商业数据挖掘Part1——前言+挖掘流程+数据检查
详细介绍了数据挖掘流程的相关工作,包括数据清洗、数据理解与分析、特征提取和模型建立等环节。在数据清洗阶段,我们验证了数据集的完整性,处理了数据集中的缺失值,并对各特征数值进行了合理处理。如何筛选了有价值的数据信息,并生成了新的数据源,为后续分析和建模提供了基础。在数据理解与分析阶段,深入理解了各个特征的含义,并通过可视化展示对数据进行了观察和分析。在特征提取阶段从原始数据中提取了与预测目标相关的有
挖掘流程+数据检查
前言
如何从历史数据中找出规律,去预测用户未来的购买需求,让最合适的商品遇见最需要的人,是大数据应用在精准营销中的关键问题,也是所有电商平台在做智能化升级时所需要的核心技术。
本教程以某商城真实的用户、商品和行为数据为基础,通过数据挖掘的技术和机器学习的算法,构越用户购买商品的预测模型,输出高潜用户和目标商品的匹配结果,为精准营销提供高质量的目标群体。
目标:使用该商城多个品类下商品的历史销售数据,构建算法模型,预测用户在未来5天内,对某个目标品类下商品的购买意向
第一章: 数据挖掘流程
(一)数据清洗
1. 数据集完整性验证
检查缺失值、重复值、数值范围和数据类型等常见的完整性验证方法
import pandas as pd
# 读取数据集
data = pd.read_csv('your_dataset.csv')
# 检查是否存在缺失值
missing_values = data.isnull().sum()
print("缺失值统计:")
print(missing_values)
# 检查是否存在重复值
duplicate_rows = data.duplicated()
print("\n重复值统计:")
print(duplicate_rows.sum())
# 检查数值范围是否合理
# 假设要验证某一列的数值范围
column_to_check = 'column_name'
min_value = data[column_to_check].min()
max_value = data[column_to_check].max()
print(f"\n'{column_to_check}' 列的最小值为:{min_value}")
print(f"'{column_to_check}' 列的最大值为:{max_value}")
# 检查数据类型是否正确
# 假设我们要验证某一列的数据类型是否为数值型
column_to_check = 'column_name'
data_types = data[column_to_check].dtypes
print(f"\n'{column_to_check}' 列的数据类型为:{data_types}")
2. 数据集中是否特在缺失值 :填充问题
(1)均值,中位数,众数,最近邻填充,固定值填充
均值填充:用特征列的均值填充缺失值。
data[column_name].fillna(data[column_name].mean(), inplace=True)
中位数填充:用特征列的中位数填充缺失值
data[column_name].fillna(data[column_name].median(), inplace=True)
众数填充:用特征列的众数填充缺失值
data[column_name].fillna(data[column_name].mode()[0], inplace=True)
最近邻填充:使用相似样本的观测值进行填充。
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=2) # 可以根据需要设置n_neighbors的值
data[column_name] = imputer.fit_transform(data[[column_name]])
固定值填充:使用预先设定的固定值填充缺失值(如0或-1)。
data[column_name].fillna(fixed_value, inplace=True)
(2)回归填充、插值法填充、多重插补填充
回归填充:使用其他特征作为自变量,通过回归模型预测缺失值
from sklearn.linear_model import LinearRegression
# 创建回归模型
regressor = LinearRegression()
# 将含有缺失值的特征列作为目标变量,将其他特征作为自变量
target_column = 'column_with_missing_values'
other_columns = ['feature1', 'feature2', 'feature3']
# 拆分数据集为已知和未知两部分
known_data = data[data[target_column].notnull()]
