大数据_Flink_Java版_容错机制(6)-检查点和重启策略配置---Flink工作笔记0075
https://blog.csdn.net/lidew521/article/details/123666066
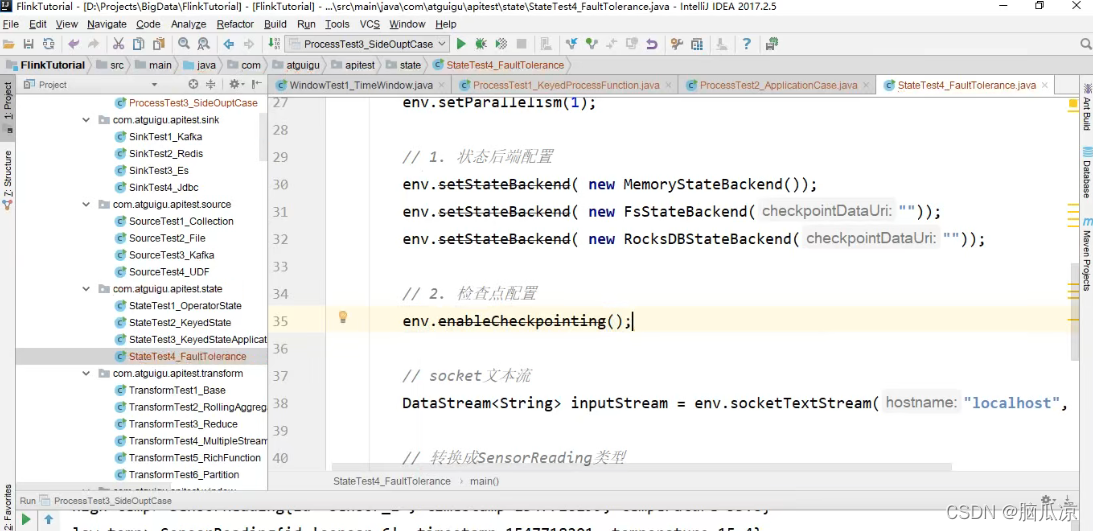
然后我们来看,在代码中我们并没有设置过检查点对吧,难道她会自动的给我们保存检查点吗,
注意,不会,因为检查点,是很耗性能的,默认是不开启的,然后我们来看一下如何开启并使用.
我们在StateTest4_FaultTolerance中做例子就行了,这个代码是现成的,我们用来做状态后端测试的.
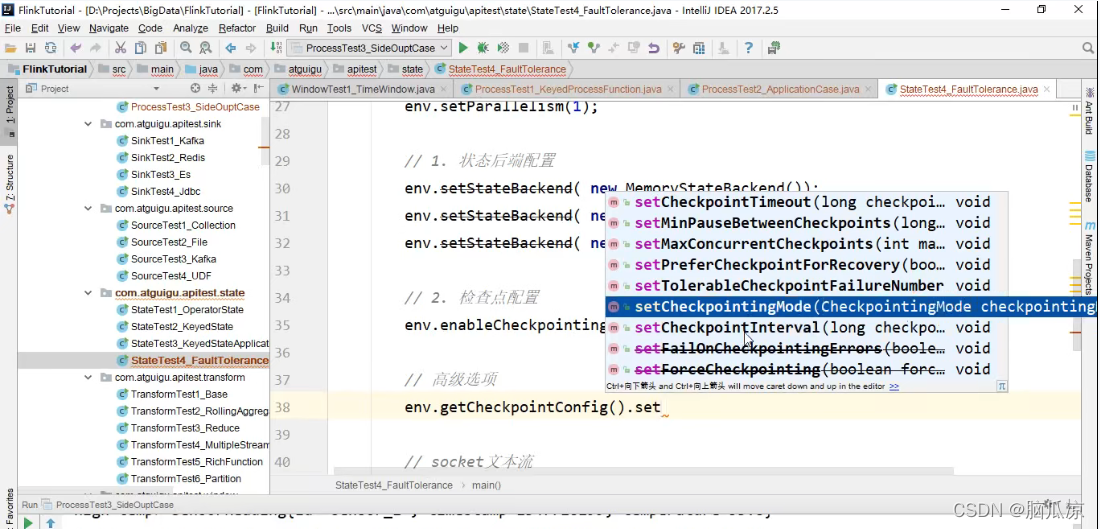
可以看到这里,我们通过env.enableCheckpointing().这里来启动检查点
