数据分析实战[日]酒卷隆治 里洋平/著 肖峰/译python代码实现 案例5—逻辑回归分析 根据过去的行为能否预测当下[从非智能手机更换到智能手机的分析]
数据分析实战[日]酒卷隆治 里洋平/著 肖峰/译python代码实现 案例4—逻辑回归分析 根据过去的行为能否预测当下[从非智能手机更换到智能手机的分析]
数据分析实战[日]酒卷隆治 里洋平/著 肖峰/译python代码实现
案例5—逻辑回归分析 根据过去的行为能否预测当下[从非智能手机更换到智能手机的分析]
目录
1. 数据收集
1.1 section7-dau.csv
1月和2月的dau数据(Daily Active User, 每天至少访问1次的的用户数据)
| region_month | region_day | app_name | user_id | device |
|---|---|---|---|---|
| 月份 | 访问时间 | 游戏名 | 用户账号 | 设备类型 |
设备类型:智能手机(SP, SmartPhone);非智能手机(FP, Feature Phone)
前10条数据: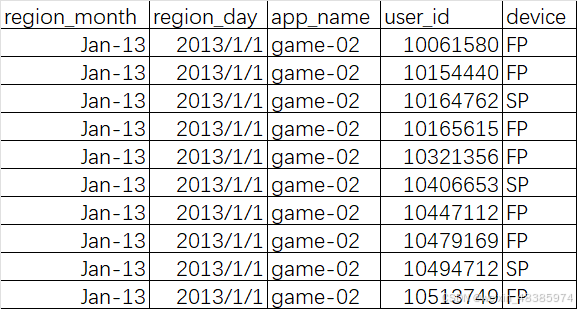
后10条数据: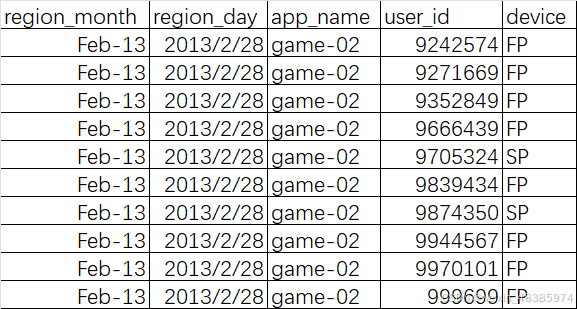
2. 数据加工
2.0 导入库读取数据
# 第七章 根据过去的行为能否预测当下
# 导入库
import pandas as pd
# 读入CSV文件
dau = pd.read_csv(r"C:\Users\Mike\Downloads\《数据分析实战》书中数据和R代码\R\section7-dau.csv")
print('dau日志数据:\n', dau.tail())
运行结果:
dau数据:
region_month region_day app_name user_id device
48983 2013-02 2013-02-28 game-02 9839434 FP
48984 2013-02 2013-02-28 game-02 9874350 SP
48985 2013-02 2013-02-28 game-02 9944567 FP
48986 2013-02 2013-02-28 game-02 9970101 FP
48987 2013-02 2013-02-28 game-02 999699 FP
一共有48987+1条数据。
1月份的非智能手机用户在2月份是流失了?还是变成使用智能手机来访问了?