unknown_data = data[data[target_column].isnull()]
# 训练回归模型
regressor.fit(known_data[other_columns], known_data[target_column])
# 预测缺失值并填充
predicted_values = regressor.predict(unknown_data[other_columns])
data.loc[data[target_column].isnull(), target_column] = predicted_values
插值法填充:使用插值方法根据已知值的模式填充缺失值,例如线性插值或样条插值。
# 使用线性插值填充
data['column_with_missing_values'].interpolate(method='linear', inplace=True)
多重插补填充:使用机器学习算法,如随机森林或KNN,根据已有特征的模式预测缺失值。
from fancyimpute import KNN # 需要安装 fancyimpute 库
# 将含有缺失值的特征列作为目标变量,将其他特征作为自变量
target_column = 'column_with_missing_values'
other_columns = ['feature1', 'feature2', 'feature3']
# 使用KNN进行多重插补
imputer = KNN(k=5) # k表示最近邻数目
filled_data = imputer.fit_transform(data[other_columns])
# 将填充后的数据重新赋值给原始数据集
data[other_columns] = filled_data
(3)非负矩阵分解填充 、 EM算法填充
非负矩阵分解 (Non-negative Matrix Factorization, NMF)适用于矩阵数据的缺失值填充,基于矩阵分解的原理。
import numpy as np
from sklearn.decomposition import NMF
# 创建 NMF 模型
nmf_model = NMF(n_components=10) # 可根据实际情况设置 n_components 的值
# 将数据集转换为矩阵形式
matrix_data = data.values
# 填充缺失值
filled_data = nmf_model.fit_transform(matrix_data)
# 将填充后的数据重新赋值给原始数据集
data = pd.DataFrame(filled_data, columns=data.columns)
Expectation-Maximization (EM) 算法:基于观测数据的概率模型,用于对缺失值进行建模和填充。
import missingpy as imputers
# 创建 EMImputer 模型
em_imputer = imputers.EMImputer()
# 填充缺失值
filled_data = em_imputer.fit_transform(data.values)
# 将填充后的数据重新赋值给原始数据集
data = pd.DataFrame(filled_data, columns=data.columns)
3. 数据集中各特征数值应该如何处理 :先懂数据,再做数据
例如:涉及到“年龄”——>进行年龄分组
(1)数据转换:
特征编码:
对于分类变量,可以使用独热编码、标签编码等方法将其转换为数值形式,以便于算法处理。
特征编码是将数据中的非数值型特征转换为数值型特征的过程,以便于机器学习算法的处理。常用的特征编码方式包括:
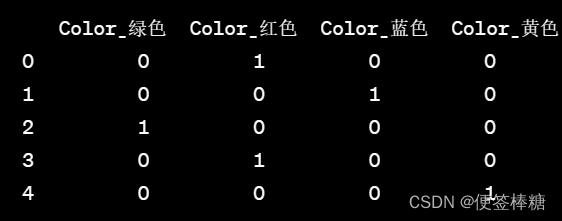
- One-Hot编码:将分类特征的每个类别转换为一个独热向量,只有一个位置为1,其余位置为0。适用于无序的分类特征。
import pandas as pd
# Example DataFrame with a categorical column 'Color'
data = {'Color': ['Red', 'Blue', 'Green', 'Red', 'Blue']}
df = pd.DataFrame(data)
# One-hot encode the 'Color' column
df_encoded = pd.get_dummies(df, columns=['Color'])
print(df_encoded)
2. Label Encoding(标签编码):将分类特征的每个类别映射为一个整数值。适用于有序的分类特征,可用于转换为序列特征。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 示例数据,包含一个分类列'Fruit'