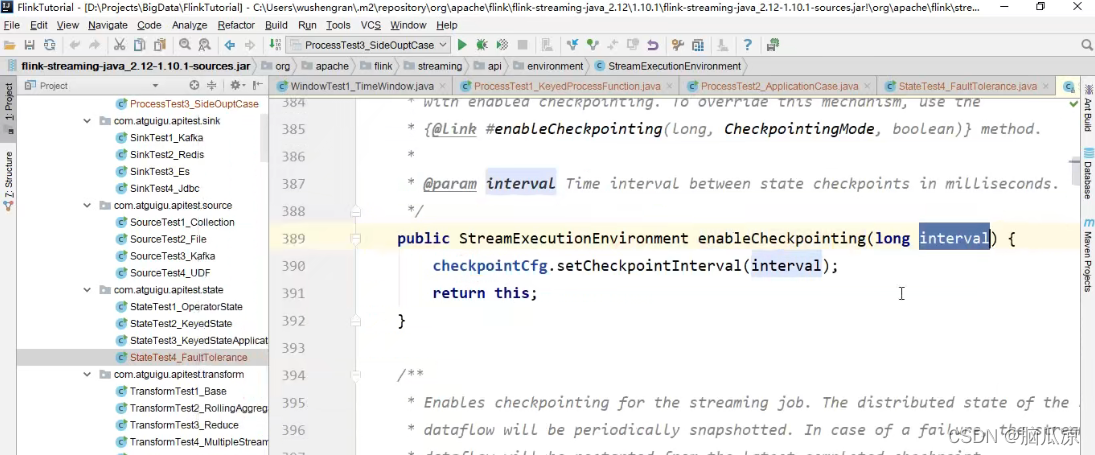
然后我们去看看,实际上还有个带参数的
enableCheckpointing对吧,里面传入一个long型的interval间隔
表示多久,要自动创建一次检查点对吧
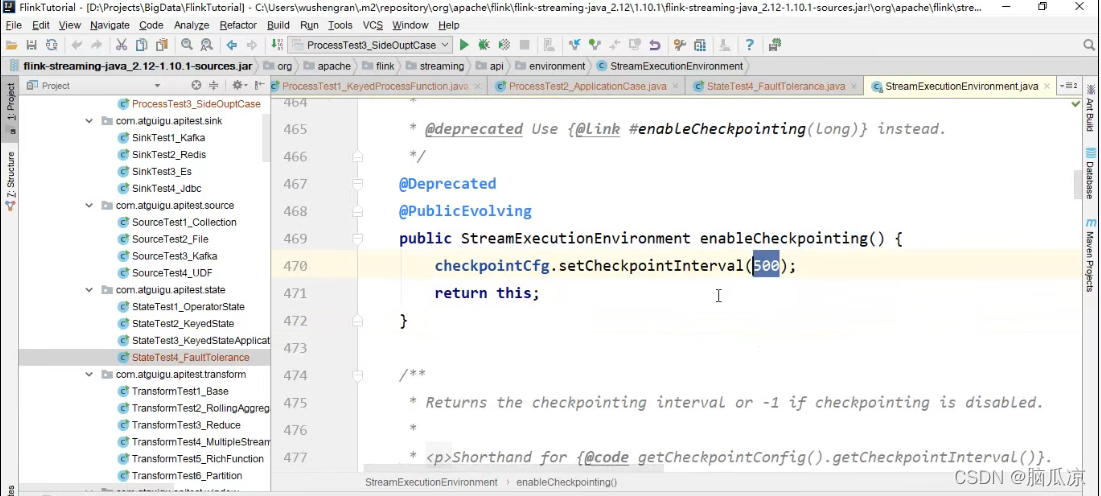
可以看到不带参数的,里面也是调用了带参数的对吧,可以看到默认是500毫秒.
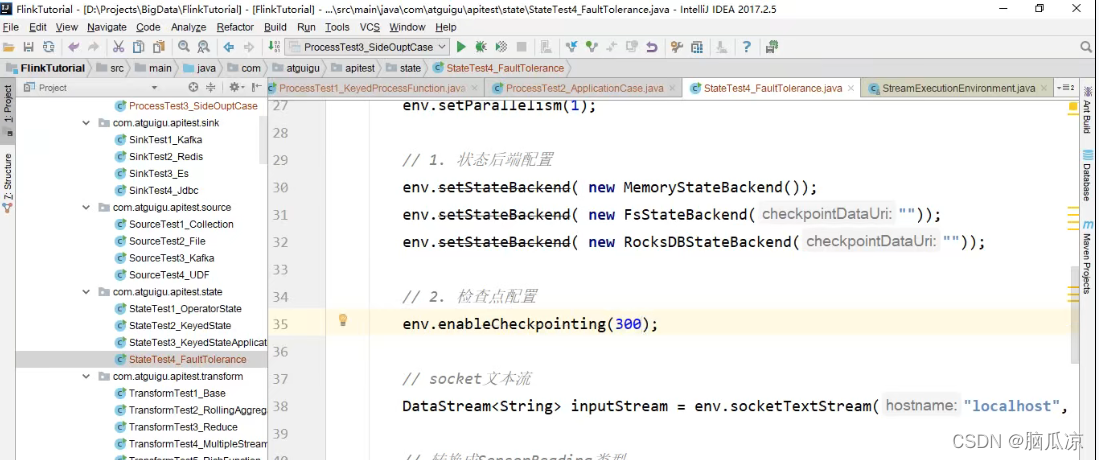
然后我们再看,可以看到我们这里可以用带参数的指定,300毫秒创建一次检查点对吧
然后
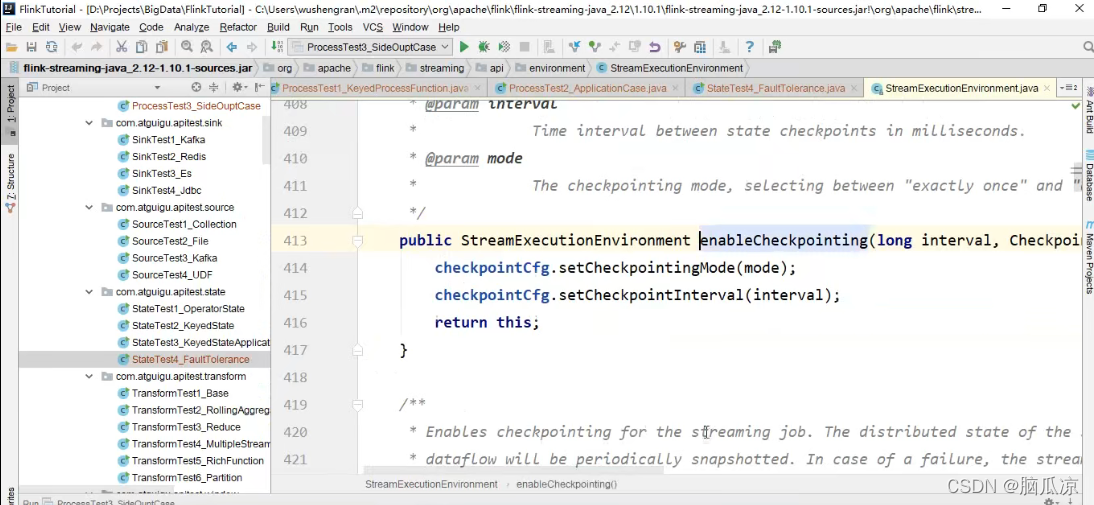
我们看还有个有两个参数的,方法,第二个可以看到是
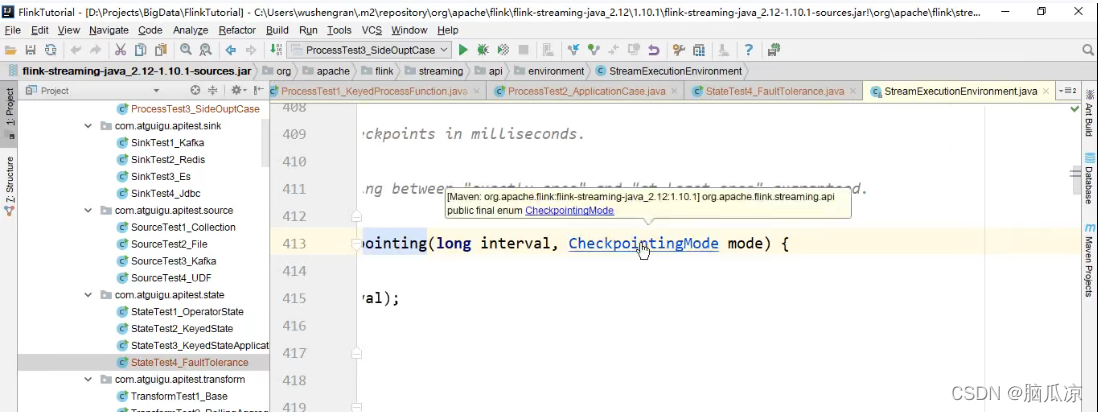
是CheckpointingMode对吧,是模式
