数据挖掘---分类算法之支持向量机实践
有了前面两篇的介绍,相信你对支持向量机有了更多的理解。这里我们一起来说说关于支持向量机代码实践那点事。有很多方式可以做到,我们这里还是举例说明下:1,使用libsvm2,使用R3,使用SPSS还有更多的方式,例如mahout,spark MLlib等等。后面有机会都列出来。
有了前面两篇的介绍,相信你对支持向量机有了更多的理解。这里我们一起来说说关于支持向量机代码实践那点事。
有很多方式可以做到,我们这里还是举例说明下:
1,使用libsvm
libsvm不多介绍了,网上很多相关资料,这里简单说下个人心得体会。
- 训练
不管是通过哪种语言来进行(libsvm有多个语言的版本,java,c,matlab,python等),都必须先进行训练学习。要训练必须有训练样本数据,那么首先得准备训练数据。输入的数据该是什么样子的呢?libsvm提供了样本,我们看看就很容易明白了。很多网友各种叫嚣,就是自己不愿意看看,学习下。libsvm解压后可以看到一个文件heart_scale(话说为什么叫scale,因为要数据预处理,归一化),里面的内容是这样的
+1 1:0.708333 2:1 3:1 4:-0.320755 5:-0.105023 6:-1 7:1 8:-0.419847 9:-1 10:-0.225806 12:1 13:-1
-1 1:0.583333 2:-1 3:0.333333 4:-0.603774 5:1 6:-1 7:1 8:0.358779 9:-1 10:-0.483871 12:-1 13:1
+1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1 8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
-1 1:0.458333 2:1 3:1 4:-0.358491 5:-0.374429 6:-1 7:-1 8:-0.480916 9:1 10:-0.935484 12:-0.333333 13:1
-1 1:0.875 2:-1 3:-0.333333 4:-0.509434 5:-0.347032 6:-1 7:1 8:-0.236641 9:1 10:-0.935484 11:-1 12:-0.333333 13:-1
-1 1:0.5 2:1 3:1 4:-0.509434 5:-0.767123 6:-1 7:-1 8:0.0534351 9:-1 10:-0.870968 11:-1 12:-1 13:1
+1 1:0.125 2:1 3:0.333333 4:-0.320755 5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.5
+1 1:0.25 2:1 3:1 4:-0.698113 5:-0.484018 6:-1 7:1 8:0.0839695 9:1 10:-0.612903 12:-0.333333 13:1
+1 1:0.291667 2:1 3:1 4:-0.132075 5:-0.237443 6:-1 7:1 8:0.51145 9:-1 10:-0.612903 12:0.333333 13:1
+1 1:0.416667 2:-1 3:1 4:0.0566038 5:0.283105 6:-1 7:1 8:0.267176 9:-1 10:0.290323 12:1 13:1
很明显,格式就知道了,我好久没有看,但是一看到这个就像起来了。
类别 下标:下标对应数值 下标:下标对应数值 下标:下标对应数值
比如: 输入向量有5列

对应的文件内容是这个样子滴:
+1 1:0.5 3:0.4 5:0.9
-1 2:0.6 5:0.8
很明显,对于空值比较多的情况,这样是很节省的。
参数选择。具体的不多说了,包括
-s svm_type
-t kernel_type
-d degree
这是我使用默认的参数,使用heart_scale文件进行训练
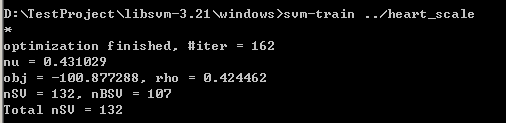
训练之后的模型文件是神马样子的呢?发现多出了一个文件heart_scale.model,这个就是模型文件
svm_type c_svc
kernel_type rbf
gamma 0.0769231
nr_class 2
total_sv 132
rho 0.424462
label 1 -1
nr_sv 64 68
SV
1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1 8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
0.5104832128985164 1:0.125 2:1 3:0.333333 4:-0.320755 5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.5
1 1:0.333333 2:1 3:-1 4:-0.245283 5:-0.506849 6:-1 7:-1 8:0.129771 9:-1 10:-0.16129 12:0.333333 13:-1
1 1:0.208333 2:1 3:0.333333 4:-0.660377 5:-0.525114 6:-1 7:1 8:0.435115 9:-1 10:-0.193548 12:-0.333333 13:1
1 1:0.166667 2:1 3:0.333333 4:-0.358491 5:-0.52968 6:-1 7:1 8:0.206107 9:-1 10:-0.870968 12:-0.333333 13:1
1 1:0.25 2:1 3:-1 4:0.245283 5:-0.328767 6:-1 7:1 8:-0.175573 9:-1 10:-1 11:-1 12:-1 13:-1
1 1:-0.541667 2:1 3:1 4:0.0943396 5:-0.557078 6:-1 7:-1 8:0.679389 9:-1 10:-1 11:-1 12:-1 13:1
1 1:0.25 2:1 3:0.333333 4:-0.396226 5:-0.579909 6:1 7:-1 8:-0.0381679 9:-1 10:-0.290323 12:-0.333333 13:0.5
1 1:-0.166667 2:1 3:0.333333 4:-0.54717 5:-0.894977 6:-1 7:1 8:-0.160305 9:-1 10:-0.741935 11:-1 12:1 13:-1
1 1:-0.375 2:1 3:1 4:-0.698113 5:-0.675799 6:-1 7:1 8:0.618321 9:-1 10:-1 11:-1 12:-0.333333 13:-1
0.02019394891242795 1:0.541667 2:1 3:-0.333333 4:0.245283 5:-0.452055 6:-1 7:-1 8:-0.251908 9:1 10:-1 12:1 13:0.5
。。。。。。
- 预测
-1
-1
1
-1
-1
1
1
1
1
- 评估

2,使用R
3,使用SPSS
还有更多的方式,例如mahout,spark MLlib等等。后面有机会都列出来。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)