大数据面试题(一)
大数据面试题
大家好,我是练习时长两年半的大数据练习生,喜欢数学,AI,大数据。
写博客是为了总结,分享,自娱自乐。希望写出的东西会对自己,对别人都有价值!
废话不多说,现在是个终身学习的时代,开始学习了!奥力给!干了兄弟们!
是时候展现真正的技术了:👇👇👇😋😋😋
文章目录
-
- 大数据项目流程
- 什么是大数据?
- 大数据有什么特点?
- 大数据能做什么?
- 大数据技术为什么那么快?
- hadoop版本
- hadoop三大公司
- Hadoop的组成部分
- 大数据为啥这么快?
- 怎么理解分布式?
- hadoop 的组成部分? 各自的管理者叫什么? 各自的工作者叫什么?
- HDFS副本存放机制?
- Namenode作用
- DataNode作用
- 什么是机架感知?
- 什么时候会用到机架感知?
- HDFS数据写入流程?
- HDFS数据读取流程?
- HDFS数据完整性如何保证?
- HDFS 特性?
- HDFS缺点?
- 什么时候进入安全模式?
- 安全模式有什么特点?
- 在安全模式下集群在做什么?
- 如何进入/退出安全模式?
- Fsimage 和 Edits 的作用是什么?
- 什么时候会使用Fsimage Edits?
- SecondaryNamenode 的工作机制是什么?
- SecondaryNamenode存在的意义是什么?
- SecondaryNamenode工作的触发因素有哪些?
- 使用SNN的FSimage和Edits还原Namenode流程是什么?
- 集群扩容1 新节点需要做哪些准备?
- 集群扩容2 集群添加一个节点的流程?
- 如何合并小文件?
- 设置 开启权限控制的key是什么?
- 使用java API 在hdfs创建一个全新的目录的过程是?
- HDFS web界面 Overview -Live Nodes之前, Startup Progress, Snapshot , Datanodes
大数据项目流程
数据生产
数据采集
数据存储
需求分析
数据预处理
数据计算
结果数据存储
结果数据展现
什么是大数据?
字面意思理解:大量的数据,海量的数据
数据集的大小已经远远超过了现有普通数据库软件和工具的处理能力的数据
大数据有什么特点?
海量化
数据量大(多)
多样化
结构化数据,半结构化数据,和非结构化数据
快速化
数据的增长速度快
高价值
海量数据价值高
大数据能做什么?
1、海量数据快速查询
2、海量数据的存储(数据量大,单个大文件)
3、海量数据的快速计算(与传统的工具对比)
4、海量数据实时计算(立刻马上)
5、数据挖掘(挖掘以前没有发现的有价值的数据)
大数据技术为什么那么快?
1、传统的是纵向扩展
服务器数量不发生变化,配置越来越高(发生变化)
大数据横向扩展
配置不发生变化,服务器数量越来越多(发生变化)
2 传统的方式资源(cpu/内存/硬盘)集中
大数据方式资源(cpu/内存/硬盘)分布(前提:同等配置的前提下)
3 传统数据备份方式单份备份
大数据数据备份方式多分备份(数据复制,默认三个副本)
4 传统的计算模型是移动数据到程序端
大数据计算模型是移动程序到数据端
io 和网络的使用率都非常低,且多节点存储,多节点计算(众人拾柴火焰高)
hadoop版本
1.0 hadoop指的是HDFS+Mapreduce
2.0 hadoop指的是HDFS+Mapreduce+yarn
hadoop三大公司
免费开源版本apache:http://Hadoop.apache.org/
hortonWorks公司 免费版本 收费版本
Cloudera (CDH) 免费版本 收费版本
Hadoop的组成部分
1、HDFS:海量数据的存储系统
2、Map Reduce:海量数据的计算系统(计算框架)
3、YARN:集群资源管理(调度)的框架。
大数据为啥这么快?
1,扩展性
传统服务器纵向扩展
服务器数量不变,配置增加
大数据服务器横向扩展
服务器配置不变,数量增加
2,分布式
传统服务器数据集中在一台服务器进行计算,数据集中存储到一台服务器
大数据服务器数据分布在不同的服务器,在不同的服务器上同时进行计算
(人多力量大,同等配置下肯定比一个服务器快)
3,可用性
传统服务器只有一份数据。
大数据服务器备份多份数据。
4,模型
传统服务器是把数据移动到程序端计算,数据大时,消耗时间大
大数据服务器是把计算程序移动到存储数据的服务器上,同时计算。
计算程序的大小远小于数据文件大小,所以速度快。
1.一个文件100M,上传到HDFS占用几个快?一个块128M,剩余的28M怎么办?