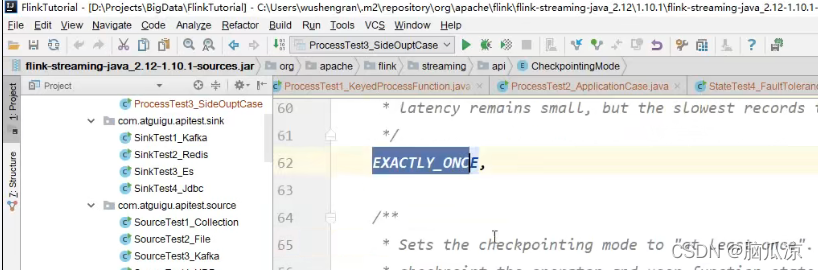
可以看到这个模式是个枚举类型
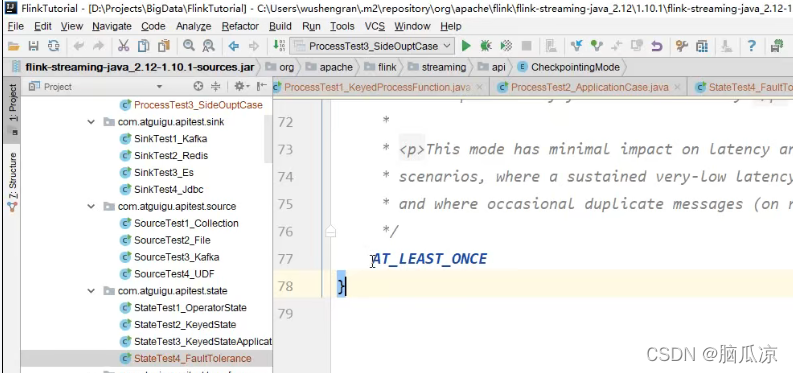
有两个一个是,执行一次创建检查点,一个是至少创建一次检查点对吧
然后我们再看
也可以这样:
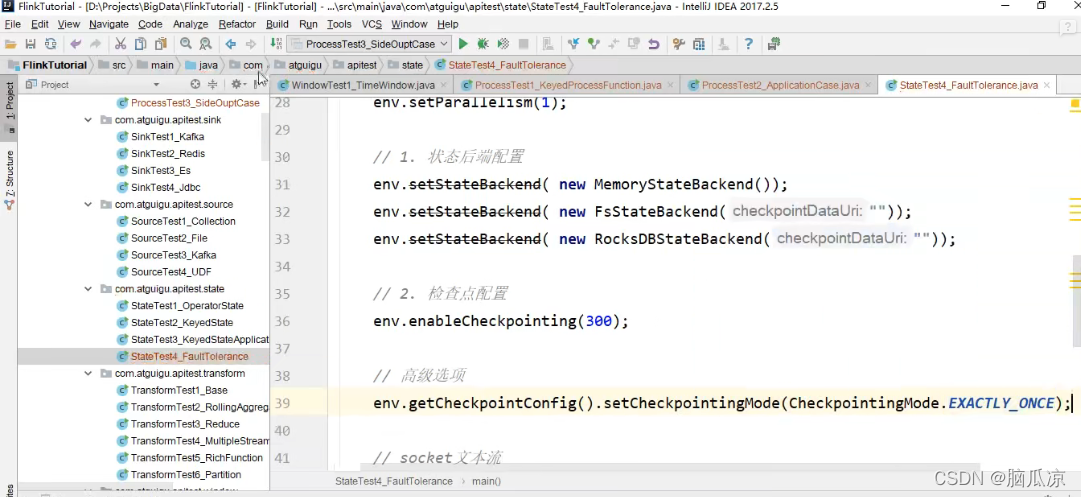
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);设置检查点保存
执行一次
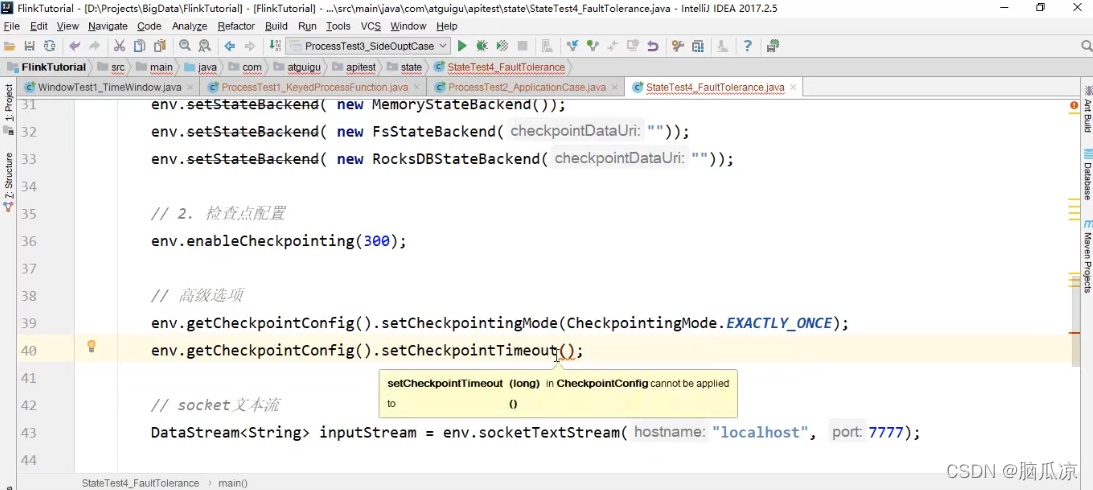
然后再看这个env.getCheckpointConfig().setCheckpointTimeout()
这个就是说,设置一个超时时间,就是说,保存检查点的时候,处理超时的时间.
