Pandas数据分析系列9-数据透视与行列转换
本文详解了pandas模块中的数据透视表pivot_table函数及使用方法,接下来讲解了stack和unstack 函数如何实现excel 中的行列互转。
·
Pandas 数据透视表
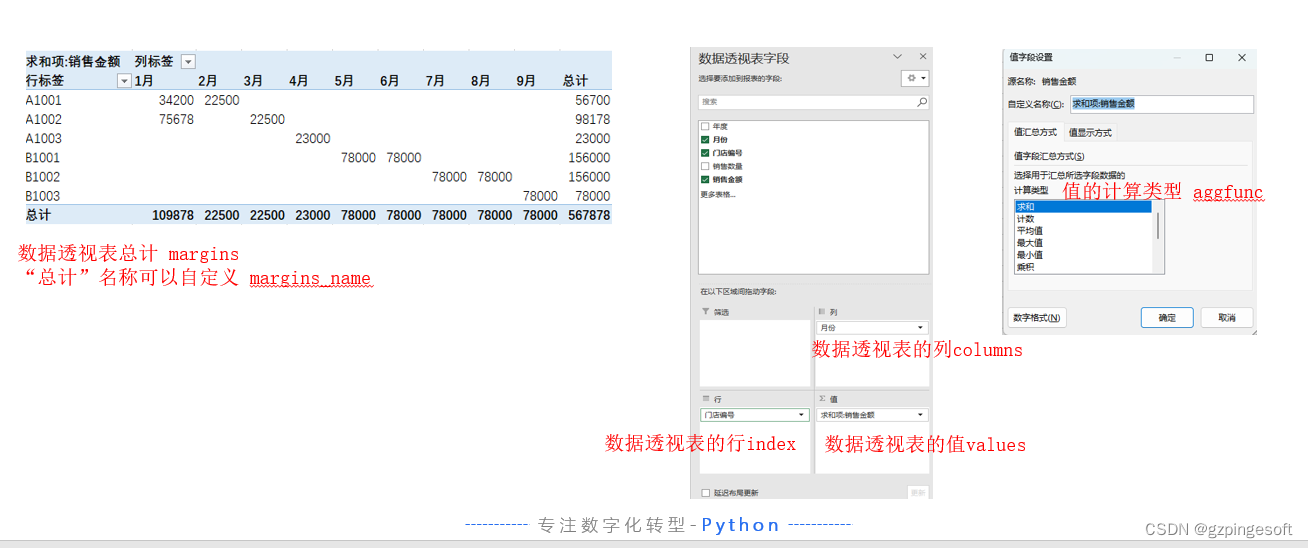
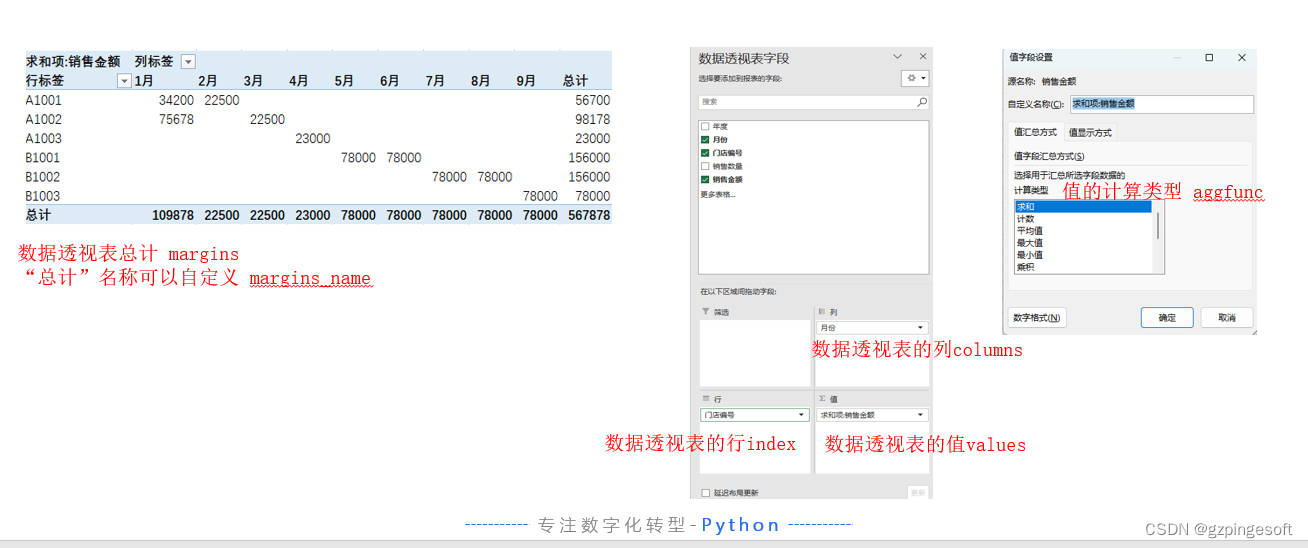
当数据量较大时,为了更好的分析数据特征,通常会采用数据透视表。数据透视表是一种对数据进行汇总和分析的工具,通过重新排列和聚合原始数据,可以快速获得更全面的数据洞察。数据透视表在Excel中也是经常使用的一个强大功能,在Pandas模块,其提供了pivot_table函数,可以快速的实现指定行、列、值和值计算类型(计数、合计、平均等) ,做出一个数据透视表。
在Excel中透视表操作如下:
Pandas 创建数据透视表语法
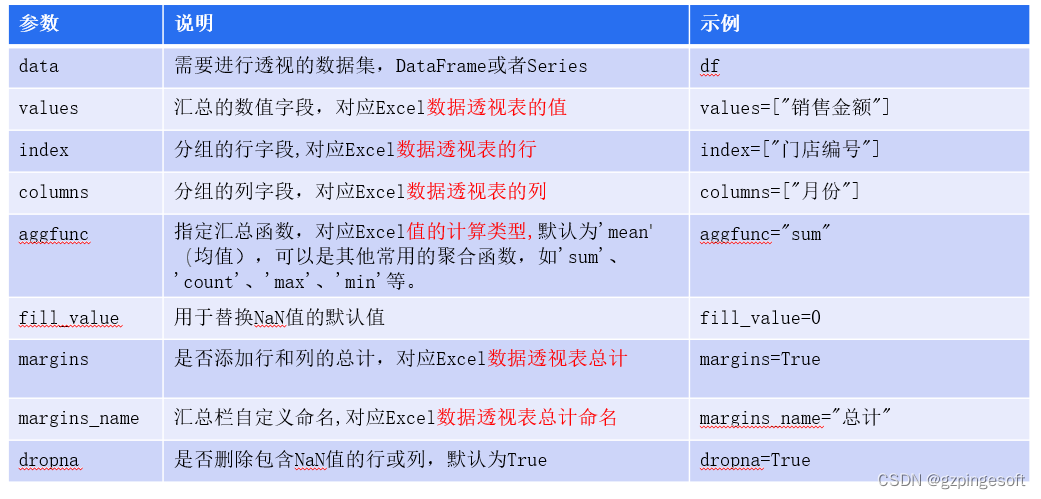
pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None,
margins=False, dropna=True, margins_name=“总计”)参数定义说明:
Pandas pivot_table示例
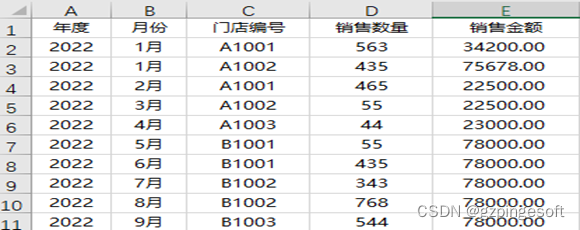
