[论文笔记]使用GPU处理数据仓库查询之“阴”和“阳”
The Yin and Yang of Processing Data Warehousing Queries on GPU Devices研究背景在数据库领域,使用GPU进行查询加速已经被人们研究了好几年。但是在数据仓库领域,我们却很少发现有人研究GPU对数据仓库查询进行加速的课题。对数据仓库的查询往往伴随着巨大的计算开销,而GPU拥有强大的并行计算能力。如果能将使用GPU进行加速,会大大提升数
The Yin and Yang of Processing Data Warehousing Queries on GPU Devices
研究背景
在数据库领域,使用GPU进行查询加速已经被人们研究了好几年。但是在数据仓库领域,我们却很少发现有人研究GPU对数据仓库查询进行加速的课题。
对数据仓库的查询往往伴随着巨大的计算开销,而GPU拥有强大的并行计算能力。如果能将使用GPU进行加速,会大大提升数据仓库的OLAP速度,加快数据仓库OLAP技术的发展。
主要工作
作者从三个维度对“数据仓库+GPU”这个问题进行了研究,结合GPU实现了几个数据仓库的查询操作,分析了查询操作的计算开销,并在此基础上实现了一些优化。
作者将GPU的计算开销分为“阴”,“阳”两部分。“阴”表示主机内存与GPU内存之间数据传输开销(Transfer);“阳”表示GPU内核的执行开销(Kernel execution)。
研究框架
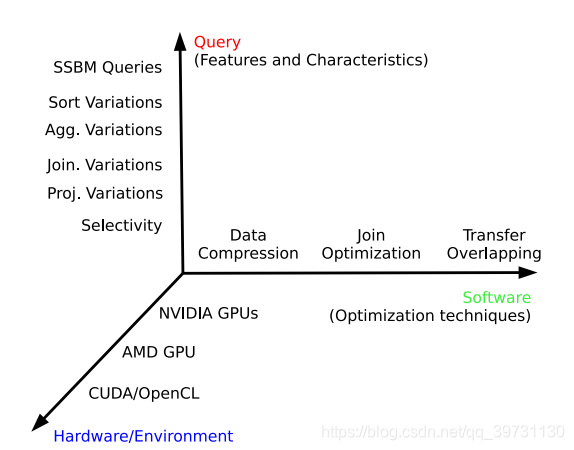
框架的三个维度分别为硬件/环境,查询操作以及优化技术。
- 查询操作:投影变化,连接变化,聚集变化,排序变化。
- 硬件/环境:NVIDIA架构的GPU,AMD架构的GPU,CUDA平台,OpenCL平台。
- 优化技术:数据压缩,传输覆盖,连接优化。
系统设计
查询结构
GPU数据仓库的查询结构如下所示。
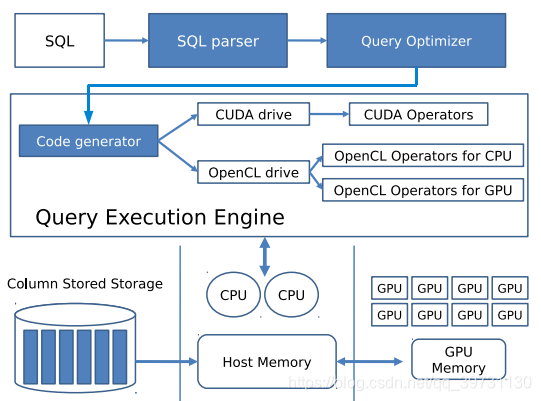
系统首先对用户输入的SQL语句进行语法分析以及语句优化,接着进入查询执行引擎,命令流传入Code generator模块,根据使用的GPU计算平台生成相应的CUDA语句或OpenCL语句。接着由CPU执行该语句,调用GPU完成查询计算任务。
数据存储
系统选择列存储技术(column-store),这种数据库存储模式更适合于数据仓库的批量数据处理。具体来说,每一张数据表存储为一组数据列的集合,每个数据列以若干分散文件的形式保存在磁盘中。除此之外,系统使用迟物化技术(late materialization),推迟元组的重组时间,以节省存储空间。