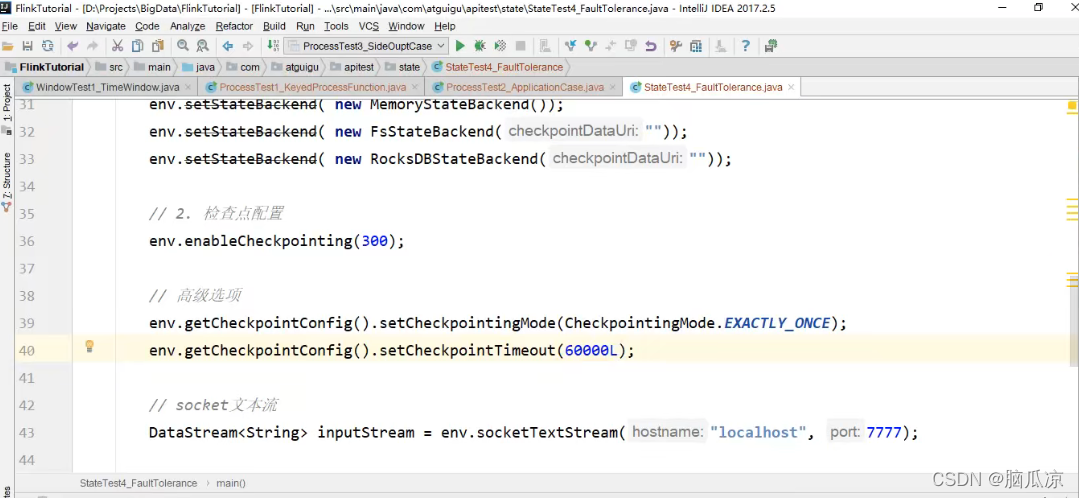
比如上面我们社这里
env.getCheckpointConfig().setCheckpointTimeout(60000L)设置了一分钟超时.
然后我们再看一下,这里
env.setCheckpointConfig().setMaxConcurrentCheckpoints(2)
这里设置了,同时执行的最大的检查点的个数,什么意思?
其实就是:
我们看这个env.setCheckpointConfig().setMaxConcurrentCheckpoints(1)
这个检查点的同时创建个数也可以是1对吧
setMaxConcurrentCheckpoints这个是什么意思?
就是说,比如我们现在正在创建一个检查点,但是由于数据量大等原因,300ms以后了,这个检查点还没有创建完
,还在创建中,这个时候,下一个检查点就已经开始正在创建了.
那么这个时候就会存在同时有两个检查点的情况了.
那么如果这个值设置为1,就表示,同时只能有一个检查点被创建,就是说,只有当前这个检查点创建完了以后,下一个检查点才能被创建
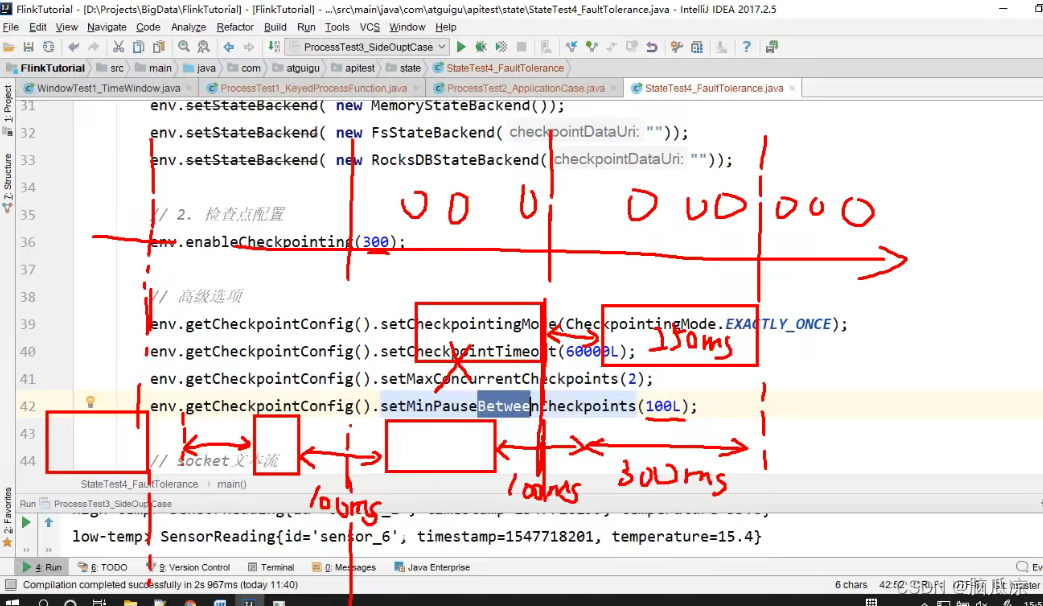
然后我们再来看这个
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(100L)
这里,设置最小的检查点间隔我们设置了100ms是什么意思呢?
数据来了,可以看到我设置的,每隔300ms,来创建一个检查点,但是现在可以看到只花了250ms就创建完检查点了
这个时候,还剩50ms对吧,就合计300ms,就又开始创建下一个检查点了,那么到了这个50ms以后能接着创建检查点嘛?