data = {'Fruit': ['苹果', '橘子', '香蕉', '苹果', '橘子', '梨']}
df = pd.DataFrame(data)
# 创建LabelEncoder对象
label_encoder = LabelEncoder()
# 将'Fruit'列进行标签编码
df['Fruit_Label'] = label_encoder.fit_transform(df['Fruit'])
print(df)

- Ordinal Encoding(有序编码):类似于Label Encoding,但在处理有序分类特征时,对类别进行排序并映射为整数值,保留了有序关系。
data = {'Level': ['Low', 'Medium', 'High', 'Medium', 'Low', 'High']}
df = pd.DataFrame(data)
# 手动指定编码映射关系
encoding_map = {'Low': 1, 'Medium': 2, 'High': 3}
# 将'Level'列进行有序编码
df['Level_Encoded'] = df['Level'].map(encoding_map)
print(df)
- Binary Encoding(二进制编码):将整数值编码为二进制形式,然后再拆分成多个二进制特征。适用于高基数的分类特征。减少特征维度,同时保留了分类特征的信息。
二进制编码的步骤如下:
对于每个不重复的分类值,给定一个唯一的整数编码。将该整数编码转换为二进制形式。为每一位二进制数创建一个新的列,并用二进制编码填充该列。
这样,对于n个不同的分类值,经过二进制编码后,将生成log2(n)个新的二进制特征列。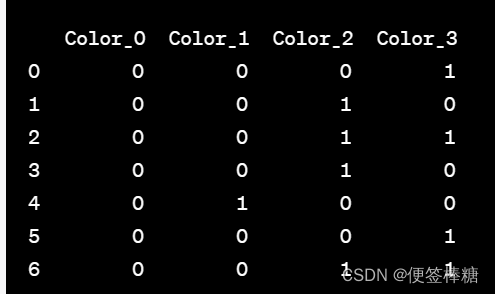 将原始的分类特征转换为了一组二进制特征,用更少的特征表示了原始的多分类特征,有助于提高模型的性能和效率。
将原始的分类特征转换为了一组二进制特征,用更少的特征表示了原始的多分类特征,有助于提高模型的性能和效率。
- Frequency Encoding(频率编码):用每个类别在数据集中出现的频率来替换分类特征中的类别。适用于高基数的分类特征。
将每个类别出现的频率转换为对应的数值。该方法可以将分类特征转换为与其在数据集中出现频率相关的数值,有助于在模型中捕捉类别之间的频率信息
频率编码的步骤如下:
1.) 对于每个不重复的分类值,计算它在整个数据集中出现的频率。
2. )使用该频率值替换原始的分类值,即用频率值进行编码。
import pandas as pd
# 示例数据,包含一个分类列'City',有多个不同的城市名
data = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Houston']}
df = pd.DataFrame(data)
# 计算每个城市名在数据集中出现的频率
city_frequency = df['City'].value_counts(normalize=True)
# 使用频率值替换原始的分类值,得到频率编码后的新列'City_Frequency'
df['City_Frequency'] = df['City'].map(city_frequency)
print(df)
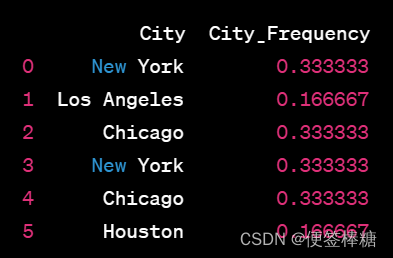
计算了每个城市名在数据集中出现的频率,并用这些频率值替换原始的城市名,得到了一个新的列City_Frequency,它表示了每个城市名的频率编码值。
通过频率编码,我们将原始的分类特征转换为了数值,这些数值与类别在数据集中的出现频率相关联。
- Target Encoding(目标编码或均值编码):用目标变量在每个类别上的平均值来替换分类特征中的类别。
将每个类别对应的目标变量的平均值(或其他统计量)转换为对应的数值。该方法可以将分类特征转换为与目标变量相关的数值,适用于分类特征对目标变量有较强关联的情况。
目标编码的步骤如下:
(1)对于每个不重复的分类值,计算它对应的目标变量的平均值(或其他统计量)。
(2)使用该平均值替换原始的分类值,即用平均值进行编码。
解决分类特征在建模中的问题:
- 处理高基数特征(有很多不同类别的特征):通过目标编码,可以将高基数特征转换为数值,减少特征空间的维度。
- 在分类特征中捕捉目标变量的信息:目标编码利用了目标变量的信息,可以帮助模型更好地理解类别与目标之间的关系。
import pandas as pd
