大数据分析工具之Kudu介绍
1. 什么是 Kudu导读Kudu的应用场景是什么?Kudu在大数据平台中的位置在哪?Kudu用什么样的设计, 才能满足其设计目标?Kudu中有什么集群角色?1.1. Kudu 的应用场景现代大数据的应用场景例如现在要做一个类似物联网的项目, 可能是对某个工厂的生产数据进行分析项目特点数据量大有一个非常重大的挑...
1. 什么是 Kudu
导读
-
Kudu的应用场景是什么? -
Kudu在大数据平台中的位置在哪? -
Kudu用什么样的设计, 才能满足其设计目标? -
Kudu中有什么集群角色?
1.1. Kudu 的应用场景
现代大数据的应用场景
例如现在要做一个类似物联网的项目, 可能是对某个工厂的生产数据进行分析
项目特点
-
数据量大
有一个非常重大的挑战, 就是这些设备可能很多, 其所产生的事件记录可能也很大, 所以需要对设备进行数据收集和分析的话, 需要使用一些大数据的组件和功能
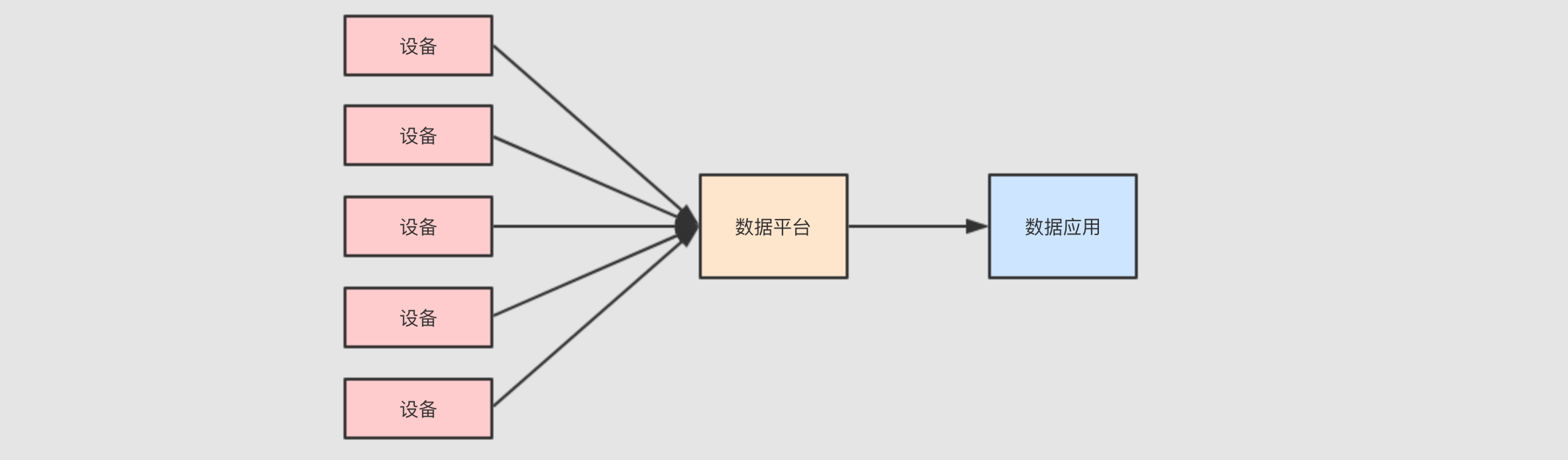
-
流式处理
因为数据是事件, 事件是一个一个来的, 并且如果快速查看结果的话, 必须使用流计算来处理这些数据
-
数据需要存储
最终需要对数据进行统计和分析, 所以数据要先有一个地方存, 后再通过可视化平台去分析和处理
对存储层的要求
这样的一个流计算系统, 需要对数据进行什么样的处理呢?
