大数据学习
大数据学习笔记
了解大数据
以前的开发场景是,分析用户需求和业务场景,进行软件设计和开发。
通过大数据能够发掘出用户自己都没有发现的需求,因为用户可能自己都不了解的自己,通过大数据来主动提供建议和选项。
2013年大数据公司开始涌现,被称为“大数据元年”。
大数据的应用领域包括医疗(医学影像识别)、教育(智能解题)、社交(舆情分析)、金融(风控)、新零售(无人超市)等等,未来基于大数据和机器学习可以给人们的生活提供无限可能。
大数据发展和主流技术
大数据技术起源于Google 2004年发表的论文,俗称“三驾马车”(分布式文件系统 GFS、大数据分布式计算框架MapReduce 和 NoSQL 数据库系统 BigTable)
Hadoop 包括分布式文件系统 HDFS 和计算引擎 MapReduce。
Hive 支持使用 SQL 语法来进行大数据计算,比如说你可以写个 Select 语句进行数据查询,然后 Hive 会把 SQL 语句转化成 MapReduce 的计算程序。
Yarn 将 MapReduce 执行引擎和资源调度分离开来,是主流的资源调度系统。
MapReduce、Spark 这类计算框架处理的业务场景都被称作批处理计算。因为计算的数据是非在线得到的实时数据,而是历史数据,所以这类计算也被称为大数据离线计算。
Storm、Flink、Spark Streaming 等大数据流计算框架来满足此类大数据应用的场景。
流式计算要处理的数据是实时在线产生的数据,所以这类计算也被称为大数据实时计算。
Flink 可以同时支持流式计算(实时计算)和批处理计算(离线计算)。
NoSQL 系统处理大规模海量数据的存储与访问,主要有HBase(基于HDFS的)、Cassandra 等
大数据处理的主要应用场景包括数据分析、数据挖掘与机器学习。
数据分析主要使用 Hive、Spark SQL 等 SQL引擎完成;
数据挖掘与机器学习则有专门的机器学习框架 TensorFlow、Mahout 以及MLlib 等,内置了主要的机器学习和数据挖掘算法。
数据存储到分布式文件系统(HDFS)
大数据体系架构分布如下:
移动计算
想象一下在一台服务器上如何读取PB级的数据?受限于CPU速度、网络带宽(百兆/千兆)、内存、磁盘IO等硬件设施,传统的计算处理模型根本不可能满足这种计算需求。