事实上,128只是个数字,数据超过128M,便进行切分,如果没有超过128M,就不用切分,有多少算多少,不足128M的也是一个快。这个快的大小就是100M,没有剩余28M这个概念。
2.大数据为什么这么快?与传统数据相比有什么不同点?
a.传统数据纵向扩展,服务器数量不发生变化,配置越来越高,大数据横向扩展,配置不发生变化,服务器数量越来越多
b.传统的方式资源(cpu,内存,硬盘)集中,大数据的方式资源分布(相比前提是在同等配置的情况下)
c.传统的数据备份方式单份备份,大数据备份方式多份备份
d.传统的计算模型是移动数据到程序端,大数据计算模型是移动程序到数据段
e.相比之下大数据IO和网络的使用率都非常低,且多节点储存,多节点计算(众人拾柴火焰高)
3.如何验证集群是否可用?请说出两种以上方式
a.jps查看进程
b.namenode所在节点的IP+50070端口查看HDFS的web界面是否可用
c.在HDFS系统中创建一个文件夹或文件,若可以创建则表示集群可以
4.Secondary NameNode在HDFS中是什么作用,他能不能替代NameNode
Secondary NameNode主要作用是辅助namenode管理元数据信息,负责辅助NameNode管理工作。他不能替代NameNode
5.请说出HDFS副本的存放机制
a.第一份数据存放在客户端
b.第二份副本存放的位置与第一份数据在同一机架中,且不再同一节点,按照一定的规则找到一个节点存放
c.第三个副本存放的位置是与第一第二分数据副本不再同一机架上,且逻辑与存放副本1和副本2的逻辑距离最近的机架上,按照一定的规则找到一个节点存放
6.Namenode的作用
a.维护,管理文件系统的名字空间(元数据信息)
b.负责确定指定文件块到具体的DataNode节点的映射关系
c.维护管理DataNode上报的心跳信息
7.请说出你对HDFS文件系统容量的理解
将多个节点上的容量汇总到一起,拼接成一个大的文件系统,在一个节点上传数据,在其他的节点上都能够访问使用
8.hadoop的组成部分有什么?
a.HDFS:海量数据的存储
b.MapReduce:海量数据的计算
c.YARN:资源调度
9.DataNode的作用
负责工作,进行读写数据。 周期向NameNode汇报。
负责管理用户的文件数据块(一个大的数据拆分成多个小的数据块)
10.请说出YARN的管理者,工作者
a.管理者:ResourceManager
b.工作者:NodeManager
怎么理解分布式?
一个业务分拆多个子业务,部署在不同的服务器上(不同的服务器,运行不同的代码,为了同一个目的)
hadoop 的组成部分? 各自的管理者叫什么? 各自的工作者叫什么?
HDFS、mapReduce、Yarn
HDFS管理者Namenode工作者datanode
Yarn管理者ResourceManager 工作者nodeManager
HDFS副本存放机制?
a.第一份数据存放在客户端
b.第二份副本存放的位置与第一份数据在同一机架中,且不再同一节点,按照一定的规则(cpu使用较少 硬盘使用较少 io使用率较少 磁盘剩余容量较多的)找到一个节点存放
c.第三个副本存放的位置是与第一第二分数据副本不再同一机架上,且逻辑与存放副本1和副本2的逻辑距离最近的机架上,按照一定的规则找到一个节点存放
Namenode作用
1.管理HDFS的名字空间(Namespace)
2.确定指定的文件块到具体的Datanode节点的映射关系。
3.管理Datanode节点的健康状态报告和其所在节点上数据块状态报告。
DataNode作用
一:负责数据的读写操作
二:周期性的向NameNode汇报心跳日志/报告
三:执行数据流水线的复制
什么是机架感知?
机架感知可以告诉 Hadoop 集群中哪台机器属于哪个机架
什么时候会用到机架感知?
进行数据存储时会遇到机架感知。
HDFS数据写入流程?
HDFS数据写入流程?
1:Client 发起文件写入请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件,返回是否可以上传;
2:Client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3:NameNode 根据副本数量和副本放置策略进行节点分配,返回DataNode节点,如:A,B,C
4:Client 请求A节点建立pipeline管道,A收到请求会继续调用B,然后B调用C,将整个pipeline管道建立完成,后逐级返回消息到Client;
5:Client收到A返回的消息之后开始往A上传第一个block块,block块被切分成64K的packet包不断的在pepiline管道里传递,从A到B,B到C进行复制存储
6:当一个 block块 传输完成之后,Client 再次请求 NameNode 上传第二个block块的存储节点,不断往复存储
7.当所有block块传输完成之后,Client调用FSDataOutputSteam的close方法关闭输出流,最后调用FileSystem的complete方法告知NameNode数据写入成功
HDFS数据读取流程?
