Python数据分析_RFM模型及AB测试
本文主要介绍了使用Python中的Pandas进行数据分析,主要有两个案例:RFM用户价值分析模型、AB测试效果分析。
Python数据分析_RFM模型及AB测试
【模块一:RFM用户分析模型】
【理解】RFM模型的介绍
-
目标:理解RFM模型的介绍
-
实施
-
问题1:什么是RFM模型?

-
定义:RFM模型是一种常用于客户分群和定位的模型,通过对客户的最近购买时间(Recency)、购买频率(Frequency)和购买金额(Monetary)这三个方面进行分析,对客户进行分类和评分。
-
解释
- Recency(最近交易): 表示客户最近一次交易距离现在的时间。较短的时间通常表示客户活跃度更高。
- Frequency(购买频率): 表示客户在特定期间内的购买次数。购买次数较多通常意味着该客户更为忠诚或对产品更感兴趣。
- Monetary(购买金额): 表示客户在特定期间内的购买总金额。较高的总金额通常意味着客户价值更高。
-
大体划分
- 高价值客户:这些客户在最近购买(Recency)上得分高,最近交易时间较短。在购买频率(Frequency)和购买金额(Monetary)上也表现较好,通常是企业的忠实顾客或大额消费客户。
- 一般客户:这些客户可能在Recency、Frequency和Monetary各方面表现一般,属于普通消费群体。他们对产品或服务比较满意,但还没有达到高价值客户的水平。
- 低价值客户:这部分客户在Recency、Frequency和Monetary上均表现不佳,可能已有一段时间没有购买了,购买次数不多,或者每次购买金额较低。
- 流失客户:这部分客户在最近购买时间(Recency)上得分很低,表示他们很久没有购买了,可能已经流失或者处于潜在的流失状态。
-
更细分群
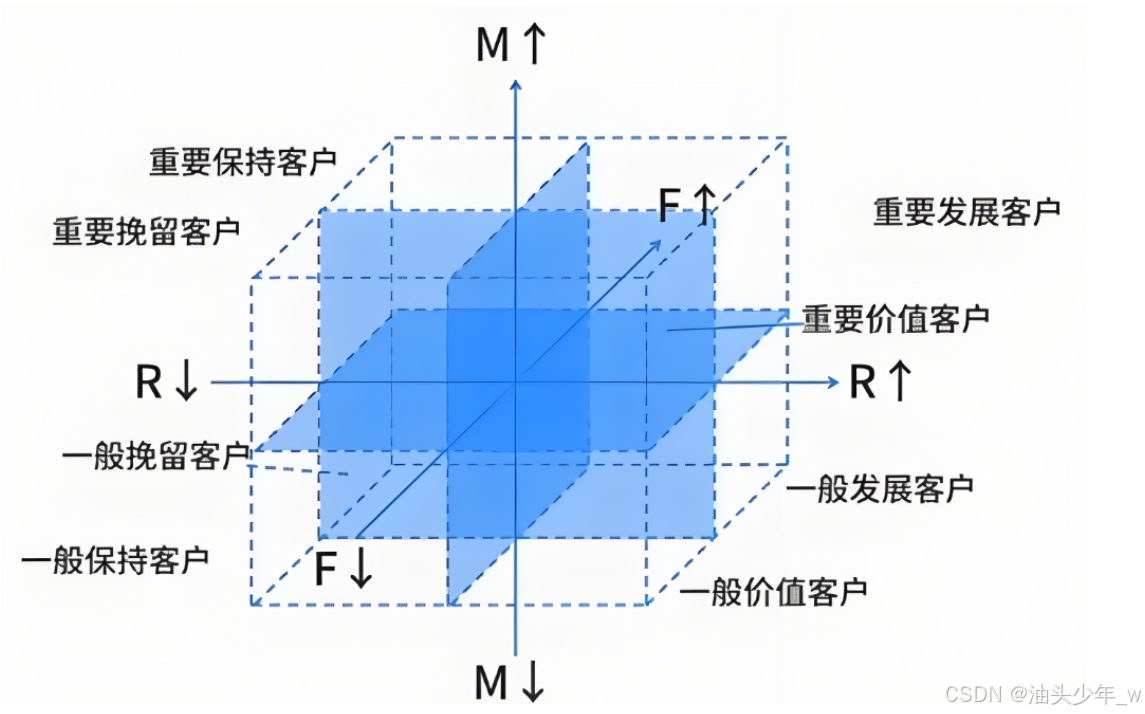
R F M 用户类别 高 高 高 重要价值用户 高 低 高 重要发展用户 低 高 高 重要保持用户 低 低 高 重要挽留用户 高 高 低 一般价值用户 高 低 低 一般发展用户 低 高 低 一般保持用户 低 低 低 一般挽留用户
-
-
问题2:为什么要做RFM模型?
-
个性化营销:对不同RFM群体的用户实施个性化的营销策略,可以提高市场反应率和购买转化率。通过了解用户的购买频率、花费金额和最近一次购买时间,企业能够更好地针对用户需求提供定制化的产品和服务。

-
资源优化:通过RFM分群,企业可以更精确地将资源投入到各类客户群体中。例如,对于高价值客户,企业可能愿意为其提供更多的折扣或增值服务;而对于低价值客户,则可以通过其他方式降低成本,并且力争提升其付费习惯。

-
忠诚度管理:RFM模型有助于企业识别哪些客户对公司更具有忠诚度,以及如何保持长期的客户关系。通过了解最近交易情况、购买频率和消费金额,企业可以在适当时机采取措施来提升客户满意度和忠诚度。

-
客户维护:针对流失客户,RFM分群可以帮助企业找到潜在的流失迹象,从而实施针对性的客户挽留方案,促使这部分客户重新产生交易行为,防止客户大规模的流失。
-
整体而言,RFM分群有助于企业更深入地了解客户的消费习惯、忠诚度和价值,指导企业制定相应的市场策略,真正实现精准营销,提高客户满意度和忠诚度,从而直接影响到企业的盈利能力和市场竞争力。
-
-
问题3:企业一般如何实现RFM模型的用户群体划分?
-
流程
-
step1:确定时间粒度和节点,基于当前时间,向前推进 每月 / 每季度 / 每年 的RFM的分析
-
step2:确定数据来源和内容,基于用户的订单信息,进行汇总,统计每个用户的RFM的值
-
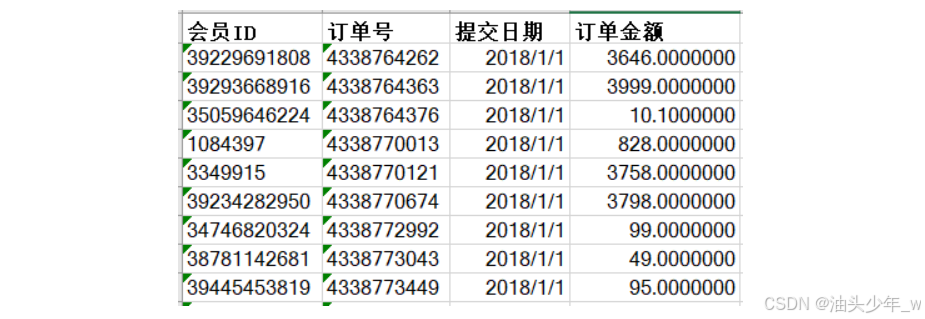
订单表:订单ID、订单时间、订单金额、用户ID
- R:用户最近一次购物时间距离计算时间之间天数
-
F:订单个数
- M:订单金额
select 用户ID , datediff(current_date(), max(订单时间)) as r = 10 , count(订单ID) as f = 100 , sum(订单金额) as m = 100 from table group by 用户ID -
step3:划分每个维度的区间,基于每个维度的数值范围将用户划分为高[3]、中[2]、低[1]三个区间
-
step4:按综合等级进行划分,基于RFM三个维度所属的区间将用户分为八种类型的用户
-
-
问题:我们怎么界定用户的R / F / M 属于 高中低哪个区间?