大数据计算处理通常是针对存量数据进行统计分析,将程序分发到数据所在的地方进行计算,就是移动计算。
移动计算是如何实现的呢?
- 将待处理的大规模数据存储在服务器集群的所有服务器上,主要使用 HDFS 分布式文件存储系统,将文件分成很多块(Block),以块为单位存储在集群的服务器上。
- 大数据引擎根据集群里不同服务器的计算能力,在每台服务器上启动若干分布式任务执行进程,这些进程会等待给它们分配执行任务。
- 使用大数据计算框架支持的编程模型进行编程,比如 Hadoop 的 MapReduce 编程模型,或者 Spark 的 RDD 编程模型。应用程序编写好以后,将其打包,MapReduce 和Spark 都是在 JVM 环境中运行,所以打包出来的是一个 Java 的 JAR 包。
- 用 Hadoop 或者 Spark 的启动命令执行这个应用程序的 JAR 包,首先执行引擎会解析程序要处理的数据输入路径,根据输入数据量的大小,将数据分成若干片(Split),每一个数据片都分配给一个任务执行进程去处理。
- 任务执行进程收到分配的任务后,检查自己是否有任务对应的程序包,如果没有就去下载程序包,下载以后通过反射的方式加载程序。走到这里,最重要的一步,也就是移动计算就完成了。
- 加载程序后,任务执行进程根据分配的数据片的文件地址和数据在文件内的偏移量读取数据,并把数据输入给应用程序相应的方法去执行,从而实现在分布式服务器集群中移动计算程序,对大规模数据进行并行处理的计算目标。
Hadoop
Hadoop是开源的大数据处理平台,主要包括HDFS(分布式文件系统)、YARN(分布式资源调度)、MapReduce(分布式离线计算)
HDFS架构
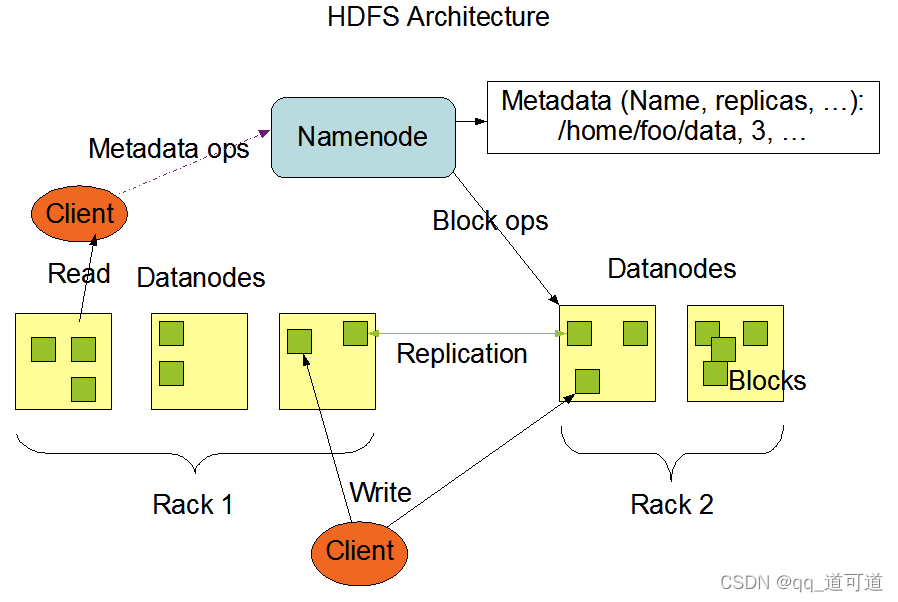
Block(数据块)
- Hadoop2以后默认128M/block。
- 大文件按照一定block大小进行分割,存储不同主机,若文件小于Block大小,则实际占用其文件大小。
- 配置大块原因(减少搜寻时间、减少管理块的数据开销,每个块都需要在NameNode上有对应记录、减少网络连接成本。)
- 通过偏移量查找数据,因此不用担心句子分割到不同block的情况。
- 副本可靠性,默认3个(默认不同主机、就近存放),老数据可适量减少副本节省成本。