1:Client 发起文件读取请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件,来确定请求文件 block块的位置信息
2:NameNode会视情况返回文件的部分或者全部block块列表,对于每个block块,NameNode 都会返回含有该 block副本的 DataNode 地址
3:这些返回的 DataNode 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
4:Client 选取排序靠前的 DataNode 调用FSDataInputSteam的read方法来读取 block块数据,如果客户端本身就是DataNode,那么将从本地直接获取block块数据
5:当读完一批的 block块后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表,继续读取
6.所有block块读取完成后,Client调用FSDataInputStream.close()方法,关闭输入流,并将读取来所有的 block块合并成一个完整的最终文件
HDFS数据完整性如何保证?
当DataNode读取block的时候,它会计算checksum,如果计算后的checksum,与block创建时(第一次上传是会计算checksum值)值不一样,说明block已经损坏,则client读取其他DataNode上的block.
datanode在其文件创建后周期验证checksum
HDFS 特性?
1、海量数据存储: HDFS可横向扩展,其存储的文件可以支持PB级别或更高级别的数据存储。
2、高容错性:数据保存多个副本,副本丢失后自动恢复。可构建在廉价的机器上,实现线性扩展。当集群增加新节点之后,namenode也可以感知,进行负载均衡,将数据分发和备份数据均衡到新的节点上。
3、商用硬件:Hadoop并不需要运行在昂贵且高可靠的硬件上。它是设计运行在商用硬件(廉价商业硬件)的集群上的。
4、大文件存储:HDFS采用数据块的方式存储数据,将数据物理切分成多个小的数据块。所以再大的数据,切分后,大数据变成了很多小数据。用户读取时,重新将多个小数据块拼接起来。
HDFS缺点?
1、不能做到低延迟数据访问:由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟访问数据的业务需求不适合HDFS。
2、不适合大量的小文件存储 :由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量。根据经验,每个文件、目录和数据块的存储信息大约占150字节。因此,如果有一百万个小文件,每个小文件都会占一个数据块,那至少需要300MB内存。如果是上亿级别的,就会超出当前硬件的能力。
3、修改文件:HDFS适合一次写入,多次读取的场景。对于上传到HDFS上的文件,不支持修改文件。Hadoop2.0虽然支持了文件的追加功能,但不建议对HDFS上的文件进行修改。因为效率低下.
4、不支持用户的并行写:同一时间内,只能有一个用户对同一个文件执行写操作。
什么时候进入安全模式?
集群启动时默认进入安全模式30秒
通过命令启动时进入
一定数量节点丢失后,进入安全模式
安全模式有什么特点?
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。
如果HDFS处于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求)。
在安全模式下集群在做什么?
在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。
如何进入/退出安全模式?
hdfs dfsadmin -safemode enter
# 进入安全模式
hdfs dfsadmin -safemode leave
# 离开安全模式
重启集群后自动进入安全模式30秒
Fsimage 和 Edits 的作用是什么?
fsimage保存了最新的元数据检查点,在HDFS启动时加载fsimage的信息,包含了整个HDFS文件系统的所有目录和文件的信息。
对于文件来说包括了数据块描述信息、修改时间、访问时间等。
对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
Fsimage,editlog主要用于在集群启动时将集群的状态恢复到关闭前的状态。
什么时候会使用Fsimage Edits?
集群启动时,集群运行时
SecondaryNamenode辅助Namenode工作时
SecondaryNamenode 的工作机制是什么?
1、 secnonaryNN通知NameNode切换editlog
2、secondaryNN从NameNode中获得FSImage和editlog(通过http方式)
3、secondaryNN将FSImage载入内存,然后开始合并editlog,合并之后成为新的fsimage
4、secondaryNN将新的fsimage发回给NameNode
5、NameNode用新的fsimage替换旧的fsimage
SecondaryNamenode存在的意义是什么?
由于editlog记录了集群运行期间所有对HDFS的相关操作,所以这个文件会很大,而集群关闭后再次启动时会将Fsimage,editlog加载到内存中,进行合并,恢复到集群的上一次关机时状态。
由于editlog文件很大所有,集群再次启动时会花费较长时间。为了加快集群的启动时间,所以使用secondarynameNode辅助NameNode合并Fsimage,editlog。
SecondaryNamenode工作的触发因素有哪些?
fsimage与edits的合并时机取决于两个参数,第一个参数是默认1小时fsimage与edits合并一次。
第二个参数是hdfs操作次数达到1000000 也会触发合并
第一个参数:时间达到一个小时fsimage与edits就会进行合并(每过一个小时)
dfs.namenode.checkpoint.period :3600
第二个参数:hdfs操作达到1000000次也会进行合并(操作达到100万次)
dfs.namenode.checkpoint.txns :1000000
还有一个参数是每隔多长时间检查一次hdfs的操作次数(60秒检查一次操作次数)
dfs.namenode.checkpoint.check.period :60
使用SNN的FSimage和Edits还原Namenode流程是什么?