-
要能够及时的看到最近的数据, 判断系统是否有异常
-
要能够扫描历史数据, 从而改进设备和流程
所以对数据存储层就有可能进行如下的操作
-
逐行插入, 因为数据是一行一行来的, 要想及时看到, 就需要来一行插入一行
-
低延迟随机读取, 如果想分析某台设备的信息, 就需要在数据集中随机读取某一个设备的事件记录
-
快速分析和扫描, 数据分析师需要快速的得到结论, 执行一行
SQL等上十天是不行的
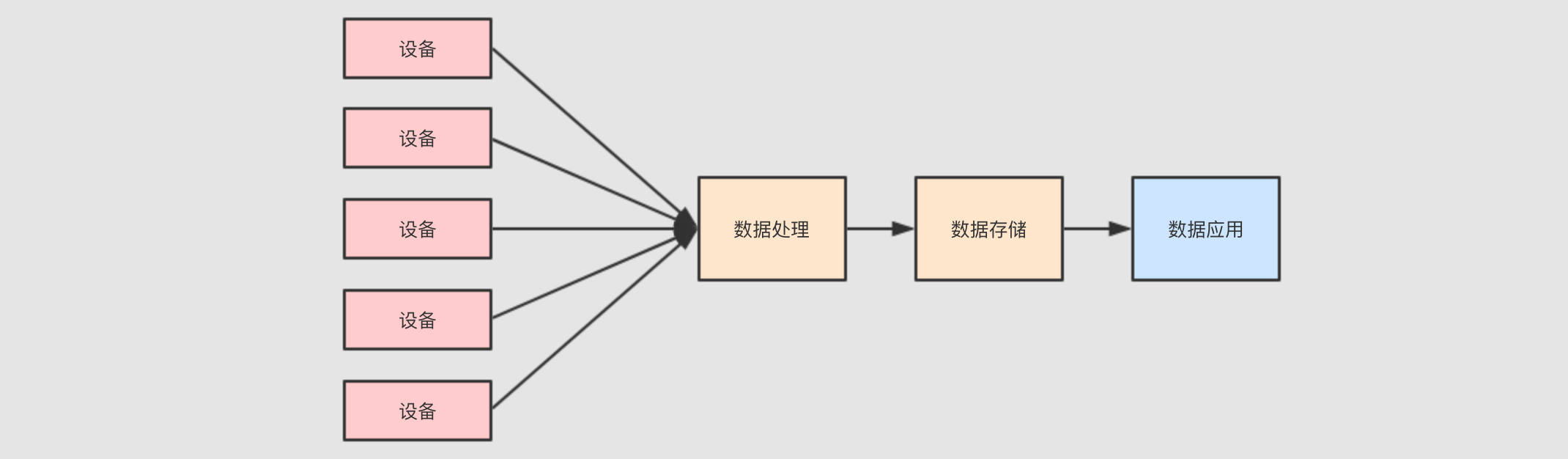
方案一: 使用 Spark Streaming 配合 HDFS 存储
总结一下需求
-
实时处理,
Spark Streaming -
大数据存储,
HDFS -
使用 Kafka 过渡数据

但是这样的方案有一个非常重大的问题, 就是速度机器之慢, 因为 HDFS 不擅长存储小文件, 而通过流处理直接写入 HDFS 的话, 会产生非常大量的小文件, 扫描性能十分的差
方案二: HDFS + compaction
上面方案的问题是大量小文件的查询是非常低效的, 所以可以将这些小文件压缩合并起来

但是这样的处理方案也有很多问题
-
一个文件只有不再活跃时才能合并
-
不能将覆盖的结果放回原来的位置
所以一般在流式系统中进行小文件合并的话, 需要将数据放在一个新的目录中, 让 Hive/Impala 指向新的位置, 再清理老的位置
方案三: HBase + HDFS
前面的方案都不够舒服, 主要原因是因为一直在强迫 HDFS 做它并不擅长的事情, 对于实时的数据存储, 谁更适合呢? HBase 好像更合适一些, 虽然 HBase 适合实时的低延迟的数据村醋, 但是对于历史的大规模数据的分析和扫描性能是比较差的, 所以还要结合 HDFS 和 Parquet 来做这件事

因为 HBase 不擅长离线数据分析, 所以在一定的条件触发下, 需要将 HBase 中的数据写入 HDFS 中的 Parquet 文件中, 以便支持离线数据分析, 但是这种方案又会产生新的问题
-
维护特别复杂, 因为需要在不同的存储间复制数据
-
难以进行统一的查询, 因为实时数据和离线数据不在同一个地方
这种方案, 也称之为 Lambda, 分为实时层和批处理层, 通过这些这么复杂的方案, 其实想做的就是一件事, 流式数据的存储和快速查询
方案四: Kudu
Kudu 声称在扫描性能上, 媲美 HDFS 上的 Parquet. 在随机读写性能上, 媲美 HBase. 所以将存储存替换为 Kudu, 理论上就能解决我们的问题了.