NameNode(元数据记录)
管理文件与Block和DataNode的关系
运行时所有数据都保存在内存中
节点数据定时保存到磁盘中
secondaryNameNode(定时同步NameNode日志)
DataNode(block数据存储、数据读写与复制)
Hadoop单机版安装部署(2.10.1)
基础环境
主机:10.18.255.76
软件目录:/data/big_data/
# 安装
wget -b -c https://dlcdn.apache.org/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz --no-check-certificate
# 安装jdk
略
# 配置免密登录
ssh-keygen -t rsa
将/root/.ssh/id_rsa.pub内容追加到 /root/.ssh/authorized_keys 中
配置
JAVA_HOME配置
etc/hadoop/hadoop-env.sh(我这里是yum安装的)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64
hosts配置:/etc/hosts
10.18.255.76 hadoop1
公共配置etc/hadoop/core-site.xml
<configuration>
<!-- Hadoop工作目录,用于存放Hadoop运行时产生的临时数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop1/data</value>
</property>
<!-- NameNode的通信地址,1.x默认9000,2.x可以使用8020 -->
<property>
<name>fs.default.name</name>
<value>hdfs://10.18.255.76:8020</value>
</property>
</configuration>
hdfs配置etc/hadoop/hdfs-site.xml
<configuration>
