大数据实战:Ambari开发手册之OpenTSDB快速集成技巧
用于描述这个服务,服务的组件和管理脚本用于执行命令。一个组件的服务可以是MASTER,SLAVE或CLIENT类别。这个<category>告诉Ambari默认命令应该用于管理和监控组件。为每个组件指定<commandScript >执行命令时使用。有一个默认命令定义组件必须支持。
大数据实战:Ambari开发手册之OpenTSDB快速集成技巧
开头先吼一句口号:不会编程的大数据运维,不是一个好的DBA。
为啥这么说呢?因为我职位归属为DBA,负责大数据平台的建设与维护,而日常工作有80%左右的时间是在干开发。
-
DBA:数据仓库实现的功能也就是一个数据库,叫DBA,这勉强说得过去吧。
-
大数据运维:数仓的底层是由大数据平台做的,搞这个平台的维护说是大数据运维,貌似也说得过去吧。
-
编程:(看我怎么狡辩)。这就是大数据运维和普通运维、DBA岗位最本质的区别。众所周知,宏观的大数据不是特指某项特定技术,而是为了解决一个大量数据集而产生的解决方案合集。说白了,就是啥都要,最常见的就是Hadoop/Hive + Spark套装。但是实际的需求往往比这多得多。那么怎么才能维护好这个平台呢,那就是“开发”自己的运维工具。
1.OpenTSDB
今天,我们就来聊聊大数据全家桶中的一类数据处理结构“TSDB”,这种数据结构在运维眼中是怎么一个存在。接到一个这样的数据类型需求,怎么来做维护支持。接下来从以下几个层次来论述:
-
基础概念和使用:什么是OpenTSDB,怎么使用?
-
怎么进行批量维护?
-
怎么优化?
1.1 基础概念
TSDB(Time Series & Spatial Temporal Database)中文名称为“时间序列时空数据库”。是一种高性能、低成本、稳定可靠的在线时序时空数据库服务。它提供高效读写、高压缩比存储、时序数据插值及聚合计算等服务,广泛应用于物联网(IoT)设备监控系统、企业能源管理系统(EMS)、生产安全监控系统和电力检测系统等行业场景。
现在常见的TSDB有下面两个数据库:
-
InfluxDB:InfluxDB是一个开源的时间序列数据库,具有高可用性、可扩展性和实时性,适用于存储大量的时间序列数据。它支持灵活的查询语言,可以轻松地分析和可视化时间序列数据。
-
OpenTSDB:OpenTSDB是一个基于HBase的时间序列数据库,专门为存储和查询大量时间序列数据而设计。它提供了高效的数据存储和查询功能,支持快速的数据插值和聚合计算。
我们今天的主角OpenTSDB。为啥选它呢?因为我是搞大数据平台,我刚好有HBase,这不刚好吗。
1.2 基础使用
OpenTSDB可以通过以下方式进行数据的写入:
1)使用telnet协议写入数据:telnet是OpenTSDB默认的数据写入方式,可以通过telnet连接到OpenTSDB的4242端口,然后使用put命令将数据写入数据库中。
import telnetlib
import time
# OpenTSDB连接信息
host ="localhost"
port = 4242
# 连接OpenTSDB服务器
tn = telnetlib.Telnet(host, port)
# 写入数据
metric ="cpu.idle"
timestamp = int(time.time())
value = 99.0
data = f"{metric} {value} {timestamp}\n"
tn.write(data.encode('ascii'))
# 关闭连接
tn.close()
在这个示例中,我们首先使用telnetlib库创建了一个telnet连接,连接到OpenTSDB服务器。然后,我们定义了要写入的数据,包括metric、timestamp和value。最后,我们将数据转换为OpenTSDB的格式,并通过telnet连接写入到OpenTSDB中。需要注意的是,我们使用了time库获取当前时间戳,并将其转换为整数类型。同时,我们使用了encode方法将数据转换为ASCII码格式。
2)使用HTTP API写入数据:OpenTSDB还提供HTTP API来写入数据。可以使用POST请求将数据发送到OpenTSDB的/api/put接口,请求中需要包含必要的参数,如metric、timestamp、value等。
