【博学谷学习记录】超强总结,用心分享|狂野大数据课程 【Hive函数】
【代码】【博学谷学习记录】超强总结,用心分享|狂野大数据课程 【Hive函数】
·
Hive的内置函数
数学函数
-- 四舍五入
select round(3.555);
-- 指定位数四舍五入
select round(3.555,2);
-- 向下取整
select floor(3.9);
-- 向上取整
select ceil(3.1);
-- 取随机数
select floor((rand() * 100) + 1); -- 1到100之间的随机数
-- 绝对值
select abs(-12);
-- 几次方运算
select pow(2,4);
字符串函数
-- URL路径解析
select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'HOST'); -- www.baidu.com
select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'PATH'); -- /info/s
select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY');-- /info/s
select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY'); -- word=bigdata&tn=25017023_2_pg
select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY','word'); -- bigdata
select parse_url('https://www.baidu.com/info/s?word=bigdata&tn=25017023_2_pg', 'QUERY','tn'); -- 25017023_2_pg
-- json数据解析
select get_json_object('{"name": "zhangsan","age": 18, "preference": "music"}', '$.name');
select get_json_object('{"name": "zhangsan","age": 18, "preference": "music"}', '$.age');
select get_json_object('{"name": {"aaa":"bbb"}}', '$.name.aaa');
-- 字符串拼接
select concat(rand(),'-',sid) as sid, sname from student;
select concat(rand(),'-',sid) as sid, sname from student;
-- 字符串拼接,带分隔符
select concat_ws('-','2022','10','15');
select log10(100)
-- 字符串截取
select substr('2022-12-23 10:13:45',1,4); -- 2022 从1开始,不是从0
select substr('2022-12-23 10:13:45',6,6); -- 12
select substr('abcde',-3);
select substring('abcde',-3);
select upper('abcDE')
select lower('abcDE')
-- 字符串替换
select regexp_replace('foobar', 'oo|ar', '');
select ltrim(' xxxxxxxx');
-- 字符串切割
select split('2022-12-23','-');
日期函数
select unix_timestamp(); -- 离1970年1月1日秒值,晚了8个小时
select `current_date`(); -- 获取当前的年月日
select `current_timestamp`(); -- 获取当前的年月日,时分秒
select from_unixtime(1677584757, 'yyyy-MM-dd HH:mm:ss');
select from_unixtime(unix_timestamp() + 8 * 3600, 'yyyy-MM-dd HH:mm:ss');
select unix_timestamp('20111207 13:01:03', 'yyyyMMdd HH:mm:ss');
select unix_timestamp('2022年12月23日 11点22分36秒', 'yyyy年MM月dd日 HH点mm分ss秒');
select from_unixtime(unix_timestamp('2022年12月23日 11点22分36秒', 'yyyy年MM月dd日 HH点mm分ss秒'),
'yyyy-MM-dd HH:mm:ss');
select date_format('2022-1-1 3:5:6', 'yyyy-MM-dd HH:mm:ss'); -- 日期格式转换
select to_date('2011-12-08 10:03:01'); -- 获取年月日
select year('2011-12-08 10:03:01') + 10;
select substring('2011-12-08 10:03:01', 1, 4) + 10;
select hour('2011-12-08 10:03:01');
select `dayofweek`('2023-02-28') - 1; -- 默认周日是第一天
select weekofyear('2023-02-28'); -- 获取今年的第几周
select quarter('2023-02-28'); -- 获取季度
select datediff('2023-02-28', '2008-08-08'); -- 日期的差值
select abs(datediff('2008-08-08', '2023-02-28'));
select date_add('2023-02-28', 100); -- 日期向后推移
select date_add('2023-02-28', -100); -- 日期向前推移
select date_sub('2023-02-28', 100);
条件判断函数
-- ------------------if语句----------------------------
select if(TRUE, 100, 200);
select if(FALSE, 100, 200);
select *,
if(sscore >= 60, '及格', '不及格') as flag
from score;
-- ------------------case语句----------------------------
/*
口径不统一:
A表:性别: m f
B表:性别:男,女
*/
select *,
case sex
when 'm' then '男'
when 'f' then '女'
end as gender
from test3;
select *,
case
when sscore >= 90 then '优秀'
when sscore >= 80 then '良好'
when sscore >= 60 then '及格'
when sscore < 60 then '不及格'
else '其他' end
from score;
select *,
case
when salary >= 100000 then '高薪'
where salary >= 5000 then '工薪'
when sscore < 3000 then '屌丝'
else '其他' end
from score;
类型强转函数
链接: [link](https://www.csdn.net/).
