毕业设计项目----基于 Python+ Django 的 豆瓣图书评论推荐可视化系统
本项目是一个基于的豆瓣图书评论推荐可视化系统。该系统从豆瓣网站爬取图书的评论数据,通过推荐算法生成个性化的图书推荐,并提供一个可视化的界面展示用户的推荐结果。通过该系统,用户可以查看图书信息、评论内容,并得到个性化的书籍推荐。本项目是一个基于 Django 的图书评论推荐系统,能够从豆瓣网站抓取书籍和评论数据,通过推荐算法提供个性化推荐。项目包括数据爬取、推荐算法、用户管理、数据展示和可视化等功能
一、项目概述
1. 项目背景
本项目是一个基于 Python Django 的 豆瓣图书评论推荐可视化系统。该系统从豆瓣网站爬取图书的评论数据,通过推荐算法生成个性化的图书推荐,并提供一个可视化的界面展示用户的推荐结果。通过该系统,用户可以查看图书信息、评论内容,并得到个性化的书籍推荐。
2. 项目目标
- 实现豆瓣图书评论数据的抓取与存储。
- 提供基于用户评论的图书推荐算法。
- 使用 Django 提供 Web 界面展示书籍、评论和推荐结果。
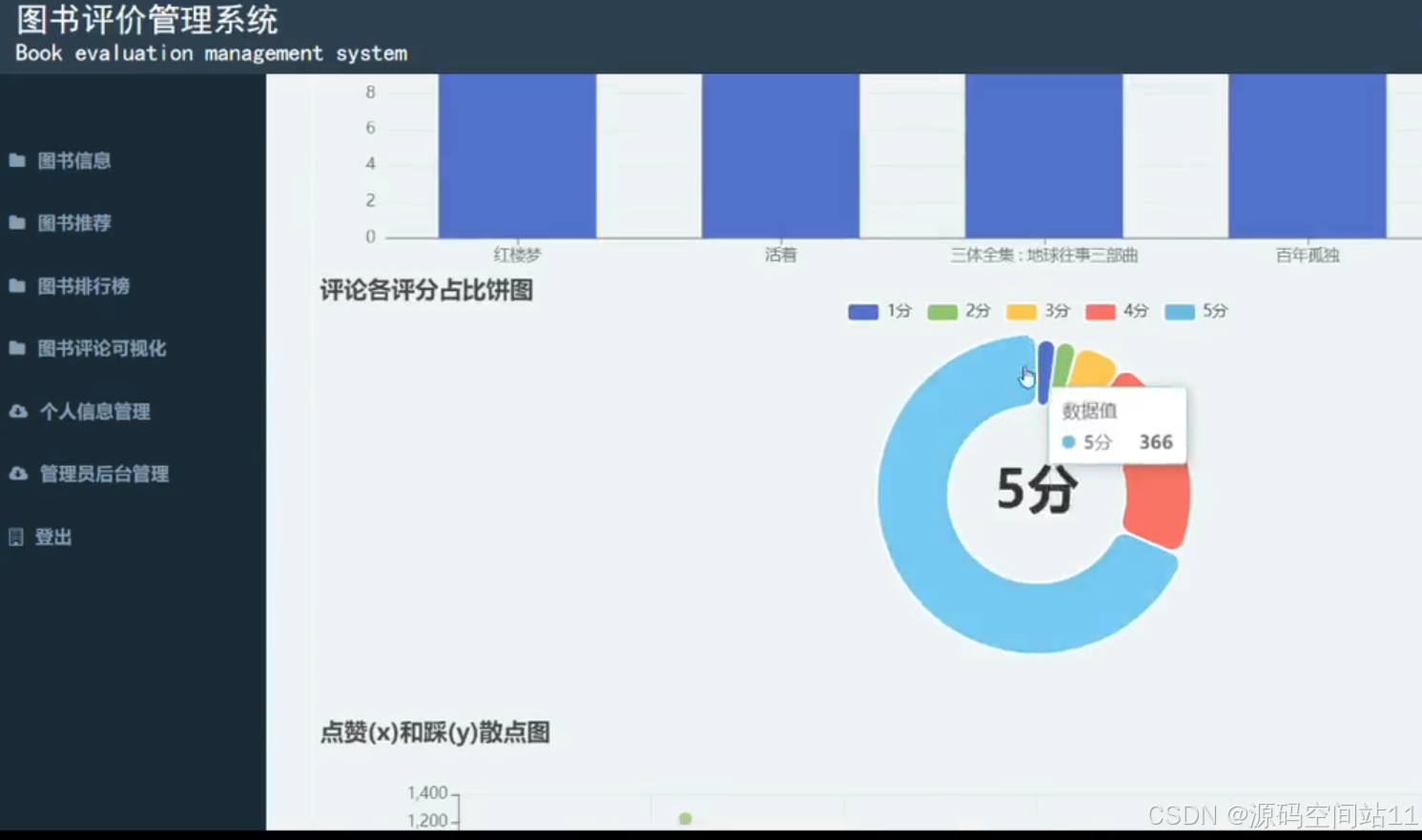
- 提供可视化展示,帮助用户直观了解图书评分和评论。
二、技术栈
- Web 框架:Django
- 前端技术:HTML, CSS, JavaScript, Bootstrap
- 数据库:SQLite / MySQL (通过 Django ORM)
- 推荐算法:基于内容的推荐(Content-based Filtering)
- 数据抓取:爬虫技术(requests, BeautifulSoup)
- 数据可视化:Matplotlib 或 Plotly (可能用于图书评分展示)
- 版本控制:Git
三、功能模块
1. 数据爬取
- 使用 Python 爬虫(requests + BeautifulSoup)从豆瓣网站抓取图书信息、用户评论等数据。
- 该模块的功能包括:
- 抓取图书基本信息:名称、作者、评分等。
- 抓取用户评论内容和评分。
- 将数据存储到数据库中,供推荐系统和用户展示使用。
2. 推荐系统
- 基于用户评论内容和评分的 内容推荐算法。
- 该模块根据用户的历史评分和评论,生成个性化的书籍推荐。
- 基于图书的相似度计算进行推荐。
- 用户可以根据推荐查看不同类别或主题的书籍。
3. 用户管理
- 提供用户注册、登录和管理功能。
- 用户可以保存喜欢的书籍,查看推荐和历史评论。
4. 数据展示与可视化
- 提供图书信息展示页面,展示书籍的名称、作者、评分等信息。
- 提供评论展示页面,显示用户评论和评分。
- 推荐结果页面展示个性化的书籍推荐。
- 可视化图表展示评分统计和评论分析,使用 Matplotlib 或 Plotly。
四、系统架构
1. 项目结构
项目主要由多个 Django 应用(App)组成,每个应用负责不同的功能模块。
豆瓣图书评论推荐系统/ │ ├── manage.py # Django 管理脚本 ├── book/ # 书籍相关应用 │ ├── models.py # 数据库模型定义 │ ├── views.py # 控制器,处理请求 │ ├── templates/ # 书籍信息和评论页面模板 ├── data/ # 存储爬取的图书评论数据 ├── Shop/ # 可能与书店相关的应用 ├── static/ # 存放静态文件(CSS, JS, 图像等) ├── templates/ # 全局模板(如主页模板) ├── db.sqlite3 # SQLite 数据库 └── requirements.txt # 项目依赖库
2. 数据库设计
