
Python数据分析(1):NumPy与pandas基础,数据加载与存储
本系列是对Python for Data Analysis第三版的整理,个人目的仅是进一步熟悉Python以及学习NumPy、pandas等库。
本系列是对Python for Data Analysis第三版的整理,个人目的仅是进一步熟悉Python以及学习NumPy、pandas等库。
忽略了原书的大部分API介绍,仅保留了部分基础API。
作者提供了在线电子版https://wesmckinney.com/book,以及相关代码https://github.com/wesm/pydata-book。不适应英文原文的可以选择有中文翻译的第二版https://www.jianshu.com/p/04d180d90a3f,或者纸质书《利用Python进行数据分析》。
第1章 准备工作
1.1 基本的Python库
NumPy一直以来是Python中数值计算的基石,提供了该领域大部分的数据结构、算法和胶水库。pandas提供高级数据结构与功能,针对结构化或表格数据。matplotlib是用于数据可视化的最流行的 Python 库。
IPython是交互式Python解释器;Jupyter基于前者,是一个针对交互式与探索性计算的高效环境。本书提供的示例代码全部使用Jupyter。
SciPy 是解决科学计算中许多基本问题的软件包集合。scikit-learn是通用机器学习工具包。statsmodels是一个统计分析包,包含经典统计和计量经济学的算法。
1.2 安装与设置
Python、conda的安装不再赘述。
Jupyter的安装与自动格式化,需要首先(创建并进入conda环境)在命令行下输入以下命令,然后在弹出的网页中找到Setting-Advanced Setting Editor-Jupyterlab Code Formatter,选中Auto format config。
pip install black jupyterlab jupyterlab-code-formatter jupyterlab-spellcheckerjupyter lab
第2章与第3章主要介绍Python基础语法、内置数据结构等,这里直接跳过。如果对Python基础语法不太熟悉的可以看网上各类教程,例如https://www.liaoxuefeng.com/wiki/1016959663602400,以及本公众号之前的Effective Python系列。
第4章 NumPy基础:数组和矢量化计算
之所以不用Python内置数据结构,而用NumPy这样的数值计算包,很大程度是因为:NumPy基于C,计算速度比纯Python代码更快;NumPy的数组操作是在连续的内存块中进行的,而内置数据结构有额外的开销。
NumPy的核心特性之一是多维数组ndarray。
import numpy as np# 创建ndarraydata = np.array([[1.5, -0.1, 3], [0, -3, 6.5]])assert data.ndim == 2assert data.shape == (2, 3)# 常用工厂函数data = np.arange(10)data = np.zeros((2, 3, 2))# 数据类型dtypearr = np.array([1, 2, 3, 4, 5])assert arr.dtype == np.int32float_arr = arr.astype(np.float64)
元素级操作:
arr * arr1 / arrarr**2z = np.sqrt(xs ** 2 + ys ** 2)arr = np.exp(arr)arr = np.maximum(x, y)arr = np.where(arr > 0, arr * 2, -2)
保存与读取:
arr = np.arange(10)np.save("some_array", arr)np.load("some_array.npy")np.savez("array_archive.npz", a=arr, b=arr)
线性代数:
# 转置arr.T# 点乘x.dot(y)np.dot(x, y)x @ np.ones(3)# 逆矩阵from numpy.linalg import inv, qrinv(arr)
最后,以模拟随机运动为例:
# 随机数生成器rng = np.random.default_rng(seed=12345)# 生成1000个1、-1draws = rng.integers(0, 2, size=1000)steps = np.where(draws == 0, 1, -1)# 模拟结果walk = steps.cumsum()walk.min()walk.max()
第5章 pandas入门
Series是一维数组对象,包含一系列索引与数据。
import numpy as npimport pandas as pdfrom pandas import Seriesobj = pd.Series([4, 7, -5, 3], index=["d", "b", "a", "c"])print(obj.array)print(obj.index)print(obj.to_dict())assert obj["d"] == 4
DataFrame代表一个矩形数据表,可以看作存储着索引相同的Series的字典。