-
解决:1、业务实际判断,2、平均值或中位数或分位数,3、二八法则
-
栗子:基于Excel来实现RFM的分析
-
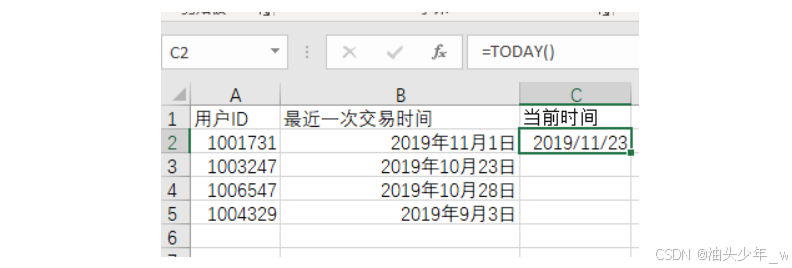
获取当前时间=TODAY()
-
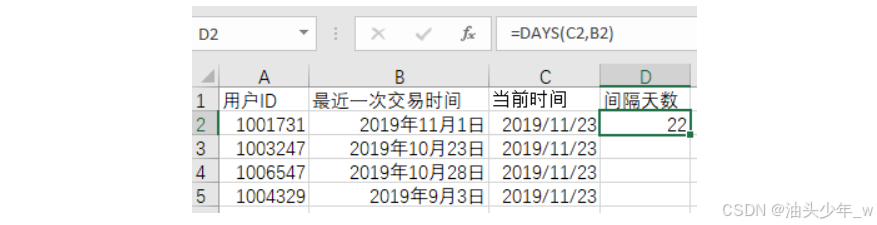
计算时间间隔:R
-
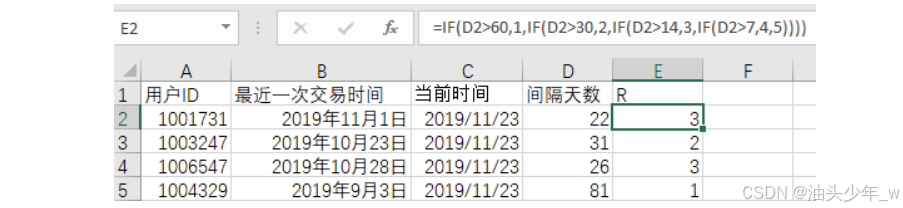
根据天数长短赋予对应的R值,R值由我们自定,时间间隔越短R值越高
=IF(D2>60,1,IF(D2>30,2,IF(D2>14,3,IF(D2>7,4,5))))
-
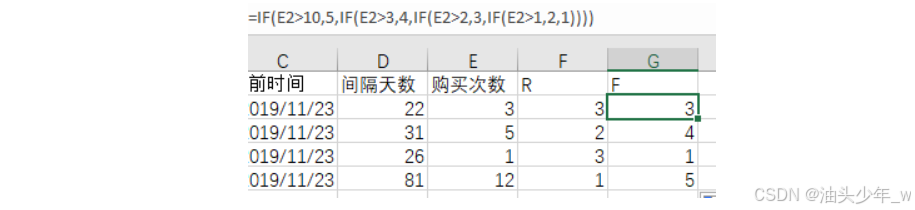
从历史数据中取出所有用户的购买次数,根据次数多少赋予对应的F分值;购买次数越多、F值越大
=IF(E2>10,5,IF(E2>3,4,IF(E2>2,3,IF(E2>1,2,1))))
-
从历史数据中汇总,求得该用户的交易总额,根据金额大小赋予对应的M值;交易总额越大、M值越大
-
=IF(F2>1000,5,IF(F2>500,4,IF(F2>300,3,IF(F2>230,2,1))))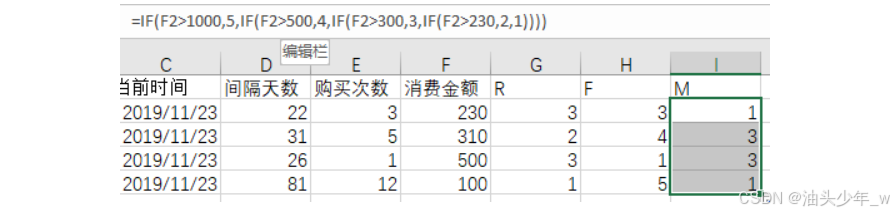
-
-
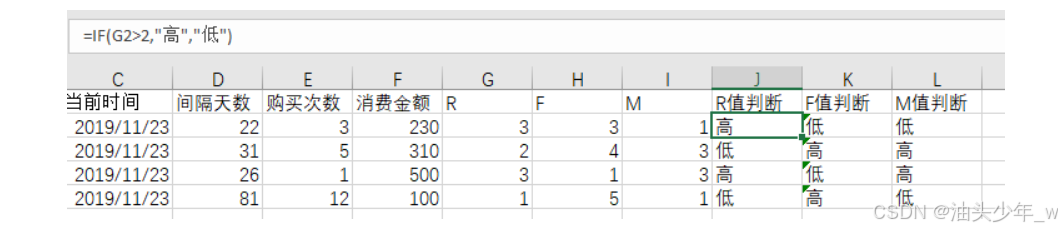
分别求出RFM的中值,例如中位数,用中值和用户的实际值进行比较,高于中值的为高,否则为低
-
-
-
-
小结:理解RFM模型的介绍
【理解】RFM案例需求分析
-
目标:理解RFM案例需求分析
-
实施
-
背景:xxx零售电商公司
-
问题:用户订单转化率较低、活动参与度较低、用户粘性较差、流失率较高
-
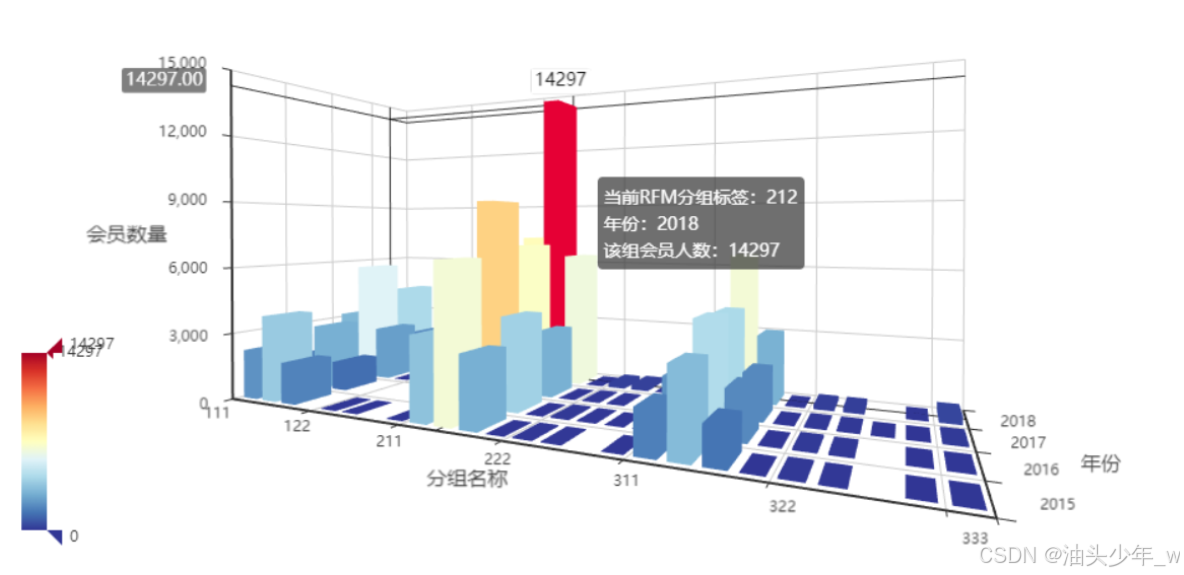
需求:基于2015 ~ 2018年的订单数据,统计每年不同群体的用户分布情况
- 1、实现向不同群体的用户推荐适合其购买偏好和消费能力的产品。比如对于高价值客户可以提供定制的产品推荐,而对于低价值客户则可以通过特价促销刺激其购买欲望。
- 2、实现更精准地设计营销活动。针对低频率但高金额的客户,企业可以推出限时促销以增加其购买频率;对于经常购买但金额较低的客户,则可以采取积分或奖励制度来激励其增加单笔交易金额。
- 3、实现制定相应的忠诚计划,对高价值客户提供更多的回馈和尊贵服务,例如定期送礼品、提前获得新品试用权益等,以此激励他们继续保持高频次的购买行为。
- 4、实现通过监测客户的最近交易时间(Recency)和购买频率(Frequency),可以识别潜在的流失客户,并通过发送个性化的优惠券或专属福利卡等方式,积极挽留这部分用户,以重返客户的消费旅程。
-
结果
-
-
小结:理解RFM案例需求分析
【理解】RFM案例数据探索
-
目标:理解RFM案例数据探索
-
实施
-
原始数据:现有2015 ~ 2018 年一共4年的用户订单数据,包括用户ID、订单号、订单金额
-
目标数据:得到每一年每种人群的用户个数【27种人群,111-333】:4 * 27 = 108
R: 高、中、低 F: 高、中、低 M: 高、中、低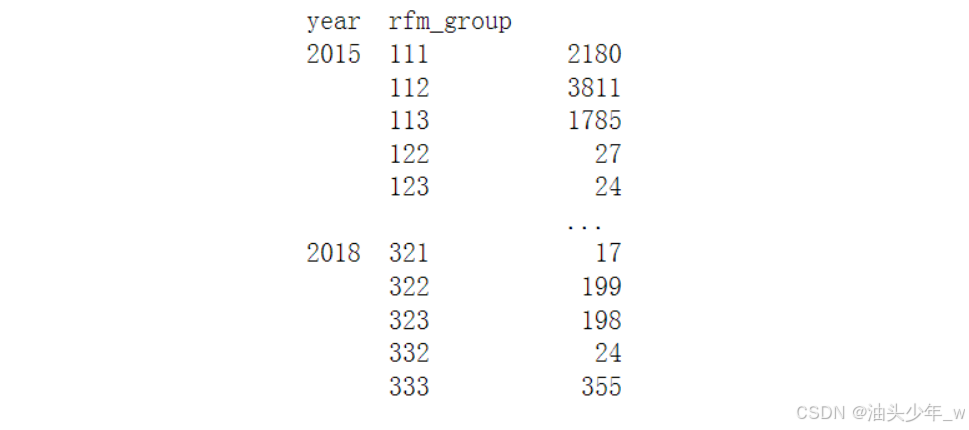
-
实现流程
-
step1:导包:导入需要使用到的分析库、时间函数库、图表库
import time # 时间库 import numpy as np # numpy库 import pandas as pd # pandas库 from pyecharts.charts import Bar3D # 3D柱形图 -