# 示例数据,包含一个分类列'City'和目标变量'Income'
data = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Houston'],
'Income': [50000, 60000, 55000, 48000, 52000, 45000]}
df = pd.DataFrame(data)
# 计算每个城市名对应的目标变量'Income'的平均值
city_income_mean = df.groupby('City')['Income'].mean()
# 使用平均值替换原始的分类值,得到目标编码后的新列'City_Target_Encoding'
df['City_Target_Encoding'] = df['City'].map(city_income_mean)
print(df)
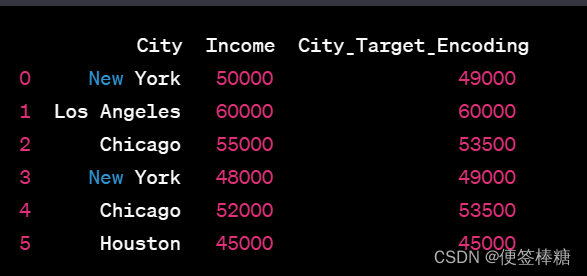
一个名为City的分类列和一个目标变量Income,其中包含多个不同的城市名和相应的收入。
计算每个城市名对应的目标变量Income的平均值,并用这些平均值替换原始的城市名,得到了一个新的列City_Target_Encoding,它表示了每个城市名的目标编码值。
通过目标编码,将原始的分类特征转换为了数值,这些数值与目标变量的平均值相关联。目标编码可以帮助模型更好地利用类别与目标之间的关联性,从而提高预测性能。
可能会引入过拟合问题,因此通常需要进行交叉验证等技术来避免过拟合。
-
Count Encoding(计数编码):用每个类别在数据集中出现的次数来替换分类特征中的类别。
-
Hash Encoding(哈希编码):将类别特征通过哈希函数映射为一组特征,可以减少特征维度。它通过将每个不同的分类值哈希成固定长度的整数,将分类特征转换为数值表示。哈希编码可以用于处理高基数特征(有很多不同类别的特征),从而减少特征空间的维度。
哈希编码的步骤如下:
- 对于每个不同的分类值,使用哈希函数将其映射到一个固定长度的整数。
- 使用映射后的整数替换原始的分类值,即用哈希值进行编码。
哈希编码的优点是可以有效地减少特征空间的维度,并且在处理高基数特征时能够节省内存。
由于哈希函数的特性,不同的分类值可能被映射到相同的哈希值,这可能导致信息损失,同时也难以还原原始的分类值。因此,在使用哈希编码时需要权衡维度的减少与信息损失之间的平衡。
import pandas as pd
import hashlib
# 示例数据,包含一个分类列'City'
data = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Houston']}
df = pd.DataFrame(data)
# 使用MD5哈希函数将每个城市名映射为固定长度的整数(这里使用16位的哈希值)
df['City_Hash_Encoding'] = df['City'].apply(lambda x: int(hashlib.md5(x.encode()).hexdigest(), 16))
print(df)
输出结果如下:
City City_Hash_Encoding
0 New York 196398298693981109819830
1 Los Angeles 4748279794646237864888212
2 Chicago 80685857579411885325158
3 New York 196398298693981109819830
4 Chicago 80685857579411885325158
5 Houston 354400604876138771502849
一个名为City的分类列,使用MD5哈希函数将每个城市名映射为一个16位的整数,得到了一个新的列City_Hash_Encoding,它表示了每个城市名的哈希编码值。
不同的哈希函数可能会得到不同的编码结果。在实际使用中,可以根据具体的需求选择合适的哈希函数和哈希编码的长度。
由于哈希编码的不可逆性,它一般用于特征处理的中间步骤,而不是作为最终的特征表示。
特征归一化/标准化:
将数值特征进行归一化或标准化,以消除量纲差异,确保不同特征之间具有可比性。
时间特征处理:
对于时间戳特征,可以进行拆分,提取年、月、日、小时等信息,或计算时间间隔等衍生特征。
(2)特征缩放:
- 最大最小值缩放:将特征值缩放到[0, 1]范围内,常用于某些要求特征处于相同尺度的算法(如神经网络)。
- 标准化:使用特征的均值和标准差将特征值转换为标准正态分布,常用于某些要求特征服从正态分布的算法(如线性回归)。
- 其他缩放方法:如均值缩放、正则化等,根据不同情况选择适合的缩放方法。
(3)特征组合/交互
- 特征组合:将多个特征进行组合,形成新的特征。例如,将身高和体重组合成BMI指数。这可以帮助模型捕捉更复杂的特征模式。