import requests
import json
# OpenTSDB连接信息
host ="localhost"
port = 4242
api_endpoint = f"http://{host}:{port}/api/put"
# 连接OpenTSDB服务器
response = requests.post(api_endpoint, data=json.dumps({
"metrics": [
{
"metric":"cpu.idle",
"timestamp": int(time.time()),
"value": 99.0,
"tags": {}
}
]
}))
# 关闭连接
response.close()这个示例中,我们首先定义了要写入的数据,包括metric、timestamp和value。然后,我们使用requests库创建了一个HTTP连接,连接到OpenTSDB服务器的/api/put接口。在请求中,我们将数据转换为JSON格式,并通过POST方法发送到接口中。需要注意的是,我们使用了int()函数将当前时间戳转换为整数类型。同时,我们使用了json.dumps()方法将数据转换为JSON格式。最后,我们使用response.close()关闭连接。
3)使用批量导入工具:OpenTSDB支持使用批量导入工具来一次性写入大量数据。可以使用tsdb-import命令来将本地文件中的数据导入到OpenTSDB中。这个用到的时候大家再百度。
1.3 存储原理解析
OpenTSDB的存储原理基于HBase,它使用了四张表来存储时间序列数据,分别是tsdb_uid、tsdb、tsdb_tree和tsdb_meta。
-
tsdb_uid表:这个表用于存储时间序列数据的唯一标识符(UID),包括指标(metric)、标签(tag)和时间戳(timestamp)。UID是OpenTSDB中每个数据点的唯一标识,由指标、标签和时间戳的组合而成。这个表的主要作用是提供数据点的索引和快速检索。
-
tsdb表:这个表用于存储实际的时间序列数据。每个数据点都会存储在这个表中,包括指标的值、时间戳和其他相关的元数据。这个表按照时间戳和指标进行排序,以便快速检索和聚合操作。
-
tsdb_tree表:这个表用于存储时间序列数据的聚合结果。通过将原始数据聚合为更粗粒度的数据,可以减少存储的数据量并提高查询效率。这个表中的数据是根据时间范围和聚合函数(如平均值、最小值、最大值等)计算得出的。
-
tsdb_meta表:这个表用于存储时间序列数据的元数据信息,如数据的度量标准、标签的命名空间等。这些元数据信息对于查询和分析时间序列数据非常重要。
OpenTSDB通过这四张表的组合使用,实现了时间序列数据的快速存储和查询。UID表提供了数据点的索引和快速检索,tsdb表存储了实际的数据点,tsdb_tree表存储了聚合结果,而tsdb_meta表则存储了元数据信息。这样的设计使得OpenTSDB具有高效的数据存储和查询能力。
1.4 存储过程
首先模拟一条数据录入:
putsystem.user.cpu159858218775420host=host1整个存储过程,会涉及两个表数据的插入:tsdb 和tsdb-uid
其中tsdb-uid表的数据如下:
hbase(main):002:0> scan'tsdb-uid'
ROW COLUMN+CELL
\x00 column=id:metrics,timestamp=1598582365144,value=\x00\x00\x00\x00\x00\x00\x00\x03\x00 column=id:tagk, timestamp=1598517313604,value=\x00\x00\x00\x00\x00\x00\x00\x01\x00 column=id:tagv, timestamp=1598582365162,
\x00\x00\x01 column=name:tagk, timestamp=1598517313609,value=host
\x00\x00\x02 column=name:tagv, timestamp=1598582365168,value=host1
\x00\x00\x03 column=name:metrics, timestamp=1598582365150,value=cpu.load