总结
对于实时流式数据处理, Spark, Flink, Storm 等工具提供了计算上的支持, 但是它们都需要依赖外部的存储系统, 对存储系统的要求会比较高一些, 要满足如下的特点
-
支持逐行插入
-
支持更新
-
低延迟随机读取
-
快速分析和扫描
1.2. Kudu 和其它存储工具的对比
导读
-
OLAP和OLTP -
行式存储和列式存储
-
Kudu和MySQL的区别 -
Kudu和HBase的区别
OLAP 和 OLTP
广义来讲, 数据库分为 OLTP 和 OLAP
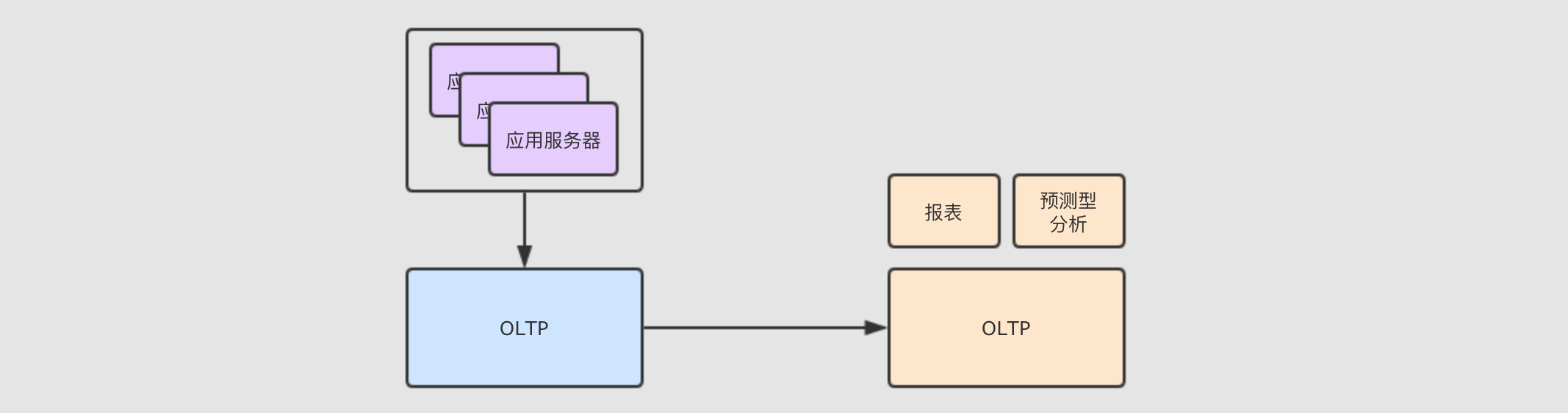
-
OLTP先举个栗子, 在电商网站中, 经常见到一个功能 - "我的订单", 这个功能再查询数据的时候, 是查询的某一个用户的数据, 并不是批量的数据
OLTP需要做的事情是-
快速插入和更新
-
精确查询
所以
OLTP并不需要对数据进行大规模的扫描和分析, 所以它的扫描性能并不好, 它主要是用于对响应速度和数据完整性很高的在线服务应用中 -
-
OLAPOLAP和OLTP的场景不同,OLAP主要服务于分析型应用, 其一般是批量加载数据, 如果出错了, 重新查询即可 -
总结
-
OLTP随机访问能力比较强, 批量扫描比较差 -
OLAP擅长大规模批量数据加载, 对于随机访问的能力则比较差 -
大数据系统中, 往往从
OLTP数据库中ETL放入OLAP数据库中, 然后做分析和处理
-
行式存储和列式存储