集群扩容1 新节点需要做哪些准备?
第一步:复制或创建一台新的虚拟机出来
将我们纯净的虚拟机(只配置了动态网络的虚拟机)复制一台出来,作为我们新的节点
第二步:修改mac地址以及IP地址
修改onboot=yes,修改mac地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
第三步:关闭防火墙,关闭selinux
关闭防火墙、开机不自启防火墙
service iptables stop
chkconfig iptables off
关闭selinux
vim /etc/selinux/config
第四步:更改主机名(hadoop04)
更改主机名命令
vim /etc/sysconfig/network
第五步:四台机器更改主机名与IP地址映射
四台机器都要修改hosts文件
vim /etc/hosts
192.168.100.201 hadoop01.Hadoop.com hadoop01
192.168.100.202 hadoop02.Hadoop.com hadoop02
192.168.100.203 hadoop03.Hadoop.com hadoop03
192.168.100.204 hadoop04.Hadoop.com hadoop04
第六步:hadoop04服务器关机重启并生成公钥与私钥
hadoop04执行以下命令关机重启
reboot
hadoop04执行以下命令生成公钥与私钥
ssh-keygen -t rsa
hadoop04执行以下命令将hadoop04的私钥拷贝到hadoop01服务器
ssh-copy-id hadoop01
hadoop01执行以下命令,将authorized_keys拷贝给hadoop04
cd /root/.ssh/
scp authorized_keys hadoop04:$PWD
第七步:hadoop04安装jdk
hadoop04统一两个路径
mkdir -p /export/softwares/
mkdir -p /export/servers/
然后解压jdk安装包,配置环境变量,或将集群中的java安装目录拷贝一份,并配置环境变量。
第八步:解压Hadoop安装包
hadoop01执行以下命令将Hadoop安装包拷贝到hadoop04服务器
cd /export/softwares/
scp hadoop-2.6.0-cdh5.14.0-自己编译后的版本.tar.gz hadoop04:$PWD
在hadoop04服务器上面解压Hadoop安装包到/export/servers
第九步:将hadoop01关于Hadoop的配置文件全部拷贝到hadoop04
hadoop01执行以下命令,将Hadoop的配置文件全部拷贝到hadoop04服务器上面
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/
scp ./* hadoop04:$PWD
集群扩容2 集群添加一个节点的流程?
第一步:创建dfs.hosts文件
在hadoop01也就是namenode所在的机器的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下创建dfs.hosts文件
[root@hadoop01 Hadoop]# cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
[root@hadoop01 Hadoop]# touch dfs.hosts
[root@hadoop01 Hadoop]# vim dfs.hosts
添加如下主机名称(包含新服役的节点)
hadoop01
hadoop02
hadoop03
hadoop04
第二步:hadoop01编辑hdfs-site.xml添加以下配置
在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
hadoop01执行以下命令
cd /export/servers/Hadoop-2.6.0-cdh5.14.0/etc/Hadoop
vim hdfs-site.xml
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
第三步:刷新namenode
hadoop01执行以下命令刷新namenode
hdfs dfsadmin -refreshNodes
第四步:更新resourceManager节点
hadoop01执行以下命令刷新resourceManager
yarn rmadmin -refreshNodes
第五步:namenode的slaves文件增加新服务节点主机名称
hadoop01编辑slaves文件,并添加新增节点的主机,更改完后,slaves文件不需要分发到其他机器上面去
hadoop01执行以下命令编辑slaves文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/Hadoop
vim slaves
hadoop01
hadoop02
hadoop03
hadoop04
第六步:单独启动新增节点
hadoop04服务器执行以下命令,启动datanode和nodemanager
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/hadoop-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
第七步:浏览器查看
(windows上需要起别名192.168.100.201起别名hadoop01)
http://hadoop01:50070/dfshealth.html#tab-overview
http://hadoop01:8088/cluster
第八步:使用负载均衡命令,让数据均匀负载所有机器
hadoop01执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
如何合并小文件?
hdfs dfs -getmerge /config/*.xml ./hello.xml
设置 开启权限控制的key是什么?
(直接说:dfs.permissions)
首先停止hdfs集群,在hadoop01机器上执行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/stop-dfs.sh
修改node01机器上的hdfs-site.xml当中的配置文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
dfs.permissions的value改为true
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
修改完成之后配置文件发送到其他机器上面去
scp hdfs-site.xml hadoop02:$PWD
scp hdfs-site.xml hadoop03:$PWD
重启hdfs集群
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/start-dfs.sh
使用java API 在hdfs创建一个全新的目录的过程是?
