基于大数据的电商用户行为分析系统
models.py使用 SQLAlchemy / Flask SQLAlchemy 定义与数据库表相对应的模型类。配置数据库连接信息(MySQL),如。Flask 路由:定义诸如/index/analysis/report等接口,处理请求并返回相应的模板页面或数据 JSON。结合数据库查询与算法分析结果,对外提供业务逻辑。templates/使用 Jinja2 编写 HTML 模板,把后端返回的数
一、项目简介
本项目旨在构建一个基于大数据的电商用户行为分析系统,通过采集和存储用户在电商网站的各种行为数据(如浏览记录、商品点击、购物车操作、下单/支付、评价等),并使用 Flask 作为后端框架提供数据分析与可视化接口,帮助运营人员或管理者更好地了解用户行为规律,从而做出科学的业务决策。
1.1 开发背景
随着电商行业的飞速发展,用户规模和行为数据量呈指数级增长,传统的数据分析方式难以满足海量数据的实时或准实时分析需求。为此,本项目在后端采用了**Flask + 大数据技术(如Hadoop/Spark/分布式数据库等)**的方式,既能提供灵活的 Web 接口,又能处理海量数据分析需求。
1.2 功能目标
- 数据采集:对电商网站的用户行为进行实时或周期性采集并存储。
- 数据处理:对原始数据进行清洗、转换、聚合等预处理操作。
- 用户行为分析:从多维度(时间、商品、用户画像)对用户行为进行聚合统计、可视化。
- 推荐算法或预测分析(可选):基于用户画像与行为特征,对用户进行个性化推荐或需求预测。
- 可视化展示:通过前端页面或图表,为运营管理者提供直观的数据分析结果。
二、技术栈说明
2.1 后端框架
- Flask:基于 Python 实现的轻量级 Web 框架,优点是简单易用、灵活度高,适合快速开发与部署。
2.2 数据处理与分析
- Python:核心语言,便于大数据处理、算法实现以及调用各种数据分析库(如 NumPy、Pandas、scikit-learn 等)。
- 大数据平台/分布式计算(可选):
- Hadoop/HDFS:如果数据量较大,可用作分布式存储。
- Spark:可用于大规模数据的清洗、聚合以及机器学习的分布式计算。
若数据规模尚可,也可以先用传统关系型数据库或本地文件进行原型验证,后期根据需求演进到分布式平台。
2.3 数据库
- MySQL(或其他关系型数据库):存储电商元数据、用户基本信息、订单信息等。
- NoSQL 数据库(如 Redis、MongoDB):存储用户会话数据、行为日志,或作为缓存层,提高查询效率。
2.4 前端与可视化
- HTML + CSS + JavaScript:标准 Web 前端开发技术。
- Flask Jinja2 模板:后端直接渲染模板,生成可视化页面。
- ECharts / Chart.js(可选):用于可视化图表展示。
三、系统架构设计
下图为本项目的整体架构示意(可根据实际情况绘制架构图):
+-------------------+ +-------------------+
| 前端界面 |<------>| Flask Server |
| HTML / JS / CSS | | (Web Service) |
+-------------------+ +---------+---------+
|
+-------------v--------------+
| 数据分析与处理层 |
| (Spark/Hadoop/Python) |
+-------------+--------------+
|
+-------------v--------------+
| 数据库存储层 |
| MySQL + NoSQL (Redis) |
+---------------------------+
3.1 前端层
- 负责与用户交互,展示分析结果、图表报表等。
- 通过请求 Flask 后端获取数据,或提交筛选条件,获得分析报表。
3.2 服务层(Flask)