不能对吧,因为我们设置了最小间隔是100ms,也就是说,创建完第一个检查点以后,再隔100ms,然后再创建检查点,
可以看到,第一个250ms创建完了检查点,然后等50ms到300ms,然后再等50ms,这个时候,就是第一个检查点,创建完成
100ms了.就可以创建第二个检查点了.如果创建第二个检查点的时候,出问题了系统这个时候就需要,恢复上一个检查点.
第二个检查点创建以后,再隔100ms,再创建第3个检查点对吧.如果第二个检查点用了200ms创建完了,可以看到,还剩
50ms,然后就是第二个300ms,然后第3个检查点,又要空出50ms来,创建对吧,然后如果第3个检查点,只用了50ms就创建完了呢
可以看到还剩200ms,这个时候,怎么办?第3个300ms,现在才用了100ms对吧,还剩200,那么间隔100ms,这里肯定能做到,然后
还剩100ms,那么这个时候就需要等着了,因为这个300ms,还没用完对吧,等着这200ms过去以后,再创建第4个检查点.
所以可以看到上面创建的时候是创建最小的间隔对吧,setMinpauseBetweenCheckpoints(100L)对吧
然后我们再看这里
env.getCheckpointConfig().setPreferCheckpointForRecovery();
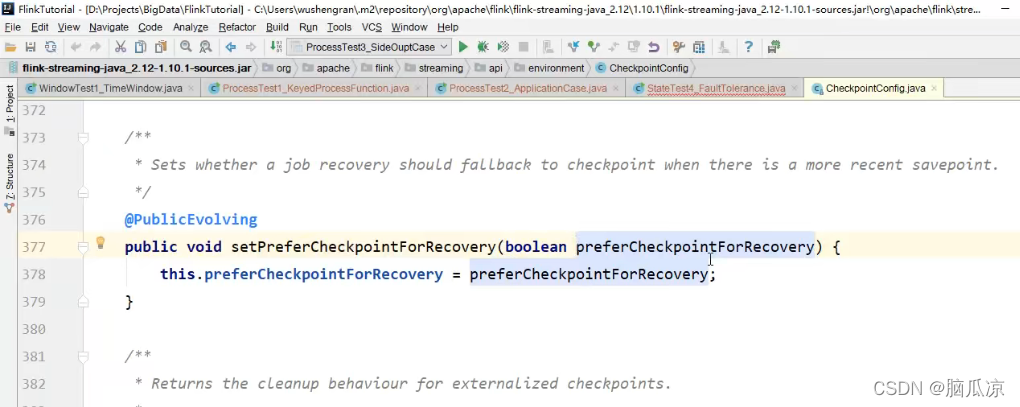
可以看到这里传入一个boolean值.
这个就是说,是更倾向于用checkpoint吗?
因为,这里默认是获取最近的检查点 或者是保存点 来恢复的,但是如果这个设置true的话,那么
如果比较近的,是一个保存点的话,他也不会获取保存点来执行了.
他也会获取比较远的检查点来执行恢复,这就是true,指定了更倾向于使用检查点.
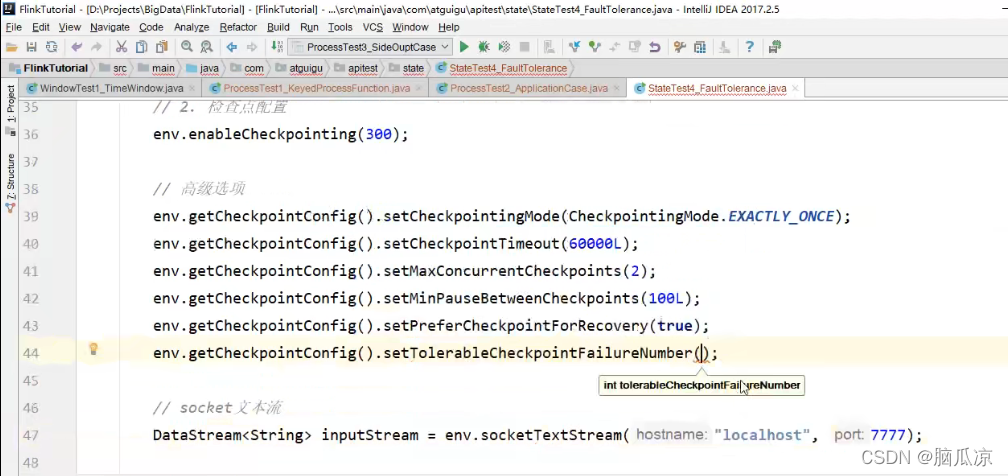
然后我们再看:
env.getCheckpointConfig().setTolerableCheckpointFailureNumber()
设置,容忍度,检查点创建失败的容忍度,就是说,这个值默认的是0,就是不容忍检查点失败,如果检查点失败了,
那么就代表任务也挂了,这个时候就执行重启,但是如果这里设置了2,表示,创建两次检查点如果失败了,那么就
认为任务失败了就需要重启了.
这里可以自己设置次数.
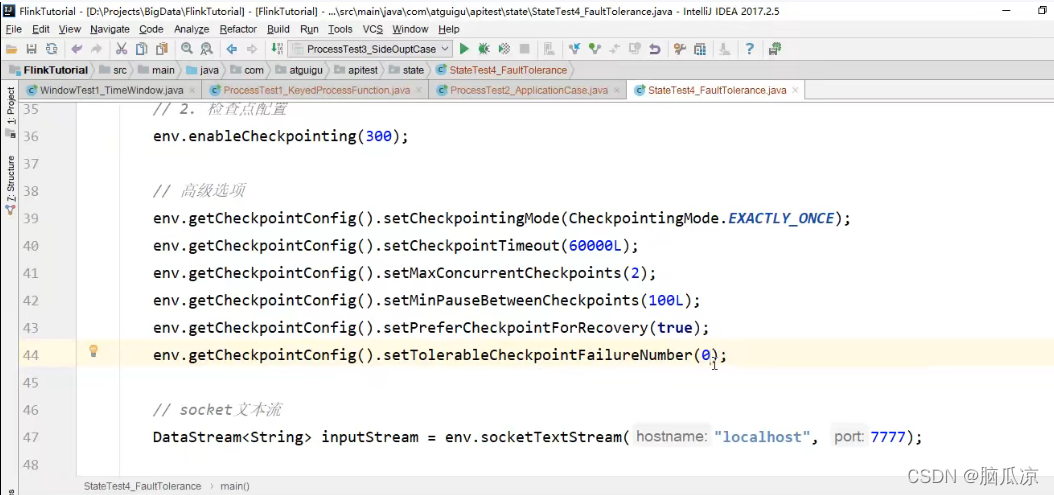
然后这个容忍度默认是,0,也就是说如果创建检查点失败了就认为,任务失败了需要重启.