cpu.load column=id:metrics,timestamp=1598582365155,value=\x00\x00\x03
host column=id:tagk,timestamp=1598517313613,value=\x00\x00\x01
host1 column=id:tagv,timestamp=1598582365172,value=\x00\x00\x02首先,在tsdb-uid表中,对所有的tagk,tagv 和metric进行编号排序。比如:
-
监控指标(metric)cpu.load编号为:\x00\x00\x03
-
监控标记(tagk)host 编号为:\x00\x00\x01
-
监控标记对应的值(tagv)host1编号为:\x00\x00\x02
有以上信息后,那么就到tsdb表中进行数据查询
hbase(main):002:0>scan'tsdb'
ROW COLUMN+CELL
\x00\x00\x03_He \x00\x00\x01\x00\x00\x02 column=t:\xF8Xz\x80, timestamp=1598582366383, value=\x14其中整个Key是由上面查询中得出的三个值 + 时间来进行排序的。对应的关系如下图:
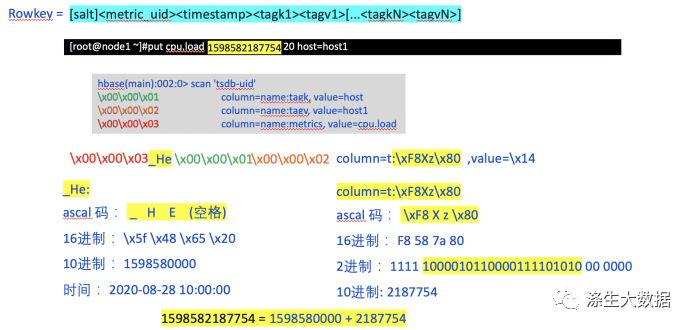
其中需要特殊说明的是时间此列,值为:_He(空格);
ascal码:_He空格
16进制:\x5f\x48\x65\x20
10进制:1598580000
时间:2020-08-2810:00:00这时间,是不是有点不对?这个值是整小时数据,所以,所有整个小时内的数据,在HBase中的Key是完全一样的。那么怎么知道具体的时间呢?具体的时间点在其对应的column中。
偏移量:column=t:\xF8Xz\x80;
2或者4字节组成。代表秒或者毫秒偏移量
ascal:\xF8 X z \x80
16进制:F8 58 7a 80
2进制:11111000010110000111101010 00 0000
前4位,限定字符:1111
后22位偏移量:1000010110000111101010对应10进制 2187754
后2位,保留字段:00
最后4为,格式标记:0000
第一位:0 整数;1 浮点数
后三位:000;数据长度;000 = 1字节;010 = 2字节;
那么整个时间详细参数就是上面两个红色地方的和:
1598582187754=1598580000 + 2187754当看完以上的所有流程,那么,这个数据库你就懂了大半了,可以在实际环境使用了。那么就可以开始运维工作了。
2.安装部署
此处,只会单纯讲解最简单的安装,能用即可。需要先部署好Hadoop和HBase,用啥方法安装好都行。
2.1 安装包下载
首先,下载安装软件:
https://github.com/OpenTSDB/opentsdb/releases有打包好的,直接下载即可,如果Hadoop和HBase的版本有点特殊的话,那么就麻烦各位大佬自己用源码包自己编译一波吧。这个编译难度不大,很稳,自己去折腾吧。
现在也有做好的RPM包,也可以直接使用。
2.2 配置修改
其安装目录下的文件结构如下:
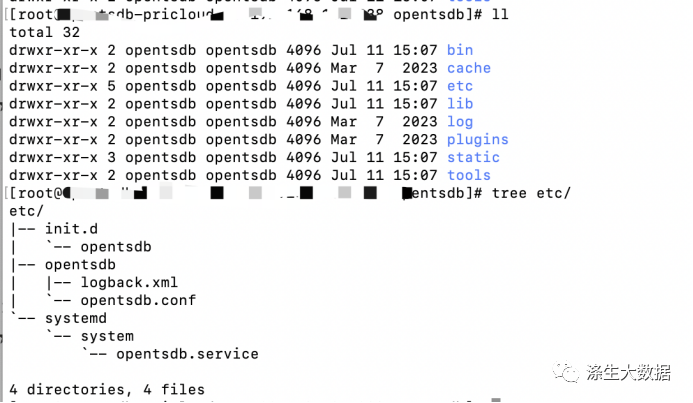
其中配置文档位于:./etc/opentsdb.conf ;其中主要定于各个配置信息:
tsd.network.bind =0.0.0.0
tsd.network.port =4242
tsd.storage.hbase.data_table = tsdb
tsd.storage.hbase.uid_table = tsdb-uid
tsd.storage.hbase.zk_basedir = /hbase
tsd.storage.hbase.zk_quorum = localhost
tsd.http.query.allow_delete =True
tsd.storage.fix_duplicates =True
tsd.core.timezone=Asia/Shanghai其中主要的参数如上,zk修改为HBase的zookeeper 地址信息即可。默认的存储表只有tsdb,tsdb-uid,其他表需要额外开启对应的索引。