<!--指定block的备份数量(将block复制到集群中备份数-1个DataNode节点中)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭HDFS的访问权限 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
yarn配置:etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 配置Reduce取数据的方式是shuffle(随机) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
MapReduce配置:mapred-site.xml
<configuration>
<!-- 让MapReduce任务使用YARN进行调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
格式化namenode
bin/hdfs namenode -format
启动hdfs
sbin/start-dfs.sh
检查进程,有NameNode,DataNode,SecondaryNameNode
# jps
1183633 DataNode
1183237 NameNode
1184047 SecondaryNameNode
访问hdfs管理页面
http://10.18.255.76:50070/dfshealth.html#tab-overview
启动yarn
sbin/start-yarn.sh
jps检查,多了ResourceManager与NodeManager
# jps
1230850 ResourceManager
1183633 DataNode
1183237 NameNode
1184047 SecondaryNameNode
1231071 NodeManager
执行mapreduce任务示例
示例目录/data/big_data/hadoop-2.10.1/share/hadoop/mapreduce下默认自带了很多计算方法,可以用bin/hadoop jar xxx.jar调用,如下
hadoop-mapreduce-examples-2.10.1.jar 就提供了wordcount词频统计功能,将示例文件上传到hdfs(上文中的web页面/下文中的命令行/程序上传)
cat words.txt
A
B
C
D
E
F
