Python之数据挖掘实践--scikit learn库介绍和下载、实践、采坑
文章目录前言A sklearn库是什么?A1 依赖库介绍1.Numpy库2.Scipy库3. matplotlibA2 下载安装B 实践过程B1 主成分分析(PCA)B2 实现Kmeans算法C Debug报错问题C1 报错:ModuleNotFoundError: No module named matplotlibC2 报错:pip version 20.0.2问题描述:解决方法:([参考](
文章目录
前言
数据挖掘小组实验计划将体测报告的数据通过一些聚类算法总结出某些定论,目前需要通过Python来实现。下面是笔者在Python环境下通过Pycharm的 sklearn 库来加载 Iris 数据集,并且使用matplotlib 进行数据可视化。
A sklearn库是什么?
- sklearn是scikit-learn的简称,是一个基于Python的第三方模块。sklearn库集成了一些常用的机器学习方法,在进行机器学习任务时,并不需要实现算法,只需要简单的调用sklearn库中提供的模块就能完成大多数的机器学习任务。
- sklearn库主要模块功能简介如下,这张图将sklearn的功能基本概括。
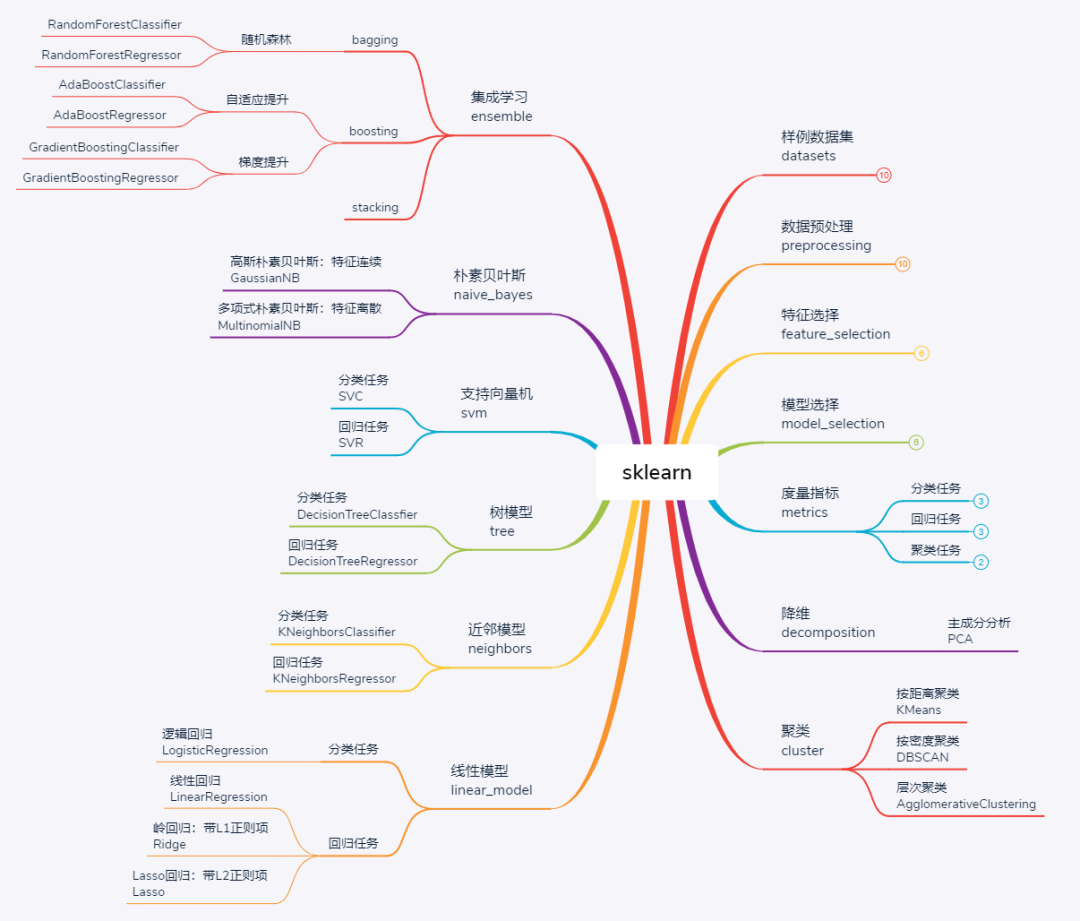
A1 依赖库介绍
sklearn库是在Numpy、Scipy和matplotlib的基础上开发而成的,因此在介绍sklearn的安装前,需要先安装这些依赖库。所以也简单介绍一下:
1.Numpy库
Numpy(Numerical Python的缩写)是一个开源的Python科学计算库。在Python中虽然提供了list容器和array模块,但这些结构并不适合于进行数值计算,因此需要借助于Numpy库创建常用的数据结构(如:多维数组,矩阵等)以及进行常用的科学计算(如:矩阵运算)。
2.Scipy库