step2:导入数据:读取Excel文件,获取2015年 ~ 2018年之间的订单数据
问题: 怎么读取多个sheet的数据?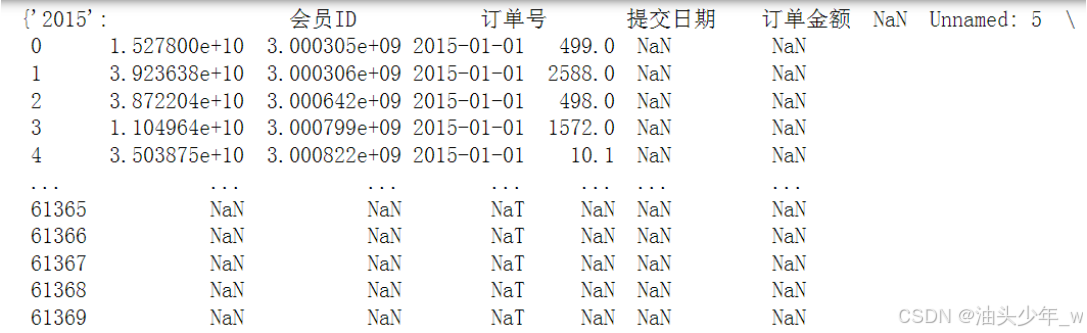
-
step3:查看数据内容结构,去除空数据:查看读取数据的内容,检查数据是否正常
问题: 怎么去除多余的空行和空列?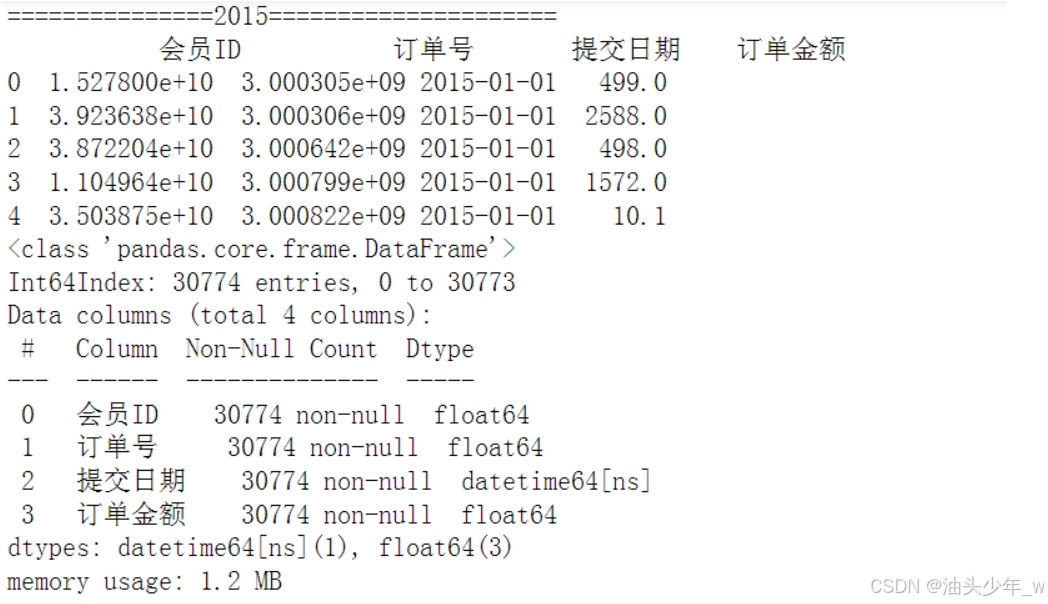
-
step4:合并数据:将4年的数据,按照行合并为一个DataFrame
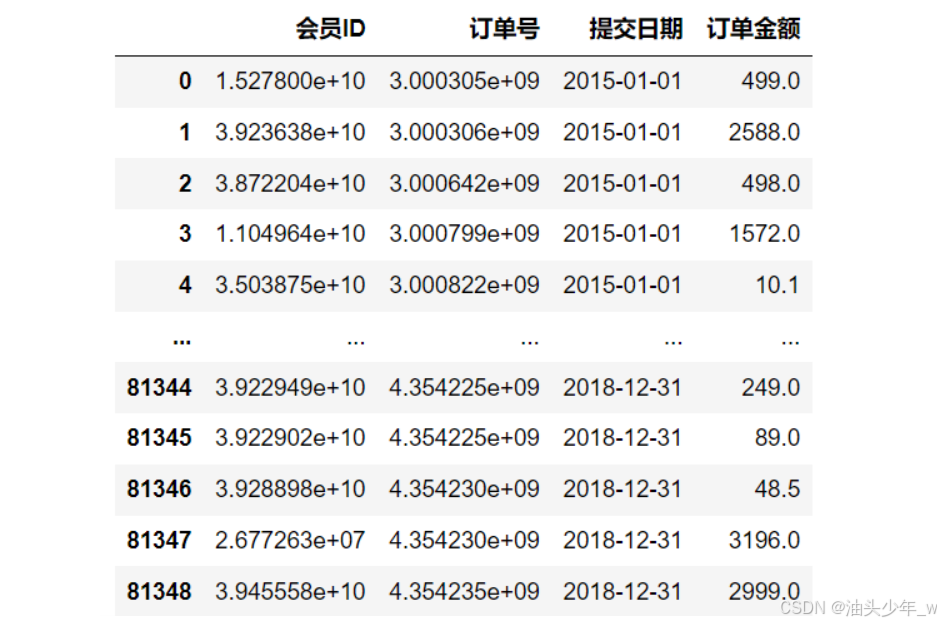
-
step5:清洗数据:基于以下的清洗需求的条件,将数据进行筛选转换,构建需要的数据列
-
筛选订单金额大于1的
-
提取年信息构建年份字段
-
-
构建每年的最大时间列:构建这一年的最后一天
-
构建时差列,计算订单提交时间与最大时间之间的差距:一年的信息
-
计算R = 这年最后一天 - 用户在这一年最后一个订单时间
-
每个用户在每一年的最后一个订单距离这一年最后一天的差值
userid order_date max_year_date date_interval 001 2015-01-01 2015-12-31 364 001 2015-01-03 2015-12-31 362 001 2015-01-06 2015-12-31 …… 001 2015-12-01 2015-12-31 001 2015-12-30 2015-12-31 1-
算法1:先取出每个用户最后一个订单时间,然后再计算与最后一天的差值
max_year_date - max(order_date) = 1 -
算法2:先计算这个用户每个订单与最大日期的差值,取最小差值
min(max_year_date - order_date) = 1
-
-
-
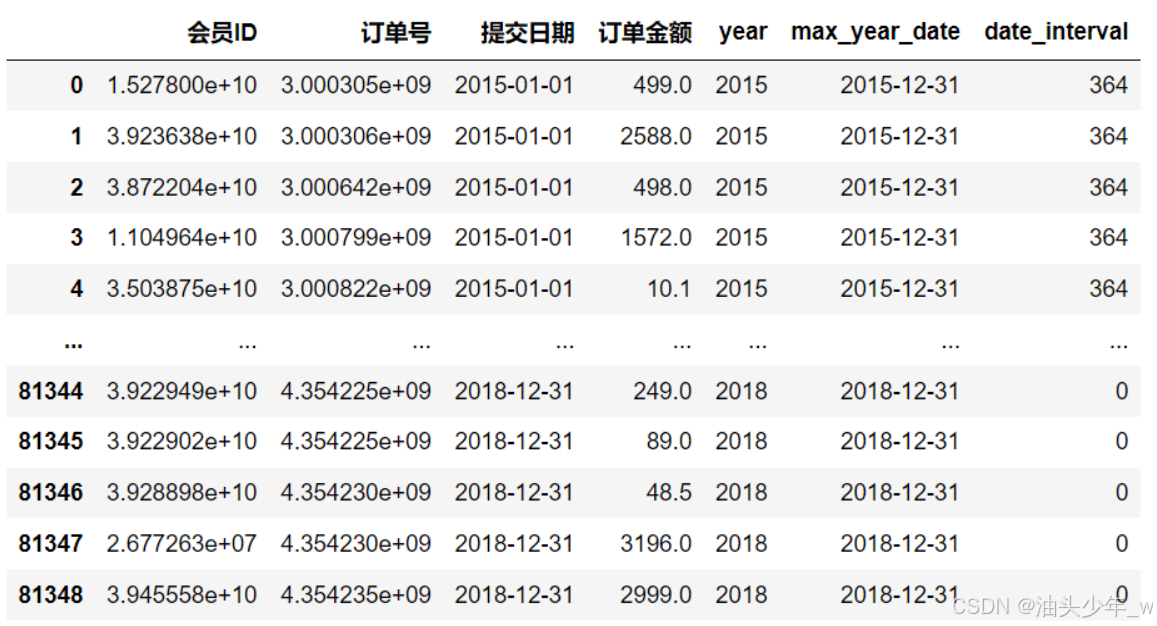
-
-
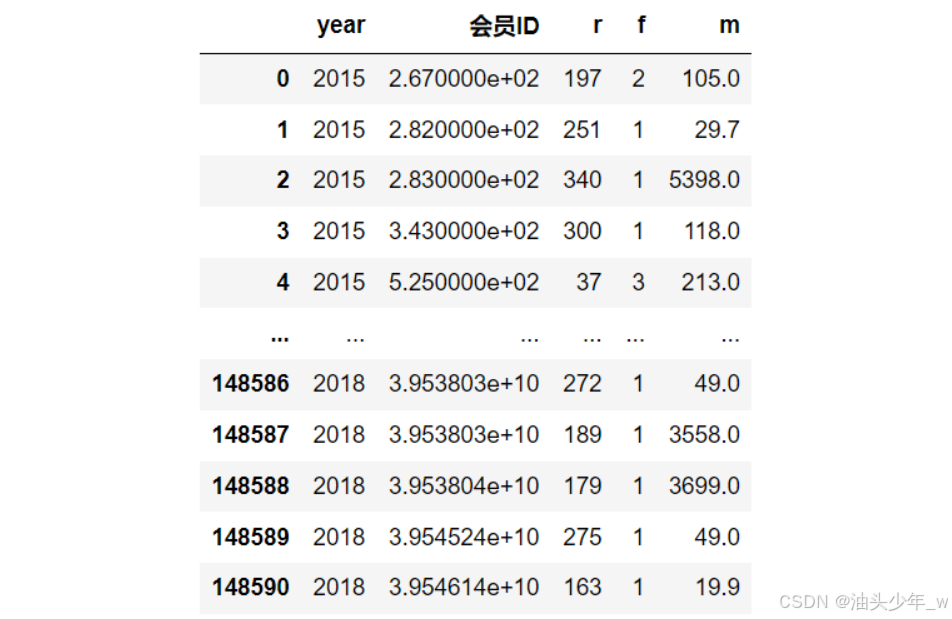
step6:计算RFM:计算每个用户在每一年的最后一个订单的消费时差、消费的订单个数、消费的订单金额
-
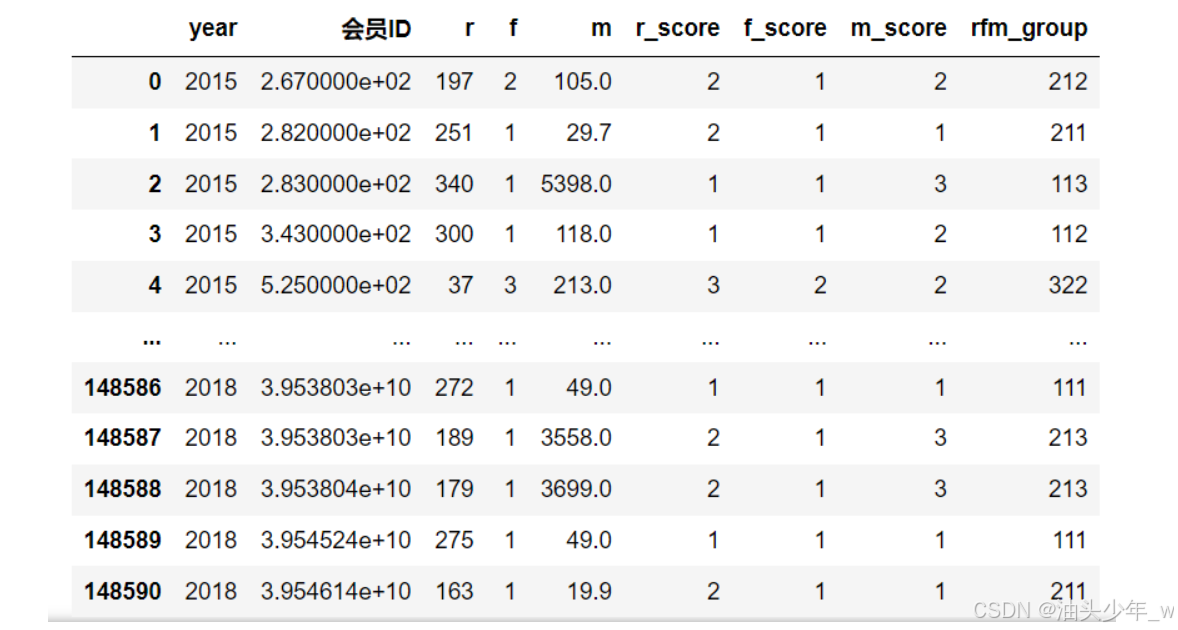
step7:转换评分:基于**分位数**,对每个用户的RFM的情况进行打分,分别标记,然后拼接得到分群标记
-
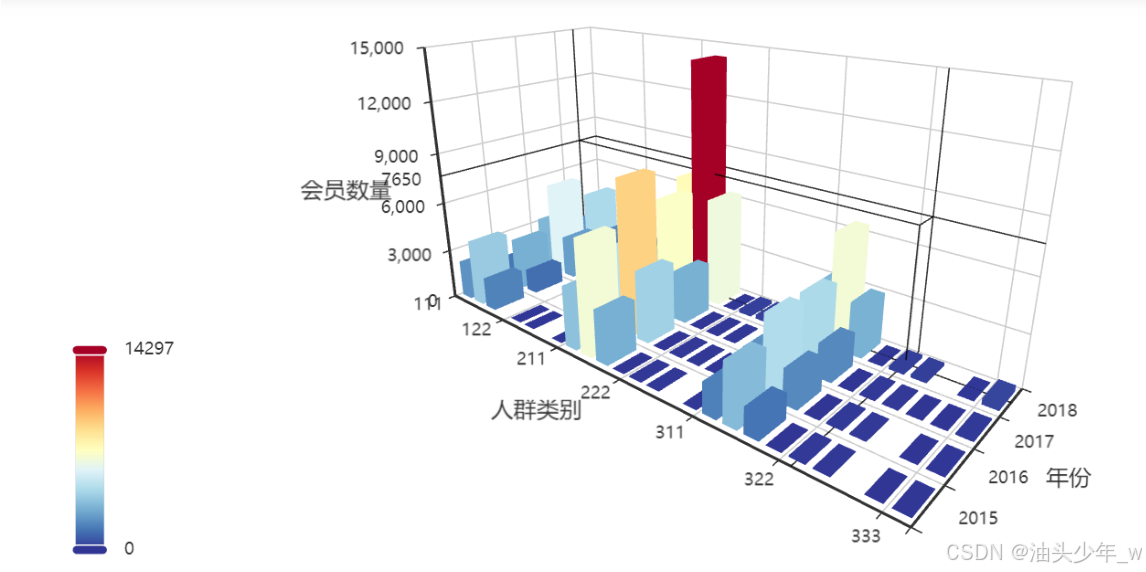
step8:构建可视化图表:基于PyEcharts对上一步的结果构建图表,展示每年每种人群的分布情况
-
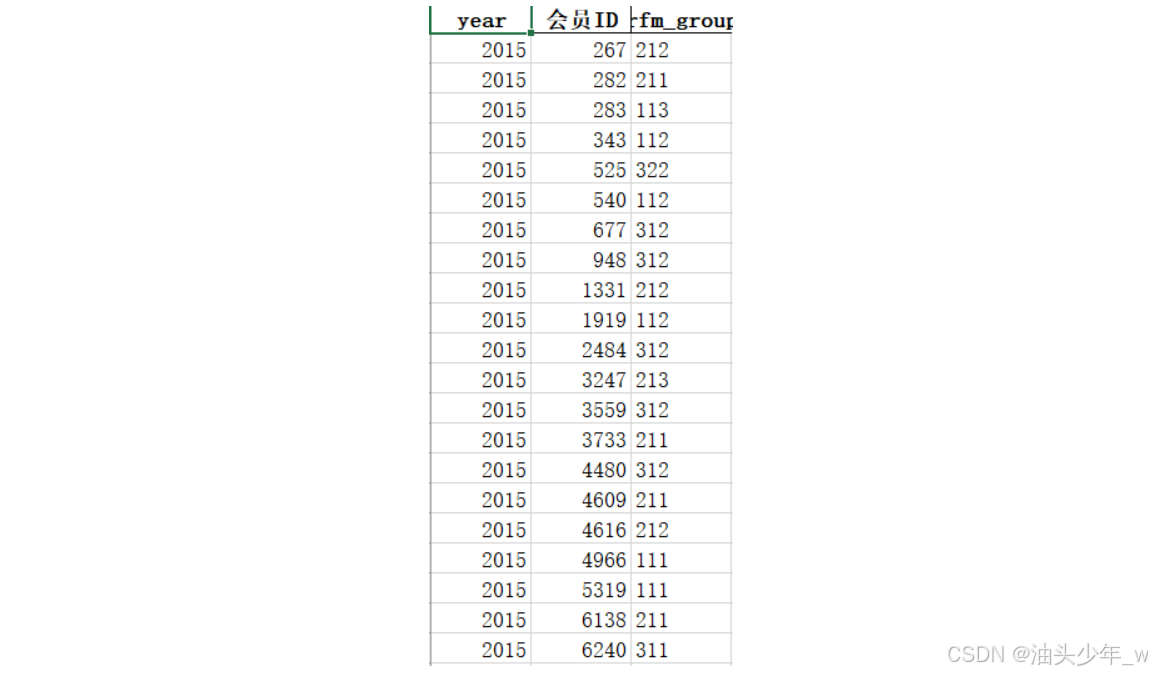
step9:保存到Excel中:将分析的结果存储到Excel文件中
-
step10:保存到MySQL中:将分析的结果存储到MySQL中
-
小结:理解RFM案例数据探索
【实现】RFM案例加载清洗
-
目标:实现RFM案例加载清洗
-
实施
-
step1:导包
import time # 时间库 import numpy as np # numpy库 import pandas as pd # pandas库 from pyecharts.charts import Bar3D # 3D柱形图 -
step2:读取数据