系统实现与基准实验
本章节初步地实现了GPU数据仓库系统,并进行了一些查询实验,作为性能衡量的基准参考。
查询操作
作者实现了几个常用的数据仓库查询操作,分别为选择,连接,聚集,排序。
- 选择:选择操作分为两步,首先连续扫描所有元组,判定每条元组是否满足给定的谓词条件,若满足则赋值1,不满足则赋值0,将所有赋值保存在一个0-1容器中。第二步使用该容器过滤值为0的元组并生成投影后的查询结果。
- 连接:作者使用哈希连接的方式进行连接操作,使用哈希函数进行关键字连接,可以大大减少关键字检索带来的开销。这里选取2倍于输入数据规模的内存空间作为哈希表,如此可以减小哈希冲突的可能。
- 聚集:聚集操作分为两步。首先连续扫描“group-by”的关键字并计算每一个关键字的哈希值。接着将哈希值相同的元组结合为一条元组并计算出对应的聚集函数值。
- 排序:对元组的关键字进行排序,接着根据将元组其余部分组合到关键字所在的位置。由于排序操作通常是在聚集操作后执行,待排序的元组数量往往很小,因此排序工作可以使用双调排序来完成。
硬件选择
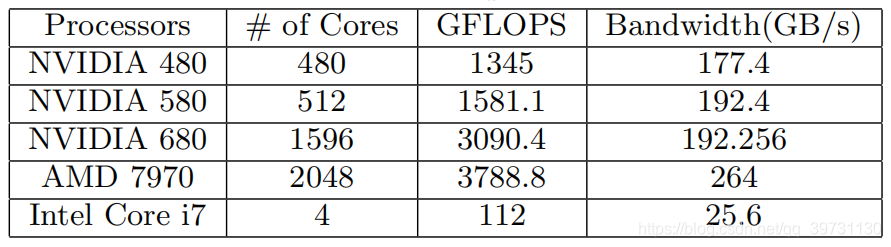
作者分别考虑了NVIDIA GTX 480,580,680和AMD HD 7970显卡,对它们进行了传输效率测试(“阴”)和内核执行速度测试(“阳”),最终选取NVIDIA GTX 680作为基准实验的GPU硬件。除此之外,实验选择了Intel Core i7 3770k作为CPU硬件。
各硬件的性能如下图所示。
 各GPU性能的测试结果如下所示。其中pinned内存是GPU可以直接访问的主存空间;pageable内存GPU无法直接访问,需要CPU进行控制。
各GPU性能的测试结果如下所示。其中pinned内存是GPU可以直接访问的主存空间;pageable内存GPU无法直接访问,需要CPU进行控制。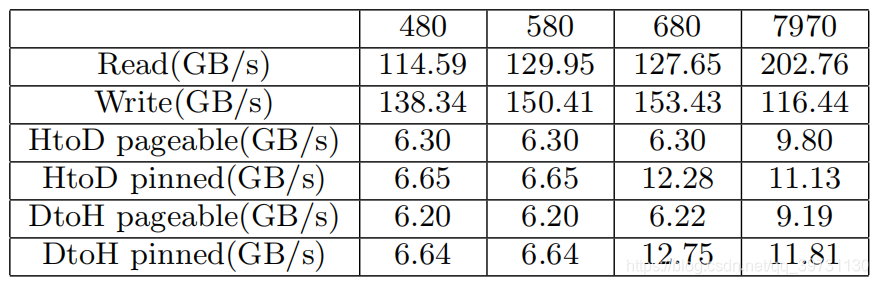
数据模型
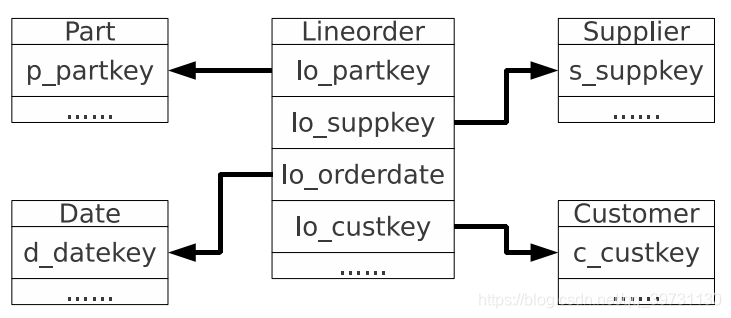
基准实验使用的是星型模型(SSBM),此模型的应用范围最广,因此具有代表性。该模型由1个事实表和4个维表组成,如图所示。事实表名字为Lineorder,4个维表分别叫做Date, Supplier, Customer和Part。该模型表示的是顾客购买商品的数据。
查询方案
基准实验的查询方案为13条,如下表所示。