Scipy库是sklearn库的基础,它是基于Numpy的一个集成了多种数学算法和函数的Python模块。它的不同子模块有不同的应用,如:积分、插值、优化和信号处理等。
3. matplotlib
matplotlib是基于Numpy的一套Python工具包,它提供了大量的数据绘图工具,主要用于绘制一些统计图形,将大量的数据转换成更加容易被接受的图表。(注意要先安装numpy再安装matplotlib库)
A2 下载安装
因此下载顺序如下:Numpy库、Scipy库、matplotlib库、sklearn库,具体教程参见:sklearn库的安装教程。
下载过程遇到一个小问题:pip升级19.3.1问题

解决方法比较简单,这里就不花时间跟CSDN的大家重复写教程了。
B 实践过程
B1 主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。
首先要了解下主成分分析的基本步骤:

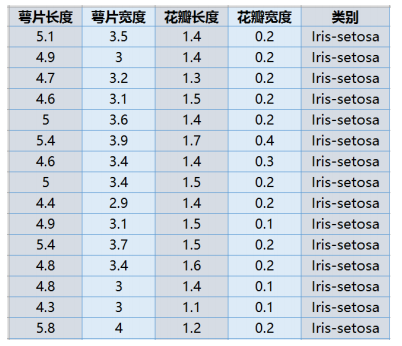
我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布。样本数据结构如下图:
代码部分
import matplotlib.pyplot as plt # 加载matplotlib用于数据的可视化
from sklearn.decomposition import PCA # 加载PCA算法包
from sklearn.datasets import load_iris
data = load_iris()
y = data.target
x = data.data
pca = PCA(n_components=2) # 加载PCA算法,设置降维后主成分数目为2
reduced_x = pca.fit_transform(x) # 对样本进行降维
red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], []