2.1 生成1月份的非智能手机用户在2月份是否依然访问游戏的数据
2.1.1 提取mau数据(Monthly Active User)
# 关于用户是否进行了账号迁转的数据的整理
# mau 删除重复值保留唯一值的数据
mau = dau.drop_duplicates(subset=["region_month", "device", "user_id"], keep="first", inplace=False) # 删除重复值,保留1行
print('mau数据:\n', mau.tail())
运行结果:
region_month region_day app_name user_id device
48633 2013-02 2013-02-28 game-02 38756442 FP
48704 2013-02 2013-02-28 game-02 43727481 FP
48708 2013-02 2013-02-28 game-02 4403390 SP
48834 2013-02 2013-02-28 game-02 54980118 SP
48901 2013-02 2013-02-28 game-02 62429282 FP
删除重复值后,数据量减少了
2.1.2 提取非智能手机1月的用户数据fp_mau1
# fp_mau 非智能手机用户数据
fp_mau = dau[dau['device'] == "FP"].drop_duplicates(subset=("region_month", "device", "user_id"), keep="first",
inplace=False) # 筛选非智能机FP,删除重复值,保留唯一
print('fp_mau数据:\n', fp_mau.tail())
# fp_mau1 非智能手机1月用户数据
fp_mau1 = fp_mau[fp_mau['region_month'] == "2013-01"] # 非智能手机1月用户数据
print('fp_mau1数据:\n', fp_mau1.tail())
运行结果:
fp_mau数据:
region_month region_day app_name user_id device
48288 2013-02 2013-02-28 game-02 17684116 FP
48627 2013-02 2013-02-28 game-02 38113062 FP
48633 2013-02 2013-02-28 game-02 38756442 FP
48704 2013-02 2013-02-28 game-02 43727481 FP
48901 2013-02 2013-02-28 game-02 62429282 FP
fp_mau1数据:
region_month region_day app_name user_id device
25418 2013-01 2013-01-31 game-02 32703983 FP
25472 2013-01 2013-01-31 game-02 37422557 FP
25743 2013-01 2013-01-31 game-02 60366312 FP
25812 2013-01 2013-01-31 game-02 7962877 FP
25827 2013-01 2013-01-31 game-02 8773015 FP
2.1.3 提取2月的手机访问数据并设置访问标志位mau2
# 分别获取1月份和2月份的数据
# mau2 2月用户数据
mau2 = mau[mau['region_month'] == "2013-02"]
mau2 = mau2.copy()
mau2['is_access'] = 1 # 将mau2数据的is_access属性全部设置为1
print('mau2数据:\n', mau2.head())
运行结果:
mau2数据:
region_month region_day app_name user_id device is_access
25847 2013-02 2013-02-01 game-02 10164762 SP 1
25848 2013-02 2013-02-01 game-02 10165615 FP 1
25849 2013-02 2013-02-01 game-02 10253686 FP 1
25850 2013-02 2013-02-01 game-02 10321356 FP 1
25851 2013-02 2013-02-01 game-02 10406653 FP 1
2.1.3 提取1月份的非智能手机用户在2月份的访问情况数据
# 1月份的非智能手机用户在2月份的访问情况
fp_mau1 = pd.merge(fp_mau1, mau2, how='left', on="user_id", suffixes=('', '_g',))
fp_mau1['is_access'].fillna(0, inplace=True) # NaN值填充为0
fp_mau1 = fp_mau1[['user_id', 'region_month', 'device', 'is_access']]
print('fp_mau1合并mau2后的数据:\n', fp_mau1.head())
运行结果:
fp_mau1合并mau2后的数据:
user_id region_month device is_access
0 10061580 2013-01 FP 1.0
1 10154440 2013-01 FP 0.0
2 10165615 2013-01 FP 1.0
3 10321356 2013-01 FP 1.0
4 10447112 2013-01 FP 1.0
这样就知道了1月的用户在2月份是否访问过,访问过is_access=1,没有访问过is_access=0。
2.2 区分2月份的用户访问是继续来自非智能手机还是来自智能手机
2.2.1 2月份的访问来自非智能手机用户的数据
# 1月份访问过游戏的非智能手机用户在2月份是否是继续通过非智能手机来访问的
fp_mau2 = fp_mau[fp_mau['region_month'] == "2013-02"] # 非智能手机2月用户数据
fp_mau2 = fp_mau2.copy()
fp_mau2['is_fp'] = 1 # 将fp_mau2数据的is_fp属性全部设置为1
print('fp_mau2数据:\n', fp_mau1.head())
fp_mau1 = pd.merge(fp_mau1, fp_mau2, how='left', on='user_id', suffixes=('', '_g',)) # 合并fp_mau1和fp_mau2
fp_mau1['is_fp'].fillna(0, inplace=True) # NaN值填充为0
fp_mau1 = fp_mau1[['user_id', 'region_month', 'device', 'is_access', 'is_fp']]
print('fp_mau1合并fp_mau2后的数据:\n', fp_mau1.head())
运行结果:
fp_mau2数据:
region_month region_day app_name user_id device is_fp
25848 2013-02 2013-02-01 game-02 10165615 FP 1
25849 2013-02 2013-02-01 game-02 10253686 FP 1
25850 2013-02 2013-02-01 game-02 10321356 FP 1
25851 2013-02 2013-02-01 game-02 10406653 FP 1
25853 2013-02 2013-02-01 game-02 10447112 FP 1
fp_mau1合并fp_mau2后的数据:
user_id region_month device is_access is_fp
0 10061580 2013-01 FP 1.0 1.0
1 10154440 2013-01 FP 0.0 0.0
2 10165615 2013-01 FP 1.0 1.0
3 10321356 2013-01 FP 1.0 1.0
4 10447112 2013-01 FP 1.0 1.0
2.2.2 2月份的访问来自智能手机用户的数据
# 1月份访问过游戏的非智能手机用户在2月份是否是通过智能手机来访问的
sp_mau = dau[dau['device'] == "SP"].drop_duplicates(subset=("region_month", "device", "user_id"), keep="first",
inplace=False) # 筛选智能机SP,删除重复值,保留唯一
sp_mau2 = sp_mau[sp_mau['region_month'] == "2013-02"] # 智能手机2月用户数据
sp_mau2 = sp_mau2.copy()
sp_mau2['is_sp'] = 1 # 将sp_mau2数据的is_sp属性全部设置为1
print('sp_mau2数据:\n', sp_mau2.head())
fp_mau1 = pd.merge(fp_mau1, sp_mau2, how='left', on='user_id', suffixes=('', '_g'))
fp_mau1['is_sp'].fillna(0, inplace=True)
fp_mau1 = fp_mau1[['user_id', 'region_month', 'device', 'is_access', 'is_fp', 'is_sp']]
print('fp_mau1合并fp_mau2再合并sp_mau2后的数据:\n', fp_mau1.head())
运行结果:
sp_mau2数据:
region_month region_day app_name user_id device is_sp
25847 2013-02 2013-02-01 game-02 10164762 SP 1
25852 2013-02 2013-02-01 game-02 10406653 SP 1
25855 2013-02 2013-02-01 game-02 10494712 SP 1
25858 2013-02 2013-02-01 game-02 10588037 SP 1
25860 2013-02 2013-02-01 game-02 10718123 SP 1
fp_mau1合并fp_mau2再合并sp_mau2后的数据:
user_id region_month device is_access is_fp is_sp
0 10061580 2013-01 FP 1.0 1.0 0.0
1 10154440 2013-01 FP 0.0 0.0 0.0
2 10165615 2013-01 FP 1.0 1.0 0.0
3 10321356 2013-01 FP 1.0 1.0 0.0
4 10447112 2013-01 FP 1.0 1.0 0.0
2.2.3 去除2月份继续使用非智能手机访问的数据
目的是判断那些非智能手机用户下个月是会通过智能手机继续访问还是会流失。下个月继续使用非智能手机访问的用户数据对于模型的建立没有什么作用,先排除掉。
# 以'2月份没有访问'或者'2月份从智能手机访问'为条件对数据进行过滤
fp_mau1 = fp_mau1[(fp_mau1['is_access'] == 0) | (fp_mau1['is_sp'] == 1)]
print('提取2月没有访问或者2月通过智能手机访问的数据:\n', fp_mau1.head())
运行结果:
提取2月没有访问或者2月通过智能手机访问的数据:
user_id region_month device is_access is_fp is_sp
1 10154440 2013-01 FP 0.0 0.0 0.0
7 10528830 2013-01 FP 0.0 0.0 0.0
20 1163733 2013-01 FP 1.0 0.0 1.0
21 11727630 2013-01 FP 0.0 0.0 0.0
43 13401362 2013-01 FP 1.0 0.0 1.0
这样就得到了逻辑回归分析所需的数据①。
2.3 每个用户每天访问情况的数据
2.3.1 1月份非智能手机用户每天的访问情况
# 关于是否每天访问游戏的数据的整理
# 提取1月非智能手机用户每天的访问情况数据
fp_dau1 = dau[(dau['device'] == "FP") & (dau['region_month'] == "2013-01")]
fp_dau1 = fp_dau1.copy()
fp_dau1['is_access'] = 1
fp_dau1_cast = pd.pivot_table(fp_dau1, values='is_access', index='user_id', columns='region_day',
aggfunc='mean').reset_index()
fp_dau1_cast.fillna(0, inplace=True)
# 重命名列名
old_column_names = list(fp_dau1_cast.columns)[1:]
new_column_names = list('X' + str(i) + 'day' for i in range(1, 32))
rename_mapping = dict(zip(old_column_names, new_column_names))
fp_dau1_cast.rename(columns=rename_mapping, inplace=True)
print('1月非智能手机用户每天的访问数据:\n', fp_dau1_cast.head())
运行结果:
1月非智能手机用户每天的访问数据:
region_day user_id X1day X2day X3day ... X28day X29day X30day X31day
0 397286 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
1 471341 1.0 1.0 1.0 ... 0.0 0.0 0.0 0.0
