毕业设计:基于情感分析的个性化音乐推荐系统 大数据
毕业设计:基于情感分析的个性化音乐推荐系统旨在研究如何利用情感分析技术为用户提供个性化的音乐推荐服务。为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,这个课题提供了一个具有挑战性和创新性的研究方向。无论您对深度学习技术保持浓厚兴趣,还是希望探索机器学习、算法或人工智能领域的同学,这篇博文都能为您提供灵感和指导。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于情感分析的个性化音乐推荐系统
设计思路
一、课题背景与意义
在数字音乐时代,人们可以轻松访问大量的音乐资源。然而,由于音乐的多样性和个人口味的差异,用户在面对大量音乐选择时常常感到困惑。音乐推荐系统可以通过分析用户的情感状态和音乐的情感特征,为用户提供符合其情感需求的个性化音乐推荐,提升用户的音乐体验和满意度,同时也促进音乐产业的发展和数字音乐平台的用户黏性。
二、算法理论原理
2.1 知识图谱
知识图谱是一种以图形结构来组织和表示知识的技术。它是一种语义网络,用于存储、表示和推理关于世界的知识。知识图谱由实体(如人、地点、事件等)和它们之间的关系组成,以图的形式展现。知识图谱可以被视为一种语义数据库,其中的实体和关系具有丰富的语义信息。它不仅仅是一种数据结构,还包含了对实体和关系的语义理解和推理能力。知识图谱可以由人类专家手动构建,也可以通过自动化的方式从结构化和非结构化数据中提取出来。
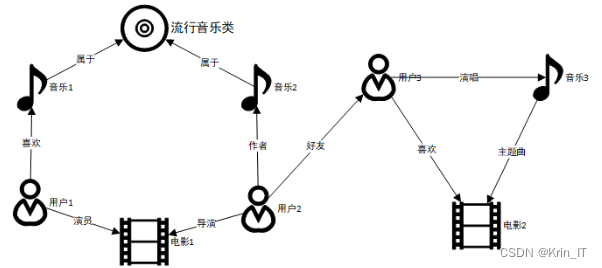
知识图谱以实体和边的形式表示现实世界中的知识,为推荐系统、搜索引擎、自然语言处理等领域提供丰富的语义信息和可解释性。知识图谱表示学习是将实体和关系映射到低维向量空间的技术,以更好地表示实体和关系之间的语义关系,为后续任务提供更好的数据基础。该学习过程包括确定实体和关系的表示方式、定义得分函数以评估三元组的合理性,以及学习实体和关系的表示以最大化知识图谱中的三元组得分。常见的知识图谱表示学习模型包括距离翻译模型、语义匹配模型、随机游走模型和子图汇聚模型。这些模型通过不同的方式提取和表示知识图谱中的语义信息,为进一步的计算和分析提供支持。
2.2 图神经网络
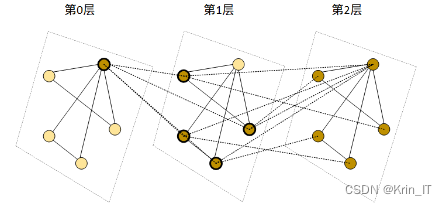
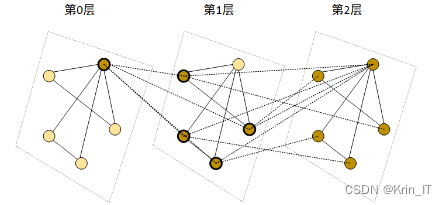
图神经网络(GNN)是一种基于图结构的深度学习方法,将神经网络的计算推广到图数据上。它结合了卷积网络、循环网络和自动编码器等神经网络结构,并被广泛应用于处理图数据。GNN通过全连接层、卷积层、池化层等组件构建,根据图数据的类型和复杂性以及所需的输出选择合适的层类型和数量。它接收格式化的图数据作为输入,并生成图嵌入,即用于表示节点及其关系的数值向量。图嵌入在机器学习中常用于将复杂信息转换为可学习的结构,类似于自然语言处理中的词嵌入。
在GNN中,每个节点的特征与其相邻节点的特征相结合,通过消息传递的方式进行信息交流。如果GNN由多个层组成,后续层会重复执行消息传递操作,从邻居的邻居收集数据并将其与前一层的值聚合。例如,在社交网络中,第一层将用户的数据与其朋友的数据结合,下一层将添加来自朋友的朋友的数据等。最终输出层会生成节点的嵌入向量,该向量表示节点数据以及节点对图中其他节点的知识。
2.3 情感分析
音乐情感分析是利用计算机技术对音乐进行特征提取和分析,将音乐映射到情感空间以识别音乐所表达情感的过程。一般包括域定义、特征提取和情感识别三个步骤。在域定义阶段,需要选择适当的数据集和情感模型。情感模型可以分为分类模型和维度模型。分类模型通过对音乐所表达情感的形容词进行分类,典型的分类模型是Hevner模型。维度模型将情感映射到多个维度,通过区分音乐在各个维度上的程度来表示情感,典型的维度模型是VA模型。
特征提取阶段可以从音乐的音频、歌词以及情感标签中提取特征。特征提取可以采用手工设计和选择的方法,也可以采用自动特征提取方法。手工特征提取需要专业领域知识和经验,并且耗费大量时间,但提取的特征具有可解释性。自动特征提取利用深度学习算法学习高度抽象和复杂的特征,不需要专业领域知识,但需要大量数据和计算资源。