- 提供 HTTP 接口,用于前端调用。
- 接收前端的分析请求,调度后端的算法或数据查询,返回结果。
- 整合数据库及大数据平台的处理结果,把最终数据序列化后发送给前端。
3.3 数据分析与处理层
- 包含数据清洗、聚合、挖掘及机器学习算法的核心逻辑(可基于 Python 的标准库或 Spark MLlib 等)
- 当数据量较大时,利用 Spark/Hadoop 进行分布式处理;当数据量适中时,也可使用单机 Python 脚本+Pandas 做分析。
3.4 数据库层
- MySQL:用于存储电商业务的结构化数据,如用户表、商品表、订单表、评价表等。
- NoSQL (Redis / MongoDB):
- 可能存储日志数据、用户行为 JSON 数据等非结构化数据。
- 在需要高并发或者实时查询时,也可将部分分析结果或中间计算结果缓存到 Redis。
四、数据库设计
以 MySQL 为例,下面列举一些主要表的设计示例,并给出简要说明。根据项目规模和需求,实际中会有更多或更复杂的表。
4.1 数据库 E-R 关系示意
用户表(user) ----< 订单表(order) ----< 订单明细表(order_item)
\--< 浏览行为表(browse_log)
\--< 购物车行为表(cart_log)
\--< 商品收藏表(fav_log)
商品表(product) ----< 订单明细表(order_item)
\--< 浏览行为表(browse_log)
\--< 购物车行为表(cart_log)
\--< 商品收藏表(fav_log)
4.2 主要数据表结构
4.2.1 用户表(user)
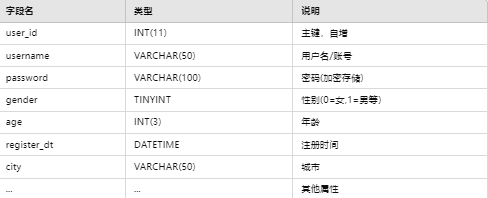
4.2.2 商品表(product)
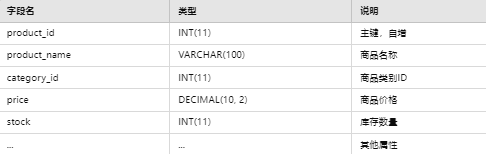
4.2.3 订单表(order)
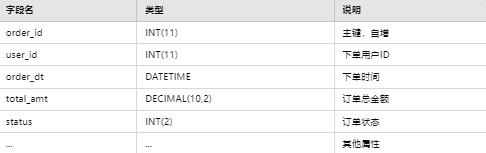
4.2.4 订单明细表(order_item)
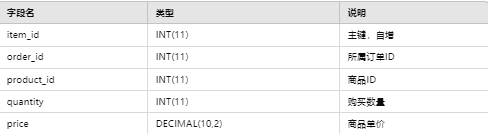
4.2.5 行为日志表(browse_log/cart_log/fav_log 等)
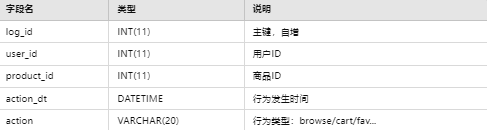
五、主要功能与实现
5.1 数据采集
- 可以使用埋点脚本或服务器日志方式获取用户浏览、点击、收藏、加购、下单及支付行为,定时或实时写入日志数据库或日志文件。
- 大规模时可用 Kafka + Spark Streaming 实时采集;小规模时可直接插入数据库或 CSV 文件。
5.2 数据清洗与存储
- 若采用大数据方式:
- 启动 Spark 任务读取源日志文件/HDFS 文件,做去重、格式化等处理后再写回到 HDFS 或关系型数据库。
- 若规模不大:
- 采用 Python 脚本 + Pandas 进行数据预处理,然后批量写入 MySQL 或 MongoDB。
5.3 数据分析模块
常见分析指标与方法:
- 用户价值分析:使用 RFM(Recency, Frequency, Monetary)模型对用户进行分层;或结合用户订单频次、金额等定义 VIP、常规、潜在流失等分层。
- 用户画像:根据用户行为特征(品类偏好、价格偏好、地区分布等)对用户进行画像标签化。
- 推荐算法:
- 协同过滤(基于用户/基于商品)
- 关联规则(如 Apriori)挖掘用户对商品组合购买倾向
- 基于内容的推荐
- 聚类算法:可使用 K-Means / DBSCAN 等算法,对用户行为特征向量进行聚类,找出相似群体。
- 关联分析:订单与商品、地域、时间、活动等多维度联动分析。
5.3.1 示例:K-Means 用户聚类
- 数据准备:抽取活跃用户的购买金额、购买次数、平均停留时长等特征。
- 算法流程:
- 标准化特征(如 Z-Score)。