- 特征交互:将特征之间进行相互作用,例如,将特征A和B相乘形成一个新的特征。这有助于模型捕捉特征之间的相关性和非线性关系。
(4)特征选择
- 方差选择:根据特征的方差进行选择,删除低方差的特征,以减少噪声和冗余信息。
- 相关性选择:根据特征与目标变量之间的相关性进行选择,选择与目标变量具有较高相关性的特征。
- 正则化方法:如L1正则化(Lasso)和L2正则化(Ridge)等,通过增加惩罚项来减少特征的数量和复杂度。
(5)特征降维
- 主成分分析(PCA):通过线性变换将高维数据映射到低维空间,保留主要特征的变换方法。
- 线性判别分析(LDA):在降低维度的同时,最大化类别之间的差异,用于解决分类问题。
- t-SNE:用于可视化高维数据和聚类分析的非线性降维方法。
(6)文本特征处理
- 分词/词袋化:将文本拆分成单词或词条,并将其表示为向量形式,以便计算机能够处理。
- TF-IDF:根据词的频率和在文档集中的重要性计算词的权重,用于表示文本的特征。
- 词嵌入(Word Embedding):使用词向量模型(如Word2Vec、GloVe)将词转换为低维密集向量,捕捉词之间的语义关系。
4. 哪些数据是我们想要的,哪些是可以过滤掉的
5. 将有价值数据信息做成新的数据源 :重新提取和统计
6. 去除无行为交互的商品和用户
7. 去掉浏览量很大而购买量很少的用户(惰性用户或爬虫用户)
(二)数据理解与分析:EDA过程
通过EDA可以获取关于数据的信息,包括数据的质量、分布、异常值、关联性以及潜在的模式和趋势。
1. 掌握各个特征的含义
2. 观察数据有哪些特点,是否可利用来建模
- 数据观察:初步观察数据集的整体情况,包括数据的大小、结构、特征数量等。可以使用函数或工具加载数据,查看数据的前几行、字段名称和数据类型。
- 描述统计分析:计算数据的统计指标,如平均值、中位数、最大值、最小值和方差等。这些统计量可以帮助了解数据的中心趋势、分布形态和离散程度。
- 数据可视化:使用图表和图形展示数据的分布、关系和趋势,以更直观地理解数据。常见的数据可视化方法包括直方图、箱线图、散点图、折线图、饼图等。
- 缺失值和异常值处理:检查数据是否存在缺失值和异常值。可以使用可视化方法和统计技巧来检测异常值,并使用插补或删除等方法处理缺失值。
- 相关性分析:探索变量之间的关联性,可以计算相关系数(如Pearson相关系数)来衡量变量之间的线性相关程度。此外,还可以使用热图等可视化工具来显示变量之间的相关性。
- 特征分布分析:分析各个特征的分布情况,并观察是否存在偏态、峰度等特征。根据特征的分布情况,可以选择合适的数据变换或标准化方法。
- 高维数据降维:对于高维数据集,可以使用降维技术(如主成分分析)来减少变量数量,从而更好地理解和可视化数据。
3. 可视化展示便于分析
4. 用户的购买意向是否随着时间等因素变化
(三) 特征提取:核心部分
- 基于清洗后的数据集哪些特征是有价值
- 分别对用户与商品以及其之间构成的行为进行特征提取
- 行为因素中哪些是核心? 如何提取?
- 瞬时行为特征or累计行为特征?
1. 购买行为特征:
购买频率:客户在一段时间内的购买次数。
购买金额:客户在每次购买中的消费金额。
购买产品类别:客户购买的产品类别或类别组合。
2. 浏览行为特征:
浏览次数:客户在一段时间内浏览产品的次数。
浏览时长:客户在每次浏览中花费的时间。
浏览产品类别:客户浏览的产品类别或类别组合。
3. 购物车行为特征:
添加购物车次数:客户将商品添加到购物车的次数。
添加购物车商品数量:客户每次添加购物车的商品数量。
购物车转化率:添加到购物车的商品最终被购买的比率。
4. 优惠券使用行为特征:
优惠券领取次数:客户领取优惠券的次数。
优惠券使用次数:客户使用优惠券的次数。
优惠券折扣力度:客户使用的优惠券折扣力度(如折扣率或折扣金额)。
5. 用户偏好特征:
品牌偏好:客户对特定品牌的购买偏好程度。
类别偏好:客户对特定产品类别的购买偏好程度。
价格敏感度:客户对产品价格的敏感程度。
6. 用户活跃度特征:
注册时间:客户的注册时间或加入时间。
最近活动时间:客户最近一次进行购买、浏览或其他相关活动的时间。
活跃周期性:客户购买或其他活动的周或月周期性。
6. 地理位置特征:
地理位置信息:客户所在地区、城市或其他地理位置相关信息。
根据具体的数据集和业务需求进行相应的选择和提取,根据购物行为的上下文,还可以考虑时间特征、交互特征等。
其他领域:
1.社交行为:包括与他人交流、分享内容、评论等社交媒体或社交网络上的行为。
2.搜索行为:包括在搜索引擎上输入关键词搜索信息或在网站内部搜索功能上进行搜索的行为。
3.阅读行为:指阅读在线文章、博客、新闻或其他类型的文本内容的行为。
