
计算机毕业设计hadoop+spark+hive天气预测系统 天气可视化大屏 大数据毕业设计(源码+LW文档+PPT+讲解)
计算机毕业设计hadoop+spark+hive天气预测系统 天气可视化大屏大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
开题报告
题目:Hadoop+Spark+Hive天气预测系统
一、研究背景与意义
在当今信息时代,大数据已成为科学研究和行业应用的重要驱动力。气象领域,尤其是天气预报,正是大数据技术应用广泛的领域之一。天气预报需要处理大量的数据,包括实时的气象数据、历史气象数据、卫星图像、气象模型等。传统的数据处理方法已无法满足天气预测系统对大规模数据处理的需求,因此需要借助大数据处理技术。
Hadoop、Spark和Hive作为大数据处理领域的领军技术,各自具有独特的优势。Hadoop提供了分布式存储和计算能力,适合处理大规模天气数据;Spark提供了批处理和流处理能力,适合对天气数据进行实时或批量分析;Hive基于Hadoop的数据仓库工具,提供数据管理和查询功能,方便对天气数据进行清洗、聚合和转换。将这些技术结合应用于天气预测系统中,具有提高预测准确性、提升数据处理效率、优化资源配置和推动大数据技术应用的重要意义。
二、研究目标与内容
2.1 研究目标
本研究旨在利用Hadoop、Spark和Hive构建天气预测系统,实现以下目标:
- 提高天气预测的准确性和可靠性,通过深度挖掘和分析大规模天气数据,构建精准的预测模型。
- 提升数据处理效率,利用Hadoop和Spark的分布式计算能力,加速天气数据的处理和分析。
- 优化资源配置,帮助气象部门和相关行业更好地了解天气趋势和需求。
- 探索大数据技术在天气预测中的应用,为气象行业数字化转型提供实践经验和理论支持。
2.2 研究内容
本研究将围绕以下内容进行展开:
- 数据采集与预处理:通过气象站、卫星、雷达、气象模型等渠道获取天气数据,并进行清洗、去重、格式化等预处理操作,确保数据质量。