2.3 数据库初始化
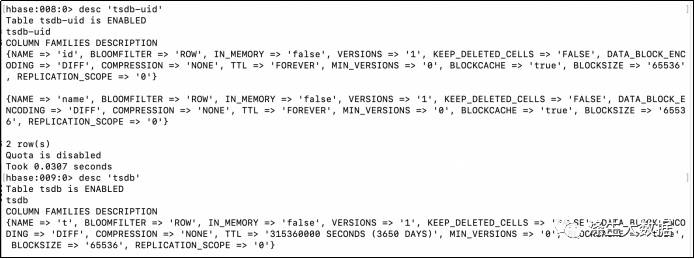
软件配置完毕后,在服务启动之前,还需要在HBase中建立对应的HBase表信息。对应的建表语句为: tools/create_table.sh
如果可以的话,修改下表中的压缩格式和TTL,这样可以有效控制数据利用率。
# LZO requires lzo2 64bit to be installed + the hadoop-gpl-compressionjar.
COMPRESSION=${COMPRESSION-'SNAPPY'}
TSDB_TTL=${TSDB_TTL-'315360000'}然后直接在命令行运行创建语句:./tool/create_table.sh
2.4 启动验证
为了方便管理,可以使用系统的服务管理组件来做启动服务。
ln-s /opt/app/opentsdb/etc/opentsdb /etc/opentsdb
ln-s /opt/app/opentsdb/etc/systemd/system/opentsdb.service /lib/systemd/system
systemctldaemon-reload然后使用命令:systemctl start opentsdb 即可启动服务。
服务启动后,使用浏览器访问:http://ipaddr:4242能看到页面证明就安装成功了。
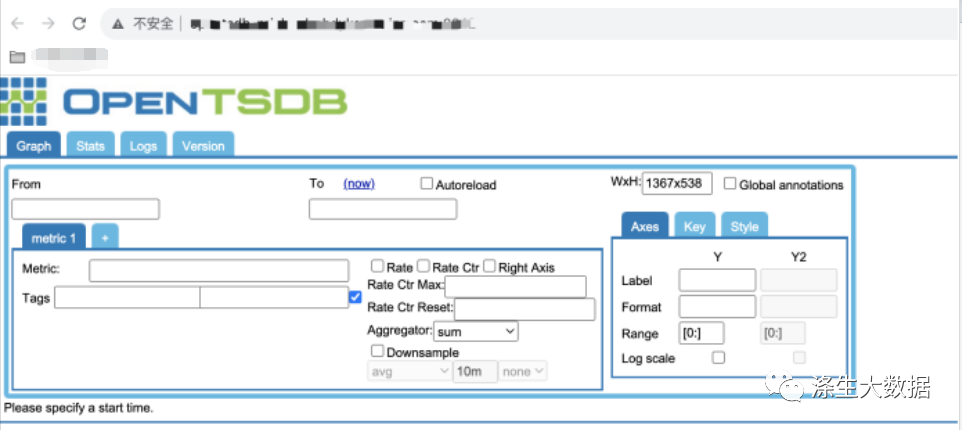
接下来就可以使用1.2 章节的案例进行数据案例测试了。
3.自动化实现
我们在上章2中使用了systemctl进行了该服务的管理。但是问题来了,我这里有一个完整的大数据部署平台Ambari,其他组件都在这个列表里可以点点点了。但是OpenTSDB却需要到服务器上去维护。如果我集群规模大了,谁还记得那台主机安装了啥东西呢?
所以,在这个大需求的情况下,作为项目经理的我给大数据平台开发(我)提出了如下需求:
-
需要将OpenTSDB集成到Ambari管理平台。
-
OpenTSDB需要支持多实例需求。
-
不同实例之间存储分离
3.1 需求分析
根据以上分析,我们整体结构可以使用Ambari的开发框架来进行主体实现。这个难度不大,可以参考以前发布的过的文章《Amabri二开-DolphinScheduler》来参考。
至于多实例的实现和存储的隔离,这…(头发还能保住吗)。
接下来要分析TSDB的存储结构和配置信息。看了1.3节后的内容,实际的存储由tsdb,tsdb-uid 表来实现,是不是改这个表配置的话,是不是就可以修改这个配置来实现吗?接下来就先验证一波(背地里暗暗得搞)。最后通过笔者熬了一个通宵后,终于搞出了可行的技术方案:
-
OpenTSDB的主要存储配置中,将opentsdb.conf 和create_table.sh中关于表的信息修改来实现具体的存储隔离。
-
接下来同一个Ambari实现多个实例呢?这个可以使用Ambari中的配置组管理来进行隔离。不过有点要注意的是,同一台主机,只能部署同一个类型的实例。
当解决方案想到,并小小测试通过后,就可以去码代码实现了。
3.2 RPM准备
准备安装包
可以去TSDB的官网下载现有的rpm修改。
https://github.com/OpenTSDB/opentsdb/releases按以上套路解压rpm,修改下OpenTSDB的安装路径等信息。
修改配置
主要修改内容如下:
a. spec 文件中的“%file”内容
将软件安装路径“/opt/app/opentsdb”,修改%file下的安装路径,如下所示:
%files
%attr(0755, root, root)"/usr/bin/tsdb"
%dir %attr(0755, root, root)"/opt/app/opentsdb"
%dir %attr(0755, root, root)"/opt/app/opentsdb/bin"
%attr(0644, root, root)"/opt/app/opentsdb/bin/mygnuplot.bat"b. /bin/tsdb
修改家目录文件的定义:默认在“/usr/lib/opentsdb”,修改为“/opt/app/opentsdb”:
[root@ bin]# vim tsdb
...