创建FileSystem对象
FileSystem fileSystem=FileSystem.get(new URI(“hdfs://192.168.100.201:8020”),conf);
执行创建操作
fileSystem.mkdirs(new Path("/user/new"));
HDFS web界面 Overview -Live Nodes之前, Startup Progress, Snapshot , Datanodes
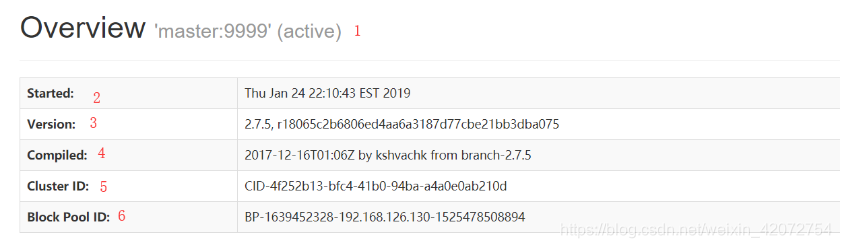
第1处的master:9999表示当前HDFS集群的基本路径。这个值是从配置core-site.xml中的fs.defaultFS获取到的。
第2处的Started表示集群启动的时间
第3处的Version表示我们使用的Hadoop的版本,我们使用的是2.7.5的Hadoop
第4处的Compiled表示Hadoop的安装包(hadoop-2.7.5.tar.gz)编译打包的时间,以及编译的作者等信息
第5处的Cluster ID表示当前HDFS集群的唯一ID
第6处的Block Pool ID表示当前HDFS的当前的NameNode的ID,我们知道通过HDFS Federation (联盟)的配置,我们可以为一个HDFS集群配置多个NameNode,每一个NameNode都会分配一个Block Pool ID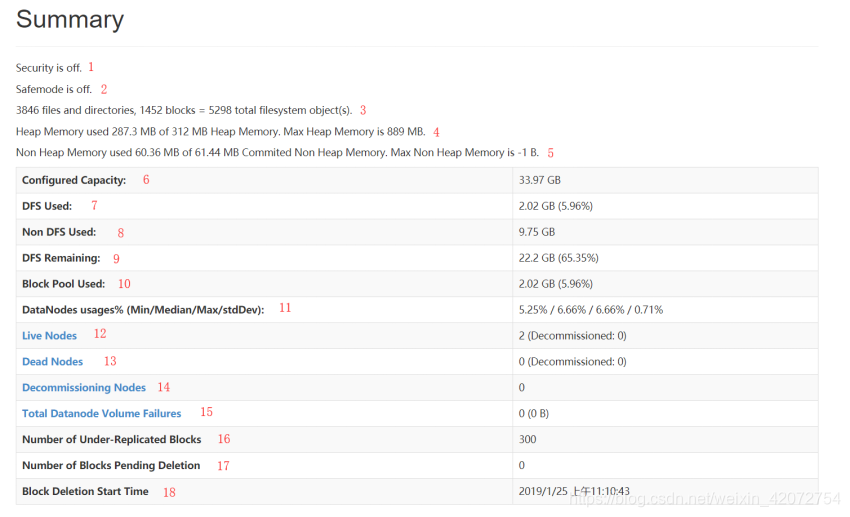
第1处的Security is off表示当前的HDFS集群没有启动安全机制
第2处的Safemode is off表示当前的HDFS集群不在安全模式,如果显示的是Safemode is on的话,则表示集群处于安全模式,那么这个时候的HDFS集群是不能用的
第3处表示当前HDFS集群包含了3846个文件或者目录,以及1452个数据块,那么在NameNode的内存中肯定有3846 + 1452 = 5298个文件系统的对象存在
第4处表示NameNode的堆内存(Heap Memory)是312MB,已经使用了287.3MB,堆内存最大为889MB
第5处表示NameNode的非堆内存的使用情况,有效的非堆内存是61.44MB,已经使用了60.36MB。没有限制最大的非堆内存,但是非堆内存加上堆内存不能大于虚拟机申请的最大内存(默认是1000M)
第6处的Configured Capacity表示当前HDFS集群的磁盘总容量。这个值是通过:Total Disk Space - Reserved Space计算出来的。Total Disk Space表示所在机器所在磁盘的总大小,而Reserved Space表示一个预留给操作系统层面操作的空间。Reserved space空间可以通过dfs.datanode.du.reserved(默认值是0)在hdfs-site.xml文件中进行配置。我们这边的总容量为什么是:33.97GB呢,我们可以通过du -h看一下两个slave的磁盘使用情况,如下: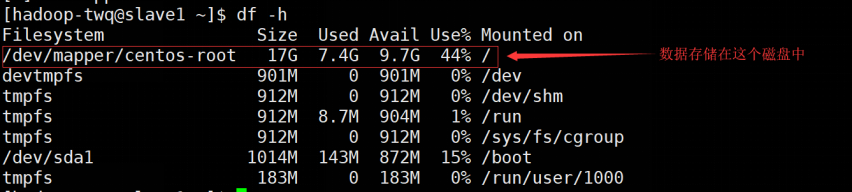