图片: 
带尺寸的图片: 
居中的图片: 
居中并且带尺寸的图片: 
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
-- 类型转换函数
select cast(12.95 as int);
select cast('20190607' as int);
select cast('2020-12-05' as date);
select cast(123 as string);
行转列和列转行函数
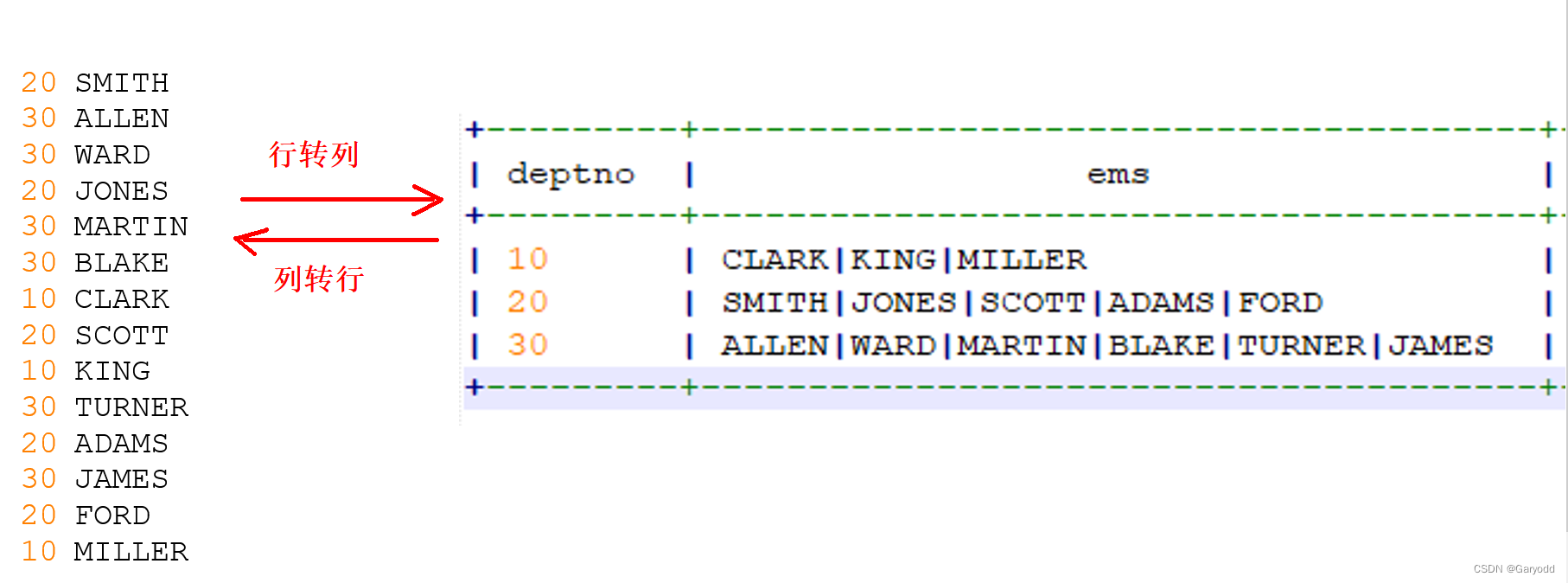
行转列和列转行函数
/*
20 SMITH
30 ALLEN
30 WARD
20 JONES
30 MARTIN
30 BLAKE
10 CLARK
20 SCOTT
10 KING
30 TURNER
20 ADAMS
30 JAMES
20 FORD
10 MILLER
*/
-- 1、建表
create table emp(
deptno int,
ename string
) row format delimited fields terminated by '\t';
-- 2、加载数据
load data local inpath '/root/test/test1.txt' into table emp;
-- 3、实现
select * from emp;
set hive.stats.column.autogather=false;
set hive.exec.mode.local.auto=true; --开启本地mr
-- collect_list可以将每一组的ename存入数组,不去重
select deptno,collect_list(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重
select deptno,collect_set(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重,concat_ws将数组中的每一个元素进行拼接
select deptno,concat_ws('|',collect_set(ename)) as enames from emp group by deptno;
列转行
-- 1、建表
create table emp2(
deptno int,
names array<string>
)
row format delimited fields terminated by '\t'
collection items terminated by '|';
-- 2、加载数据
load data local inpath '/root/test/test2.txt' into table emp2;
select * from emp2;
-- 3、SQL实现
select explode(names) from emp2; -- 此方法行不通
-- 将原来的表emp2和炸开之后的表进行内部的关联,判断炸开的每一行都来自哪个数组
select * from emp2 lateral view explode(names) t as name;
-- t是explode生成的函数的别名,name是explode列的别名
select deptno, name from emp2 lateral view explode(names) t as name
Hive的窗口函数
分组排序函数
/*
user1,2018-04-11,5
user2,2018-04-12,5
user2,2018-04-12,5
user1,2018-04-11,5
user2,2018-04-13,6
user2,2018-04-11,3
user2,2018-04-12,5
user1,2018-04-10,1
user2,2018-04-11,3
user1,2018-04-12,7
user2,2018-04-12,5
user1,2018-04-13,3
user2,2018-04-13,6
user1,2018-04-14,2
user1,2018-04-15,4
user1,2018-04-16,4
user2,2018-04-10,2
user2,2018-04-14,3
user1,2018-04-11,5
user2,2018-04-15,9
user2,2018-04-16,7
*/
-- 1、建表
CREATE TABLE test_window_func1(
userid string,
createtime string, --day
pv INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- 2、加载数据:
load data local inpath '/root/test/test3.txt' overwrite into table test_window_func1;
select * from test_window_func1;
-- 3、需求:按照用户进行分组,并且在每一组内部按照pv进行降序排序
-- row_number,rank,dense_rank
/*
partition by userid 按照哪个字段分组,等价于group by
order by pv desc 组内按照哪个字段排序
*/
select
*,
row_number() over (partition by userid order by pv desc) as rk_row_number, -- 1 2 3 4 5
rank() over (partition by userid order by pv desc) as rk_rank, -- 1 2 3 3 5