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0)
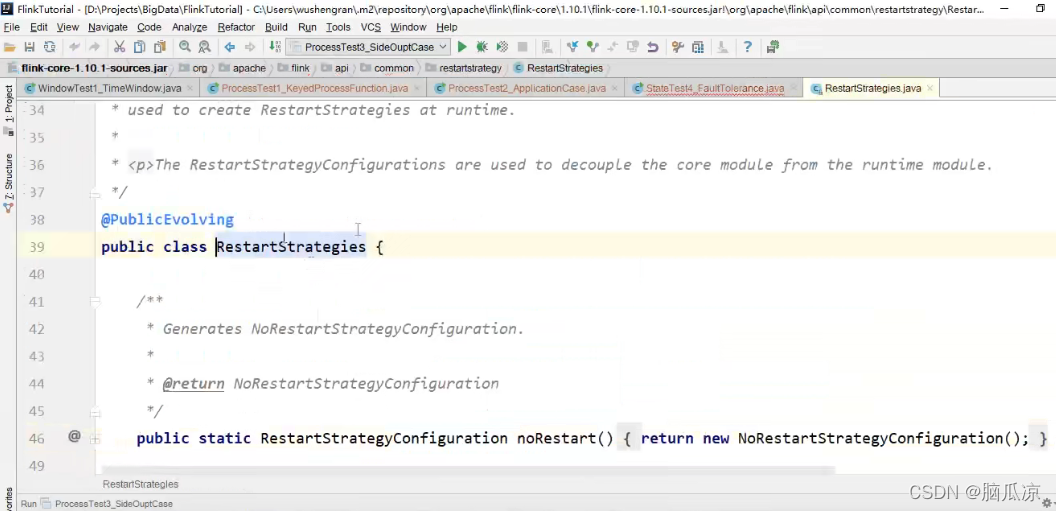
然后我们再来看,失败重启配置策略,可以看到这个
RestartStrategies
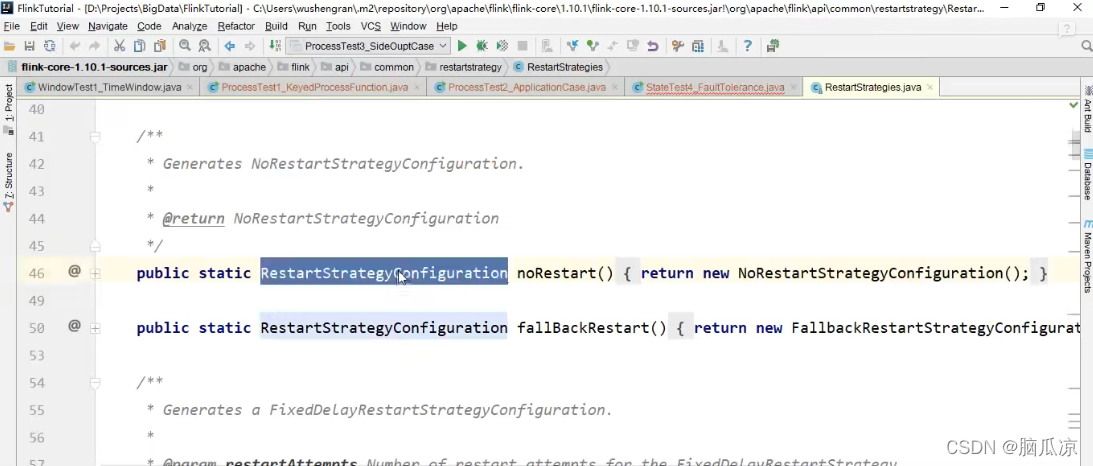
可以看到这里面有个noRestart就是不重启对吧
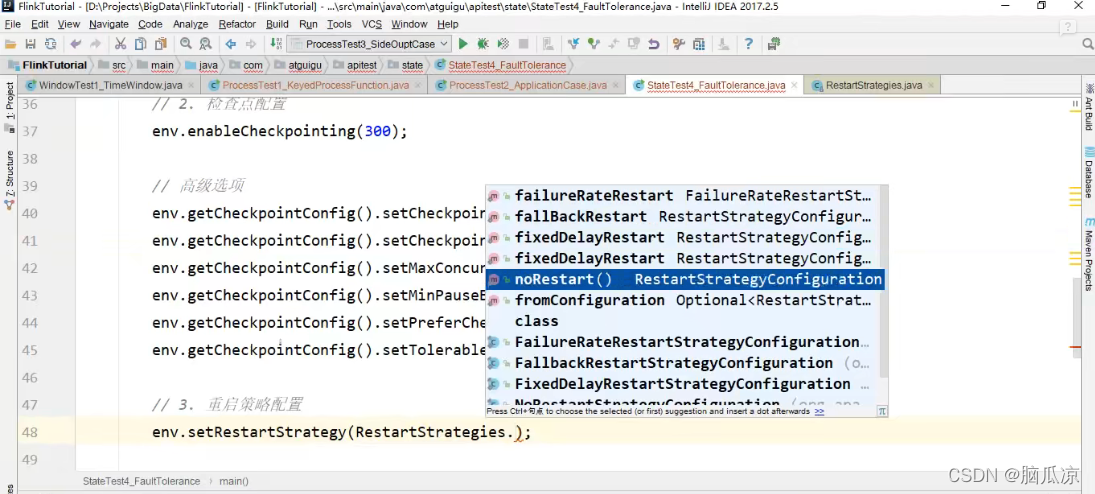
我们去看可以通过
env.setRestartStrategy(RestartStrategies.);
来设置,重启策略
可以看到上面noRestart是不重启
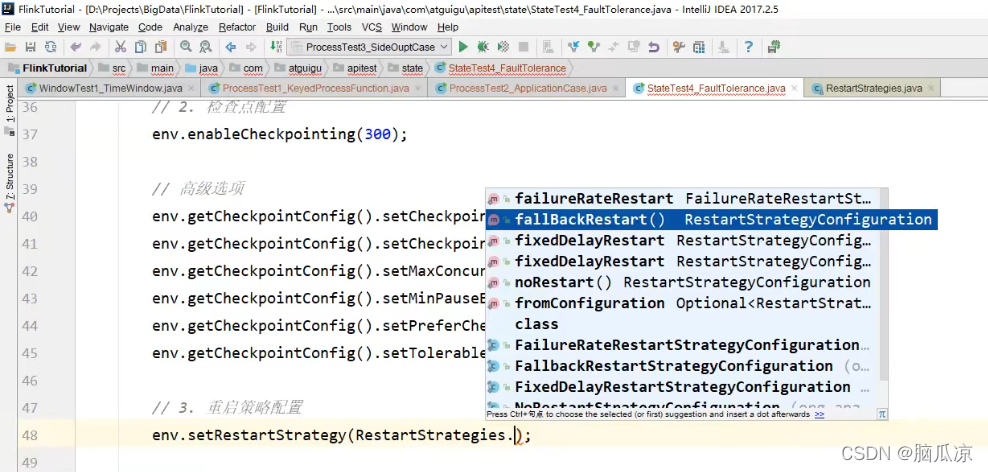
然后再看,这里
fallBackRestart是回滚,什么意思?