行式和列式是不同的存储方式, 其大致如下
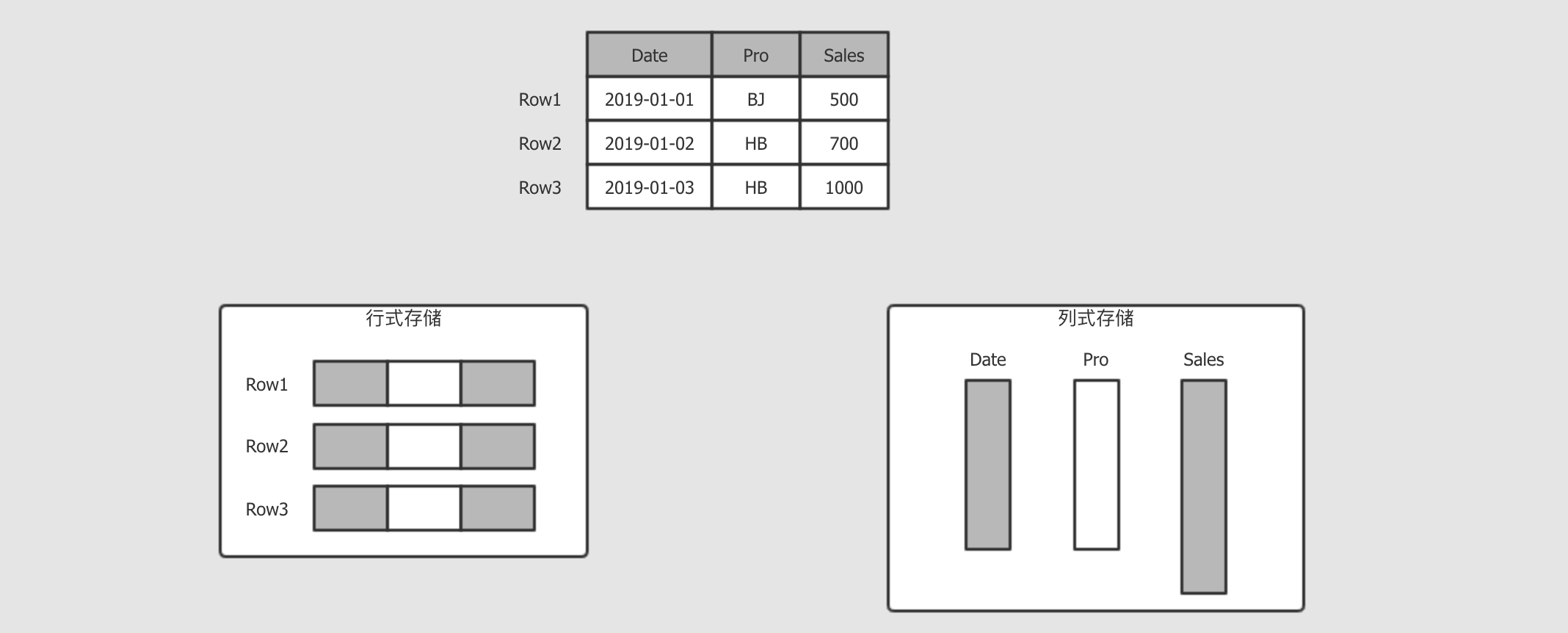
-
行式存储
行式一般用做于
OLTP, 例如我的订单, 那不仅要看到订单, 还要看到收货地址, 付款信息, 派送信息等, 所以OLTP一般是倾向于获取整行所有列的信息 -
列式存储
而分析平台就不太一样了, 例如分析销售额, 那可能只对销售额这一列感兴趣, 所以按照列存储, 只获取需要的列, 这样能减少数据的读取量
存储模型
结构
-
Kudu的存储模型是有结构的表 -
OLTP中代表性的MySQL,Oracle模型是有结构的表 -
HBase是看起来像是表一样的Key-Value型数据,Key是RowKey和列簇的组合,Value是具体的值
主键
-
Kudu采用了Raft协议, 所以Kudu的表中有唯一主键 -
关系型数据库也有唯一主键
-
HBase的RowKey并不是唯一主键
事务支持
-
Kudu缺少跨行的ACID事务 -
关系型数据库大多在单机上是可以支持
ACID事务的
性能
-
Kudu的随机读写速度目标是和HBase相似, 但是这个目标建立在使用SSD基础之上 -
Kudu的批量查询性能目标是比HDFS上的Parquet慢两倍以内
硬件需求
-
Hadoop的设计理念是尽可能的减少硬件依赖, 使用更廉价的机器, 配置机械硬盘 -
Kudu的时代SSD已经比较常见了, 能够做更多的磁盘操作和内存操作 -