for i in range(len(reduced_x)):
if y[i] == 0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i] == 1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
# 可视化
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()
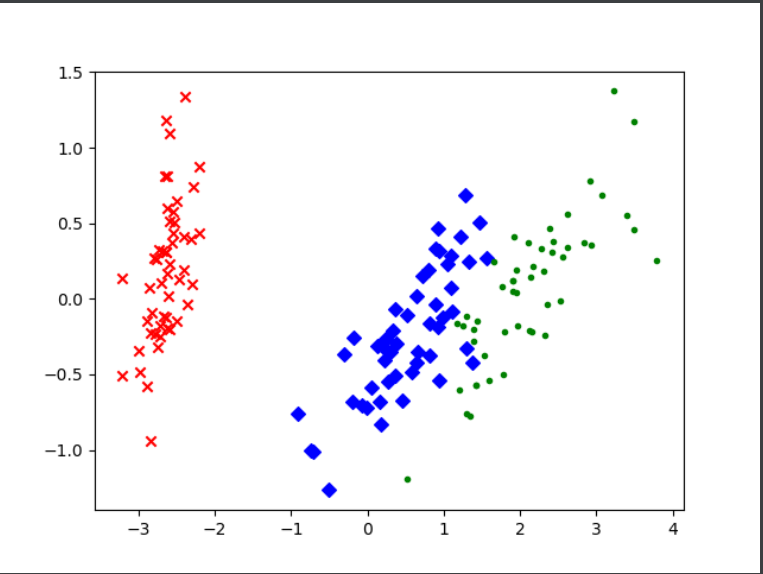
最后结果如下图:
B2 实现Kmeans算法
在机器学习的任务中有一个非常重要的任务就是对样本进行聚类,聚类的方法有很多,本文讲述的是通过使用sklearn库在python中实现kmeans算法。
kmeans是一种无监督的算法,它的步骤如下:
1.随机选择k个点作为初始的聚类中心;
2.对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇
3.对每个簇,计算所有点的均值作为新的聚类中心
4.重复2、3直到聚类中心不再发生改变
接下来会说一下如何通过代码实现这个问题:
import numpy as np
from sklearn.cluster import KMeans #导入sklearn相关包
加载数据,创建K-means算法实例,并进行训练,获得聚类后的标签
if __name__ == '__main__':
data,cityName = loadData('city.txt') #下载样本
km = KMeans(n_clusters=4) #聚类中心为4
label = km.fit_predict(data) #得到聚类后的标签
expenses = np.sum(km.cluster_centers_,axis=1) #按行求和