上面 17GB + 17GB = 34GB,而且我们没有配置Reserved Space,所以HDFS总容量就是33.97GB(有一点点的误差可以忽略)
第7处DFS Used表示HDFS已经使用的磁盘容量,说白了就是HDFS文件系统上文件的总大小(包含了每一个数据块的副本的大小)
第8处Non DFS Used表示在任何DataNodes节点上,不在配置的dfs.datanode.data.dir里面的数据所占的磁盘容量。其实就是非HDFS文件占用的磁盘容量
配置dfs.datanode.data.dir就是DataNode数据存储的文件目录
第9处DFS Remaining = Configured Capacity - DFS Used - Non DFS Used。这是HDFS上实际可以使用的总容量
第10处Block Pool Used表示当前的Block Pool使用的磁盘容量
第11处DataNodes usages%表示所有的DataNode的磁盘使用情况(最小/平均/最大/方差)
Datanode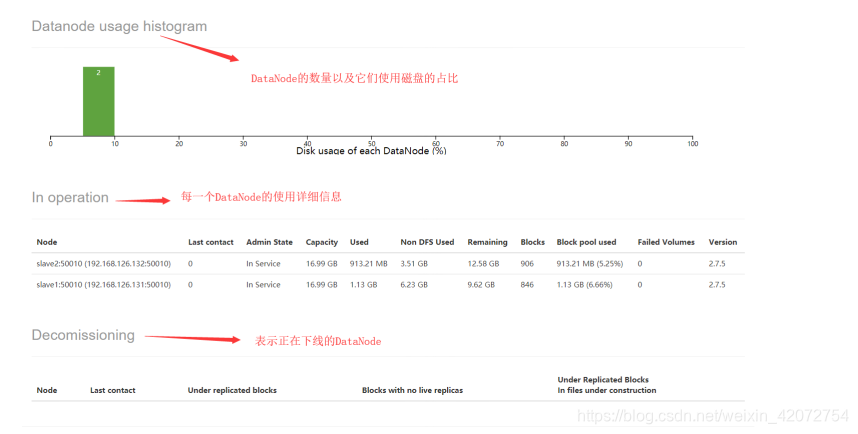
上面有一个Admin State我们有必要说明下,Admin State可以取如下的值:
1.In Service,表示这个DataNode正常
2.Decommission In Progress,表示这个DataNode正在下线
3.Decommissioned,表示这个DataNode已经下线
4.Entering Maintenance,表示这个DataNode正进入维护状态
5.In Maintenance,表示这个DataNode已经在维护状态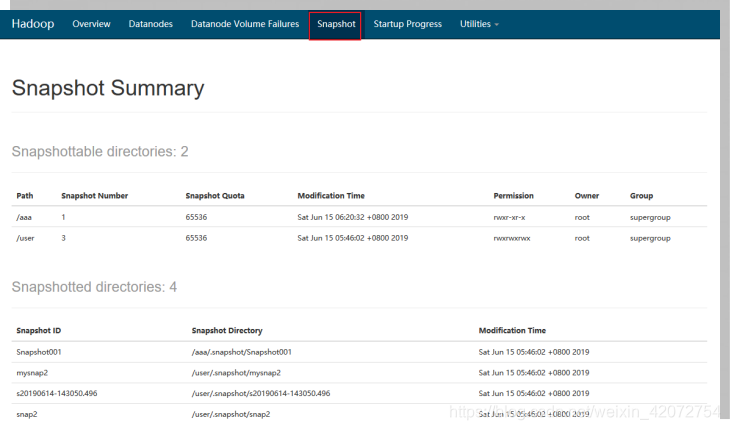
Snapshot Summary:快照摘要
Snapshottable directories : 快照目录列表:2
Snapshotted directories: 已创建的快照目录:4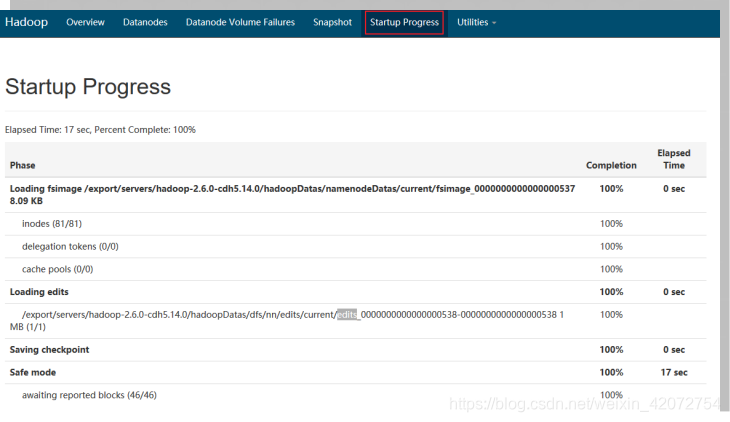
Startup Progress:集群启动时加载的fsimage和edits
启动时加载的fsimage: fsimage_0000000000000000537
启动时加载的edits:edits_0000000000000000538-0000000000000000538
怎么理解分布式?