就是这里不做设置,如果出错,就把重启权限,交给,比如k8s,集群他们定义的重启策略.
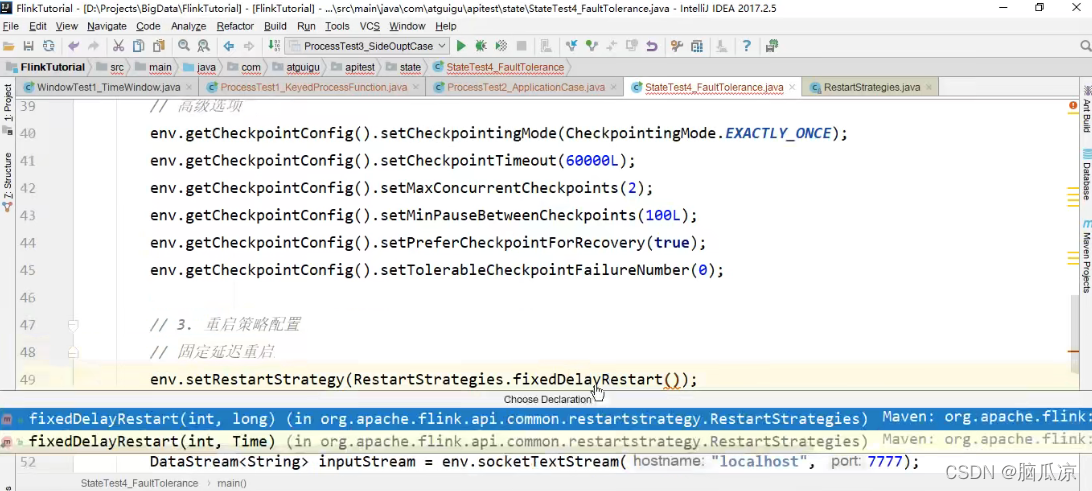
然后再看这里有个fixedDelayRestart()
固定延迟时间重启
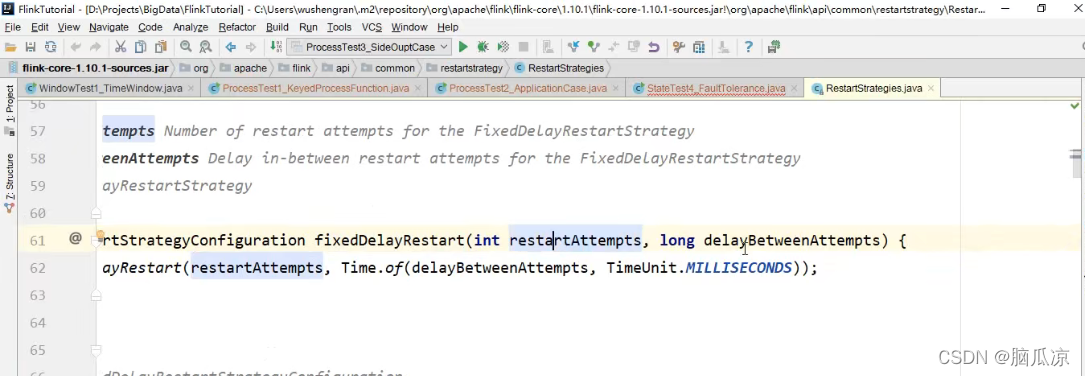
可以看到这里,有2个参数,一个是int,重启次数,一个是
delayBetweenAttempts 两次重启之间的间隔时间.