- 使用 K-Means 算法对用户进行聚类,设定合理的 k 值(可根据轮廓系数等指标评估)。
- 根据聚类结果将用户分成若干类,每类有不同的特征定位(高消费低频、高频中消费等)。
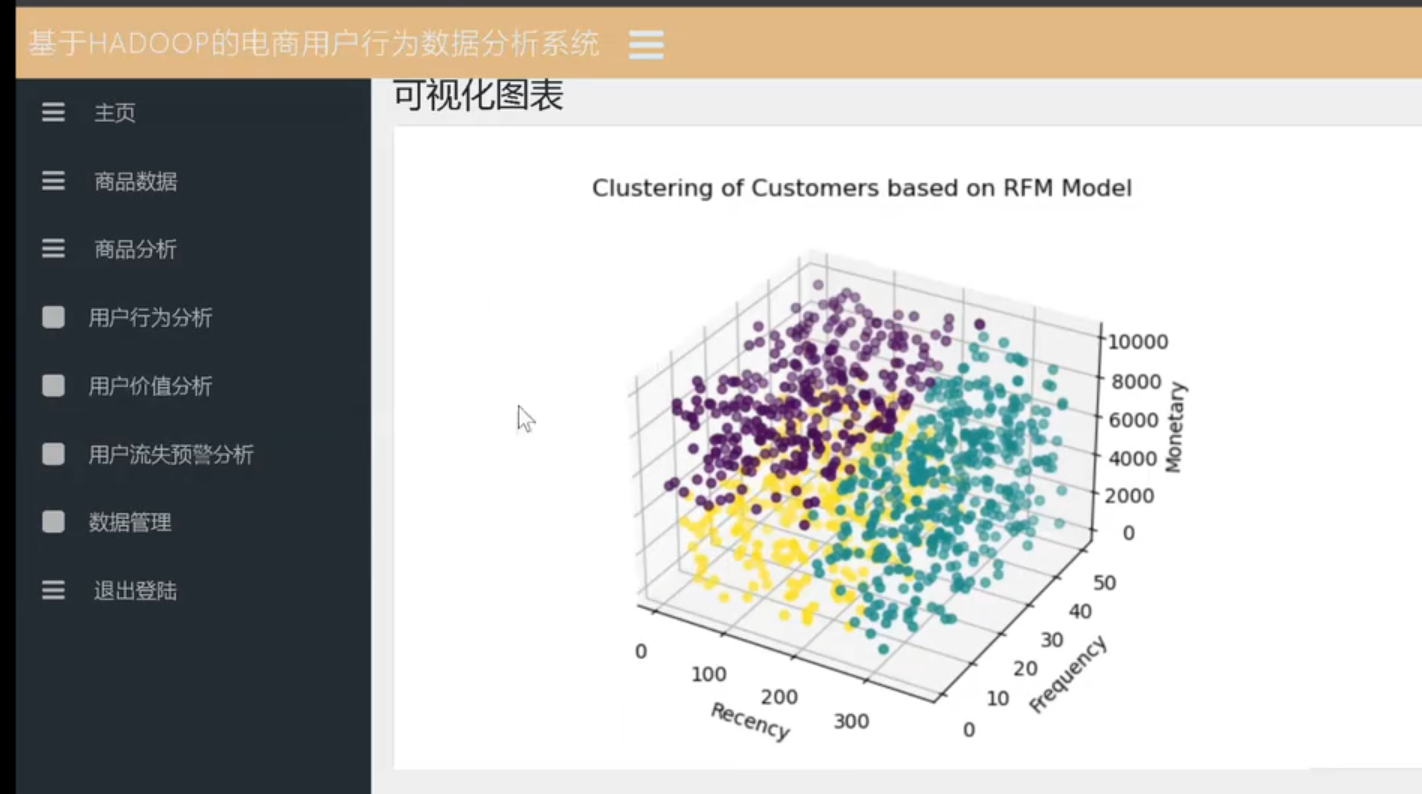
5.3.2 示例:RFM 模型用户分层
- R(Recency):最后一次购买距离当前的时间
- F(Frequency):在固定时间段内的购买次数
- M(Monetary):在固定时间段内的消费总金额
- 根据 R、F、M 进行打分或加权,设定阈值,将用户分为不同等级(重要价值用户、一般用户、低价值等)。
六、Flask 后端实现
6.1 项目结构
project/
│ manage.py # 入口脚本 (可用flask run方式)
│ requirements.txt # 依赖库列表
├─ app/
│ ├─ __init__.py # Flask应用初始化
│ ├─ models.py # 数据库ORM模型定义
│ ├─ views.py # 视图函数/路由
│ ├─ controllers/ # 控制器(业务逻辑)
│ ├─ templates/ # HTML模板
│ └─ static/ # 前端静态文件(css, js, img)
└─ analytics/
├─ data_clean.py # 数据清洗脚本
├─ user_cluster.py # 用户聚类算法脚本
└─ recommendation.py # 推荐算法脚本
6.2 主要模块介绍
- models.py
- 使用 SQLAlchemy / Flask SQLAlchemy 定义与数据库表相对应的模型类。
- 配置数据库连接信息(MySQL),如
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://user:password@host:port/dbname'。
- views.py / controllers/
- Flask 路由:定义诸如
/index,/analysis,/report等接口,处理请求并返回相应的模板页面或数据 JSON。 - 结合数据库查询与算法分析结果,对外提供业务逻辑。
- templates/
- 使用 Jinja2 编写 HTML 模板,把后端返回的数据渲染到前端。
- analytics/
- 存放数据分析与机器学习相关的脚本,如用户聚类、推荐算法、关联规则分析等。
- 通过定时任务或手动触发,生成分析结果,存入数据库或缓存。
6.3 路由示例
from flask import Blueprint, render_template, request, jsonify
from app.models import db, User, Order
# 假设 analysis.py 封装了一些分析函数
from analytics.user_cluster import do_cluster_analysis
analysis_bp = Blueprint('analysis', __name__)
@analysis_bp.route('/cluster')
def cluster_users():
# 1. 调用算法脚本进行用户聚类
result = do_cluster_analysis()
# 2. 返回结果(可视化或JSON)
return jsonify({'clusters': result})
七、核心算法举例
以下以用户聚类和协同过滤推荐为例简要说明:
7.1 用户聚类(K-Means)
- 数据来源:从
order表统计用户过去一段时间(如半年)的消费次数F、消费总额M,以及距离当前最近一次消费的时间R。 - 特征向量:对 (R, F, M) 进行标准化处理得到 (R', F', M')。
- 聚类过程:
- 设定聚类个数 k(如 4),用 K-Means 对所有用户进行聚类。
- 输出每个用户的聚类标记,并持久化到数据库或输出文件。