2 503874 1.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
3 512250 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
4 513811 0.0 0.0 0.0 ... 1.0 1.0 0.0 1.0
2.3.2 合并‘1月每天的访问情况数据’和‘2月没有访问或者2月通过智能手机访问的数据’
# 合并fp_dau1_cast和fp_mau1
fp_dau1_cast = pd.merge(fp_dau1_cast, fp_mau1, how='right', on='user_id') # 注意:how='right'
fp_dau1_cast.drop(columns=['region_month', 'device', 'is_access', 'is_fp'], inplace=True)
print('合并fp_dau1_cast和fp_mau1后的数据:\n', fp_dau1_cast.head())
运行结果:
合并fp_dau1_cast和fp_mau1后的数据:
user_id X1day X2day X3day X4day ... X28day X29day X30day X31day is_sp
0 10154440 1.0 1.0 1.0 1.0 ... 0.0 0.0 0.0 0.0 0.0
1 10528830 1.0 0.0 1.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
2 1163733 1.0 1.0 0.0 0.0 ... 1.0 0.0 0.0 0.0 1.0
3 11727630 1.0 1.0 1.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
4 13401362 1.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 1.0
经过上述处理,就能够得到分析所需要的数据。
2.3.3 确认一下流失的用户(包含因账号迁转设定失败而流失的用户)和账号迁转的用户分别有多少人
# 确认一下流失的用户(包含因账号迁转设定失败而流失的用户)和账号迁转的用户分别有多少人
fp_dau1_cast_is_sp = pd.pivot_table(fp_dau1_cast, values='user_id', index=None, columns='is_sp',
aggfunc='count')
print('用户流失和账号迁转人数的统计数据:\n', fp_dau1_cast_is_sp)
运行结果:
用户流失和账号迁转人数的统计数据:
is_sp 0.0 1.0
user_id 190 62
统计的结果是有190名用户流失了,而号迁转的用户有62名。
3. 建立模型和验证模型
3.1 使用逻辑回归分析来建立模型
# 基于逻辑回归分析建立模型
# 书中R语言使用step()函数数以赤池信息量准则(AIC)为标准对模型中自变量的增减进行自动的探寻和选择。这里先暂时指定指标。后面发现python的方法在解决。
formula = 'is_sp ~ X1day + X4day + X5day + X7day + X10day + X13day + X22day + X29day + X31day'
# 建立模型
model = smf.glm(
formula=formula,
data=fp_dau1_cast,
family=sm.families.Binomial(sm.families.links.logit())).fit()
print(model.summary())
运行结果:
Generalized Linear Model Regression Results
==============================================================================
Dep. Variable: is_sp No. Observations: 252
Model: GLM Df Residuals: 242
Model Family: Binomial Df Model: 9
Link Function: logit Scale: 1.0000
Method: IRLS Log-Likelihood: -63.365
Date: Mon, 16 Dec 2024 Deviance: 126.73
Time: 15:54:41 Pearson chi2: 165.
No. Iterations: 6 Pseudo R-squ. (CS): 0.4583
Covariance Type: nonrobust
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -3.6036 0.427 -8.441 0.000 -4.440 -2.767
X1day 1.5334 0.572 2.681 0.007 0.412 2.654
X4day 1.7753 0.642 2.764 0.006 0.516 3.034
X5day -1.0353 0.762 -1.358 0.174 -2.529 0.459
X7day 1.7002 0.711 2.392 0.017 0.307 3.094
X10day -2.6753 0.942 -2.841 0.005 -4.521 -0.829
X13day 1.3726 0.755 1.819 0.069 -0.106 2.852
X22day 1.6233 0.638 2.543 0.011 0.372 2.874
X29day 2.0012 0.648 3.088 0.002 0.731 3.271
X31day 1.7310 0.814 2.126 0.034 0.135 3.327
==============================================================================
3.1.1 回归模型的系数:
| 系数的预估值 | 标准误差 | z值 | p值 | |
|---|---|---|---|---|
| 常数项 | -3.6036 | 0.427 | -8.441 | 0.000 |
| X1day | 1.5334 | 0.572 | 2.681 | 0.007 |
| X4day | 1.7753 | 0.642 | 2.764 | 0.006 |
| X5day | -1.0353 | 0.762 | -1.358 | 0.174 |
| X7day | 1.7002 | 0.711 | 2.392 | 0.017 |
| X10day | -2.6753 | 0.942 | -2.841 | 0.005 |
| X13day | 1.3726 | 0.755 | 1.819 | 0.069 |
| X22day | 1.6233 | 0.638 | 2.543 | 0.011 |
| X29day | 2.0012 | 0.648 | 3.088 | 0.002 |