# 定义需要读取的Sheet的名称列表 sheet_names = ['2015','2016','2017','2018'] # 如果excel里面有多个sheet 需要指定sheet_name 才能都加载出来, 否则默认只加载第一个sheet # 返回一个字典, 用sheet_name作为key 每个key能取出一个value sheet_datas = pd.read_excel('../data/7、sales.xlsx',sheet_name =sheet_names, engine='openpyxl') sheet_datas # 查看类型 type(sheet_datas) print(sheet_datas.keys()) # 查看2016年数据内容 sheet_datas['2016'].dropna(axis=1, how='all', inplace=True) sheet_datas['2016'].dropna(axis=0, how='all', inplace=True) sheet_datas['2016'] -
step3:查看数据
# 遍历查看每个sheet的情况并去掉空值 for i in sheet_names: print('==============='+i+'=====================') sheet_datas[i].dropna(axis=1, how='all', inplace=True) sheet_datas[i].dropna(axis=0, how='all', inplace=True) print(sheet_datas[i].head()) print(sheet_datas[i].info()) print(sheet_datas[i].describe()) print('=====================================') -
step4:合并数据
# 将数据内容转换为列表 data_list = list(sheet_datas.values()) # 数据拼接 data_merge = pd.concat(data_list, ignore_index=True) data_merge.dropna(inplace = True).reset_index() # data_merge.info() data_merge -
step5:清洗数据
# 筛选订单金额大于1的 data_merge.query('订单金额>1',inplace = True) # 提取年信息构建年份字段 data_merge['year'] = data_merge['提交日期'].dt.year # 查看数据 data_merge.head(10) # 查看数据条数 data_merge.shape # 构建每年的最大时间列 # 分组转换, 类似于SQL的窗口函数, 分组之后.agg聚合, 每一组会聚合成一条结果, # 分组转换 不会改变数据的条目数, 每一组使用相同的聚合函数, 会给每一行返回这一组相同的结果 data_merge['max_year_date'] = data_merge.groupby('year')['提交日期'].transform(max) data_merge.head(10) # 查看每年的数据量 data_merge['year'].value_counts() # 构建时差列,计算订单提交时间与最大时间之间的差距 data_merge['date_interval'] = (data_merge['max_year_date']-data_merge['提交日期']).dt.days data_merge
-
-
小结:实现RFM案例加载清洗
【实现】RFM案例模型构建
-
目标:实现RFM案例模型构建
