
[数据分析项目实战1-5]pandas利用透视表pivot_table构建用户RFM模型
以上的数据只是我们初步筛选过后的数据,我们要知道RFM可视为一个三维坐标系,用户要被映射到坐标范围在(0,1) 之间,那么指标就需要可比性,可计算行,首先我们需要将' or_date '这个日期属性转变一下,同时对列名进行更改。RFM模型用三个指标来对用户进行分类,可以将用户视作某个点在三维坐标系的位置,将指标的度量映射到(0,1)上,从而对用户进行可视化分类。现在关键的一步是如何将其映射到(0,
Hello,大家好,好久不见,又是一个屁股坐酸的下午,有点闲时间,来更新一下。
先给大家聊一聊RFM模型,好像在很多人简历上都看到过项目经历设计刀RFM模型构建,那么什么是RFM模型呢?RFM模型是衡量客户价值和客户创造利益能力的重要工具和手段,通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况,从而制定有效的策略来提高用户对企业的价值。
RFM模型用三个指标来对用户进行分类,可以将用户视作某个点在三维坐标系的位置,将指标的度量映射到(0,1)上,从而对用户进行可视化分类。
书接上回1-4数据,现在我们需要构建一个用户RFM模型,为了新来的同学能够了解数据,我先展示部分数据样式。
df.head()

对用户数据进行数据表透视,获取目标信息。其实对就是对指定的字段进行分别处理。
rfm = df.pivot_table(
index='id',
values=['or_date','or_num','or_amount'],
aggfunc={
'or_date':'max'
,'or_num':'sum',
'or_amount':'sum'
})
#获取用户最近一次消费日期以及累积金额与次数这里的index表示分类字段,相当于groupby,values表示需要取出的字段,aggfunc表示对不同字段需要做的函数操作。以上的数据只是我们初步筛选过后的数据,我们要知道RFM可视为一个三维坐标系,用户要被映射到坐标范围在(0,1) 之间,那么指标就需要可比性,可计算行,首先我们需要将' or_date '这个日期属性转变一下,同时对列名进行更改
rfm['R'] = -(rfm['or_date']-rfm['or_date'].max())/np.timedelta64(1,'D')
#将日期转化为天数,数据越大,表明最近消费日期相较远一点
rfm.rename(columns={'or_num':'F','or_amount':'M'},inplace=True)
现在关键的一步是如何将其映射到(0,1)上,怎么选取比较点,这里我们取指标的均值作为分割点,在进行转化。
rfm['label']= rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(label,axis=1)这里的映射函数label可如下,这里的函数较为简化了,将大于的值设为1,其余都为0
def label(data):
level = data.apply(lambda x:'1' if x>=1 else '0')
label = level['R']+level['F']+level['M']
type={
'111':'a',
'110':'b',
'101':'c',
'100':'d',
'010':'e',
'011':'f',
'001':'g',
'000':'h'
}
return type[label]这里面有个很关键的点就是对不同类型的数据进行分类,我们可以先将类别放入字典,在利用key值进行提取
这样,用户的类别划分其实已经结束,但是由于一般都是二维数据表示,这里用散点图展示
for x,y in rfm.groupby('label'):
i = y['F']
j = y['M']
plt.scatter(i,j,label=x)
plt.show()之前有说过分类后的数据有两类,所以用两个参数接受,结果如下
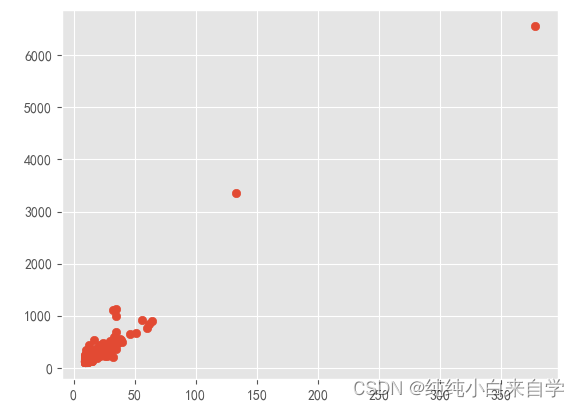
这里对F,M数据进行展示

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)