A
B
C
D
执行统计,对/words文件计算,将结果放到/result
./bin/hadoop jar /data/big_data/hadoop-2.10.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /words /result
查看yarn管理界面查看任务:http://10.18.255.76:8088/cluster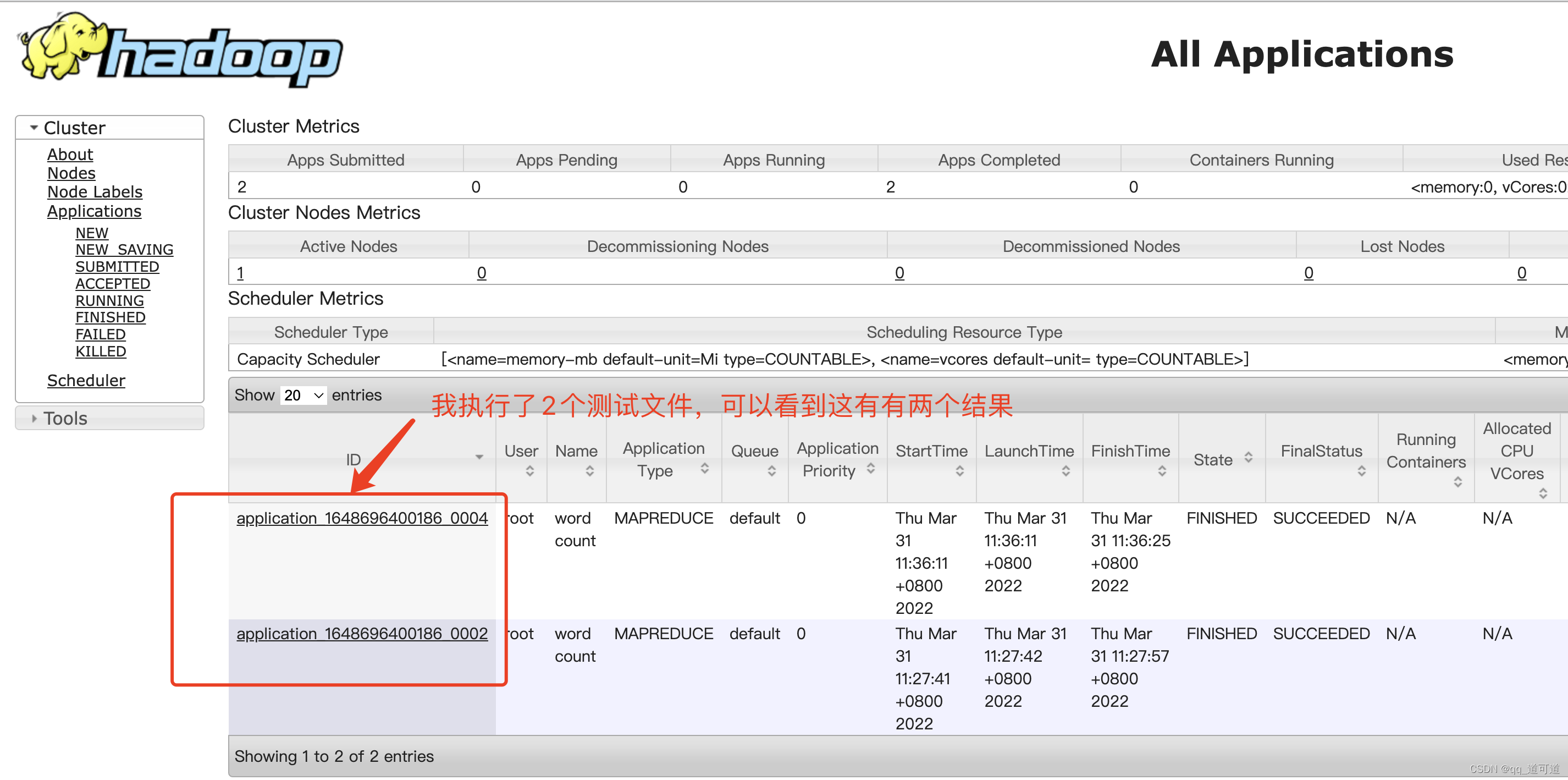 查看hdfs管理页面,查看文件及执行结果http://10.18.255.76:50070/explorer.html#/
查看hdfs管理页面,查看文件及执行结果http://10.18.255.76:50070/explorer.html#/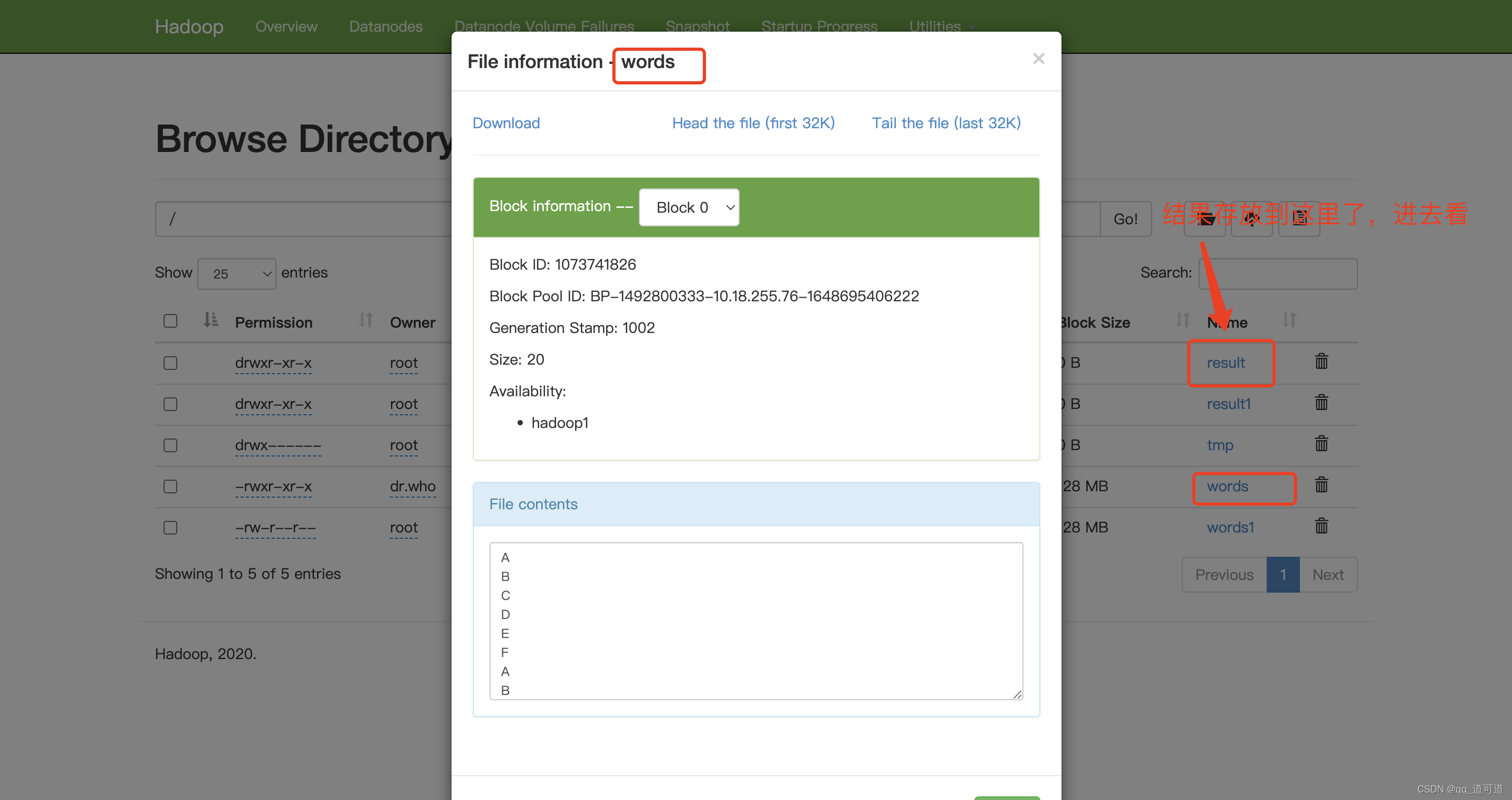
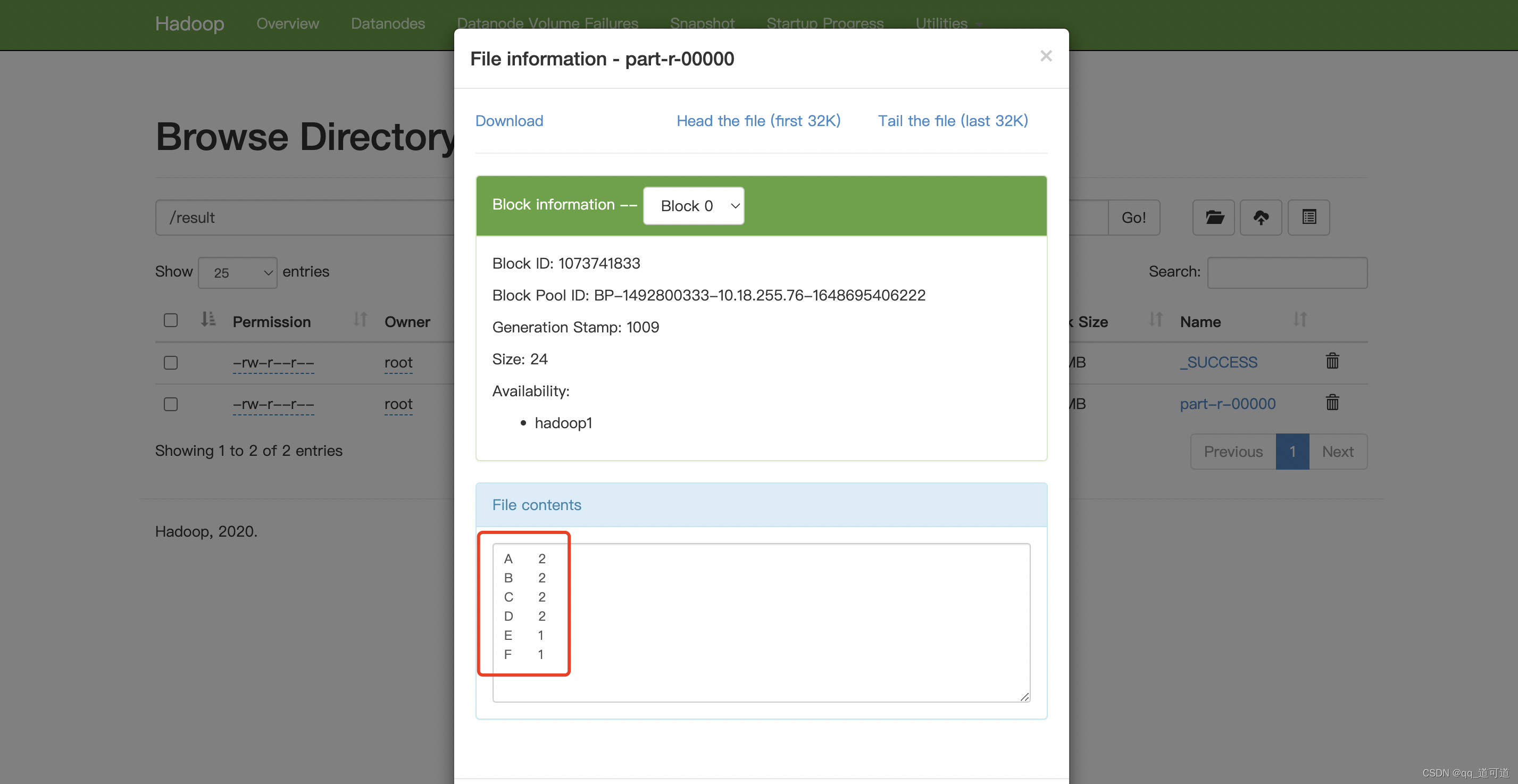
附:shell操作hadoop
#查询指定路径下文件的个数
bin/hadoop fs -count <path>
#显示指定目录下的内容
bin/hadoop fs -ls <path>
#显示文件中的内容
bin/hadoop fs -cat <src>
#将本地中的文件上传到HDFS
bin/hadoop fs -put <localsrc> <dst>
#将HDFS中的文件下载到本地
bin/hadoop fs -get <src> <localdst>
#将本地中的文件剪切到HDFS中
bin/hadoop fs -moveFromLocal <localsrc> <dst>
#将HDFS中的文件剪切到本地中
bin/hadoop fs -moveToLocal <src> <localdst>
#在HDFS内对文件进行移动
bin/hadoop fs -mv <src> <dst>
#在HDFS内对文件进行复制
bin/hadoop fs -cp <src> <dst>
#删除HDFS中的文件
bin/hadoop fs -rm <src>
#创建目录
bin/hadoop fs -mkdir <path>
HDFS HA架构
参考