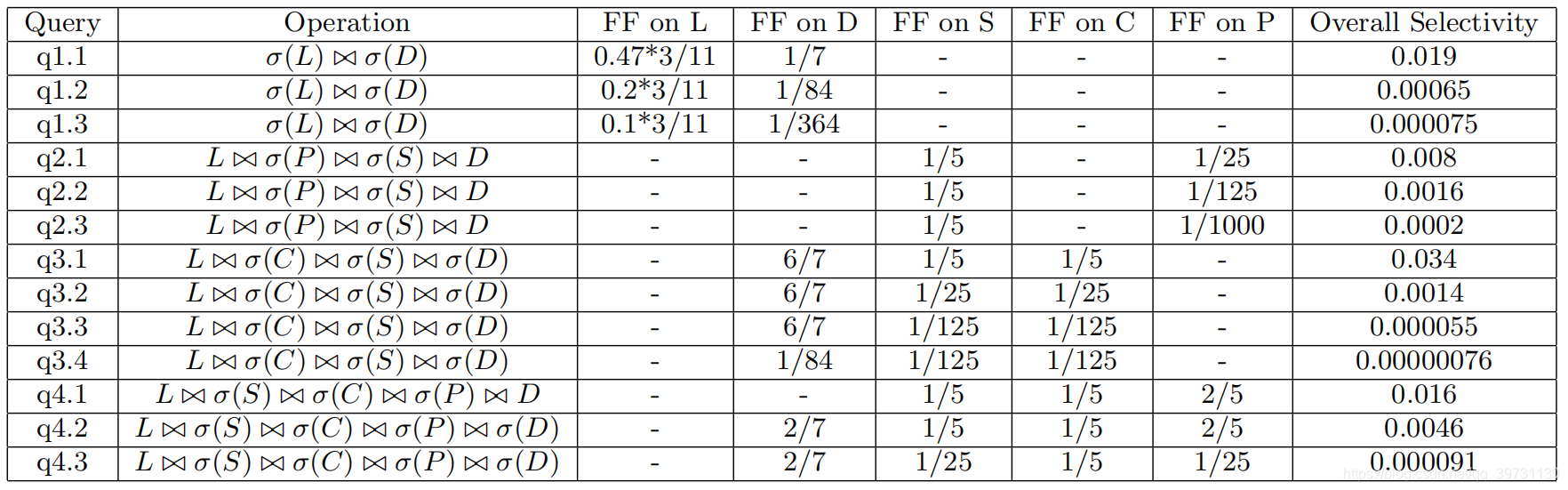
其中FF表示过滤因子,即表中有多少比例的元组被选中。L, D, S, C, P分别表示事实表Lineorder, 维表Date, Supplier, Customer, Part。从表中可以看到,13条查询方案分为4类,每类的查询操作相同,区别在于元组的选择率不同。
基准实验
基准实验的执行结果如下图所示。
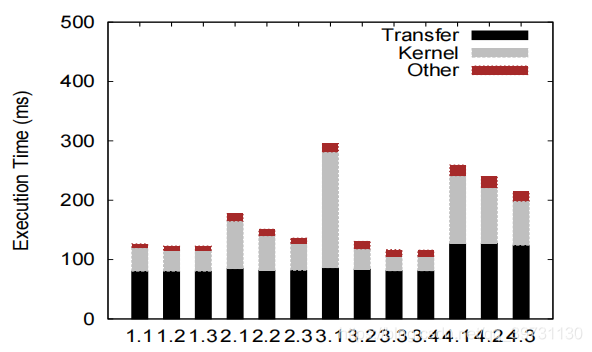
粗粒度地分析,作者将查询执行时间分为Transfer,Kernel和Other三部分,分别对对应“阴”,“阳”部分的执行时间以及CPU的执行时间。为了进一步对Kernel的执行时间进行分析,作者进一步地将进行细分,如下图所示。
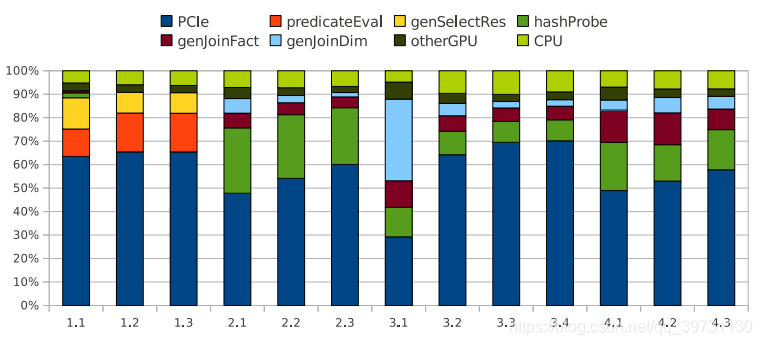
结果分析
我们分别对4类查询方案进行分析。
- Q1.1~Q1.3:该组查询方案的kernel执行开销主要用于选择操作,可以看到kernel执行时间大多在predicateEval部分,即谓词判定,以及生成选择操作后的查询结果(getSelectRes)。
- Q2.1~Q2.3:该组大部分的kernel执行开销用于哈希的冲突探测(hashProbe)操作,即用于连接操作并生成连接结果(genJoinFact和genJoinDim)。这三个查询方案的区别在于元组选择率不同,可以看到随着选择率下降,kernel的执行时间下降。
- Q3.1~Q3.4:该组查询方案可以分为Q3.1和Q3.2-Q3.4两部分。Q3.1的kernel执行时间远大于其余方案,这是因为该查询方案的元组选择率很高,所以执行开销主要来自于查询维表并生成连接结果(genJoinDim)。Q3.2-Q3.4的选择率较低,kernel开销于哈希冲突探测(hashProbe)和查询事实表并生成连接结果(getJoinFact)。
- Q4.1~Q4.3:该组方案的kernel开销于Q3.2-Q3.4接近,主要用于哈希冲突探测(hashProbe)和查询事实表并生成连接结果(getJoinFact)。方案之间的区别在于选择率不同。整体来看,选择率越低的方案,kernel执行开销越小。值得注意的是,该组方案的kernel执行时间比其他组整体高出一截,这是因为该组查询方案涉及到的数据量是最大的。
优化技术
基于基准实验结果,作者提出了三种优化方案,分别为数据压缩(data compression),传输覆盖(transfer overlapping)和隐式连接(invisible join)。
