数据挖掘复习笔记第六章——分类
第六章 分类6.1 分类、回归与聚类分类和回归是两种数据分析形式,用于提取描述重要数据类或预测未来的数据趋势的模型。分类:预测类对象的分类标号(离散值)回归:建立连续函数值模型6.2 分类的应用案例6.3 分类概念分类过程测试集要独立于训练样本集,否则会出现“过分拟合”(overfitting)的情况6.4 常用的分类方法6.4.1 K-近邻给定一个未知样本,k-最近邻分类法搜索模式空间,找出最接
第六章 分类
6.1 分类、回归与聚类
- 分类和回归是两种数据分析形式,用于提取描述重要数据类或预测未来的数据趋势的模型。
- 分类:预测类对象的分类标号(离散值)
- 回归:建立连续函数值模型
6.2 分类的应用案例
6.3 分类概念
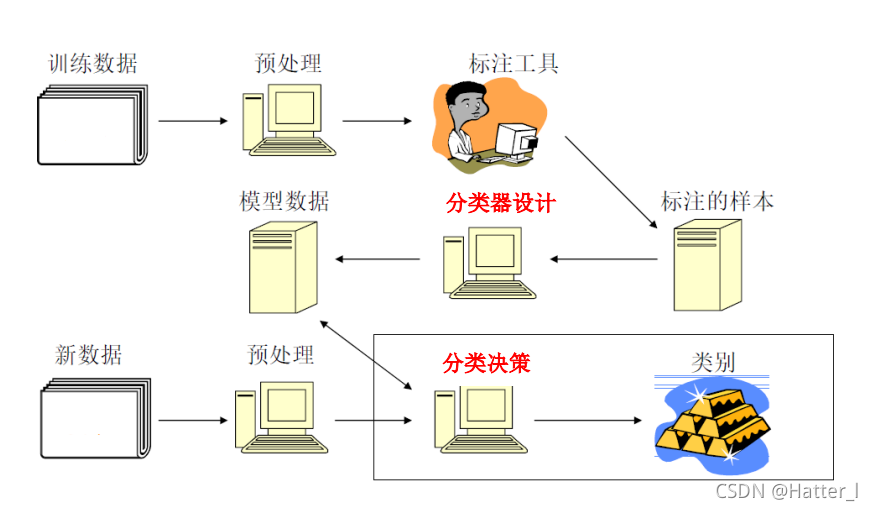
- 分类过程
- 测试集要独立于训练样本集,否则会出现“过分拟合”(overfitting)的情况
6.4 常用的分类方法
6.4.1 K-近邻
- 给定一个未知样本,k-最近邻分类法搜索模式空间,找出最接近未知样本的k个训练样本;然后使用k个最临近者中最公共的类来预测当前样本的类标号
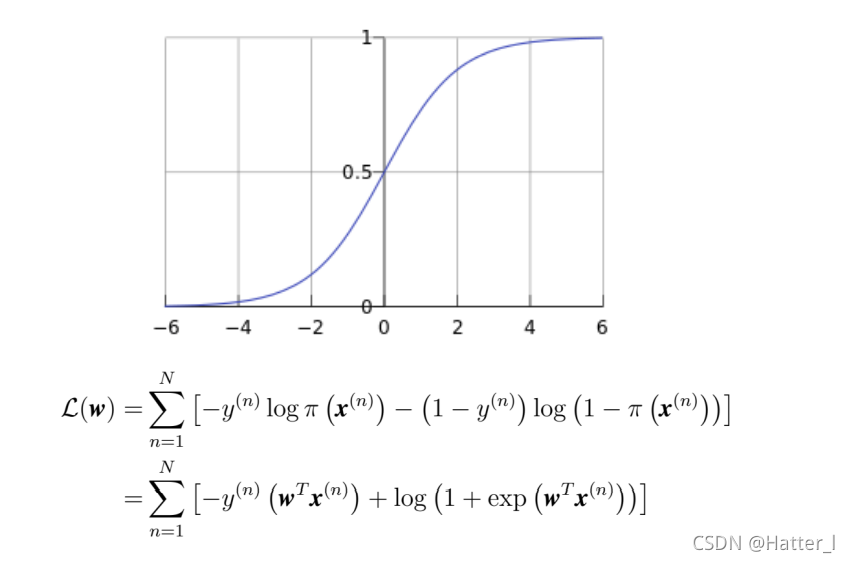
6.4.2 Logistic回归方法
6.4.3 支持向量机
- 其决策边界是对学习样本求解的最大边距超平面
6.4.4 神经网络
- 神经网络是一组连接的输入/输出单元,每个连接都与一个权相连。在学习阶段,通过调整神经网络的权,使得能够预测输入样本的正确标号来学习。
6.4.5 决策树
- 结点{属性} 边{属性值} 叶子结点{类别}
6.4.6 贝叶斯分类
- 朴素贝叶斯分类:假设每个属性之间都是相互独立的,并且每个属性对非类问题产生的影响都是一样的。