- 结果分析:
- 将用户聚类结果可视化,如散点图或表格,帮助业务方进行分类运营。
7.2 协同过滤推荐
- 基于用户的协同过滤:
- 构建用户-商品的偏好矩阵,利用余弦相似度等度量,找到目标用户最相似的若干个用户,再结合他们购买/喜欢的商品做推荐。
- 基于商品的协同过滤:
- 计算商品两两相似度(被相同用户购买或浏览的次数)。当用户购买/浏览某商品时,推荐与之最相似的其他商品。
八、部署与运行
8.1 环境配置
- Python 环境:Python 3.x 及以下依赖库(在
requirements.txt中列出)
- Flask
- SQLAlchemy
- Pandas / NumPy / scikit-learn 等
- PyMySQL (或其他 MySQL connector)
- 可能包含 pyspark 等大数据包(可选)
- 数据库:安装并配置好 MySQL,创建对应数据库和表。
- 大数据平台(可选):如使用 Hadoop/Spark,需要安装对应版本并配置集群。
8.2 运行步骤
- 克隆/下载项目代码至本地,进入项目根目录。
- 创建并激活虚拟环境(可选):
python -m venv venv source venv/bin/activate # mac/linux venv\Scripts\activate # windows
- 安装依赖:
pip install -r requirements.txt
- 修改
app/__init__.py或config.py中的数据库连接信息。 - 初始化数据库(如使用 Flask-Migrate 等迁移方式,执行
flask db upgrade)。 - 启动 Flask:
flask run --host=0.0.0.0 --port=5000
- 或者:
python manage.py runserver
- 打开浏览器访问
http://localhost:5000/,查看系统主页面。
九、项目总结与展望
- 项目亮点:
- 基于大数据平台或分布式处理框架,能够处理较大规模的用户行为数据。
- 使用 Flask 快速搭建 Web 接口,结合分析脚本实现前后端分离或服务化。
- 引入机器学习算法(聚类、协同过滤、关联规则等),为运营决策提供个性化建议。
- 后期优化方向:
- 优化数据采集方案,减少延迟,提高实时性。
- 在推荐算法中引入更多特征(用户画像、商品属性等),提升推荐准确率。
- 引入可视化报表功能,如基于 ECharts 或 React + Ant Design 等前端框架,进一步提升易用性。
- 在实际大规模部署中,可将 Flask + gunicorn/nginx 配合使用,提升并发性能与稳定性。
十、附录
10.1 依赖库(示例)
Flask==2.2.5 Flask-SQLAlchemy==3.0.5 PyMySQL==1.0.2 pandas==1.5.3 numpy==1.23.5 scikit-learn==1.2.1 matplotlib==3.6.3
根据实际项目需要调整版本或添加其他依赖。
10.2 常用指令
- 开发环境启动:
flask run - 数据库迁移:
- 初始化:
flask db init - 生成迁移脚本:
flask db migrate -m "init" - 应用迁移:
flask db upgrade
实际项目演示效果如下:
【【大数据分析毕设项目参考】基于hadoop的电商用户行为分析大屏可视化】 【大数据分析毕设项目参考】基于hadoop的电商用户行为分析大屏可视化_哔哩哔哩_bilibili
技术栈:Python+flask+pyspark+echart+pandas

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 10
10 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)