- 数据存储与管理:利用Hadoop的分布式文件系统(HDFS)存储天气数据,确保数据的完整性和安全性;利用Hive对天气数据进行管理和查询,方便后续分析。
- 数据处理与分析:利用Spark对预处理后的天气数据进行分析,提取有用特征;基于时间序列分析、机器学习等算法,构建天气预测模型。
- 系统设计与实现:设计并实现天气预测系统的各个模块,包括数据采集、存储、处理、建模和预测等功能,构建完整的天气预测系统。
- 系统测试与优化:进行单元测试、集成测试和用户测试,确保系统稳定性和预测准确性;根据测试结果优化预测算法和系统性能。
三、技术选型与架构
3.1 技术选型
- Hadoop:用于提供分布式存储和计算能力,支持大规模天气数据的存储和处理。
- Spark:用于提供批处理和流处理能力,支持对天气数据的实时或批量分析,以及机器学习算法的实现。
- Hive:基于Hadoop的数据仓库工具,用于提供数据管理和查询功能,方便对天气数据进行清洗、聚合和转换。
3.2 系统架构
本系统采用大数据处理架构,包括数据采集层、数据存储层、数据处理层、预测算法层和应用服务层。
- 数据采集层:通过气象站、卫星、雷达、气象模型等渠道获取天气数据。
- 数据存储层:利用Hadoop的分布式文件系统(HDFS)存储天气数据。
- 数据处理层:利用Spark对采集到的天气数据进行清洗、去重、格式化等预处理操作;利用Hive对预处理后的数据进行进一步分析,提取有用特征。
- 预测算法层:基于时间序列分析、机器学习等算法,构建天气预测模型;利用Spark的机器学习库(如MLlib)实现预测算法。
- 应用服务层:提供天气预测服务,为气象部门和相关行业提供精准的预测结果。
四、研究方法与步骤
4.1 研究方法
本研究将采用以下方法进行研究:
- 文献调研:研究Hadoop、Spark和Hive的技术文档和应用案例,了解预测算法。
- 需求分析:明确系统功能需求和非功能需求(性能、安全性)。
- 系统设计:设计数据库模型、API接口和预测算法。