P(c∣x)=P(x∣c)P(c)P(x) P(c|x)=\frac{P(x|c)P(c)}{P(x)} P(c∣x)=P(x)P(x∣c)P(c)
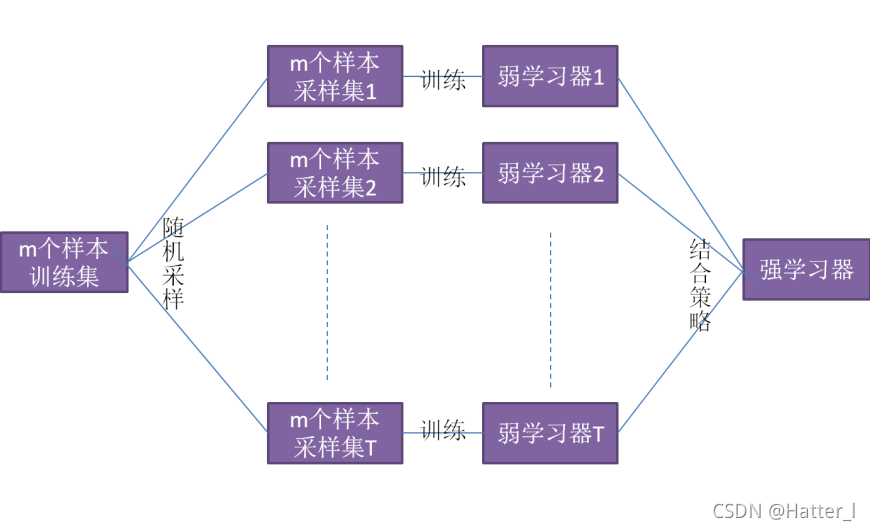
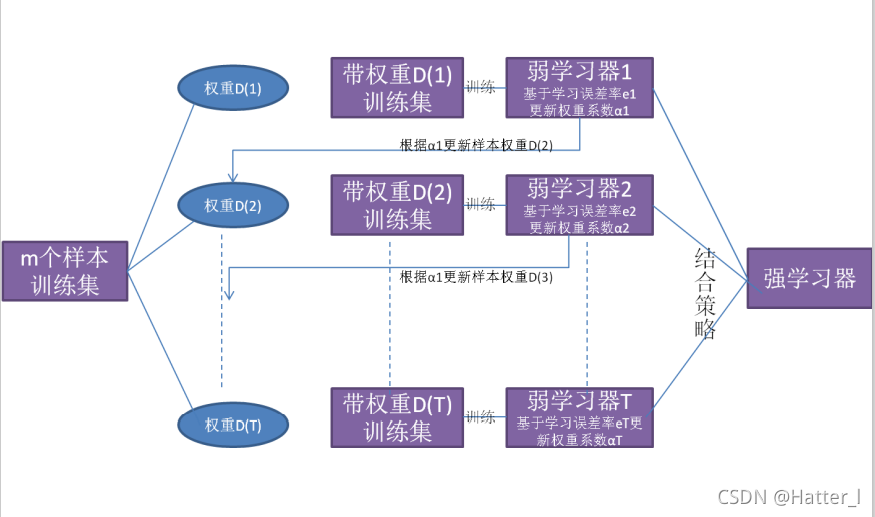
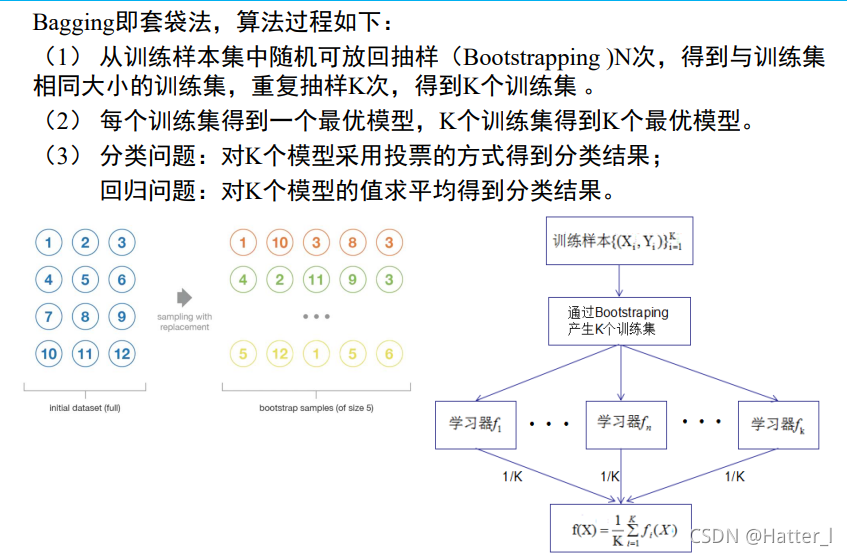
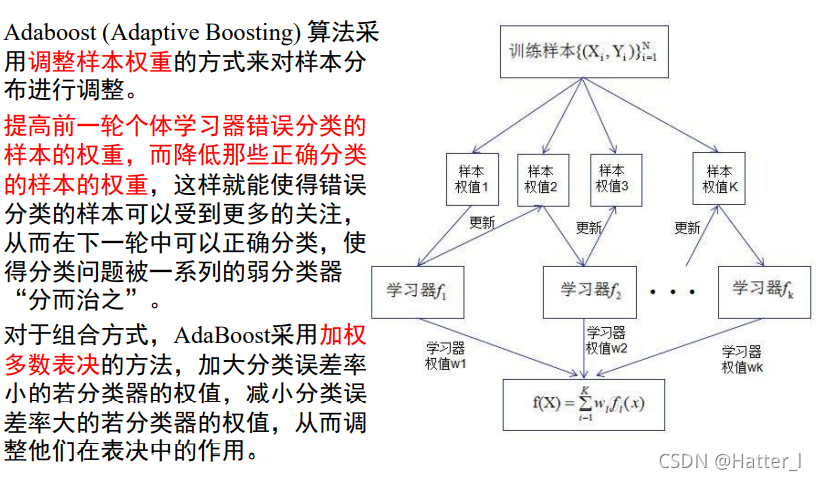
6.5 集成学习
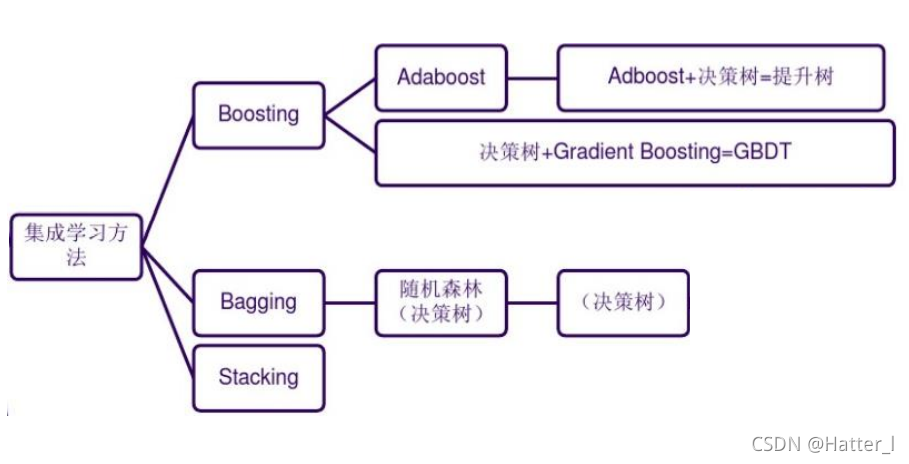
-
Bagging
-
Boosting
6.6 评估
6.6.1 分类的评价方法
- 训练测试法
- 把数据随机分成训练集和测试:训练集 (e.g., 2/3) 用于模型构建;测试 (e.g., 1/3) 用于评估准确率
- 交叉验证法
- 例如,十折交叉验证。即是将数据集分成十份,轮流将其中9份做训练1份做测试,10次的结果的均值作为对算法精度的估计。
6.6.2 分类的评价准则
-
准确度
-
速度
-
鲁棒性
-
可解释性
-
混淆矩阵
| A\PA\backslash PA\P | CCC | C‾\overline{C}C | TotalTotalTotal |
|---|---|---|---|
| CCC | TPTPTP | FNFNFN | PPP |
| C‾\overline{C}C | FPFPFP | TNTNTN | NNN |
| TotalTotalTotal | P′P'P′ | N′N'N′ | ALLALLALL |
-
准确率:
Accuracy=(TP+TN)ALL Accuracy=\frac{(TP+TN)}{ALL} Accuracy=ALL(TP+TN) -
错误率:
Error rate=(FP+FN)ALL Error\ rate=\frac{(FP+FN)}{ALL} Error rate=ALL(FP+FN) -
敏感度:
Sensitivity=TPP Sensitivity=\frac{TP}{P} Sensitivity=PTP -
特效性:
Specificity=TNN Specificity= \frac{TN}{N} Specificity=NTN -
精度:
precsion=TP(TP+FP) precsion=\frac{TP}{(TP+FP)} precsion=(TP+FP)TP -
召回率:
recall=TP(TP+FN) recall=\frac{TP}{(TP+FN)} recall=(TP+FN)TP -
F-measure:
𝐹−𝑚𝑒𝑎𝑠𝑢𝑟𝑒=2×𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛×𝑅𝑒𝑐𝑎𝑙𝑙𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑅𝑒𝑐𝑎𝑙𝑙 𝐹 − 𝑚𝑒𝑎𝑠𝑢𝑟𝑒 =\frac{2 × 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑅𝑒𝑐𝑎𝑙𝑙}{𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙} F−measure=Precision+Recall2×Precision×Recall
第六章完

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)