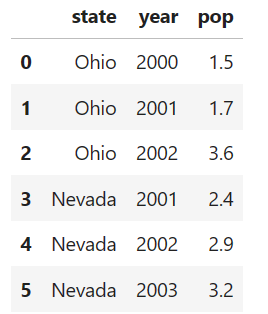
from pandas import DataFramedata = {"state": ["Ohio", "Ohio", "Ohio", "Nevada", "Nevada", "Nevada"],"year": [2000, 2001, 2002, 2001, 2002, 2003],"pop": [1.5, 1.7, 3.6, 2.4, 2.9, 3.2],}frame = pd.DataFrame(data)assert "state" in frame.columnsassert 0 in frame.index# 查询列frame["state"]frame.year# 查询行frame2.loc[1]frame2.iloc[2]# 删除列del frame["frame"]
与ndarray类似,Series与DataFrame同样支持各种基础操作以及数学与统计方法。这里不再一一介绍了,后文实际例子中遇到时再逐个讲解;有兴趣的可以自己读pandas文档。
第6章 数据加载、存储和文件格式
pandas中有许多旨在将文本转化为DataFrame对象的函数,例如read_csv、read_excel等等。它们的可选参数包括:索引,类型推断和数据转换,日期和时间解析,迭代,脏数据问题,
首先,以csv文件为例:
# 没有标题行pd.read_csv("examples/ex2.csv", header=None)# 自定义标题行pd.read_csv("examples/ex2.csv", names=["a", "b","message"])# 自定义分隔符,取代默认的逗号result = pd.read_csv("examples/ex3.txt", sep="\s+")# 迭代处理大文件chunker = pd.read_csv("examples/ex6.csv", chunksize=1000)for piece in chunker:...# 写入文件data.to_csv("examples/out.csv")
有时read_csv不足以满足需求,需要手动处理。以下是处理流程的简单示例:
import csvwith open("examples/ex7.csv") as f:lines = list(csv.reader(f))header, values = lines[0], lines[1:]# zip函数同时迭代两个迭代器data_dict = {h: v for h, v in zip(header, zip(*values))}
接下来考虑JSON文件:
import jsonresult = json.loads(obj)asjson = json.dumps(result)data = pd.read_json("examples/example.json")data.to_json(sys.stdout)
其余的二进制文件、xml、html、excel、web api、database基本上全都换汤不换药。这里不再赘述,有需要时再查即可。
第7章 数据清理与准备
在进行数据分析和建模的过程中,大量时间都花在数据准备上。有时,数据存储在文件或数据库中的方式不适合特定任务。pandas提供了一组高级、灵活且快速的工具,能够将数据操作成正确的形式。
首先考虑缺失值的情况:
float_data = pd.Series([1.2, -3.5, np.nan, 0])# 返回一个布尔Series,代表每一项是否是NAfloat_data.isna()float_data.notna()# 去除所有NAfloat_data.dropna()# 将NA替换为其他值float_data.fillna(0)
接下来考虑数据转换:
# 重复data.duplicated()data.drop_duplicates()# 映射def get_animal(x):return ...data["animal"] = data["food"].map(get_animal)# 替换data.replace(-999, np.nan)# 过滤col[col.abs() > 3]
此外,还有一些字符串操作:
val = "a,b, guido"# 以逗号分隔,去除首尾空格pieces = [x.strip() for x in val.split(",")]# 以::连接"::".join(pieces)val.index(",") == 1val.find(":") == -1val.count(",")val.replace(",", "::")# 正则表达式操作这里不再介绍# pandas也有字符串处理data.str[:5]data.str.contains("gmail")pattern = r"([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})"data.str.findall(pattern, flags=re.IGNORECASE)data.str.extract(pattern, flags=re.IGNORECASE)
扩展数据类型、分类数据部分略过。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。


永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)