4.视频观看行为:包括观看在线视频、流媒体服务(如YouTube、Netflix)等的行为。
5.游戏行为:指在电子游戏、手机应用程序或在线游戏平台上进行游戏的行为。
6.旅行行为:涉及预订机票、酒店、租车或参观旅游景点等旅行相关的行为。
7.金融行为:包括银行转账、理财投资、股票交易、支付账单等与金融相关的行为。
8.健康行为:涉及健康管理、锻炼、饮食、睡眠等与个人健康相关的行为。
9.学习行为:包括在线学习、参加培训课程、阅读教育资料等学习相关的行为。
10.娱乐行为:指参加音乐会、电影放映、体育比赛等娱乐活动的行为。
个性化推荐、行为分析、市场调研等领域。在实际应用中,根据业务需求和数据可用性选择相应的行为特征进行分析和建模。
(四)模型建立
- 使用机器学习算法进行预测
- 参数设置与调节
- 数据集如何切分
第二章 数据检查
1. 检查用户一致性
保证行为数据中的所产生的行为均由用户数据中的用户产生(但是可能存在用户在行为数据中无行为)思路:利用pd.Merge连接sku 和 Action中的sku, 观察Action中的数据是否减少
def user_action_check():
df_user = pd.read_csv('data/JData_User.csv',encoding='gbk')
df_sku = df_user.loc[:,'user_id'].to_frame()
df_month2 = pd.read_csv('data/JData_Action_201602.csv',encoding='gbk')
print ('Is action of Feb. from User file? ', len(df_month2) == len(pd.merge(df_sku,df_month2)))
df_month3 = pd.read_csv('data/JData_Action_201603.csv',encoding='gbk')
print ('Is action of Mar. from User file? ', len(df_month3) == len(pd.merge(df_sku,df_month3)))
df_month4 = pd.read_csv('data/JData_Action_201604.csv',encoding='gbk')
print ('Is action of Apr. from User file? ', len(df_month4) == len(pd.merge(df_sku,df_month4)))
user_action_check()
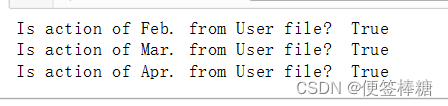 结论: User数据集中的用户和交互行为数据集中的用户完全一致
结论: User数据集中的用户和交互行为数据集中的用户完全一致
根据merge前后的数据量比对,能保证Action中的用户ID是User中的ID的子集
2. 检查重复记录(无意义行为)
除去各个数据文件中完全重复的记录,可能解释是重复数据是有意义的,比如用户同时购买多件商品,同时添加多个数量的商品到购物车等
def deduplicate(filepath, filename, newpath):
df_file = pd.read_csv(filepath,encoding='gbk')
before = df_file.shape[0]
df_file.drop_duplicates(inplace=True)
after = df_file.shape[0]
n_dup = before-after
print ('No. of duplicate records for ' + filename + ' is: ' + str(n_dup))
if n_dup != 0:
df_file.to_csv(newpath, index=None)
else:
print ('no duplicate records in ' + filename)
deduplicate 函数接受三个参数:filepath(输入文件的路径),filename(输入文件的名称)和 newpath(保存去重数据的路径)。
让我们一步一步解析这个函数:
- 使用
pd.read_csv()函数,读取由 filepath 指定的 CSV 文件,并将其赋值给 df_file DataFrame。 - 在变量 before 中存储去重之前 DataFrame 中的行数。
- 调用
df_file.drop_duplicates(inplace=True)方法,对 DataFrame 执行去重操作。该操作会删除 DataFrame 中的重复记录,而保留每个唯一记录的第一个出现。 - 在变量