Hadoop不太能发挥比较好的硬件的能力, 而Kudu为了大内存和SSD而设计, 所以Kudu对硬件的需求会更大一些
1.3. Kudu 的设计和结构
导读
-
Kudu是什么 -
Kudu的整体设计 -
Kudu的角色 -
Kudu的概念
Kudu 是什么
HDFS 上的数据分析
HDFS 是一种能够非常高效的进行数据分析的存储引擎
-
HDFS有很多支持压缩的列式存储的文件格式, 性能很好, 例如Parquet和ORC -
HDFS本身支持并行
HBase 可以进行高效的数据插入和读取
HBase 主要用于完成一些对实时性要求比较高的场景
-
HBase能够以极高的吞吐量来进行数据存储, 无论是批量加载, 还是大量put -
HBase能够对主键进行非常高效的扫描, 因为其根据主键进行排序和维护 -
但是对于主键以外的列进行扫描则性能会比较差
Kudu 的设计目标
Kudu 最初的目标是成为一个新的存储引擎, 可以进行快速的数据分析, 又可以进行高效的数据随机插入, 这样就能简化数据从源端到 Hadoop 中可以用于被分析的过程, 所以有如下的一些设计目标
-
尽可能快速的扫描, 达到
HDFS中Parquet的二分之一速度 -
尽可能的支持随机读写, 达到
1ms的响应时间 -
列式存储
-
支持
NoSQL样式的API, 例如put,get,delete,scan
总体设计
-