情感识别阶段将提取到的特征输入到分类模型中进行情感分类。分类模型可以是传统机器学习模型或深度学习模型。传统机器学习模型使用KNN、SVM等传统分类器,具有较快的分类速度但准确度较低。深度学习模型可以采用CNN、RNN等模型进行端到端的学习和分类,随着训练集的增加,性能提高,且能够自动学习数据特征。与传统模型相比,深度学习模型通常具有更高的性能。
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,我决定进行网络爬取,收集了大量的音乐相关数据,并制作了一个全新的数据集。这个数据集包含了各种类型的音乐,以及与音乐相关的情感标签和用户评价等信息。通过网络爬取和数据整理,我能够获取真实的用户对音乐的情感反馈。为了确保数据集的质量和可用性,进行了数据标注工作。对音乐和用户评论进行情感标注,以便系统能够准确地理解和分析用户的情感状态。
3.2 实验及结果分析
在对比实验中,我们采用了评分预测任务中的AUC指标和推荐系统任务中的Top-K推荐评价指标中的Recall指标来对模型进行评估。
AUC是评估模型在二分类问题中的性能的常用指标。在评分预测任务中,我们可以将其应用于预测用户对音乐的喜好或评分。AUC衡量了模型对正负样本的区分能力,即模型预测正样本的概率高于负样本的概率的能力。较高的AUC值表示模型具有更好的分类能力和准确性。
推荐系统任务中的Top-K推荐评价指标主要关注模型在给定用户的历史行为后,能够准确地推荐出用户可能喜欢的前K个项目的能力。Recall指标衡量了模型在推荐列表中包含用户实际喜欢项目数量的能力。较高的Recall值表示模型能够更好地捕捉用户的兴趣和需求,提供个性化的推荐结果。
通过对比实验中的AUC和Recall指标,我们可以综合评估模型在评分预测和推荐任务中的性能。AUC指标关注模型对评分的准确性,而Recall指标关注模型对用户兴趣的捕捉能力。综合考虑这两个指标可以提供关于模型性能的更全面和准确的评估。
相关代码示例:
import nltk
from nltk.corpus import wordnet as wn
# 构建情感词典
emotion_lexicon = {
'happy': wn.synset('happy.a.01'),
'sad': wn.synset('sad.a.01'),
'angry': wn.synset('angry.a.01'),
'fearful': wn.synset('fearful.a.01'),
'disgusted': wn.synset('disgusted.a.01')
}
# 情感标签映射
label_mapping = {
'positive': ['happy'],
'negative': ['sad', 'angry', 'fearful', 'disgusted']
}
def analyze_emotion(text):
tokens = nltk.word_tokenize(text.lower())
emotion_scores = {'positive': 0, 'negative': 0}
for token in tokens:
synsets = wn.synsets(token)
for synset in synsets:
for label, emotions in label_mapping.items():
if any(synset == emotion_lexicon[emotion] for emotion in emotions):
emotion_scores[label] += 1
total_score = sum(emotion_scores.values())
if total_score == 0:
return {'positive': 0, 'negative': 0}
emotion_distribution = {label: score / total_score for label, score in emotion_scores.items()}
return emotion_distribution
# 示例用法
text = "I feel so happy and excited about the news!"
result = analyze_emotion(text)
print(result)实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 19
19 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)