after中存储去重之后 DataFrame 中的行数。 - 通过将去重之前的行数减去去重之后的行数,计算重复记录的数量。
- 使用
filename和n_dup变量打印指定文件的重复记录数量。 - 如果存在重复记录(
n_dup不为零),则使用df_file.to_csv(newpath, index=None)将经过去重的 DataFrame 保存到由newpath指定的新 CSV 文件中。index=None参数确保在保存的 CSV 文件中不包含索引列。 - 如果不存在重复记录(
n_dup为零),则打印消息说明该文件中不存在重复记录。
deduplicate 函数有助于基于所有列识别和删除 DataFrame 中的重复记录。如果存在重复记录,则将经过去重的 DataFrame 保存到新文件中。
查看一下有无重复记录:
# deduplicate('data/JData_Action_201602.csv', 'Feb. action', 'data/JData_Action_201602_dedup.csv')
deduplicate('data/JData_Action_201603.csv', 'Mar. action', 'data/JData_Action_201603_dedup.csv')
deduplicate('data/JData_Action_201604.csv', 'Feb. action', 'data/JData_Action_201604_dedup.csv')
deduplicate('data/JData_Comment.csv', 'Comment', 'data/JData_Comment_dedup.csv')
deduplicate('data/JData_Product.csv', 'Product', 'data/JData_Product_dedup.csv')
deduplicate('data/JData_User.csv', 'User', 'data/JData_User_dedup.csv')
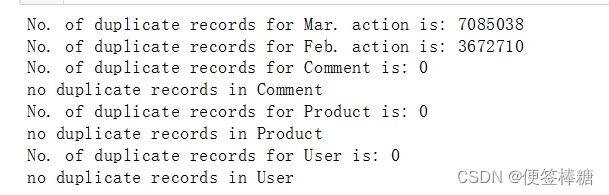 重复数据量比较大,如果去掉可能出现错误地理解用户行为;如果不去掉,则分支累乘 ,考虑到pandas可以处理千万级别的数据量,本文使用保留的方式:
重复数据量比较大,如果去掉可能出现错误地理解用户行为;如果不去掉,则分支累乘 ,考虑到pandas可以处理千万级别的数据量,本文使用保留的方式:
df_month2 = pd.read_csv('data/JData_Action_201602.csv',encoding='gbk')
IsDuplicated = df_month2.duplicated()
df_d=df_month2[IsDuplicated]
df_d.groupby('type').count() #发现重复数据大多数都是由于浏览(1),或者点击(6)产生
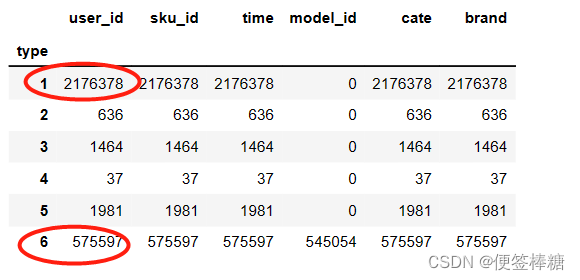
IsDuplicated = df_month2.duplicated()
使用DataFrame的duplicated方法判断df_month2中的每条记录是否为重复记录,并将判断结果保存在名为IsDuplicated的Series对象中。如果某条记录是重复记录,则对应位置为True,否则为False。df_d = df_month2[IsDuplicated]
根据IsDuplicated中的布尔值筛选出df_month2中的重复记录,将其保存为名为df_d的DataFrame对象。df_d.groupby('type').count()
对df_d中的重复记录进行分组,并对每个分组中的记录数进行计数。这里假设df_d中存在一个名为type的列,该代码将根据type列进行分组,并统计每个组中的记录数。这样可以查看每种类型的重复记录的数量。
总结
今日进行了数据挖掘流程的相关工作,主要包括数据清洗、数据理解与分析、特征提取和模型建立等环节。
- 在数据清洗阶段,我们验证了数据集的完整性,处理了数据集中的缺失值,并对各特征数值进行了合理处理。
- 筛选了有价值的数据信息,并生成了新的数据源,为后续分析和建模提供了基础。在数据理解与分析阶段,我们深入理解了各个特征的含义,并通过可视化展示对数据进行了观察和分析。
- 在特征提取阶段,我们从原始数据中提取了与预测目标相关的有价值特征,为模型建立奠定了基础。
- 最后,在模型建立阶段,我们利用经过特征提取和预处理的数据,建立了适合解决问题的预测模型。
- 此外,我们还进行了数据检查,确保了用户数据的一致性,并检查并处理了重复记录,以提高模型的准确性和可靠性。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)