| X31day | 1.7310 | 0.814 | 2.126 | 0.034 |
3.1.2 残差的分布:
# 残差分布
resid_deviance = model.resid_deviance
print('残差的分布:\n', resid_deviance.describe())
运行结果:
残差的分布:
count 252.000000
mean -0.103160
std 0.703007
min -1.955385
25% -0.451748
50% -0.231782
75% -0.061217
max 2.694612
dtype: float64
| 最小值 | 第1四分位点 | 中值 | 第3四分位点 | 最大值 |
|---|---|---|---|---|
| -1.955385 | -0.451748 | -0.231782 | -0.061217 | 2.694612 |
3.1.3 赤池信息量准则:
# AIC值
aic = model.aic.round(3)
print('赤池信息量准则:\n', aic)
运行结果:
赤池信息量准则:
146.731
3.2 从分析结果来探讨模型
通过观察逻辑回归分析的执行结果,我们发现X5day和X10day的系数为负数。如果直观地解释,那就是“如果5日和10日没来访问的话,那么下月(2月)账号就会发生迁转”,意思有些莫名其妙。出现这种情况是由于自变量之间存在着相关性,我们把这种现象称为多重共线
性。当出现多重共线性时,上述关于系数的讨论就没什么意义了。而且这种情况下得到的模型很不稳定,无法进行长期预测。一般来说此时就需要做进一步的变量选择以及增加交互作用项等,以便得到再现性更强的模型。然而,在本例中,是否能够建立模型才是我们所关注的,所以暂时不需要进行上述工作。这次我们需要建立的模型并不一定要长期有效,只要能够在本例中使用即可,也就是所谓的一次性模型。由于从一开始我们就没有包含正解的数据,因此就不用再拘泥于模型的精度或者是再现性。综上,我们建立的模型至少在本案例中不存在使用上的问题,我们用它来继续进行下面的工作。
3.3 使用建立的模型进行预测
模型的预测值是“账号迁转的概率”。当这个值大于0.5时我们取1(账号迁转),小于0.5时则取0(用户流失),生成如下数据。
# 利用生成的模型来进行预测
# 智能手机账号迁转设定的概率
fp_dau1_cast['prob'] = model.predict().round(2) # 账号迁移概率
print('账号迁转的概率:\n', fp_dau1_cast.sort_values(by='user_id').head())
# 预测在智能手机上是否进行了账号迁转设定
fp_dau1_cast['pred'] = fp_dau1_cast['prob'].apply(lambda x: 1 if x > 0.5 else 0)
print('是否账号迁转:\n', fp_dau1_cast.sort_values(by='user_id').head())
运行结果:
账号迁转的概率:
user_id X1day X2day X3day X4day ... X29day X30day X31day is_sp prob
58 471341 1.0 1.0 1.0 1.0 ... 0.0 0.0 0.0 1.0 0.43
60 503874 1.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.11
156 1073544 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.00
160 1073864 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.03
2 1163733 1.0 1.0 0.0 0.0 ... 0.0 0.0 0.0 1.0 0.39
[5 rows x 34 columns]
是否账号迁转:
user_id X1day X2day X3day X4day ... X30day X31day is_sp prob pred
58 471341 1.0 1.0 1.0 1.0 ... 0.0 0.0 1.0 0.43 0
60 503874 1.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.11 0
156 1073544 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.00 0
160 1073864 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.03 0
2 1163733 1.0 1.0 0.0 0.0 ... 0.0 0.0 1.0 0.39 0
利用上述数据,使用交叉统计表来对模型进行验证。确认预测值和实际值之间差异大小。
# 预测值和实际值对比
is_sp_vs_pred = pd.pivot_table(fp_dau1_cast, values='user_id', index='is_sp', columns='pred', aggfunc='count')
print('预测值和实际值对比:\n', is_sp_vs_pred)
运行结果:
预测值和实际值对比:
pred 0 1
is_sp
0.0 180 10
1.0 20 42
| 2 月使用情况 | 用户流失(预测值) | 账号迁转(预测值) |
|---|---|---|
| 用户流失(实际值) | 180 | 10 |
| 账号迁转(实际值) | 20 | 42 |
预测的准确率为 (180 + 42) / (180 + 10 + 20 + 42) = 88%
3.4 根据预测结果推测用户群
# 根据预测结果来推测用户群
# is_sp=1且pred=1的用户
fp_dau1_cast1 = fp_dau1_cast[(fp_dau1_cast['is_sp'] == 1) & (fp_dau1_cast['pred'] == 1)]
print('is_sp=1且pred=1的用户:\n', fp_dau1_cast1.sort_values(by='prob', ascending=False).head())
运行结果:
is_sp=1且pred=1的用户:
user_id X1day X2day X3day X4day X5day X6day X7day X8day X9day \
29 24791702 1.0 1.0 0.0 1.0 0.0 1.0 1.0 1.0 1.0
30 24791702 1.0 1.0 0.0 1.0 0.0 1.0 1.0 1.0 1.0
6 16557842 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
79 9567562 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
78 9567562 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