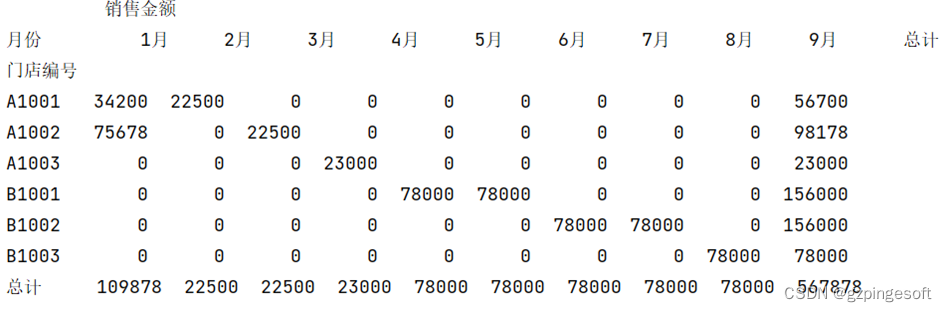
需求描述:对门店销售表,行索引为门店编号,列名称为月份,值为销售金额,进行汇总透视,并将透视结果写入到“门店销售透视”sheet页。
原始数据结构:
代码如下:
df2022=pd.read_excel("门店销售数据.xlsx",sheet_name="销售明细表2022")
pt=pd.pivot_table(df2022,values=["销售金额"],index=["门店编号"],columns=["月份"],aggfunc="sum",margins=True,margins_name="总计",
fill_value=0,dropna=True)
with pd.ExcelWriter('门店销售数据.xlsx', engine='openpyxl', mode='a') as writer:
pt.to_excel(writer, sheet_name='门店销售数据透视表', index=True)
print(pt)
效果图:
Pandas 列转换stack函数
Pandas 透视表pivot_table,实现的的本质上是将普通列的内容转换为索引或列名称,实现各种聚合计算。stack函数类似excel 的列转行,实现dataframe中的column与index 转换。
这些指标都在列上,如果想在行显示?