输出标签,查看结果
CityCluster = [[],[],[],[]]
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i])
for i in range(len(CityCluster)):
print("Expenses:%.2f" % expenses[i])
print(CityCluster[i])
C Debug报错问题
C1 报错:ModuleNotFoundError: No module named matplotlib
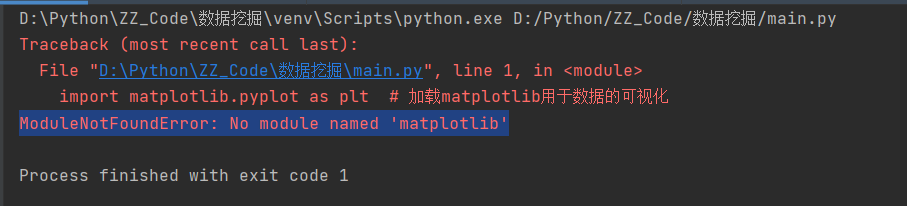
方法一:ModuleNotFoundError: No module named matplotlib 问题解决方案
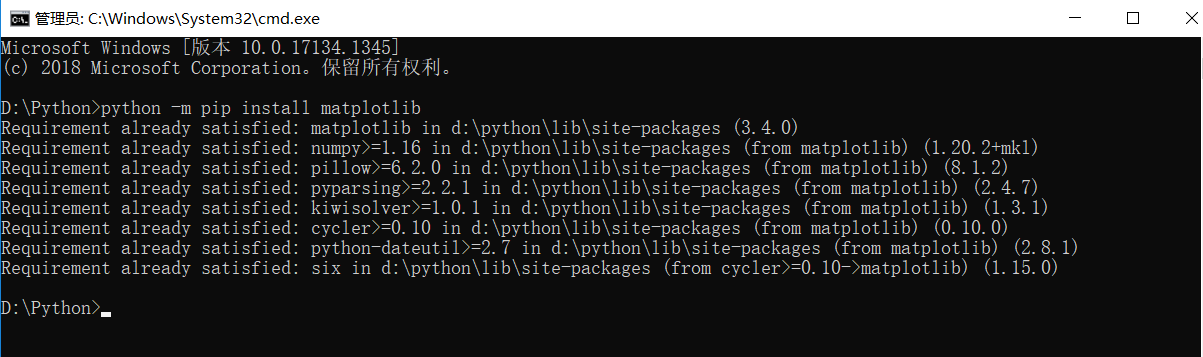
方法二:
https://www.pianshen.com/article/59589674/
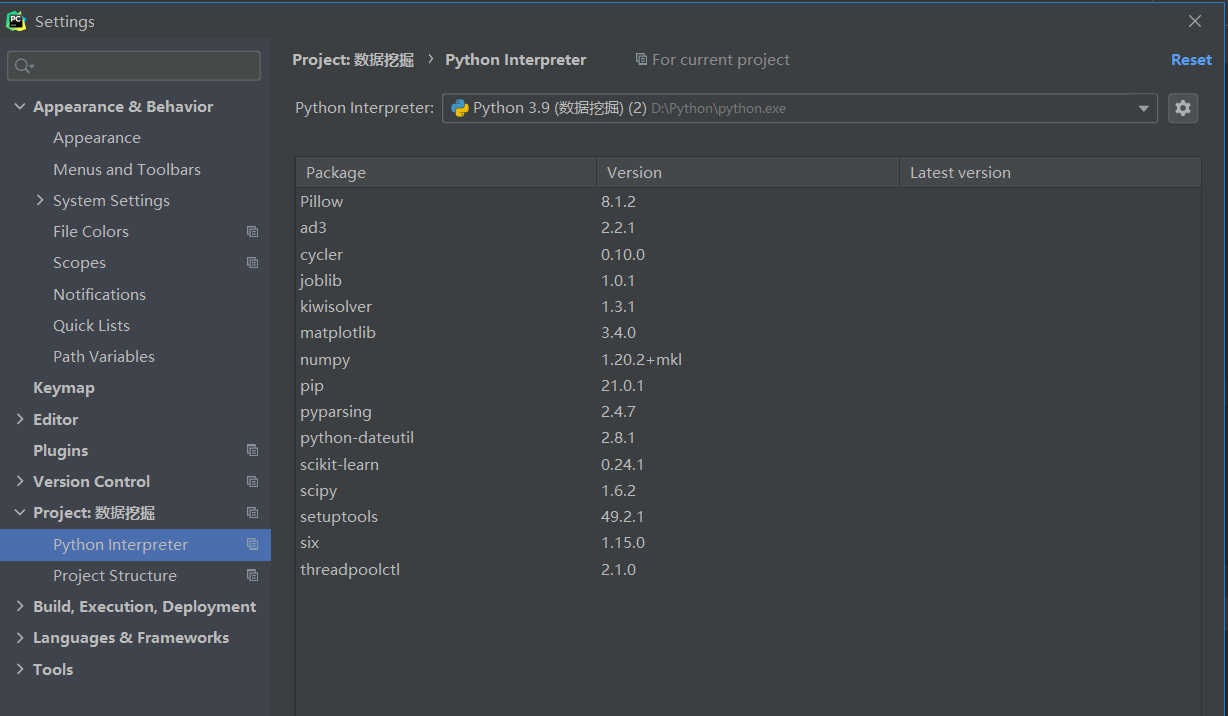
我是通过第二种方法解决的。
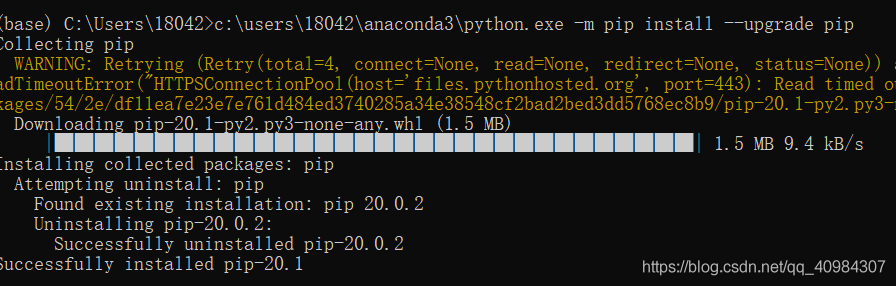
C2 报错:pip version 20.0.2
问题描述:
You are using pip version 20.0.2, however version 20.1 is available

这个意思也就是说我们pip版本有最新的需要我们进行更新。
解决方法:(参考)
1.pip直接更新
pip install --upgrade pip
pip3 install --user --upgrade pip
2.直接使用后面的提示命令
也就是you should consider upgrading via the 后面的命令
3.使用命令
python3 -m pip install pip==版本号
更新完成!