dense_rank() over (partition by userid order by pv desc) as rk_dense_rank -- 1 2 3 3 4
from test_window_func1;
-- 如果没有分组partition by 的情况
-- 将整整表看做是一组
select
*,
dense_rank() over (order by pv desc) as rk_dense_rank
from test_window_func1;
-- 如果没有分组order by 的情况
select
*,
row_number() over (partition by userid ) as rk_row_number, -- 1 2 3 4 5
rank() over (partition by userid ) as rk_rank, -- 1 1 1 1 1
dense_rank() over (partition by userid ) as rk_dense_rank -- 1 1 1 1 1
from test_window_func1;
-- 需求:求每一组的PV最多的前3个:每组的Top3
-- 方式1
select * from (
select
*,
dense_rank() over (partition by userid order by pv desc) as rk
from test_window_func1
) t
where rk <= 3;
-- 方式2
with t as (
select
*,
dense_rank() over (partition by userid order by pv desc) as rk
from test_window_func1
)
select * from t where rk <= 3;
聚合开窗函数
-- ----------------聚合开窗---------------
-- 默认是从开头累加到当前行
select userid,createtime,pv,
sum(pv) over(partition by userid order by createtime ) as pv1
from test_window_func1;
-- 作用同上
select userid,createtime,pv,
sum(pv) over(partition by userid order by createtime
rows between unbounded preceding and current row ) as pv1
from test_window_func1;
-- 指定从上一行加到当前行
select userid,createtime,pv,sum(pv) over(partition by userid order by createtime
rows between 1 preceding and current row ) as pv1
from test_window_func1;
-- 指定从上一行加到下一行
select userid,createtime,pv,sum(pv) over(partition by userid order by createtime
rows between 1 preceding and 1 following ) as pv1
from test_window_func1;
-- max
select userid,createtime,pv,
max(pv) over(partition by userid order by createtime ) as pv1
from test_window_func1;
-- min
select userid,createtime,pv,
min(pv) over(partition by userid order by createtime ) as pv1
from test_window_func1;
lag和lead函数
-- lag 和lead函数
-- 将pv列的上一行数据放在当前行
select *,
lag(pv,1,0) over(partition by userid order by createtime)
from test_window_func1;
-- 将pv列的下一行数据放在当前行
select *,
lead(pv,1,0) over(partition by userid order by createtime)
from test_window_func1;
-- ------------------模拟漏斗模型-----------------------------
/*
stage1 1000
stage2 800
stage3 50
stage4 2
*/
-- 1、创建表
create table demo( stage string, num int)
row format delimited fields terminated by '\t'
;
-- 2、加载数据
load data local inpath '/root/test/test4.txt' into table demo;
select * from demo;
-- 3、代码实现
with t as (
select *,
lag(num,1,-1) over (order by stage) as pre_num
from demo
)
select *, concat(floor((num / pre_num)*100),'%') as rate from t where stage > 'stage1';

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)