《邪不压正》好不好看?大数据分析告诉你
八月暑假季,也是影院最热闹的时候,各大电影相继在影院播放,精彩不断,给了人们更多的惊喜,尤其是《我不是药神》一路遥遥领先,拿下暑假票房冠军,但是《邪不压正》这部电影褒贬不一,笔者也看过这部电影,我自身对于这部电影的感觉,怎么说呢?有点深奥,还行吧。但是个人观点,并不能说明一部电影的好坏,我们应该通过了解数万观众对于这部影片的评价再来对这部影片定性吧。因此,我准备爬取豆瓣对《邪不压正》所...

八月暑假季,也是影院最热闹的时候,各大电影相继在影院播放,精彩不断,给了人们更多的惊喜,尤其是《我不是药神》一路遥遥领先,拿下暑假票房冠军,但是《邪不压正》这部电影褒贬不一,笔者也看过这部电影,我自身对于这部电影的感觉,怎么说呢?有点深奥,还行吧。
但是个人观点,并不能说明一部电影的好坏,我们应该通过了解数万观众对于这部影片的评价再来对这部影片定性吧。
因此,我准备爬取豆瓣对《邪不压正》所有的影评信息,然后通过大数据分析来挖掘观众对于这部影片的评价。
爬虫代码如下:
import requests
import time
from lxml import etree
class DouBan(object):
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.106 Safari/537.36'}
self.session = requests.session()
self.file_path = '/home/lzh/文档/film.txt'
self.proxies = {
'http': 'http://219.141.153.41:80',
'http': 'http://118.190.95.35:9001',
'http': 'http://61.135.217.7:80',
'http': 'http://118.190.95.43:9001',
'http': 'http://101.236.51.35:8866'
}
def login(self):
try:
pass
except Exception as e:
print('login error: ', e.args)
def get_data(self, url):
try:
final_url = url + str(0) + '&limit=20&sort=new_score&status=P'
html = self.session.get(final_url, headers=self.headers, proxies=self.proxies)
num = 0
while html.status_code == 200:
print('connect success')
text = etree.HTML(html.text)
stars = text.xpath('//*[@id="comments"]/div/div[2]/h3/span[2]/span[2]/@title')
support = text.xpath('//*[@id="comments"]/div/div[2]/h3/span[1]/span/text()')
print(stars)
print(support)
comments = text.xpath('//*[@id="comments"]/div/div[2]/p/span/text()')
with open(self.file_path, 'a+') as f:
for i in range(len(stars)):
f.write(stars[i] + ' ' + support[i] + ' ' + comments[i] + '\n')
num = num + 20
url_next = url + str(num) + '&limit=20&sort=new_score&status=P'
html = self.session.get(url_next, headers=self.headers, proxies=self.proxies)
time.sleep(1)
except Exception as e:
print('get data error: ', e.args)
if __name__ == '__main__':
spider = DouBan()
simple_url = 'https://movie.douban.com/subject/26366496/comments?start='
spider.get_data(simple_url)
爬取的数据格式如下:

数据存储在txt文档中,一行分为三个字段,主要是评价等级、赞同该观点的人数、评价内容。
首先需要对数据进行转换和清洗操作,可以将数据转换为两份数据来存储,分别是从评价内容中进行分词,从词频分析观众内心的情感;然后分析五星等级的人数来统计用户的评分。
转换的两份数据格式如下:
评价内容,抽取全部评价内容到一个文本文件:
评价等级及人数部分数据如下:
接着针对上面的评价内容进行分词操作,这里使用了jieba分词工具,使用JAVA API:
首先,引入Jieba分词依赖:
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
分词的核心代码如下:
/**
* 从文本中读取文件并且进行分词处理
* @param sc
* @param filePath
* @return
*/
public static JavaRDD<String> segmentWord(JavaSparkContext sc,String filePath){
InputStreamReader reader=null;
//存放分词结果
List<String> bufferList=new ArrayList<String>();
try {
reader=new InputStreamReader(new FileInputStream(new File(filePath)));
int count=0;
char[] buf=new char[1024];
StringBuffer buffer=new StringBuffer();
while((count=reader.read(buf))!=-1) {
buffer.append(buf, 0, count);
}
String fileText=buffer.toString();
//jieba分词器
JiebaSegmenter segmenter = new JiebaSegmenter();
Object[] list=segmenter.process(fileText, SegMode.INDEX).toArray();
for(Object str:list) {
String words=str.toString().substring(1, str.toString().length()-1);
String[] wordList=words.split(",");
String word=wordList[0];
bufferList.add(word);
}
}catch (Exception e) {
e.printStackTrace();
}finally {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bufferList!=null) {
return sc.parallelize(bufferList);
}
return null;
}
在数据清洗时主要采用了Spark框架来进行数据处理,因此上面有上面的Spark代码,看不懂没关系,后面会附源码。
在分词之后,发现有大量的“我们”,“的”等“停用词”的出现,因此,需要去除停用词,简单说下思路,由于使用了Spark框架,出于方便考虑,利用Spark并行计算的原理,使用LeftOutJoin算子对分词和停用词进行join操作,如果在停用词的词典中出现了该词,则join之后后面会标记一个值,而没有Join上的词表示不是停用词,然后对有标记的词使用filter算子过滤即可。
最后,使用统计分词后的词频数,核心代码如下(注意:由于种种原因,代码本来统一使用java编写,但是使用java编写这部分代码要很长的篇幅,因此这里改用了scala语言来完成,简洁方便,而且两三行解决,java的话至少100行代码,这里想说的是,实际项目中,应当使用一种语言编写,不然会提高了项目的复杂度和可维护性,这里有点废话。):
//读取分词后的HDFS数据文件
val text=sc.textFile("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/movie/wordgrade.txt")
val top100Word=text.flatMap(_.split(" ")).map((_,1)).filter(x=> !x._1.equals(""))
.reduceByKey(_+_).sortBy(_._2,false).take(500)
//插入数据库
insert(top100Word)
由于需要做词云,因此将最后的结果存入了数据库,便于使用web项目到前端展示,对于词云部分使用d3-cloud开源框架编写,下载地址如下:https://github.com/jasondavies/d3-cloud。
最后,词云结果如下 所示:
从词云结果可以看出,姜文导演在观众心中的地位还是很高的,毕竟演技杠杠的,影帝级别的人物;观众对于彭于晏的影响也不错(也是我喜欢的明星之一),从结果可以看出对于影片的褒贬不一,难一下定论。
接着,我们来看看用户对于影片的评分吧。
对于上面的评分等级文档数据进行分析,最后分词结果如下: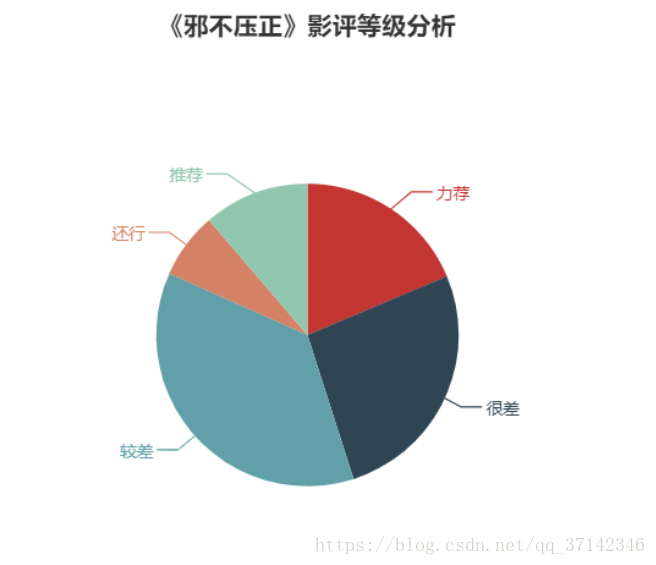
从上图可以直观的看出,该影片的口碑不是很好,当然也有许多推荐。(毕竟姜文导演的作品都比较难懂,反正这部电影我是没怎么看懂)。
最后,附一张彭于晏的帅照:
对于上面项目的所有代码,我会上传到我的github上,感兴趣的读者可以下载:

欢迎关注公众号:


永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)