分散
拆分
hadoop 的组成部分
HDFS 分布式文件存储系统
管理者:NameNode
工作者:DataNode
辅助者:SecondayNameNode
MapReduce 分布式离线计算框架
Yarn Hadoop资源调度器
管理者:ResourceManager
工作者:NodeManager
HDFS副本存放机制
第1个副本存放在客户端,如果客户端不在集群内,就在集群内随机挑选一个合适的节点进行存放;
第2个副本存放在与第1个副本同机架且不同节点,按照一定的规则挑选一个合适的节点进行存放;
第3个副本存放在与第1、2个副本不同机架且距第1个副本逻辑距离最短的机架,按照一定的规则挑选一个合适的节点进行存放;
Namenode作用
一:管理,维护文件系统的元数据/名字空间/目录树 管理数据与节点之间的映射关系(管理文件系统中每个文件/目录的block块信息),
二:管理DataNode汇报的心跳日志/报告
三:客户端和DataNode之间的桥梁(元数据信息共享)
DataNode作用
一:负责数据的读写操作
二:周期性的向NameNode汇报心跳日志/报告
三:执行数据流水线的复制
什么是机架感知?
通俗的来说就是nameNode通过读取我们的配置来配置各个节点所在的机架信息
什么时候会用到机架感知?
NameNode分配节点的时候 (数据的流水线复制和HDFS复制副本时)
HDFS数据写入流程?
1:Client 发起文件写入请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件,返回是否可以上传;
2:Client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3:NameNode 根据副本数量和副本放置策略进行节点分配,返回DataNode节点,如:A,B,C
4:Client 请求A节点建立pipeline管道,A收到请求会继续调用B,然后B调用C,将整个pipeline管道建立完成,后逐级返回消息到Client;
5:Client收到A返回的消息之后开始往A上传第一个block块,block块被切分成64K的packet包不断的在pepiline管道里传递,从A到B,B到C进行复制存储
6:当一个 block块 传输完成之后,Client 再次请求 NameNode 上传第二个block块的存储节点,不断往复存储
7.当所有block块传输完成之后,Client调用FSDataOutputSteam的close方法关闭输出流,最后调用FileSystem的complete方法告知NameNode数据写入成功
HDFS数据读取流程?
1:Client 发起文件读取请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件,来确定请求文件 block块的位置信息
2:NameNode会视情况返回文件的部分或者全部block块列表,对于每个block块,NameNode 都会返回含有该 block副本的 DataNode 地址
3:这些返回的 DataNode 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
4:Client 选取排序靠前的 DataNode 调用FSDataInputSteam的read方法来读取 block块数据,如果客户端本身就是DataNode,那么将从本地直接获取block块数据
5:当读完一批的 block块后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表,继续读取
6.所有block块读取完成后,Client调用FSDataInputStream.close()方法,关闭输入流,并将读取来所有的 block块合并成一个完整的最终文件
HDFS数据完整性如何保证?
数据写入完毕以后进行校验
数据读取之前进行校验
对比判断是否有数据丢失
NameNode会周期性的通过DataNode汇报的心跳信息中获取block块的校验和进行检查数据完整性,如果发现校验和不一致,会从其他副本节点复制数据进行恢复,从而保证数据的完整性
HDFS 特性?(适用场景:一次写入,多次读取)
1、海量数据存储
2、大文件存储
3.高容错性
a.数据自动保存多个副本;通过增加副本的形式,提高容错性
b.某一个副本丢失以后,可以自动恢复,这是由 HDFS 内部机制实现的
HDFS缺点?
1.不擅长低延时数据访问
由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟访问数据的业务需求不适合HDFS。
2.不擅长大量小文件存储
存储大量小文件的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
3.不支持多用户并发写入一个文本
同一时间内,只能有一个用户执行写操作
4.不支持文件随机修改(多次写入,一次读取)
仅支持数据末尾 append(追加),不支持文件的随机修改。
什么时候进入安全模式?
在集群重启(二次启动)的时候
人为进入
安全模式有什么特点?
安全模式中只能读取数据,不能修改数据(增、删、改)
在安全模式下集群在做什么?