https://hadoop.apache.org/docs/r2.10.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
https://www.cnblogs.com/funyoung/p/9947105.html
HBase
参考
https://www.cnblogs.com/funyoung/p/10194432.html
Hadoop Database是一个高可靠、高性能、面向列、可伸缩、实时读写的分布式数据库。利用HDFS存储数据,利用MapReduce处理海量数据。
hbase系统架构
HMaster主服务器:负责监控所有RegionServer,元数据修改接口。通常运行在NameNode上,主要负责Region和表的管理。通过zk保证多个HMaster只有1个处于active状态,其余都是备份。
RegionServer:主要负责响应用户的请求,向 HDFS 读写数据。通常运行在Datanode上。管理Region对象,每个 Region 由多个 HStore 组成,每个 HStore 对应表中一个列族的存储。
Region:数据分片,不同Region之间数据不同。
客户端:使用 HBase 的 RPC 机制与 HMaster 和 RegionServer 进行通信。(在一般情况下,客户端与 HMaster 进行管理类操作的通信,在获取 RegionServer 的信息后,直接与 RegionServer 进行数据读写类操作。而且客户端获取 Region 的位置信息后会缓存下来,用来加速后续数据的访问过程。)
Hbase本身不提供数据副本和数据复制能力,采用HDFS作为底层存储并依赖其负责高可用性。底层存储也可以用s3
Hbase和RDBMS对比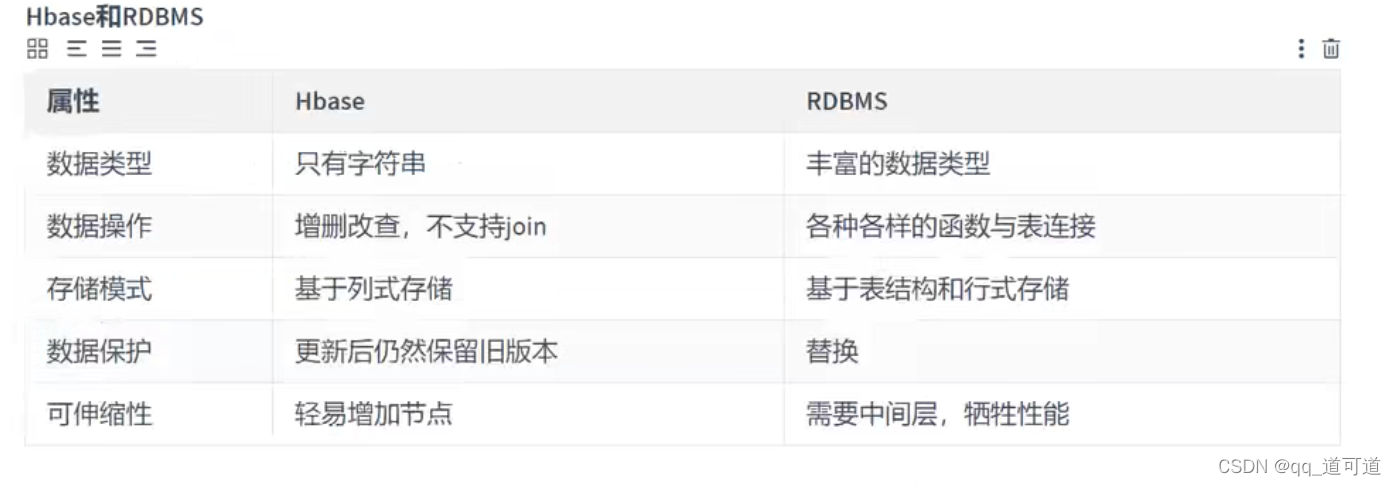
基本概念
Namespace
default:没有指定的自动落入此空间
hbase:系统默认空间,包含hbase内部表
Rowkey
记录的唯一标识,相当于关系型数据库中的主键。
RowKey的最大长度为64KB且按字典顺序进行排序存储。
HBase会自动为RowKey加上索引,当按RowKey查询时速度会很快。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)