-
实施
-
step6:计算RFM
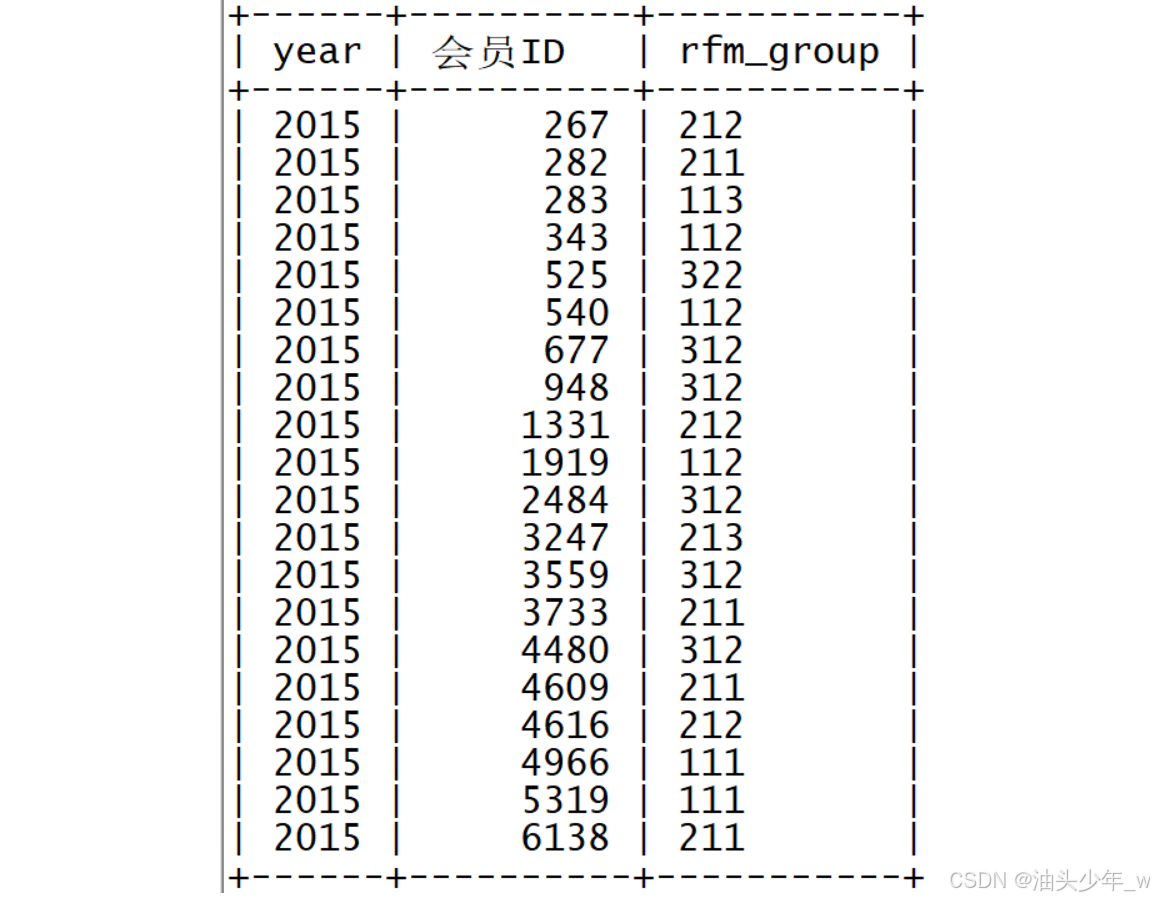
# 计算每个用户在每一年的最后一个订单的消费时差、消费的订单个数、消费的订单金额 rfm_result = data_merge.groupby(['year','会员ID'], as_index = False).agg({'date_interval':'min','订单号':'count','订单金额':'sum'}) rfm_result # 修改列名 rfm_result.columns = ['year','会员ID','r','f','m'] rfm_result -
step7:将RFM转换评分
# 禁用科学计数法 pd.set_option('display.float_format', lambda x: '%.3f' % x) # 获取RFM的分析结果 rfm_result.iloc[:,2:].describe() # 查看RFM的分析结果:转置 rfm_result.iloc[:,2:].describe().T # 这里使用 分位数作为打分的依据, 正常情况, 业务方会提供一个打分的判断条件 r_bins =[-1, 79, 255, 365] f_bins =[0, 2, 5, 130] m_bins =[0, 69, 1199, 206252] # 给 r 计算分数, 这里需要注意, r值越小分越高 rfm_result['r_score'] = pd.cut(rfm_result['r'], r_bins, labels=[i for i in range(len(r_bins)-1, 0, -1)]) # 给 f 计算分数, rfm_result['f_score'] = pd.cut(rfm_result['f'], f_bins, labels=[i for i in range(1, len(f_bins))]) # 给 m 计算分数, rfm_result['m_score'] = pd.cut(rfm_result['m'], m_bins, labels=[i for i in range(1, len(m_bins))]) rfm_result # r,f , m三个维度的分数拼接到一起, cut之后的结果 默认是pandas 的Categorical类型, 不能直接做拼接的操作, 这里用不到Categorical相关的属性 #直接转换成字符串进行拼接 rfm_result['r_score'] = rfm_result['r_score'].astype(str) rfm_result['f_score'] = rfm_result['f_score'].astype(str) rfm_result['m_score'] = rfm_result['m_score'].astype(str) rfm_result['rfm_group']= rfm_result['r_score']+rfm_result['f_score']+rfm_result['m_score'] rfm_result # 统计每一年每一种用户的个数 rs = rfm_result.groupby(['year','rfm_group'])['会员ID'].count() rs # 查询 类型为 333的用户在每一年的个数 rfm_result[rfm_result['rfm_group']=='333']['year'].value_counts() # 查看所有用户的R信息 rfm_result['r_score'] -
step8:构建可视化图表
