步任务的执行效率和稳定性 - 数据漂移的处理
数据漂移是 ODS 数据的一个顽疾,通常是指 ODS 表的同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天的变更数据
处理方法:- 多获取后一天的数据
- 通过多个时间戳字段限制时间来获取相对准确的数据
2.3 离线数据开发
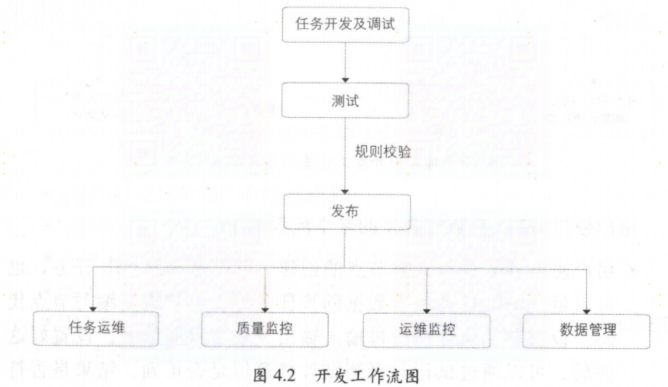
- 数据开发平台
- 统一计算平台: MaxCompute
- 统一开发平台: D2, SQLSCAN, DQC, 在彼岸
- 任务调度系统
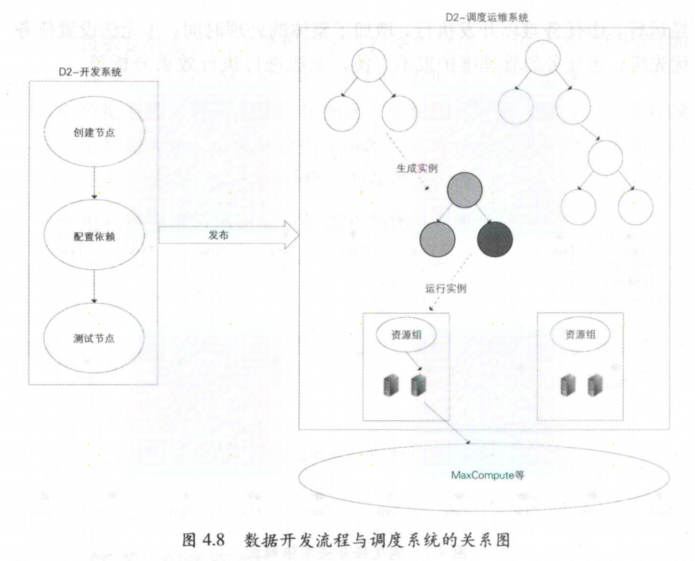
- 调度引擎(Phoneix Engine)
- 执行引擎(Alisa)
2.4 实时数据开发
- 流式数据处理特征
- 时效性高
- 常驻任务
- 性能要求高
- 应用局限性
- 流式技术架构
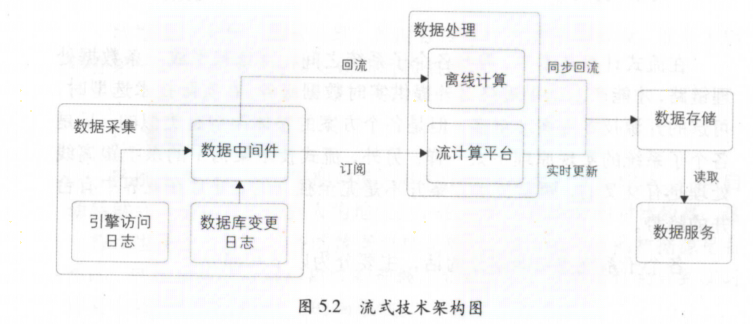
-
数据采集
采集的数据种类:数据库变更日志采集和引擎访问日志
kafka作为数据交换平台将采集到的数据分发给下游,即消息中间件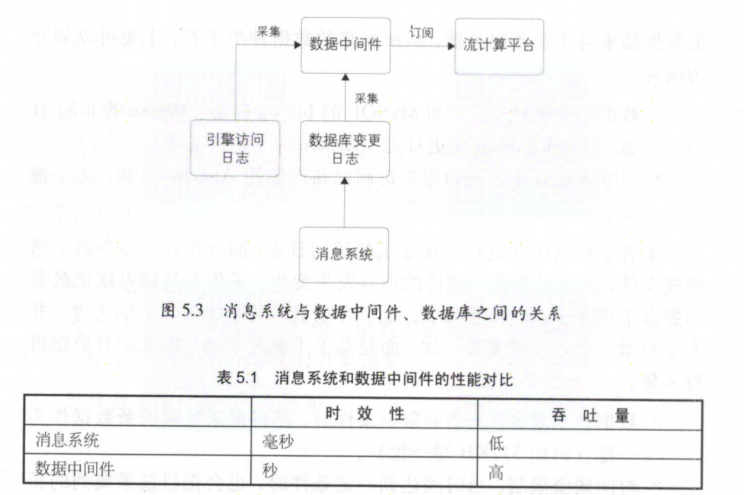
时效性和吞吐量是数据处理中的两个矛盾体 ,很多时候需要从业务的角度来权衡使用什么样的系统来做数据中转 -
数据处理
实时数据处理应用出于性能考虑,计算任务往往是多线程的。一般会根据业务主键进行分桶处理,并且大部分计算过程需要的数据都会放在内存中,这样会大大提高应用的吞吐量。当然,为了避免内存溢出,内存中过期的数据需要定时清理,可以按照 LRU(最近最少使用)算法或者业务时间集合归类清理(比如业务时间属于T-1的,会在今天凌晨进行清理
典型问题:去重指标、数据倾斜、数据处理 -
数据存储
存储的三类数据有中间计算结果、最终结果数据、维表数据,数据库种类也不同,所以要求在建表过程中考虑表命名规则 -
数据服务
-
- 流式数据模型
-
数据分层:ODS、DWD、DWS、ADS、DIM
-
多流关联:
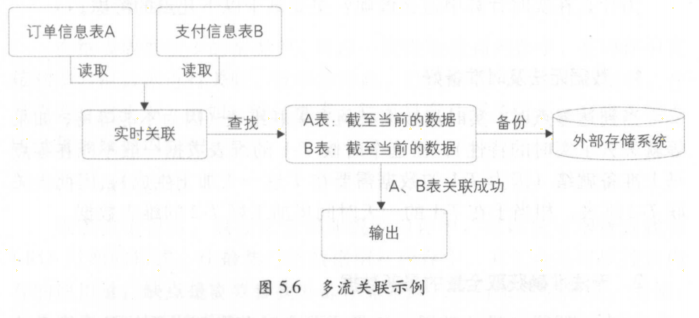
关键点在于两个表需要相互等待,只有双方都到达了,才能关联成功 -
维表使用:在实时计算中,关联维表一般使用T-2的维表数据
-
2.5 数据服务
[[《大数据之路1》笔记2:数据模型]]
[[《大数据之路1》笔记3:数据管理]]

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)