Kudu不支持SQLKudu和Impala都是Cloudera的项目, 所以Kudu不打算自己实现SQL的解析和执行计划, 而是选择放在Impala中实现, 这两个东西配合来完成任务Kudu的底层是一个基于表的引擎, 但是提供了NoSQL的API -
Kudu中存储两类的数据-
Kudu存储自己的元信息, 例如表名, 列名, 列类型 -
Kudu当然也有存放表中的数据
这两种数据都存储在
tablet中 -
-
Master server存储元数据的
tablet由Master server管理 -
Tablet server存储表中数据的
tablet由不同的Tablet server管理 -
tabletMaster server和Tablet server都是以tablet作为存储形式来存储数据的, 一个tablet通常由一个Leader和两个Follower组成, 这些角色分布的不同的服务器中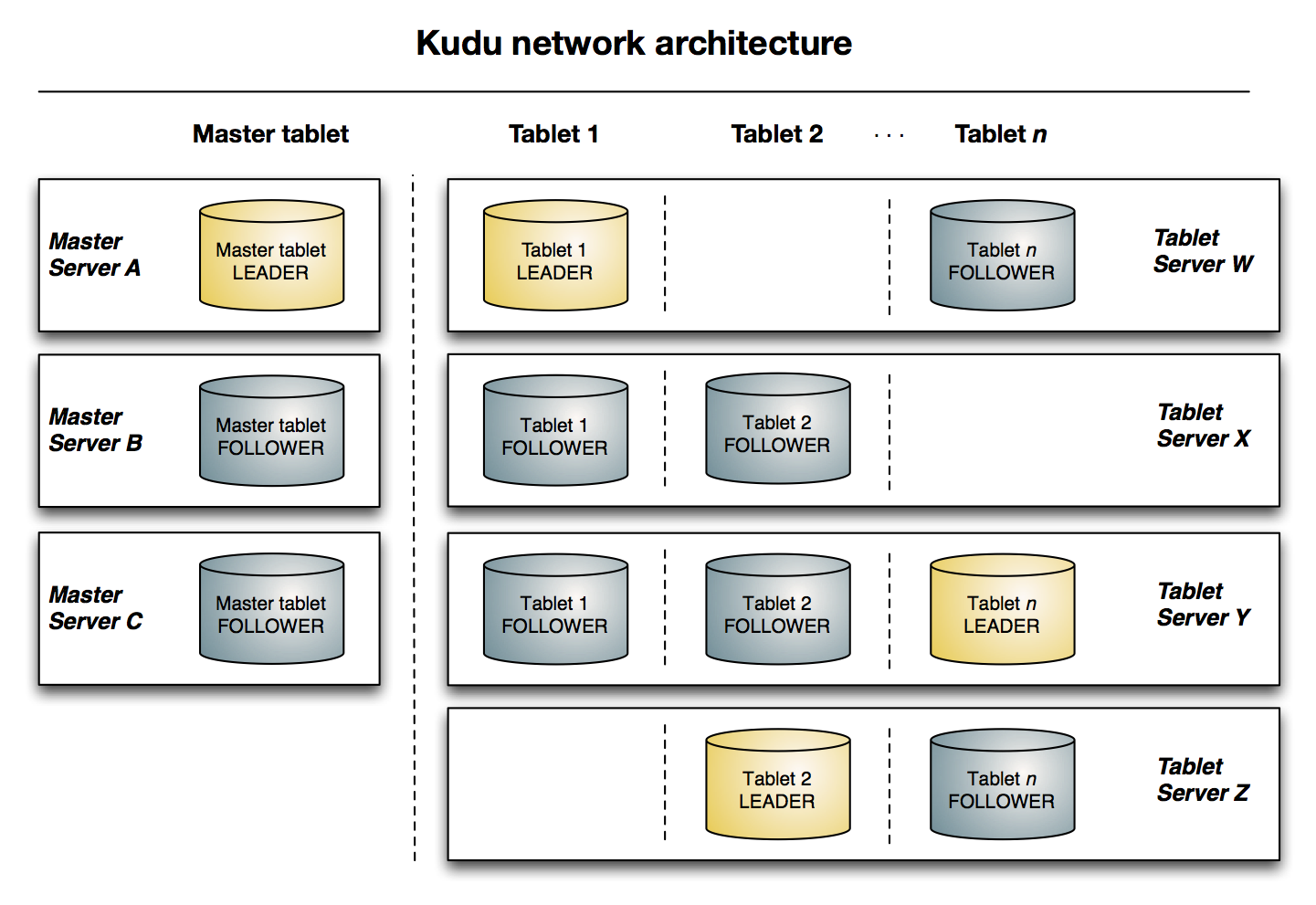
Master server
-
Master server中存储的其实也就是一个tablet, 这个tablet中存储系统的元数据, 所以Kudu无需依赖Hive -
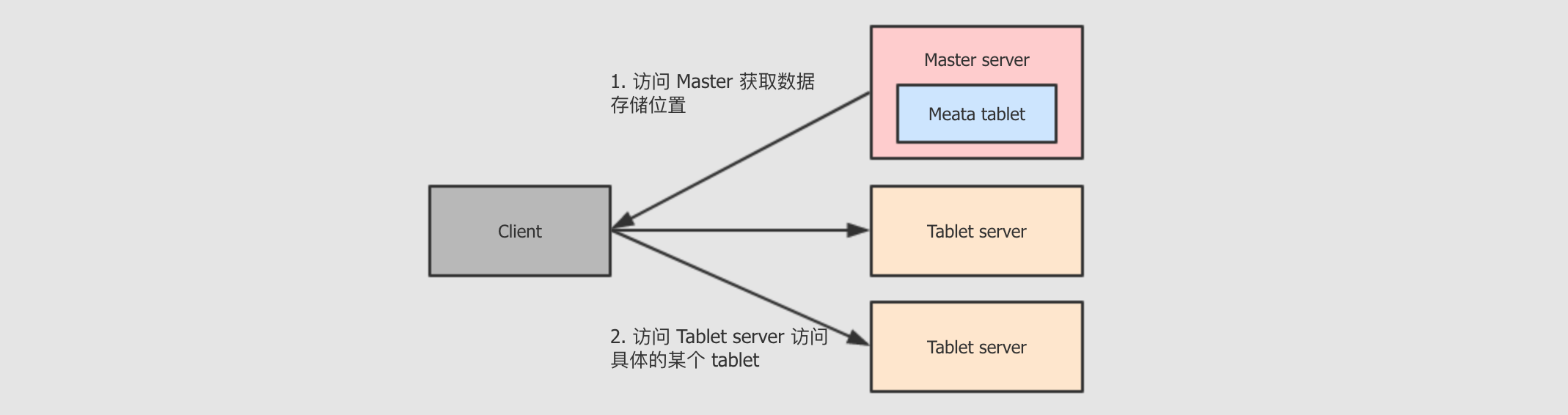
客户端访问某一张表的某一部分数据时, 会先询问
Master server, 获取这个数据的位置, 去对应位置获取或者存储数据 -
虽然
Master比较重要, 但是其承担的职责并不多, 数据量也不大, 所以为了增进效率, 这个tablet会存储在内存中 -