X10day X11day X12day X13day X14day X15day X16day X17day X18day \
29 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
30 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
6 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
79 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
78 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
X19day X20day X21day X22day X23day X24day X25day X26day X27day \
29 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
30 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
6 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
79 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
78 0.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
X28day X29day X30day X31day is_sp prob pred
29 1.0 1.0 1.0 1.0 1.0 1.00 1
30 1.0 1.0 1.0 1.0 1.0 1.00 1
6 1.0 1.0 1.0 1.0 1.0 0.99 1
79 1.0 1.0 1.0 1.0 1.0 0.99 1
78 1.0 1.0 1.0 1.0 1.0 0.99 1
数据中预测值和实际值都为“1”的用户确实是仍在频繁地访问游戏。
# is_sp=0且pred=1的用户
fp_dau1_cast2 = fp_dau1_cast[(fp_dau1_cast['is_sp'] == 0) & (fp_dau1_cast['pred'] == 1)]
print('is_sp=0且pred=1的用户:\n', fp_dau1_cast2.sort_values(by='prob', ascending=False).head())
运行结果:
is_sp=0且pred=1的用户:
user_id X1day X2day X3day X4day X5day X6day X7day X8day X9day \
14 19432099 1.0 1.0 1.0 1.0 0.0 1.0 1.0 1.0 1.0
207 41590801 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
57 43451947 1.0 1.0 1.0 1.0 1.0 0.0 1.0 1.0 1.0
53 42276142 1.0 1.0 1.0 1.0 1.0 1.0 0.0 1.0 1.0
71 6147878 1.0 0.0 0.0 1.0 1.0 1.0 1.0 1.0 1.0
X10day X11day X12day X13day X14day X15day X16day X17day X18day \
14 1.0 1.0 1.0 1.0 1.0 0.0 1.0 1.0 0.0
207 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
57 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
53 1.0 0.0 1.0 1.0 0.0 1.0 1.0 1.0 1.0
71 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
X19day X20day X21day X22day X23day X24day X25day X26day X27day \
14 1.0 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0
207 0.0 0.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0
57 1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0
53 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
71 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 0.0
X28day X29day X30day X31day is_sp prob pred
14 0.0 0.0 0.0 0.0 0.0 0.85 1
207 0.0 1.0 0.0 1.0 0.0 0.85 1
57 1.0 1.0 0.0 0.0 0.0 0.79 1
53 1.0 1.0 0.0 0.0 0.0 0.73 1
71 0.0 0.0 0.0 0.0 0.0 0.67 1
数据中“1”出现的次数很多,这表明大多数用户在1月份还是很频繁地访问游戏的。这些用户在这段时间对游戏仍有很强烈的兴趣,不太可能是因为兴趣变淡了而不再访问游戏。
# is_sp=0且pred=0的用户
fp_dau1_cast3 = fp_dau1_cast[(fp_dau1_cast['is_sp'] == 0) & (fp_dau1_cast['pred'] == 0)]
print('is_sp=0且pred=0的用户:\n', fp_dau1_cast3.sort_values(by='prob', ascending=False).head())
运行结果:
is_sp=0且pred=0的用户:
user_id X1day X2day X3day X4day X5day X6day X7day X8day X9day \
50 3955950 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0
66 57298772 1.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0
63 54777823 1.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0
0 10154440 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
68 59561276 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
X10day X11day X12day X13day X14day X15day X16day X17day X18day \