pkgdatadir='/opt/app/opentsdb'
...c. opentsdb.conf
配置文件,修改点默认配置,主要改路径:
[root@ opentsdb]# vim /opt/app/opentsdb/etc/opentsdb
tsd.network.port =8242
tsd.network.bind =0.0.0.0
tsd.http.staticroot = /opt/app/opentsdb/static/
tsd.http.cachedir = /opt/app/opentsdb/cache
tsd.core.plugin_path = /opt/app/opentsdb/plugins
tsd.storage.hbase.data_table = tsdb
tsd.storage.hbase.uid_table = tsdb-uid
tsd.storage.hbase.zk_basedir = /hbase
tsd.storage.hbase.zk_quorum = localhostd. opentsdb.service
定义TSDB的服务启动信息。将pid文件定义删除,系统版本问题,这个配置项目读取不到,不能正常启动服务。
[root@ system]# cat /opt/app/opentsdb/etc/systemd/system/opentsdb.service
[Unit]
Description=OpenTSDBonport
After=network-online.target
Before=shutdown.target
[Service]
Type=simple
User=opentsdb
Group=opentsdb
LimitNOFILE=65535
Environment=JAVA_HOME=/opt/wzapp/jdk
Environment='JVMARGS=-Xmx2048m -DLOG_FILE=/opt/app/opentsdb/log/%p.log -DQUERY_LOG=/opt/app/opentsdb/log/%p_queries.log-XX:+ExitOnOutOfMemoryError -enableassertions -enablesystemassertions'
ExecStart=/usr/bin/tsdb tsd --config /etc/opentsdb/opentsdb.conf
Restart=always
StandardOutput=journalrpm制作
Step1:使用rpm制作
使用rpmbuild制作压缩包后拷贝到repo源位置,更新repo源。【参考以上操作文档中的步骤】
Step2:验证rpm安装
寻找任意一台主机,配置内部源的repo信息,执行安装OpenTSDB操作。
a. 添加repo源配置;
[root@ services]# cat /etc/yum.repos.d/ambari.repo
[HDP]
name="Ambari 3.1.0.0-5"
baseurl=http://ipaddr/HDP/3.1.0.0-5
enabled=1
gpgcheck=0b. 更新repo源,检查TSDB是否有:
[root@ services]# yum makecache
Ambari |2.9kB00:00:00
HDP |2.9kB00:00:00
HDP-2.6-repo-1|2.9kB00:00:00
HDP-GPL |2.9kB00:00:00
[root@ services]# yum list |grep opentsdb
opentsdb.noarch2.4.0-1HDPStep3:手动安装确认
手动安装一下TSDB,查看是否可以安装并启动。
[root@***]# yum install opentsdb
正在解决依赖关系
--> 正在检查事务
---> 软件包 opentsdb.noarch.0.2.4.0-1将被 安装
--> 正在处理依赖关系 gnuplot,它被软件包 opentsdb-2.4.0-1.noarch 需要
--> 正在检查事务
.....
已安装:
opentsdb.noarch0:2.4.0-1
作为依赖被安装:
gd.x86_640:2.0.35-26.1.al7 gnuplot.x86_640:4.6.2-3.1.al7 gnuplot-common.x86_640:4.6.2-3.1.al7 libXpm.x86_640:3.5.12-1.1.al7
完毕!
[root@***]# systemctl start opentsdb
[root@***]# systemctl status opentsdb
● opentsdb.service - OpenTSDBonport
Loaded: loaded (/opt/app/opentsdb/etc/systemd/system/opentsdb.service;static; vendor preset: disabled)
Active: active (running) since 一2020-11-0916:17:20CST;6s ago
Main PID:14376(java)
Tasks:58
Memory:93.4M
CGroup: /system.slice/opentsdb.service
└─14376java -Xmx2048m -DLOG_FILE=/opt/app/opentsdb/log/opentsdb.log -DQUERY_LOG=/opt/app/opentsdb/log/opentsdb_queries.log-XX:+ExitOnOutOfMemoryError -enableassertions -enablesystemassertions -classpath/opt/app/opentsdb/*.jar:/opt/app/opentsdb:/op...