display_data = rfm_result.groupby(['rfm_group','year'], as_index = False)['会员ID'].count() display_data.columns = ['rfm_group','year','number'] display_data['rfm_group'] = display_data['rfm_group'].astype(int) display_data # 显示图形 from pyecharts.commons.utils import JsCode import pyecharts.options as opts from pyecharts.charts import Bar3D # 3D柱形图 # 颜色池 range_color = ['#313695', '#4575b4', '#74add1', '#abd9e9', '#e0f3f8', '#ffffbf', '#fee090', '#fdae61', '#f46d43', '#d73027', '#a50026'] range_max = int(display_data['number'].max()) c = ( Bar3D()#设置了一个3D柱形图对象 .add( "",#图例 [d.tolist() for d in display_data.values],#数据 xaxis3d_opts=opts.Axis3DOpts(type_="category", name='人群类别'),#x轴数据类型,名称,rfm_group yaxis3d_opts=opts.Axis3DOpts(type_="category", name='年份'),#y轴数据类型,名称,year zaxis3d_opts=opts.Axis3DOpts(type_="value", name='会员数量'),#z轴数据类型,名称,number ) .set_global_opts( # 全局设置 visualmap_opts=opts.VisualMapOpts(max_=range_max, range_color=range_color), #设置颜色,及不同取值对应的颜色 title_opts=opts.TitleOpts(title="RFM分组结果"),#设置标题 ) ) # c.render_notebook() #在notebook中显示 c.render() -
step9:结果保存到Excel
rfm_result[['year','会员ID','rfm_group']].to_excel('../data/rfm.xlsx',index=False) -
step10:结果保存到MySQL
# 结果保存 Mysql from sqlalchemy import create_engine # 创建数据库引擎,传入url规则的字符串 engine = create_engine('mysql+pymysql://root:123456@192.168.88.161:3306/analysis?charset=utf8') rfm_result[['year','会员ID','rfm_group']].to_sql('rfm_result',engine,index=False,if_exists='append')
-
-
小结:实现RFM案例模型构建
【模块二:AB测试效果分析】
【理解】AB测试的介绍
-
目标:理解AB测试的介绍
-
实施
-
问题1:什么是AB测试?