本项目使用 SQLite 数据库(可以根据需要切换为 MySQL 或 PostgreSQL)。主要的数据表包括:
数据表设计:
- Book 表:存储图书基本信息。
id: 主键,唯一标识图书。title: 图书标题。author: 作者。rating: 图书评分。description: 图书描述。- Review 表:存储用户评论信息。
id: 主键,唯一标识评论。book_id: 外键,关联到Book表。user_id: 外键,关联到User表。content: 评论内容。rating: 用户评分。- User 表:存储用户信息。
id: 主键,唯一标识用户。username: 用户名。email: 邮箱。password: 密码(加密存储)。
五、安装与运行步骤
1. 安装依赖
确保 Python 和 pip 已安装。可以通过以下命令安装项目的依赖:
pip install -r requirements.txt
2. 设置数据库
本项目使用 SQLite 数据库。如果需要使用 MySQL 或 PostgreSQL,可以修改 settings.py 中的数据库配置。
3. 启动 Django 开发服务器
使用以下命令启动 Django 开发服务器:
python manage.py runserver
4. 访问 Web 应用
访问以下 URL,查看图书推荐系统:
- 主页:
http://127.0.0.1:8000/ - 登录页面:
http://127.0.0.1:8000/login/ - 图书推荐页面:
http://127.0.0.1:8000/recommendations/
5. 数据抓取
可以通过以下命令运行爬虫脚本,抓取豆瓣图书评论数据:
python manage.py fetch_books
六、代码结构说明
1. book/models.py
此文件定义了项目中的数据模型,包括 Book、Review 和 User 表的结构。使用 Django ORM 提供的 API 来创建和查询数据库。
2. book/views.py
此文件定义了与 Web 页面相关的视图函数。例如,显示图书详情、展示评论内容和推荐结果。
3. book/templates
存储了应用的 HTML 模板,用于渲染图书信息、用户评论、推荐结果等。
4. data
存储从豆瓣网站爬取的图书数据,通常是 JSON 或 CSV 格式的文件,供推荐算法使用。
七、常见问题及解决方案
1. Django 服务器启动失败
- 确保数据库已经正确迁移,可以运行
python manage.py migrate命令进行数据库迁移。
2. 数据抓取失败
- 检查豆瓣网站结构是否发生了变化。如果是,更新爬虫脚本中的解析逻辑。
3. 数据库连接问题
- 确保数据库配置正确,检查
settings.py文件中的数据库连接信息。
八、总结
本项目是一个基于 Django 的图书评论推荐系统,能够从豆瓣网站抓取书籍和评论数据,通过推荐算法提供个性化推荐。项目包括数据爬取、推荐算法、用户管理、数据展示和可视化等功能模块,具有良好的扩展性。
项目具体演示效果:
【S2023084基于python+Django爬虫的豆瓣图书评价管理推荐可视化系统】 https://www.bilibili.com/video/BV1gD4y1s7V5/?share_source=copy_web&vd_source=3d18b0a7b9486f50fe7f4dea4c24e2a4
需要项目配套源码的可以私信博主

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 12
12 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)