11月 09 16:17:20 andesserver-vbj01-3 systemd[1]: Started OpenTSDB on port.验证目录和文件都OK,那么RPM制作成功。
3.3 Ambari开发
接下来就开始搞集成开发了
开发ambari的开发脚本。参考官网:
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=38571133所有代码放到一个文件夹OPENTSDB下面,存到放Ambari-Server的Stack目录:
/var/lib/ambari-server/resources/stacks/HDP/3.3/services代码结构
代码文件目录结构如下:
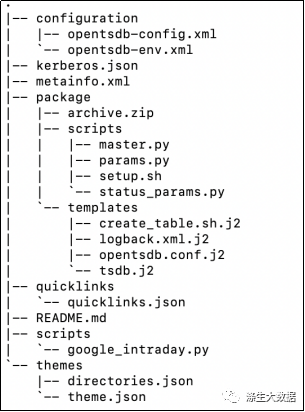
主服务定义
OPENTSDB/metainfo.xml
用于描述这个服务,服务的组件和管理脚本用于执行命令。一个组件的服务可以是MASTER,SLAVE或CLIENT类别。这个<category>告诉Ambari默认命令应该用于管理和监控组件。为每个组件指定<commandScript >执行命令时使用。有一个默认命令定义组件必须支持。
<?xml version="1.0"?>
<metainfo>
<schemaVersion>2.0</schemaVersion>
<services>
<service>
<name>OPENTSDBDEMO</name>
<displayName>OpenTSDB</displayName>
<comment>时序数据库OpenTSDB</comment>
<version>2.4.0</version>
<components>
<component>
<name>OPENTSDB_MASTER</name>
<displayName>OpenTSDB</displayName>
<category>MASTER</category>
<cardinality>1</cardinality>
<commandScript>
<script>scripts/master.py</script>
<scriptType>PYTHON</scriptType>
<timeout>5000</timeout>
</commandScript>
</component>
</components>
<osSpecifics>
<osSpecific>
<osFamily>redhat7</osFamily>
<packages>
<package><name>gnuplot</name></package>
</packages>
</osSpecific>
</osSpecifics>
<configuration-dependencies>
<config-type>opentsdb-config</config-type>
</configuration-dependencies>
<restartRequiredAfterChange>false</restartRequiredAfterChange>
</service>
</services>
</metainfo>安装脚本
OPENTSDB/package/scripts/master.py
书写OpenTSDB的安装程序,其他读取配置等的可参考HADOOP的进行编辑和修改。
其中安装命令:yum install -y opentsdb;
获取并写入pid文件(用于ambari检查):
echo"`ps -aux |grep opentsdb |grep -v grep |awk \'{print$2}\'`"
数据表初始化:
env COMPRESSION=NONE HBASE_HOME=/usr/hdp/current/hbase-client ./src/create_table.shimportsys, os, pwd, signal, time
fromresource_managementimport*
fromsubprocessimportcall
classMaster(Script):
definstall(self, env):
# Install packages listed in metainfo.xml
self.install_packages(env)
self.configure(env)
importparams
ifnotos.path.exists(params.install_dir):
os.makedirs(params.install_dir)
Execute('yum install -y opentsdb >> '+params.log)
Execute('mkdir -p '+ params.log +' >> '+params.log,ignore_failures=True)
ifparams.create_schema:
Execute('cd '+ params.install_dir +'; env COMPRESSION=NONE HBASE_HOME=/usr/hdp/current/hbase-client ./src/create_table.sh;>> '+params.log)
defconfigure(self, env):
importparams
env.set_params(params)
defstop(self, env):
importparams
importstatus_params
env.set_params(status_params)