- 算法实现:基于Spark MLlib实现预测算法,集成到系统中。
- 系统测试:进行单元测试、集成测试和用户测试,确保系统稳定性和预测准确性。
4.2 研究步骤
- 数据准备:收集并预处理天气数据,包括实时的气象数据、历史气象数据、卫星图像、气象模型等。
- 环境搭建:搭建Hadoop、Spark和Hive的分布式计算环境,配置相关参数。
- 模块开发:按照系统架构,逐步开发数据采集、存储、处理、建模和预测等模块。
- 系统集成:将各个模块进行集成,构建完整的天气预测系统。
- 系统测试与优化:进行系统测试,根据测试结果优化预测算法和系统性能。
五、预期成果与创新点
5.1 预期成果
- 实现一个基于Hadoop、Spark和Hive的天气预测系统,能够处理大规模天气数据,提供精准的预测结果。
- 发表相关学术论文,总结天气预测系统的设计与实现经验,为相关领域提供参考。
5.2 创新点
- 将Hadoop、Spark和Hive等大数据处理工具应用于天气预测系统中,提高了预测准确性和数据处理效率。
- 提出了基于时间序列分析和机器学习算法的天气预测模型,优化了预测算法。
六、研究计划与时间表
- 2025年03月-2025年04月:进行文献调研和需求分析,明确系统功能需求和非功能需求。
- 2025年05月-2025年06月:搭建Hadoop、Spark和Hive的分布式计算环境,进行环境配置和测试。
- 2025年07月-2025年09月:开发数据采集、存储、处理、建模和预测等模块,进行单元测试。
- 2025年10月-2025年11月:将各个模块进行集成,构建完整的天气预测系统,进行集成测试和用户测试。
- 2025年12月:优化预测算法和系统性能,整理研究成果,撰写学术论文。
七、参考文献
参考文献部分需根据实际查阅的文献资料进行填写,以下仅为示例
Hadoop官方文档
Spark官方文档
Hive官方文档
- 张三, 李四. 基于Hadoop的大数据处理技术研究
J
. 计算机科学, 2024, 41(3):123-130.