数据压缩
通过基准实验我们可以看到GPU执行开销有超过一半用于PCIe总线上的数据传输,即主机内存和GPU内存之间的数据交换。一个基本的优化思路是对传输的数据进行压缩,以减少需要传输的数据量。
作者使用了3种基于列存储模式的数据压缩技术:行程长度压缩(Run Length Encoding, RLE),位编码(Bit Encoding)和字典编码(Dictionary Encoding)。
RLE适用于事实表外键列的压缩,因为事实表的外键是有序的。对于有序的数据集合,可以使用RLE进行数据压缩。比如一组数据为:AAAABBBBBBCCCCCC,那么可以压缩为4A6B6C。
事实表的其它属性列可以使用位编码和字典编码进行压缩。
维表不需要进行压缩,因为维表的数据量比事实表的数据量小很多。
使用数据压缩技术后的查询实验结果如下。
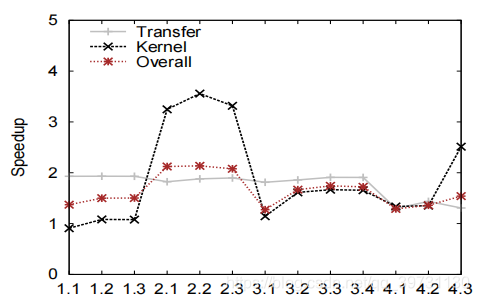
可以看到Transfer部分的效率提升了一倍左右。Kernel部分的提升效果在Q2.1~Q2.3最为显著,这是因为Q2.1-Q2.3的Kernel开销主要用于哈希冲突探测,使用数据压缩技术可以使哈希开销大幅降低。而一些操作,比如结果列投影,需要对数据进行解压,反而增加了Kernel开销。
传输覆盖
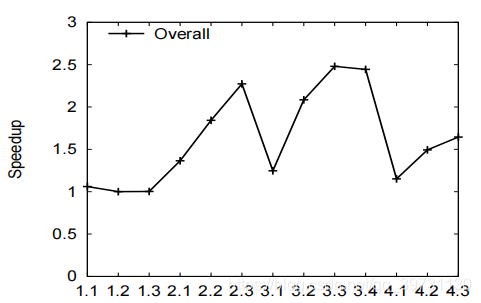
传输覆盖的思路是让Transfer与Kernel execution同时进行,即上一个任务在GPU进行计算时,下一个任务的数据通过PCIe传入GPU内存,类似于流水线。实现的前提是Transfer与Kernel execution时间尽可能相等,即“阴”,“阳”平衡。
使用传输覆盖技术后的查询实验结果如下。
隐式连接
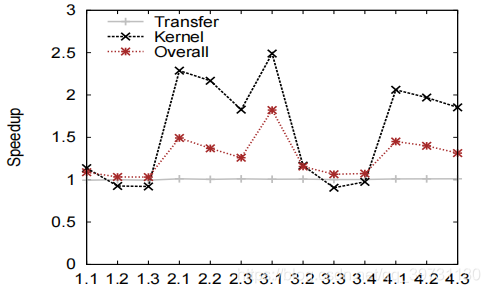
前两种优化方式都不适用于需要对维表随机访问的操作,如Q3.1。隐式连接则适合于优化此类查询操作。使用隐式连接,对维表的随机访问大幅度缩减。
使用隐式连接技术后的查询实验结果如下。
总结
作者从三个维度对GPU数据仓库进行研究。首先设计了GPU数据仓库的查询结构;接着实现了4个数据仓库的常用操作,即选择、连接、聚集和排序操作;然后使用13条查询方案进行了基准实验,分析影响执行时间的因素;最后采用了3种优化方式:数据压缩,传输覆盖和隐式连接,比较基准实验结果和优化后实验结果。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)