self.configure(env)
#kill child processes
Execute (format('systemctl stop opentsdb'))
defstart(self, env):
importparams
importstatus_params
self.configure(env)
ifnotos.path.exists(status_params.opentsdb_piddir):
os.makedirs(status_params.opentsdb_piddir)
Execute('echo Starting process: '+ params.install_dir + params.start_cmd )
Execute(params.start_cmd)
Execute('echo "`ps -aux |grep opentsdb |grep -v grep |awk \'{print $2}\'`" >'+ params.opentsdb_pidfile)
defstatus(self, env):
importstatus_params
env.set_params(status_params)
check_process_status(status_params.opentsdb_pidfile)
if__name__ =="__main__":
Master().execute()其他功能自行观察。
修改配置
OPENTSDB/configuration/opentsdb-config.xml
定义在web页面可以修改的配置。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<propertyrequire-input="true">
<name>opentsdb.install_dir</name>
<value>/opt/app/opentsdb</value>
<description>Directory under which OpenTSDP will be installed (e.g. /opt/app/opentsdb).Will be created if not already exists.</description>
</property>
<propertyrequire-input="true">
<name>opentsdb.zk.quro</name>
<value>master1:2181,master2:2181,master3:2181</value>
<description>Directory under which OpenTSDP will be installed (e.g. /opt/app/opentsdb).Will be created if not already exists.</description>
</property>
<propertyrequire-input="true">
<name>opentsdb.download_url</name>
<value>http://master2:80/locationx/soft/opentsdb-2.4.0.tar.gz</value>
<description>Online location to download OpenTSDB .tar.gz package from</description>
</property>
<propertyrequire-input="true">
<name>opentsdb.create_schema</name>
<value>true</value>
<description>Whether OpenTSDB schema should be created. Hbase must be started if thisis selected</description>
</property>
<property>
<name>opentsdb.start_cmd</name>
<value>/build/tsdb tsd --zkbasedir=/hbase-unsecure --port=8242 --zkquorum=master1:2181,master2:2181,master3:2181--cachedir=/data/tmp/tsd --staticroot=build/staticroot --auto-metric</value>
<description>Command to launch demo daemon that Ambari will monitor. Port, zk basedir, zk quorum, cache dir can be customized</description>
</property>
<property>
<name>opentsdb.log</name>
<value>/data/log/opentsdb/opentsdb.log</value>
<description>Log file (required)</description>
</property>
<property>
<name>tsd.network.port</name>
<value>4242</value>
<description>服务端口</description>
</property>
<property>
<name>tsd.network.bind</name>
<value>0.0.0.0</value>