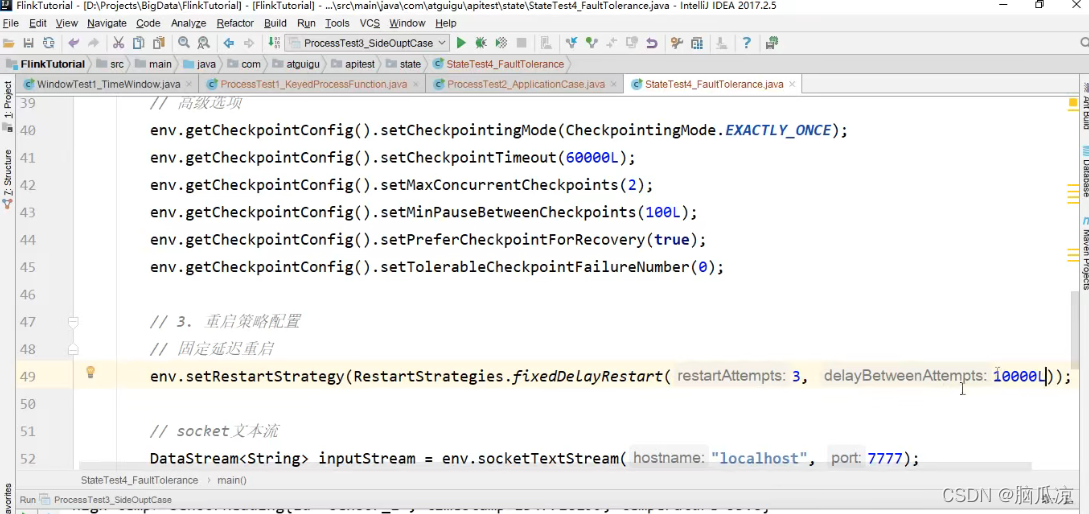
可以看到上面我们设置了,尝试3次重启,并且每次重启,隔10秒再启动下一次重启
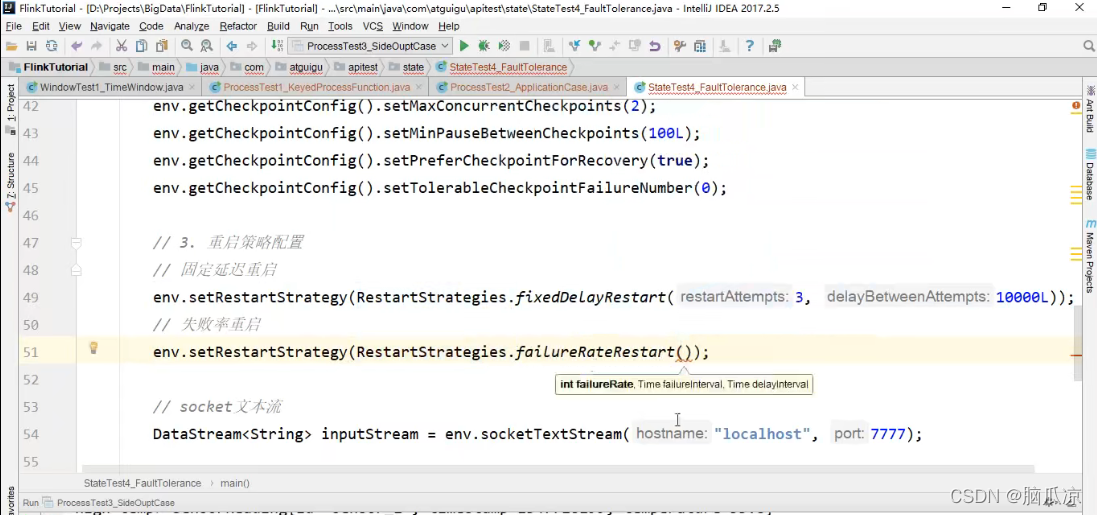
然后我们再看这里还有个
failureRateRestart是失败率重启
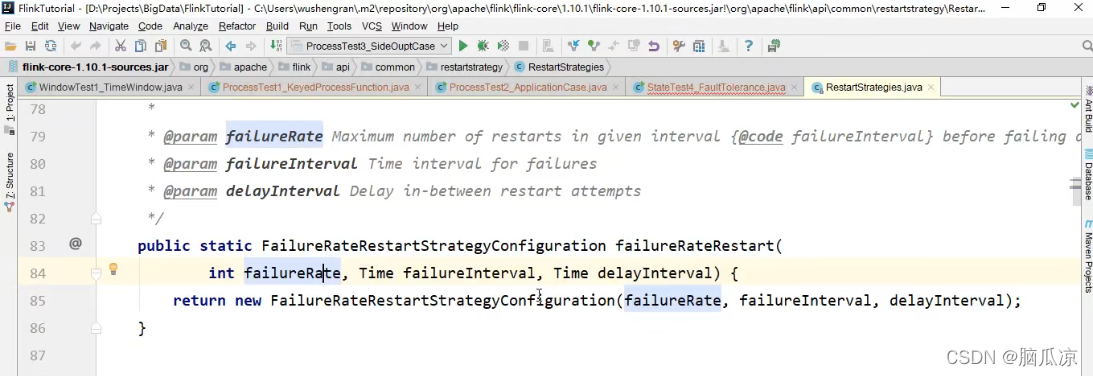
可以看到有3个参数,第一个是失败率,失败次数,第二个是设置一个时间,在这个时间内的失败次数是failureRate次,
然后最后一个参数是,失败一次以后,间隔多久再进行下一次重启.
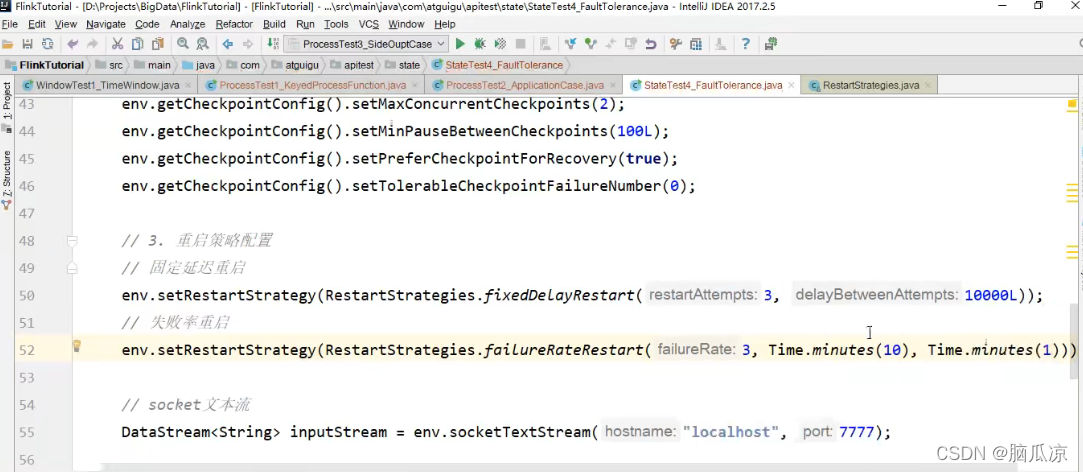
然后再看上面,这里,10分钟,以内尝试3次重启,然后每次重启以后1分钟,再尝试下一次重启.

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)