-
概念:AB测试(也称为分组实验、随机实验)是一种统计学方法,用于比较来自两个或多个版本的产品、设计或流程的性能差异。在AB测试中,参与者被随机分配到不同的实验组,每个组接收不同的处理,然后通过对比各组之间的表现来评估这些处理的效果。
-
场景:新方案的效果评估
-
理解:AB测试就是为了评估新方案的效果比旧方案要好还是要差,将新方案和旧方案分成两组进行对照试验,基于试验结果来评估

-
-
问题2:为什么要做AB测试?
-
目的:AB测试允许我们根据数据和事实做出决策,而不是依靠猜测或主观假设。它有助于测试和优化产品功能、网站设计、营销策略等。通过AB测试,我们可以确定哪种变化可以带来最大的影响,从而作出基于数据的决策。

-
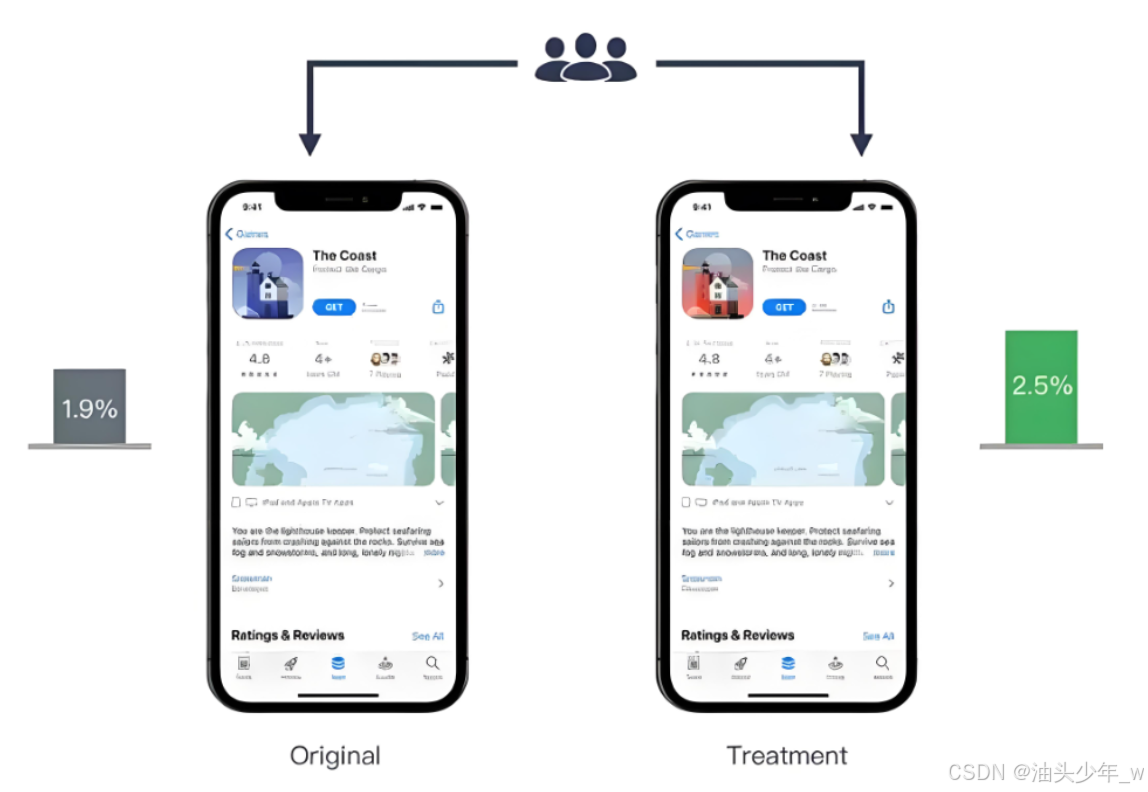
示例:界面设计:产品设计方案的选择,基于旧方案和新方案进行对比,观察用户的访问量、下载量
-
-
问题3:一般怎么做AB测试?
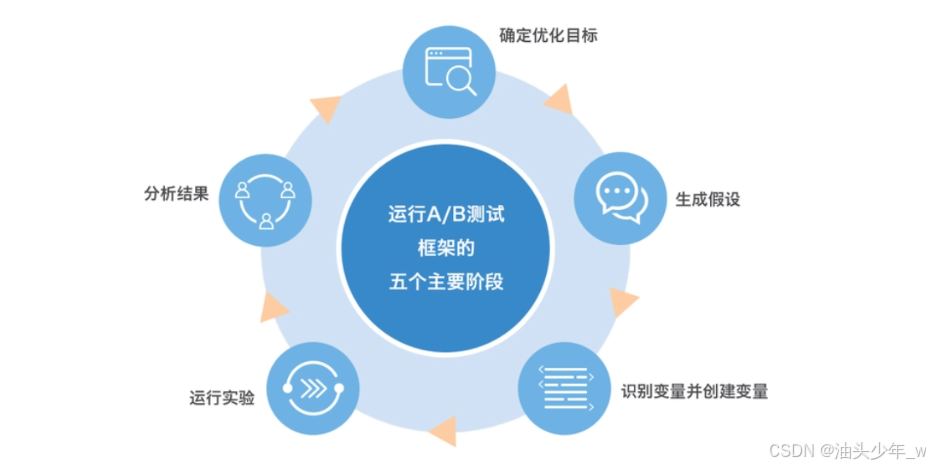
- 确定目标:明确需要改进的指标,如点击率、转化率、用户留存率等。
- 制定假设:提出假设和预期结果。例如,“更改注册按钮颜色将导致更高的点击率”。
- 创建实验组和对照组:随机将用户分为实验组和对照组。对照组接收标准处理,实验组接收变化后的处理(如新设计)。
- 确定样本量:计算所需的样本量以获得即使效果较小也能检测到的显著结果。
- 实施实验:应用更改并追踪两组的表现指标。
- 分析结果:使用统计学方法比较两组数据。
- 得出结论:根据统计显著性和实际效果大小,决定是否采用新的变化。
-
-
小结:理解AB测试的介绍
【理解】AB测试案例需求分析
-
目标:理解AB测试案例需求分析
-
实施
-
背景:XXX电商公司
-
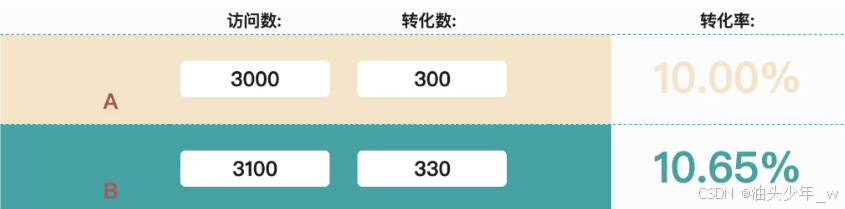
问题:公司近两年的 用户访问落地页面 的 平均点击率为13% ,现希望能够通过页面改版设计,提升页面点击率 至 15%

-
需求:设计部同事已经设计好了新版的落地页面,为了确定新版页面的效果,进行了AB测试,现希望基于AB测试的访问情况,进行数据分析,提供新版页面是否上线的决策数据支撑
-
结果
- 假设方案一【原假设】:建议保留旧版本,继续迭代新版本:新版本的数据表现无明显效果
- 假设方案二【新假设】:建议上线新版本,下线旧版本:新版本的数据表现达到了预期效果
-
思考:我们如何计算样本量?也就是说我们拿多少样本数据来代表这个效果?