<description>服务端口</description>
</property>
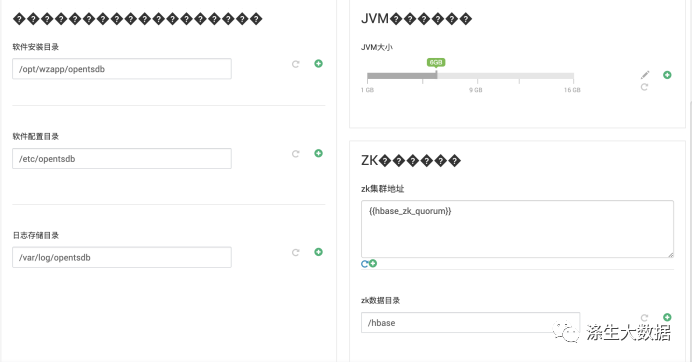
</configuration>效果图(有中文乱码,忽略):
变量获取
OPENTSDB/package/scripts/params.py
获取配置的方法,读取web上面的配置。写入变量中,提供后续安装时候调用。
#!/usr/bin/env python
from resource_management import *
# server configurations
config = Script.get_config()
opentsdb_user="opentsdb"
opentsdb_group="opentsdb"
install_dir = config['configurations']['opentsdb-config']['opentsdb.install_dir']
conf_dir = config['configurations']['opentsdb-config']['opentsdb.conf_dir']
tsd_storage_hbase_zk_quorum = config['configurations']['hbase-site']['hbase.zookeeper.quorum']
tsd_storage_hbase_zk_basedir = config['configurations']['hbase-site']['zookeeper.znode.parent']
tsd_storage_hbase_data_table = config['configurations']['opentsdb-config']['tsd_storage_hbase_data_table']
tsd_storage_hbase_uid_table = config['configurations']['opentsdb-config']['tsd_storage_hbase_uid_table']
tsd_storage_hbase_tree_table = config['configurations']['opentsdb-config']['tsd_storage_hbase_tree_table']
tsd_storage_hbase_meta_table = config['configurations']['opentsdb-config']['tsd_storage_hbase_meta_table']
start_cmd = config['configurations']['opentsdb-config']['opentsdb.start_cmd']
log_dir = config['configurations']['opentsdb-config']['opentsdb.log']
…
#tsdb
jvm_xmx=config['configurations']['opentsdb-config']['jvm_xmx']
opentsdb_piddir = config['configurations']['opentsdb-env']['opentsdb_piddir']
opentsdb_pidfile = format("{opentsdb_piddir}/opentsdb.pid")
#config
tsd_port = config['configurations']['opentsdb-config']['tsd.network.port']最后上传OPENTSDB代码包到Ambari-server的service目录,并重启Ambari-server服务。
[root@**** tools]# cp OPENRSDB /var/lib/ambari-server/resources/stacks/HDP/3.3/services/
[root@**** tools]# ambari-server restart在ambari-server的web安装页面即可查看到此服务。
3.4 安装部署验证
安装部署啥的,在页面上点点点就可以了。各位大佬读者看着安装即可。这里主要演示多实例的部署,主要需要使用Ambari的组管理
在【Ambari】组件【OpenTSDB】的【配置管理页面】:
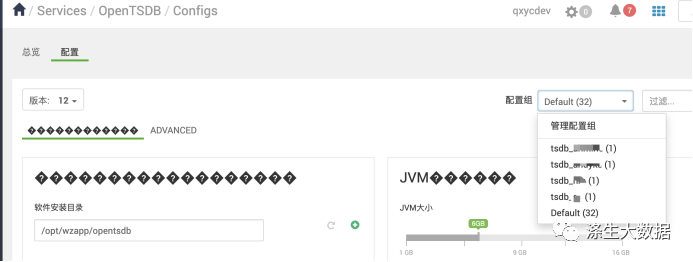
添加对应的组和主机归属:
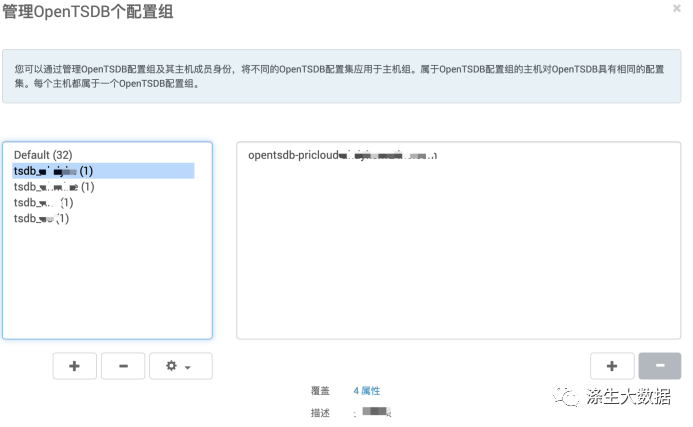
然后在详细的配置中,切换不同组,修改对应的表信息:
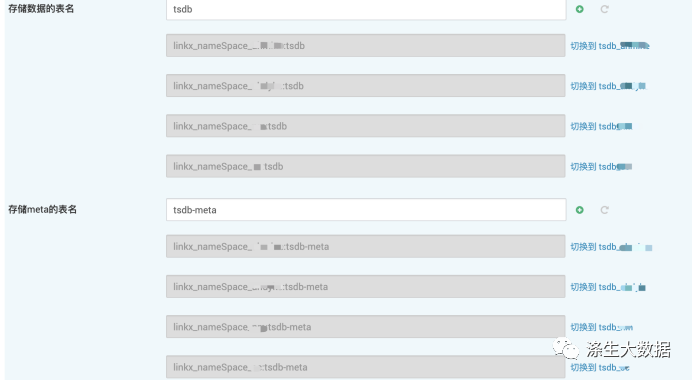
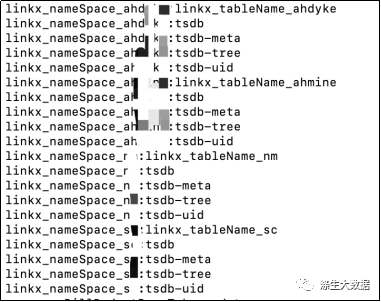
注意:四个表都得改:tsdb,tsdb-uid,tsdb-meta,tsdb-tree
最后,在不同的主机上,进行对应的安装。安装完成后的页面:
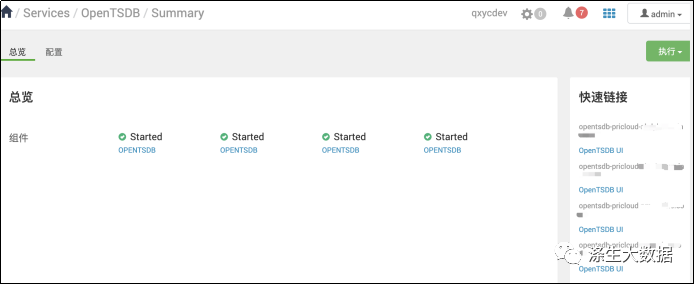
接下来双重验证,点击不同的链接,确认是否都可用。
在HBase中,确认下是否都有建立对应的存储表。
最后的最后,搞点虚拟数据验证下,看看数据读写都否都OK。然后就可以开启正常的运维生活了(玩着手机看开发各种花式掉头发)。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 20
20 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)