生产环境中通常会使用多个
Master server来保证可用性
Tablet server
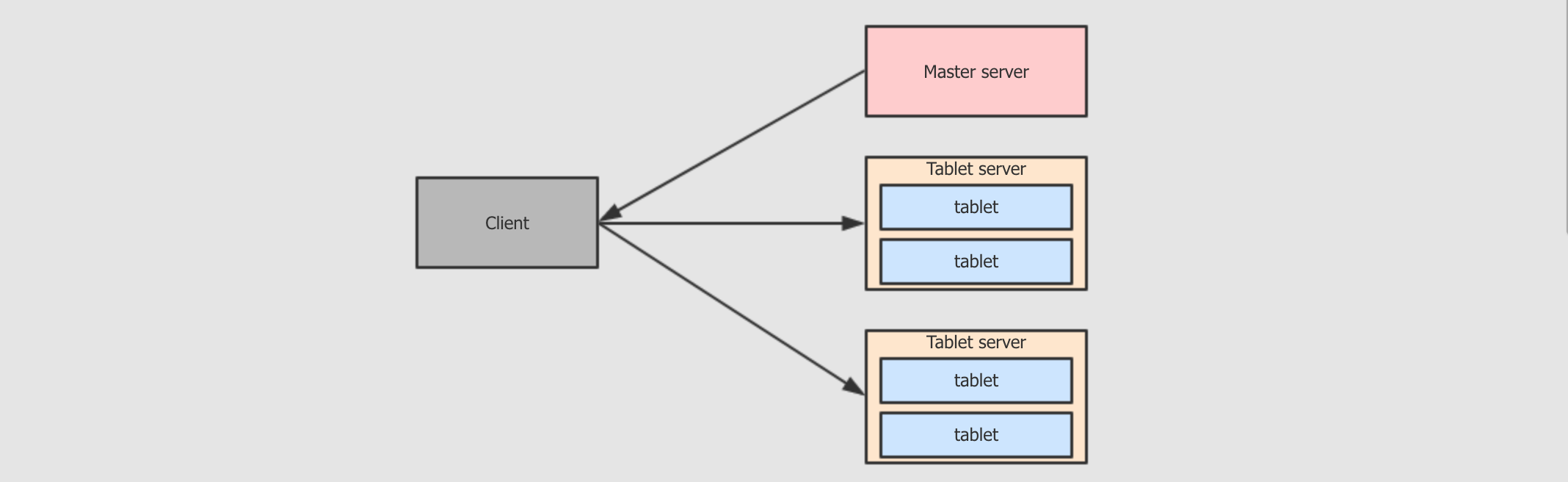
-
Tablet server中也是tablet, 但是其中存储的是表数据 -
Tablet server的任务非常繁重, 其负责和数据相关的所有操作, 包括存储, 访问, 压缩, 其还负责将数据复制到其它机器 -
因为
Tablet server特殊的结构, 其任务过于繁重, 所以有如下的限制-
Kudu最多支持300个服务器, 建议Tablet server最多不超过100个 -
建议每个
Tablet server至多包含2000个tablet(包含Follower) -
建议每个表在每个
Tablet server中至多包含60个tablet(包含Follower) -
每个
Tablet server至多管理8TB数据 -
理想环境下, 一个
tablet leader应该对应一个CPU核心, 以保证最优的扫描性能
-
tablet 的存储结构
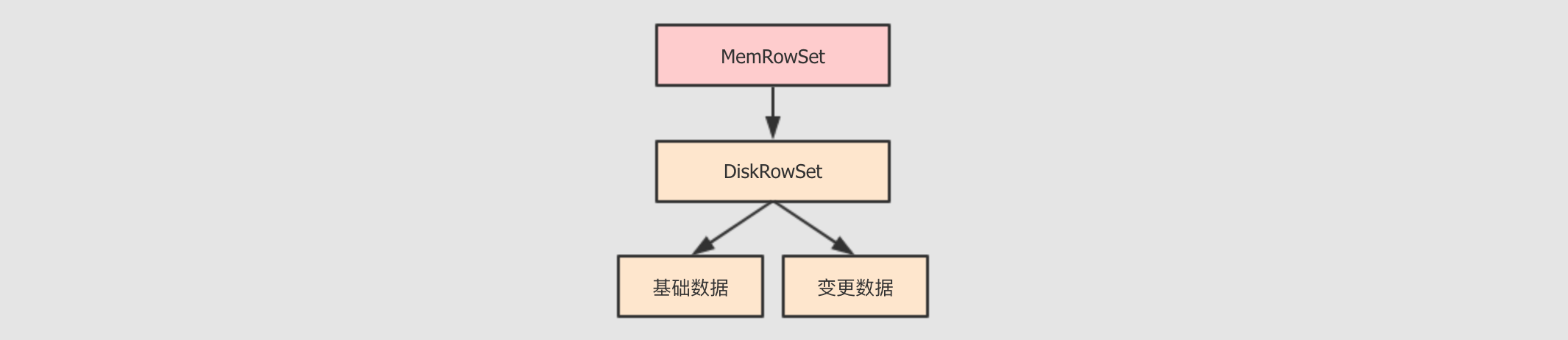
在 Kudu 中, 为了同时支持批量分析和随机访问, 在整体上的设计一边参考了 Parquet 这样的文件格式的设计, 一边参考了 HBase 的设计
-
MemRowSet这个组件就很像
HBase中的MemoryStore, 是一个缓冲区, 数据来了先放缓冲区, 保证响应速度 -