5. 王五, 赵六. 机器学习算法在天气预报中的应用
J
. 气象学报, 2023, 71(2):234-242.
以上开题报告仅为示例,具体内容需根据实际情况进行调整和完善。
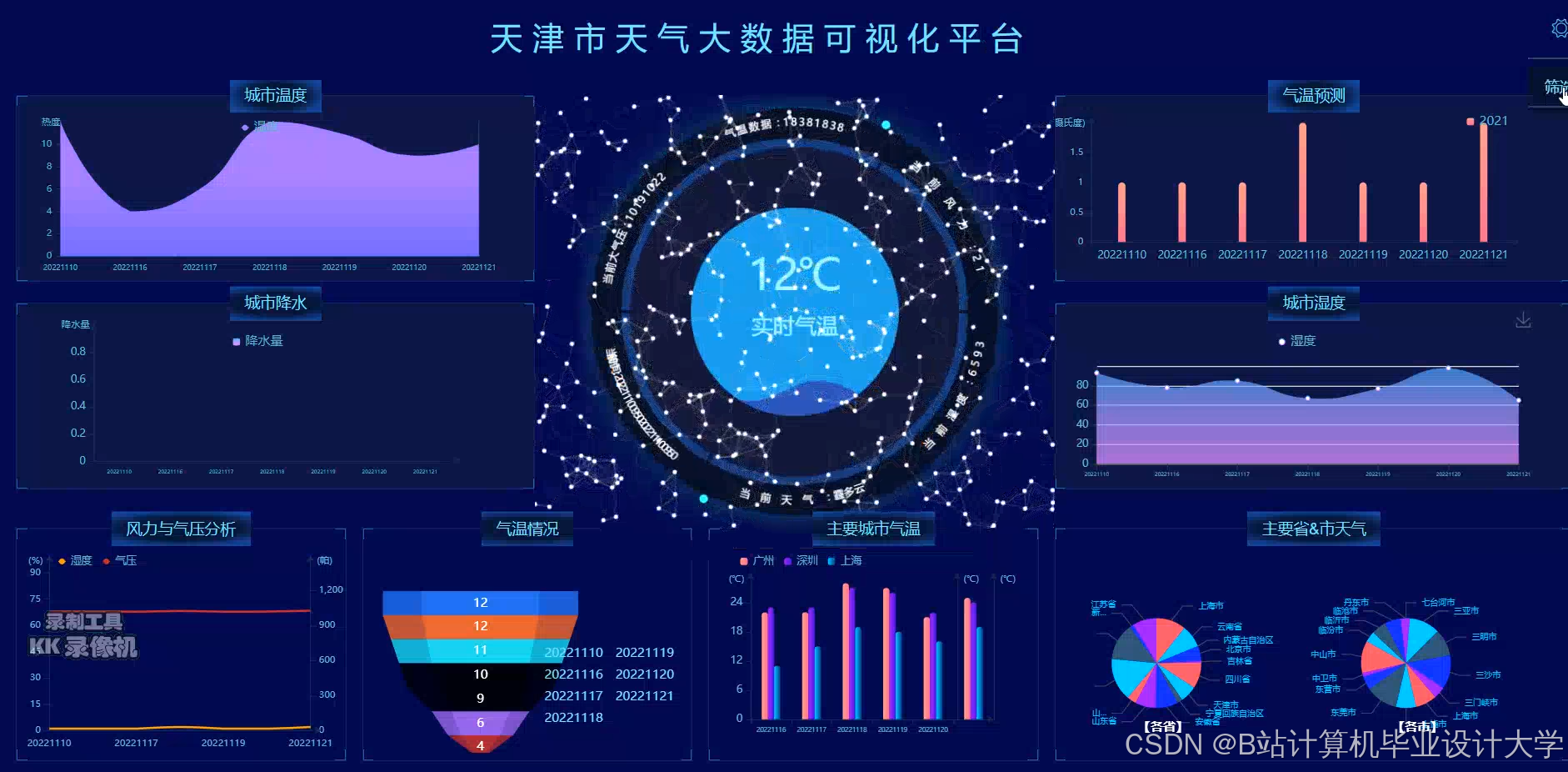
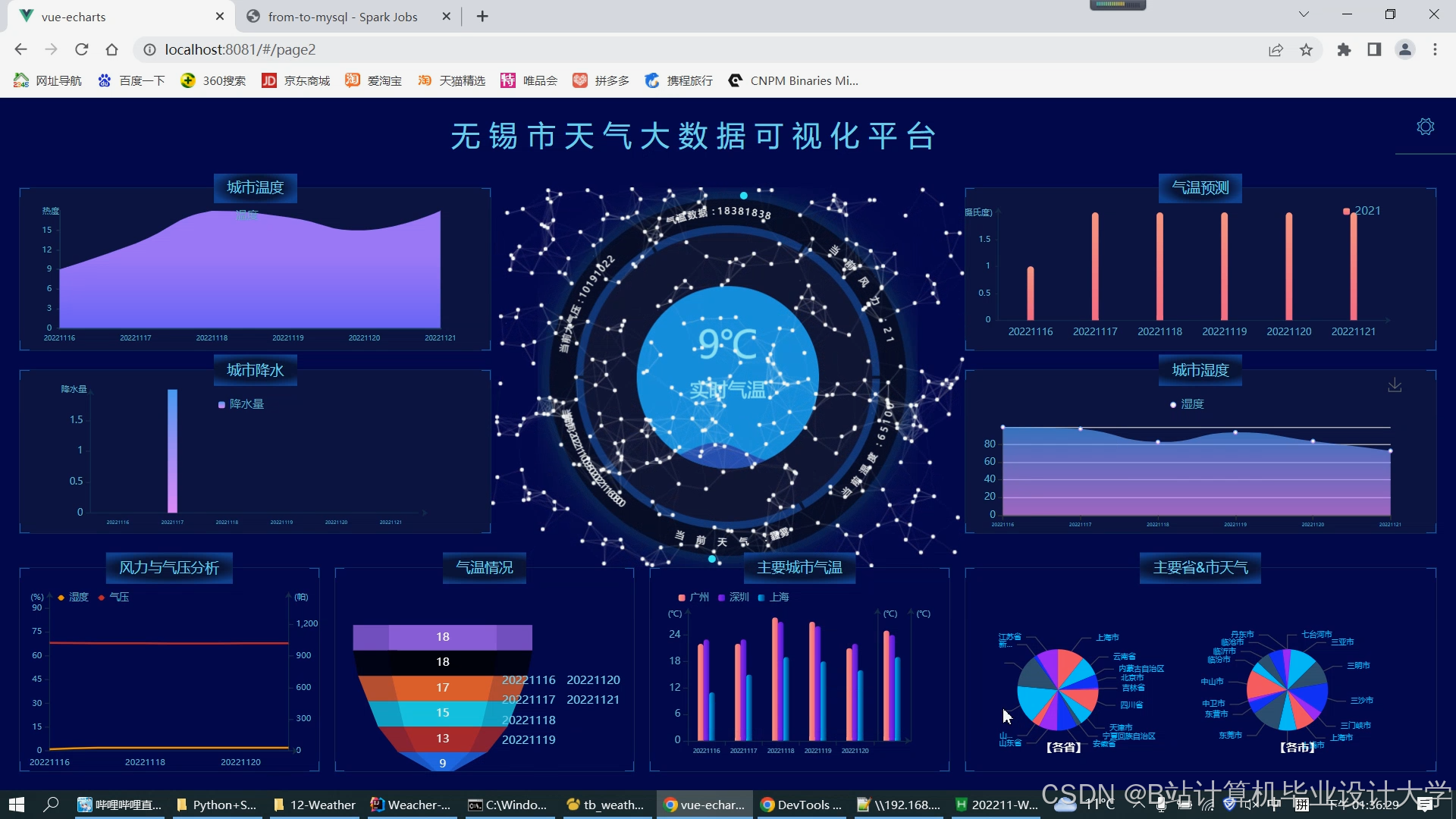
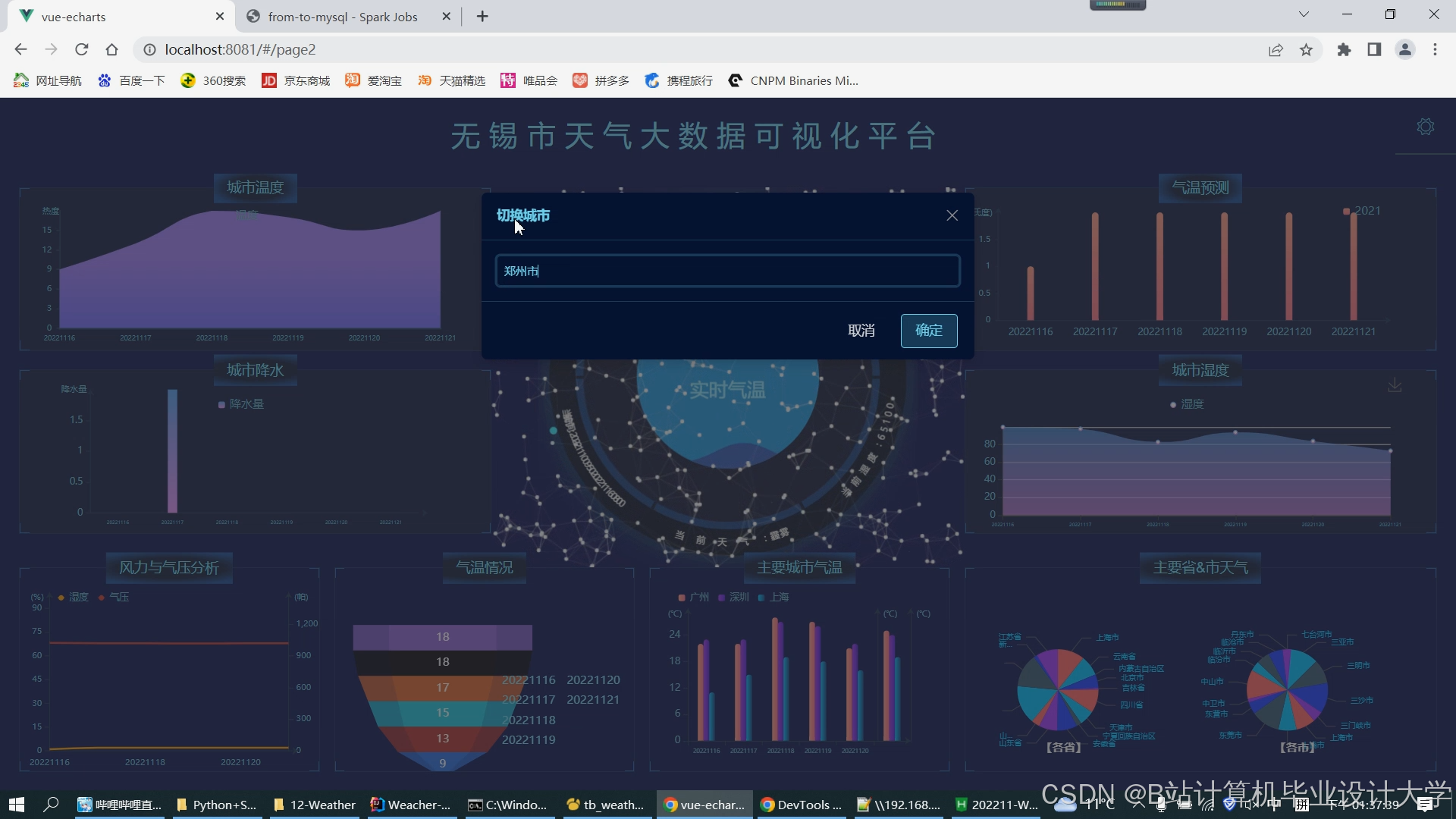
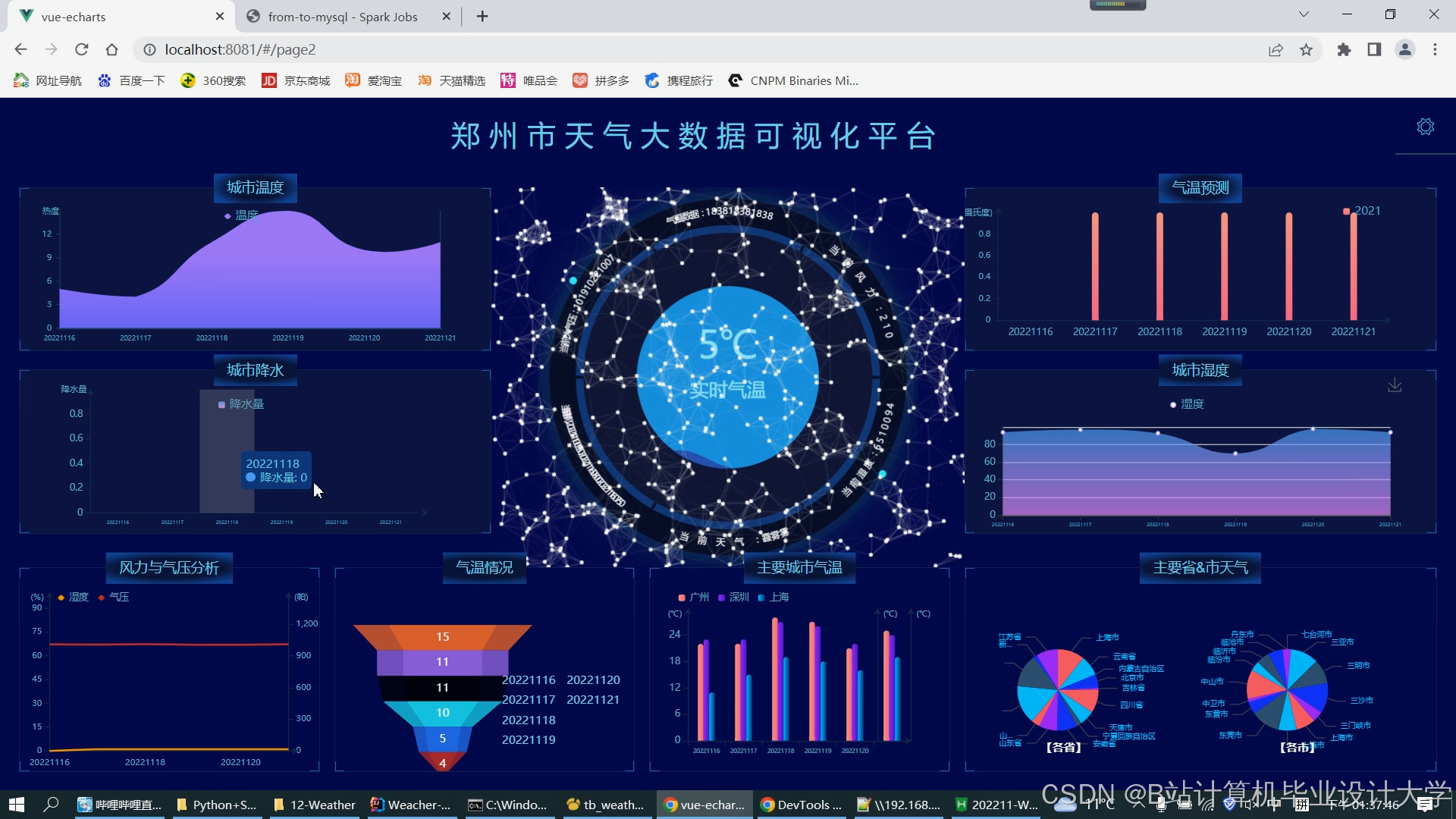
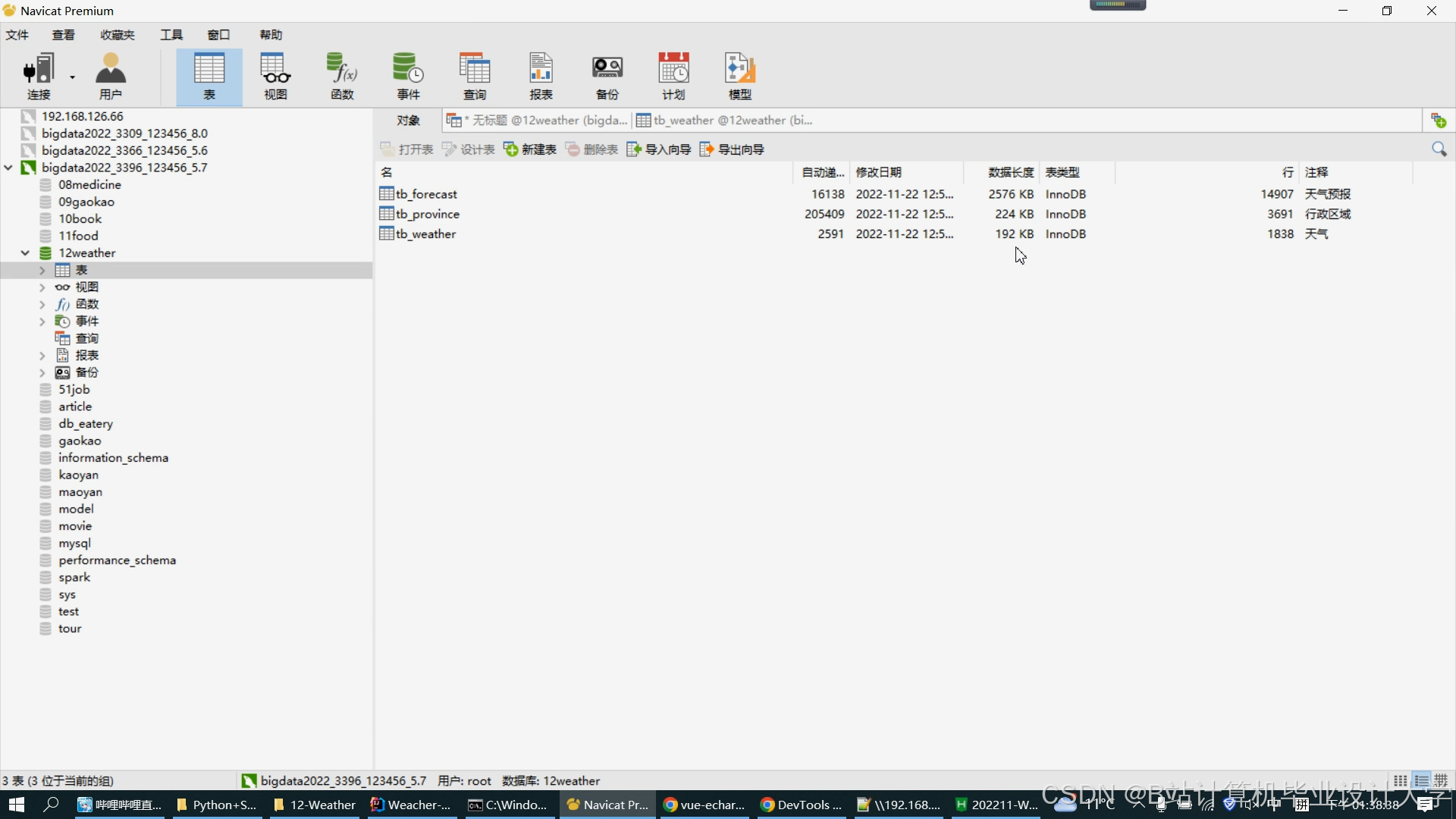
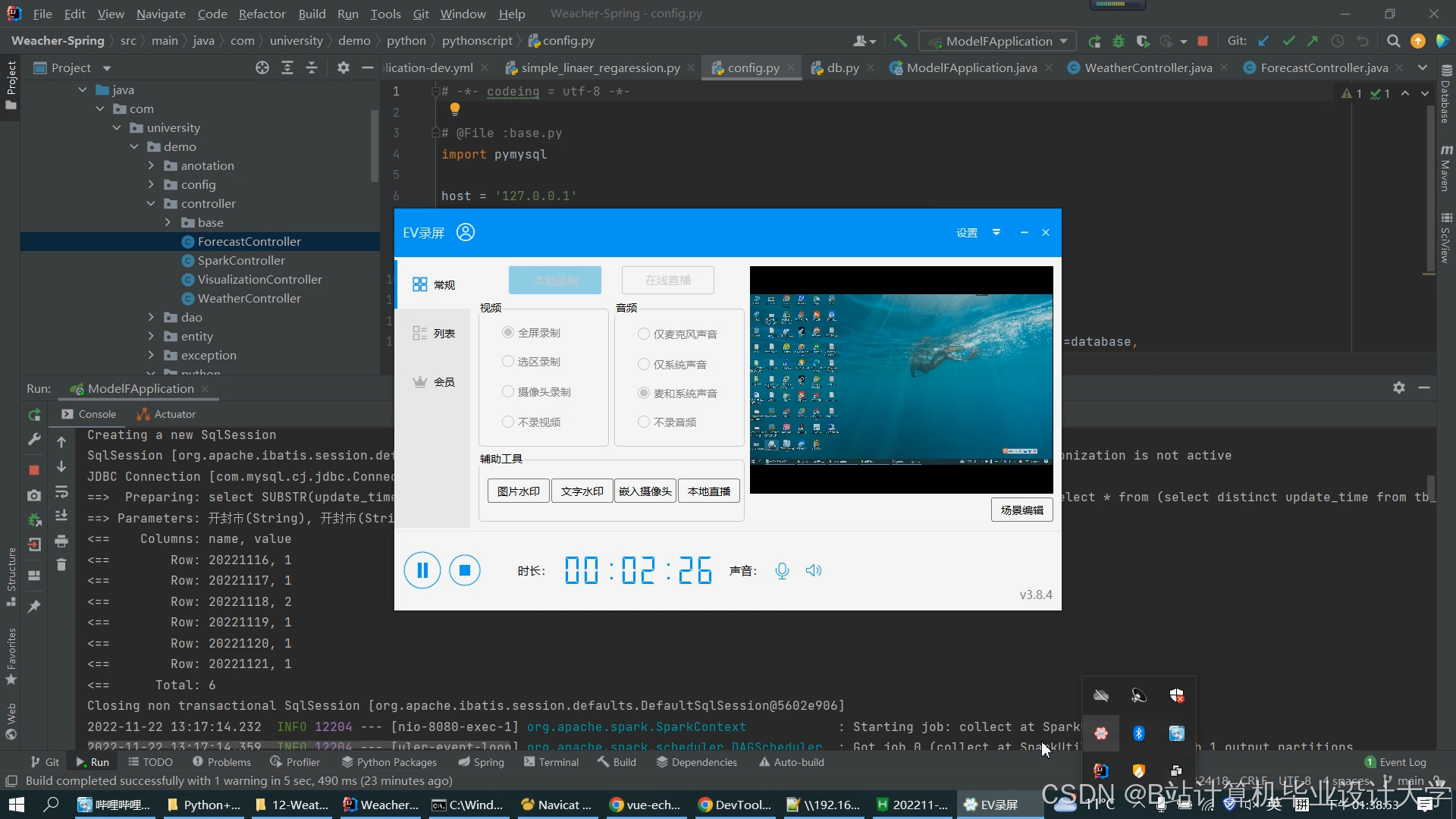
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 8
8 0
0- 0



 已为社区贡献494条内容
已为社区贡献494条内容

所有评论(0)