- 基于样本量计算的常见原理和公式,样本量的个数主要由以下几个因素决定
- 效应大小: 表示待检验效应的大小。在AB测试中,通常涉及转化率或其他比例数据。
- 统计功效(1-β):即发现真实效应存在的概率。通常设置为0.8,表示80%的概率能够发现真实效应。
- 显著性水平(α):通常设定为0.05,表示接受拒绝零假设的阈值。
- 样本比例:因为通常对照组和实验组人数相同,所以设置为1。
-
-
小结:理解AB测试案例需求分析
【理解】AB测试案例数据探索
-
目标:理解AB测试案例数据探索
-
实施
-
原始数据:
user_id:表示访问的用户IDtimestamp:表示用户访问的时间group:表示该用户是哪一组的 ,control对照组,treatment实验组landing_page:表示该用户看到的是哪一种落地页 ,old_page老页面,new_page新页面converted:表示该次访问是否有转化 ,0=无转化,1=转化
-
目标结果:基于两组数据,计算两组数据之间的 Z统计量、P值、置信区间 ,通过三个指标来评估新方案的效果
- Z统计量:Z统计量是用于检验两个比例之间差异的一种统计量。
- 在AB测试中,Z统计量可告知我们对照组和实验组转化率之间的差异是否显著。
- 如果Z统计量的绝对值较大,那么对应的p-value可能会更小,表明这两个组的转化率差异是显著的。
- P值:P值是在原假设为真的情况下,观察到样本数据或更极端情况的概率。
- 在AB测试中,P值表示了对照组和实验组转化率之间差异的显著性。
- 通常情况下,如果P值小于设定的显著性水平(如0.05),则可以拒绝原假设,即认为观察到的效果是显著的。
- 置信区间:置信区间提供了一个范围,其中包含真实参数(比如转化率)的概率区间。
- 在AB测试中,置信区间用来表示对照组和实验组转化率的估计范围。
- 例如,95%的置信区间表示我们有95%的把握真实的转化率落在这个区间中。
- Z统计量:Z统计量是用于检验两个比例之间差异的一种统计量。
-
实现流程
-
step1:计算样本人数,基于Python的statsmodels模块中的样本分析函数进行计算

-
step2:加载数据并查看数据内容
-
step3:数据清洗,对用户访问数据进行过滤,每个用户只保留一条访问记录即可
-
step4:样本抽取,从每组的所有数据中,根据step1中计算出的样本数量进行随机抽取
-
step5:计算两组的转化率
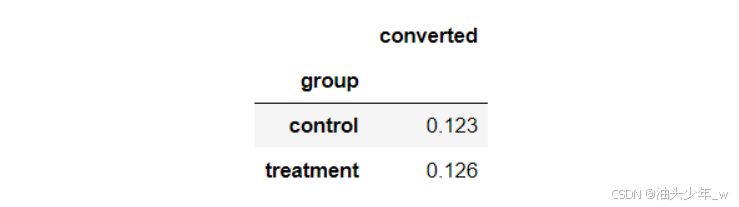
-
step6:结果分析

-
-
-
小结:理解AB测试案例数据探索
【实现】AB测试案例数据清洗
-
目标:实现AB测试案例数据清洗
-
实施
-
step0:安装依赖模块
pip install statsmodels -i https://pypi.tuna.tsinghua.edu.cn/simple/ -
step1:导包并计算样本数量
# 导包 import statsmodels.stats.api as sms import pandas as pd import numpy as np from math import ceil # 计算效应大小 effect_size = sms.proportion_effectsize(0.13, 0.15) effect_size # 基于效应大小、统计功效、显著性水平、样本比例 来 计算样本数量 required_n = sms.NormalIndPower().solve_power(effect_size, power=0.8, alpha=0.05, ratio=1) required_n = ceil(required_n) print('基于目标效果测算的样本个数为:', required_n) -
step2:加载数据
# 读取数据文件 8、ab_data.csv ab_data = pd.read_csv('../data/8、ab_data.csv') # 查看前5条数据格式 ab_data.head() # 构建透视图,观察 对照组 和 实验组 各自访问 新页面的 用户个数 和 各自访问 旧页面的用户个数 ab_data.pivot_table(index = 'group',columns='landing_page',values = 'user_id',aggfunc='count') -
step3:数据清洗
# 查看 每个用户 ID 是否只有 1条记录 ab_data['user_id'].value_counts()<2 # 统计每个用户的浏览条数 count_result = ab_data['user_id'].value_counts() # 保留浏览页面是1个页面的用户 索引 users = count_result[count_result<2].index # 筛选出这些用户的浏览信息 df= ab_data[ab_data['user_id'].isin(users)] df
-
-
小结:实现AB测试案例数据清洗
【实现】AB测试案例结果分析
-
目标:实现AB测试案例结果分析
-
实施
-
step4:样本抽取
# 统计 每组 每种落地页面 的浏览次数 df.groupby(['group','landing_page'])['landing_page'].count() ## 样本抽取:抽取 对照组 的数据样本 ## sample 随机抽样 从14万数据中抽出4720条就是 required_n ## random_state随机数种子 如果这个数固定不变, 每次产生的抽样结果相同 control_sample = df[df['group']=='control'].sample(required_n, random_state=22) control_sample ## 样本抽取:抽取 实验组 的数据样本 ## sample 随机抽样 从14万数据中抽出4720条就是 required_n ## random_state随机数种子 如果这个数固定不变, 每次产生的抽样结果相同 treatment_sample = df[df['group']=='treatment'].sample(required_n, random_state=22) treatment_sample -
step5:计算两组转化率
## 计算 对照组 的 转化率 control_sample['converted'].mean() ## 计算 实验组组 的 转化率 treatment_sample['converted'].mean() # 合并分析 # 将两份数据进行合并 ab_test = pd.concat([control_sample, treatment_sample], axis=0) ab_test.reset_index(drop=True, inplace=True) # 计算两组的转化率,并保留小数点后3位 conversion_rates = ab_test.groupby('group')[['converted']].mean() conversion_rates.style.format('{:.3f}') -
step6:结果分析
# 导入评估指标的计算模块 from statsmodels.stats.proportion import proportions_ztest, proportion_confint #获取对照组是否转化的数据 control_results = ab_test[ab_test['group'] == 'control']['converted'] #获取实验组是否转化的数据 treatment_results = ab_test[ab_test['group'] == 'treatment']['converted'] # 获取对照组人数 n_con = control_results.count() # 获取实验组人数 n_treat = treatment_results.count() # 获取实验组和对照组成功转化的人数 successes = [control_results.sum(), treatment_results.sum()] # 构建样本量列表 nobs = [n_con, n_treat] # 基于成功转化人和样本量列表 构建 统计量和P值 z_stat, pval = proportions_ztest(successes, nobs=nobs) # 计算95%的置信区间 (lower_con, lower_treat), (upper_con, upper_treat) = proportion_confint(successes, nobs=nobs, alpha=0.05) #计算置信区间 print(f'z 统 计 量: {z_stat:.2f}') print(f'P 值: {pval:.3f}') print(f'对照组95%置信区间: [{lower_con:.3f}, {upper_con:.3f}]') print(f'实验组95%置信区间: [{lower_treat:.3f}, {upper_treat:.3f}]') -
最终结论
- 最终计算出的p-value = 0.732 远大于我们实验设置的α = 0.05, 我们不能拒绝原假设,所以旧页面更好
- 查看实验组的置信区间([0.116, 0.135] 或 11.6-13.5%),注意到:
- 13% 的基准转化率在置信区间内
- 15% 的目标值(我们的目标是 2% 的提升)并不在置信区间内
- 这意味着新设计的真实转化率可能与之前的转化率接近, 证明我们的新改进并没有效果
- 结论:建议保留旧版本,继续迭代新版本:新版本的数据表现无明显效果
-
-
小结:实现AB测试案例结果分析

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)