50 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
66 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
63 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
68 1.0 1.0 1.0 1.0 0.0 0.0 0.0 0.0 0.0
X19day X20day X21day X22day X23day X24day X25day X26day X27day \
50 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
66 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0
63 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0
0 1.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
68 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
X28day X29day X30day X31day is_sp prob pred
50 0.0 0.0 0.0 0.0 0.0 0.43 0
66 0.0 0.0 0.0 0.0 0.0 0.41 0
63 0.0 0.0 1.0 0.0 0.0 0.41 0
0 0.0 0.0 0.0 0.0 0.0 0.28 0
68 0.0 0.0 0.0 0.0 0.0 0.28 0
可以看出,这些用户已经不怎么来访问了,他们对游戏的兴趣在逐渐降低,因此也就慢慢地不再来访问了。
4. 完整代码
# 第七章 根据过去的行为能否预测当下
# 导入库
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
pd.set_option("display.max_columns", None) # 显示所有列
# 读入csv文件
dau = pd.read_csv(r"C:\Users\Mike\Downloads\《数据分析实战》书中数据和R代码\R\section7-dau.csv")
print('dau数据:\n', dau.tail())
# 关于用户是否进行了账号迁转的数据的整理
# mau 删除重复值保留唯一值的数据
mau = dau.drop_duplicates(subset=["region_month", "device", "user_id"], keep="first", inplace=False) # 删除重复值,保留1行
print('mau数据:\n', mau.tail())
# fp_mau 非智能手机用户数据
fp_mau = dau[dau['device'] == "FP"].drop_duplicates(subset=("region_month", "device", "user_id"), keep="first",
inplace=False) # 筛选非智能机FP,删除重复值,保留唯一
print('fp_mau数据:\n', fp_mau.tail())
# fp_mau1 非智能手机1月用户数据
fp_mau1 = fp_mau[fp_mau['region_month'] == "2013-01"] # 非智能手机1月用户数据
print('fp_mau1数据:\n', fp_mau1.tail())
# mau2 2月用户数据
mau2 = mau[mau['region_month'] == "2013-02"]
mau2 = mau2.copy()
mau2['is_access'] = 1 # 将mau2数据的is_access属性全部设置为1
print('mau2数据:\n', mau2.head())
# 1月份的非智能手机用户在2月份的访问情况
fp_mau1 = pd.merge(fp_mau1, mau2, how='left', on="user_id", suffixes=('', '_g',))
fp_mau1['is_access'].fillna(0, inplace=True) # NaN值填充为0
fp_mau1 = fp_mau1[['user_id', 'region_month', 'device', 'is_access']]
print('fp_mau1合并mau2后的数据:\n', fp_mau1.head())
# 1月份访问过游戏的非智能手机用户在2月份是否是继续通过非智能手机来访问的
fp_mau2 = fp_mau[fp_mau['region_month'] == "2013-02"] # 非智能手机2月用户数据
fp_mau2 = fp_mau2.copy()
fp_mau2['is_fp'] = 1 # 将fp_mau2数据的is_fp属性全部设置为1
print('fp_mau2数据:\n', fp_mau2.head())
fp_mau1 = pd.merge(fp_mau1, fp_mau2, how='left', on='user_id', suffixes=('', '_g',)) # 合并fp_mau1和fp_mau2
fp_mau1['is_fp'].fillna(0, inplace=True) # NaN值填充为0
fp_mau1 = fp_mau1[['user_id', 'region_month', 'device', 'is_access', 'is_fp']]
print('fp_mau1合并fp_mau2后的数据:\n', fp_mau1.head())
# 1月份访问过游戏的非智能手机用户在2月份是否是通过智能手机来访问的
sp_mau = dau[dau['device'] == "SP"].drop_duplicates(subset=("region_month", "device", "user_id"), keep="first",
inplace=False) # 筛选智能机SP,删除重复值,保留唯一
sp_mau2 = sp_mau[sp_mau['region_month'] == "2013-02"] # 智能手机2月用户数据
sp_mau2 = sp_mau2.copy()
sp_mau2['is_sp'] = 1 # 将sp_mau2数据的is_sp属性全部设置为1
print('sp_mau2数据:\n', sp_mau2.head())
fp_mau1 = pd.merge(fp_mau1, sp_mau2, how='left', on='user_id', suffixes=('', '_g'))
fp_mau1['is_sp'].fillna(0, inplace=True)
fp_mau1 = fp_mau1[['user_id', 'region_month', 'device', 'is_access', 'is_fp', 'is_sp']]