在安全模式下集群在进行恢复元数据,即在合并fsimage和edits log,并且接受datanode的心跳信息,
恢复block的位置信息,将集群恢复到上次关机前的状态
如何进入/退出安全模式?
进入:hdfs dfsadmin -safemode enter
退出:hdfs dfsadmin -safemode leave
Fsimage 和 Edits 的作用是什么?
fsimage存储的是系统最近一次关机前的集群镜像,
edits是客户端对HDFS文件系统的所有操作日志
恢复集群到上次关机前的状态
什么时候会使用Fsimage Edits?
1.在集群二次启动时,会使用fsimage和edits合并进行恢复元数据
2.SecondayNameNode周期性的拉取fsimage和edits进行合并生成新的fsimage
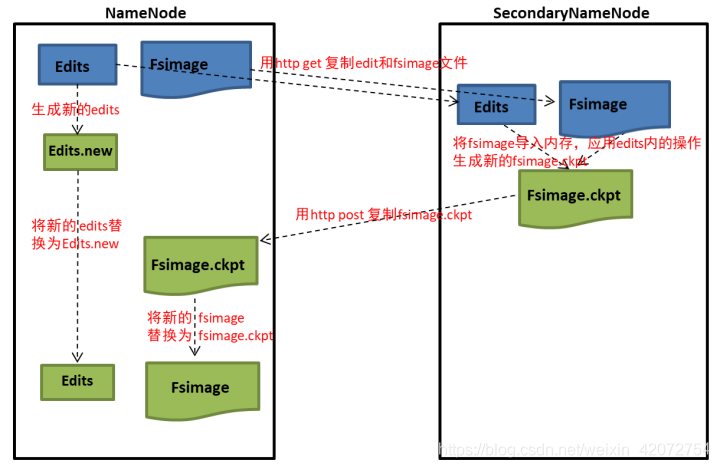
SecondaryNamenode 的工作机制是什么?
NameNode创建一个Edits.new
SNN从NameNode节点拷贝Fsimage和Edits文件到SNN---->SNN将两个文件导入内存进行合并操作生成一个新的Fsimage.ckpt文件----->
SNN将新的Fsimage.ckpt发送到NameNode节点----->重命名为Fsimage替换原先的Fsimage---------->原先的Edits生成Edits.new文件--->
将Edits替换为新的Edits.new
SecondaryNamenode存在的意义是什么?
一:进行Fsimage和Edits的合并操作,减少edits日志大小,加快集群的启动速度
二:将Fsimage与Edits进行备份,防止丢失
SecondaryNamenode工作的触发因素有哪些?
1.时间维度,默认一小时触发一次 dfs.namenode.checkpoint.period :3600
2.次数维度,默认100万次触发一次 dfs.namenode.checkpoint.txns : 1000000
3、六十秒判断一次是否达到100W
使用SNN的FSimage和Edits还原Namenode流程是什么?
进入到SNN的数据存储文件夹----->将最新版本的Fsimage以及Edits拷贝至nameNode节点,放在NN节点相应的配置目录下----->重启集群
集群扩容1 新节点需要做哪些准备?
1.配置JDK
2.配置SSH免密钥
3.关闭防火墙
4.关闭selinux
5.修改主机名
6.修改hosts
集群扩容2 集群添加一个节点的流程?
* 在配置文件目录添加dfs.hosts白名单文件,文件中加入包括新增节点在内的所有节点
* 在hdfs.site.xml中配置白名单文件生效
<property>
<name>dfs.hosts</name>
<value>/export/install/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
* 配置slaves文件,将新增节点加入
* 刷新hdfs和yarn
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
* 新节点开启相应服务
浏览WEB界面
如何合并小文件?
HDFS -> local :hadoop fs -getmerge 小文件目录 下载的目录
local -> HDFS : 遍历所有的已有小文件追加到一个文件中,再上传(文件不在HDFS)
设置 开启权限控制的key是什么?
dfs.permissions
使用java API 在hdfs创建一个全新的目录的过程是?
//实例Configuration
Configuration configuration = new Configuration();
//实例文件系统
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.100.88:8082"),configuration);
//使用文件系统对象调用mkdirs(相应的API )
boolean mkdirs = fileSystem.mkdirs(new Path("目录路径"));
HDFS web界面(两个问题)
Overview -Live Nodes之前,
Startup Progress,
Snapshot ,
Datanodes
😆小伙伴们!相信看到这里的你一定有所收获!
😂如果我哪里写错欢迎评论区来喷😂😂😂
😘如果觉得对你有帮助请给个赞哦亲!🤞🤞🤞🤞🤞🤞
🤞🤞🤞最后引用名言一句:我们无论遇到什么困难,都不要怕,微笑着面对它!消除恐惧的最好办法就是面对恐惧!加油!奥力给!

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)