C3 报错:多了空格
特别测试了一下
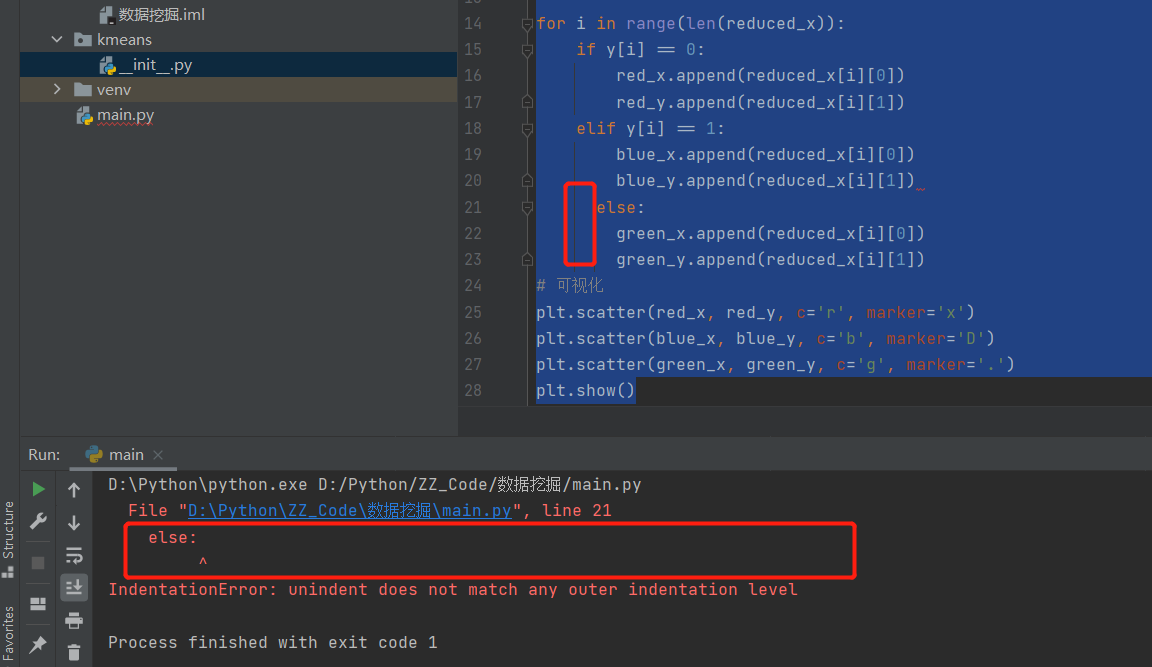
解释:python是采用冒号+缩进来标示代码块,谨防忘记缩进,避免不必要的缩进,并且同级代码的缩进必须相同,不能多也不能少。谨记Tab和空格不要混用,否则性命难保!
D 数据来源
在上面使用kmeans算法时候需要用到数据集,就特别往这个方向查了一下,工作室小伙伴推荐的两个b站视频,讲得还是挺全,链接附下,下面也简单列了一些自己比较常用的
第一类 中国全国数据
- 国务院
- 国家统计局
第二类 中国地方数据
- 地方统计局导航
- 省份/城市+数据开放
第三类 行业数据
- 行业协会(如中国汽车工业协会)
第四类 其他国家数据
- 其他国家统计局导航
- 世界数据集整合
第五类 全球数据
- 国际组织导航(国家统计局有入口)
第六类 数据整合平台
- 知网–年鉴()
第七类 其他特色数据
- 房天下
- 高德地图--------各城市
- 艺恩猫眼--------电影数据
- HiPPTer

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)