DiskRowSet列存储的好处不仅仅只是分析的时候只
I/O对应的列, 还有一个好处, 就是同类型的数据放在一起, 更容易压缩和编码DiskRowSet中的数据以列式组织, 类似Parquet中的方式, 对其中的列进行编码, 通过布隆过滤器增进查询速度
tablet 的 Insert 流程
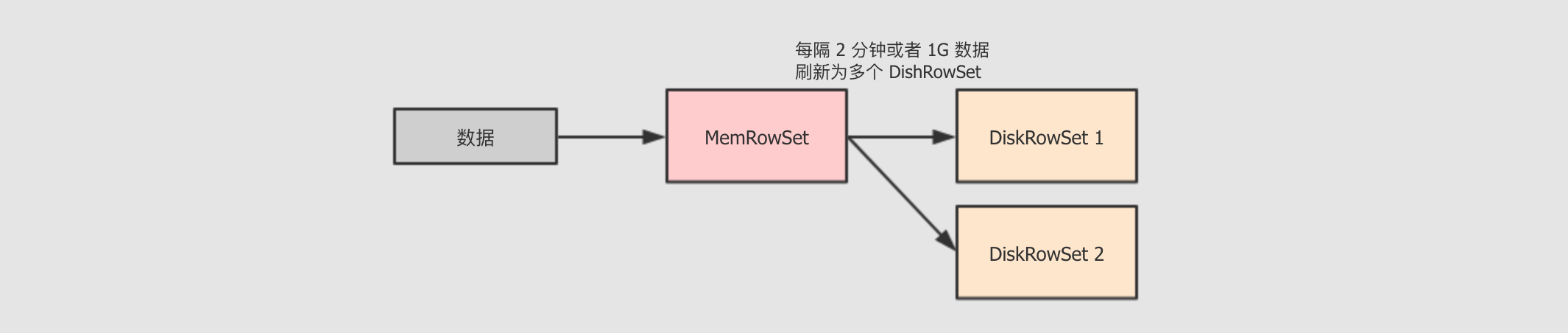
-
使用 MemRowSet 作为缓冲, 特定条件下写为多个 DiskRowSet
-
在插入之前, 为了保证主键唯一性, 会已有的 DiskRowSet 和 MemRowSet 进行验证, 如果主键已经存在则报错
tablet 的 Update 流程
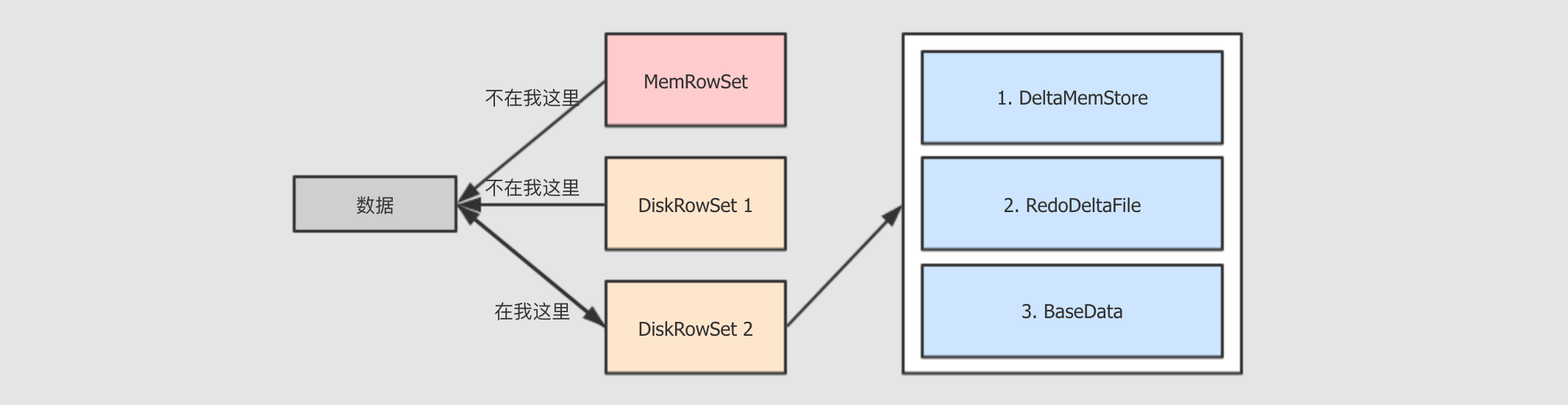
-
查找要更新的数据在哪个
DiskRowSet中 -
数据放入
DiskRowSet所持有的DeltaMemStore中, 这一步也是暂存 -
特定时机下,
DeltaMemStore会将数据溢写到磁盘, 生成RedoDeltaFile, 记录数据的变化 -
定时合并
RedoDeltaFile-
合并策略有三种, 常见的有两种, 一种是
major, 会将数据合并到基线数据中, 一种是minor, 只合并RedoDeltaFile
-

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)