print('fp_mau1合并fp_mau2再合并sp_mau2后的数据:\n', fp_mau1.head())
# 以'2月份没有访问'或者'2月份从智能手机访问'为条件对数据进行过滤
fp_mau1 = fp_mau1[(fp_mau1['is_access'] == 0) | (fp_mau1['is_sp'] == 1)]
print('提取2月没有访问或者2月通过智能手机访问的数据:\n', fp_mau1.head())
# 关于是否每天访问游戏的数据的整理
# 提取1月非智能手机用户每天的访问情况数据
fp_dau1 = dau[(dau['device'] == "FP") & (dau['region_month'] == "2013-01")]
fp_dau1 = fp_dau1.copy()
fp_dau1['is_access'] = 1
fp_dau1_cast = pd.pivot_table(fp_dau1, values='is_access', index='user_id', columns='region_day',
aggfunc='mean').reset_index()
fp_dau1_cast.fillna(0, inplace=True)
# 重命名列名
old_column_names = list(fp_dau1_cast.columns)[1:]
new_column_names = list('X' + str(i) + 'day' for i in range(1, 32))
rename_mapping = dict(zip(old_column_names, new_column_names))
fp_dau1_cast.rename(columns=rename_mapping, inplace=True)
print('1月非智能手机用户每天的访问数据:\n', fp_dau1_cast.head())
# 合并fp_dau1_cast和fp_mau1
fp_dau1_cast = pd.merge(fp_dau1_cast, fp_mau1, how='right', on='user_id') # 注意:how='right'
fp_dau1_cast.drop(columns=['region_month', 'device', 'is_access', 'is_fp'], inplace=True)
print('合并fp_dau1_cast和fp_mau1后的数据:\n', fp_dau1_cast.head())
# 确认一下流失的用户(包含因账号迁转设定失败而流失的用户)和账号迁转的用户分别有多少人
fp_dau1_cast_is_sp = pd.pivot_table(fp_dau1_cast, values='user_id', index=None, columns='is_sp',
aggfunc='count')
print('用户流失和账号迁转人数的统计数据:\n', fp_dau1_cast_is_sp)
# 基于逻辑回归分析建立模型
# 书中R语言使用step()函数数以赤池信息量准则(AIC)为标准对模型中自变量的增减进行自动的探寻和选择。这里先暂时指定指标。后面发现python的方法在解决。
formula = 'is_sp ~ X1day + X4day + X5day + X7day + X10day + X13day + X22day + X29day + X31day'
# 建立模型
model = smf.glm(
formula=formula,
data=fp_dau1_cast,
family=sm.families.Binomial(sm.families.links.logit())).fit()
print(model.summary())
# 残差分布
resid_deviance = model.resid_deviance
print('残差的分布:\n', resid_deviance.describe())
# AIC值
aic = model.aic.round(3)
print('赤池信息量准则:\n', aic)
# 利用生成的模型来进行预测
# 智能手机账号迁转设定的概率
fp_dau1_cast['prob'] = model.predict().round(2) # 账号迁移概率
print('账号迁转的概率:\n', fp_dau1_cast.sort_values(by='user_id').head())
# 预测在智能手机上是否进行了账号迁转设定
fp_dau1_cast['pred'] = fp_dau1_cast['prob'].apply(lambda x: 1 if x > 0.5 else 0)
print('是否账号迁转:\n', fp_dau1_cast.sort_values(by='user_id').head())
# 预测值和实际值对比
is_sp_vs_pred = pd.pivot_table(fp_dau1_cast, values='user_id', index='is_sp', columns='pred', aggfunc='count')
print('预测值和实际值对比:\n', is_sp_vs_pred)
# 根据预测结果来推测用户群
# is_sp=1且pred=1的用户
fp_dau1_cast1 = fp_dau1_cast[(fp_dau1_cast['is_sp'] == 1) & (fp_dau1_cast['pred'] == 1)]
print('is_sp=1且pred=1的用户:\n', fp_dau1_cast1.sort_values(by='prob', ascending=False).head())
# is_sp=0且pred=1的用户
fp_dau1_cast2 = fp_dau1_cast[(fp_dau1_cast['is_sp'] == 0) & (fp_dau1_cast['pred'] == 1)]
print('is_sp=0且pred=1的用户:\n', fp_dau1_cast2.sort_values(by='prob', ascending=False).head())
# is_sp=0且pred=0的用户
fp_dau1_cast3 = fp_dau1_cast[(fp_dau1_cast['is_sp'] == 0) & (fp_dau1_cast['pred'] == 0)]
print('is_sp=0且pred=0的用户:\n', fp_dau1_cast3.sort_values(by='prob', ascending=False).head())
5. 参考文献
Pandas:删掉重复行(drop_duplicates()用法)
总结一下利用pandas进行条件筛选的几个方法
【Pandas总结】第八节 Pandas 合并数据集_pd.merge()
python统计分析——逻辑回归
逻辑回归介绍及statsmodels、sklearn实操
python数据分析——模型诊断

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)