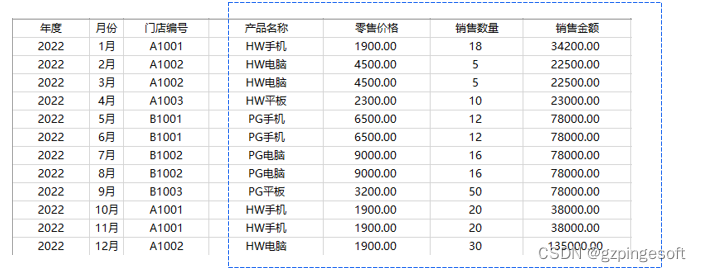
代码如下:
df2022=pd.read_excel("门店销售数据.xlsx",sheet_name="销售明细表2022")
df2022=df2022.set_index(["年度","月份","门店编号"]).stack()
print(df2022)
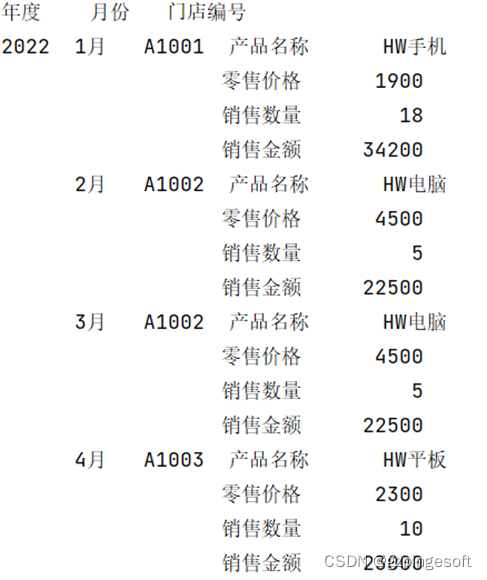
如果需将“年度”,“月份”,“门店编号“ 放在普通列,不做为索引
df2022=df2022.set_index(["年度","月份","门店编号"]).stack().reset_index()
效果图如下:
Pandas 行转换unstack函数
Pandas 透视表pivot_table,实现的的本质上是将普通列的内容转换为索引或列名称,实现各种聚合计算。unstack函数类似excel 的行转列,实现dataframe中的 index与 column转换,是stack函数逆操作。
代码如下:
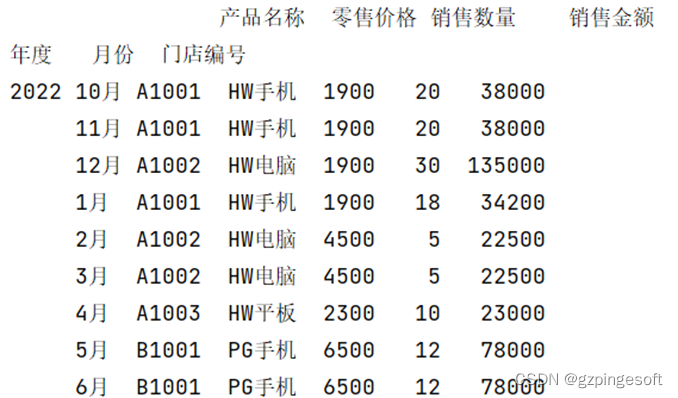
df2022=pd.read_excel("门店销售数据.xlsx",sheet_name="销售明细表2022")
df2022=df2022.set_index(["年度","月份","门店编号"]).stack()
df2022=df2022.unstack()
print(df2022)
效果图如下:

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)