大数据之路读书笔记(三)
上一章末尾简单讲述了关于Aplus.JS日志采集技术方案(基于浏览器)的主要内容,现在重点关注一下方案落地的具体流程。
前言
上一章末尾简单讲述了关于Aplus.JS日志采集技术方案(基于浏览器)的主要内容,现在重点关注一下方案落地的具体流程。
页面浏览日志采集流程
目前典型的网页访问过程是以浏览器请求、服务器响应并返回所请求的内容(大部分是HMTL文档形式)构成的,其中浏览器和服务器是两个主体,它们之间的通信遵循HTTP协议(超文本传输协议),浏览器发起的请求被称为HTTP请求(HTTP Request),服务器的返回则被称为HTTP响应(HTTP Response)。
网页访问过程图解
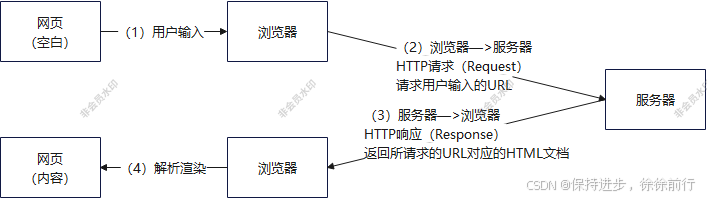
(1)用户在浏览器输入指令
(2)浏览器接受用户指令,发起网页请求,一般是HTTP请求,会按照HTTP协议中约定的格式结合用户输入进行构建,HTTP请求格式:
- 请求行(HTTP Request Line),请求行内有三个要素,分别是请求方法、所请求资源的URL以及HTTP协议版本号。
- 请求报头(HTTP Message Header),请求报头是浏览器在请求时向服务器提交的附加信息,请求报头一般会附加很多内容项,每项内容被称为一个头域(Header Field,简称Header)。扩展知识,页面访问之前已访问过,请求报头中会附加Cookie项,记录用户上一次访问时的状态或者身份信息。
- 请求正文(HTTP Message Body),可选,get请求为空,post请求有json格式字符串。
(3)服务器接收HTTP请求,解析后,服务器会按照业务逻辑处理本次请求并按照HTTP协议规定的格式生成HTTP响应,HTTP响应格式:
- 状态行,状态行标识服务器对本次请求的处理结果,一般是三位数构成的状态码,例如200(表示响应成功)、404(表示网页没找到)。
- 响应报头,响应报头就是服务器附加信息,可以在浏览器端被读取和使用,其中最重要的附加信息就是Cookie,用于更新浏览器的Cookie信息。
- 响应正文,可选,浏览器请求的文档、图片、脚本等,其实就是被封装在正文中被返回的。
(4)浏览器接收服务器的响应内容,根据HTML文档协议展现给用户查看。
页面浏览日志采集埋点设计图解
根据网页访问过程,可以知道,如果要记录这次访问行为,则采集日志的动作必然是附加在上述四个步骤中的某个环节内完成。在第一步和第二步,用户的请求尚未抵达服务器;而直到第三步完成,只能认为服务器处理了请求,不能保证浏览器能够正确地解析和渲染页面,尚不能确保用户已确实打开页面,因此在前三步是无法采集用户的浏览日志,由此可知,采集日志的动作需要在第四步,也就是浏览器开始解析文档时才能进行。
依据以上原因,日志采集思路可以设计成,在HTML文档内的适当位置增加一个日志采集节点,当浏览器解析到这个节点时,将自动触发一个特定的HTTP请求到日志采集服务器,当日志采集服务器接收到这个请求时,就可以确定浏览器已经成功地接收和打开页面了。
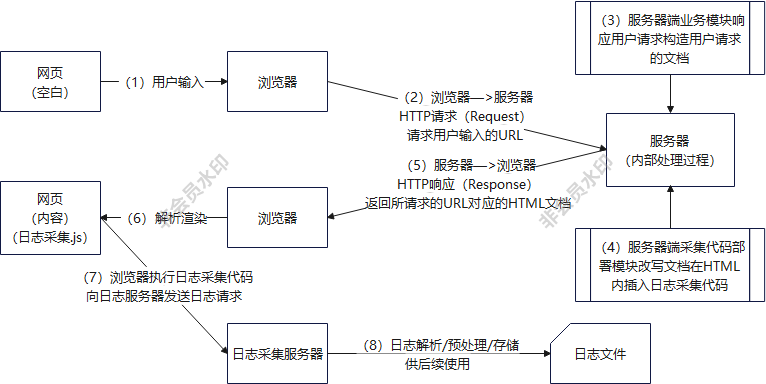
(1)客户端日志采集(浏览器),日志采集工作由植入页面HTML文档内的JavaScript脚本来执行,当采集脚本被浏览器加载解析执行时,会采集当前页面参数、浏览行为的上下文信息(如读取用户访问当前页面时的上一步页面)以及一些运行环境信息(如当前的浏览器和分辨率等)。在HTML文档内植入日志采集脚本的动作可以由业务服务器在响应业务请求时动态执行,也可以在页面被开发时被提前设计好。
(2)客户端日志发送(浏览器),采集脚本执行后,会向日志服务器发起一个日志请求,以将采集到的数据发送到日志服务器。请求发送时间,一般为采集完成立即发送,特殊情况会延时发送。日志采集和发送模块会集成在一个JavaScript脚本文件内,且通过互联网浏览器必然支持的HTTP协议与日志服务器通信,采集日志信息会以URL参数形式放在HTTP日志请求的请求行内。
(3)服务器端日志收集,日志服务器接收到客户端发送的日志请求后,会立刻响应请求成功,以免对正常的页面加载造成影响。日志服务器的日志收集模块会将日志请求内容写入日志缓冲区内,完成此条浏览日志的收集。
(4)服务端日志解析存档,日志服务器接收到的浏览日志进入缓冲区后,会被日志处理程序顺序读出并按照日志处理逻辑解析。由日志采集脚本记录的在日志请求行内的参数,会被解析(转义和解码),然后存入标准的日志文件中并注入实时消息通道内供其他后端程序读取和进一步加工处理。
页面交互日志采集流程
仅仅了解到用户到访过的页面和访问路径,不能满足用户细分研究的需求,由此就需要了解用户在访问某个页面时具体的互动行为特征,比如鼠标或输入焦点的移动变化(代表用户关注内容的变化)、对某些页面交互的反应(可借此判断用户是否对某些页面元素发生认知困难)等等。因为这些行为往往并不触发浏览器加载新的页面,所以无法通过上述的日志采集方案采集日志,需要新的方案来采集日志。
因为终端类型、页面内容、交互方式和用户实际行为的千变万化不可预估,所以页面浏览日志采集和页面交互日志采集完全不同,无法规定统一的采集内容,呈现出高度自定义的业务特征,与之相适应的,交互日志采集是以技术服务形式呈现的。
具体而言,市面上的交互日志采集服务是一个开发的基于HTTP协议的日志服务,需要采集交互日志的业务,一般经过以下几个步骤即可将自助采集的交互日志发送到日志服务器中:
(1)业务方在元数据管理界面依次注册需要采集交互日志的业务、具体的业务场景以及场景下的具体交互采集点,在注册完成后,系统会自动生成与之对应的交互日志采集代码模板。
(2)业务方将交互日志采集代码植入目标页面,并将采集代码与需要监测的交互行为做绑定。
(3)当用户在页面上产生指定行为时,采集代码和正常的业务互动响应代码一起被触发和执行。
(4)采集代码在采集动作完成后将对应的日志通过HTTP协议发送到日志服务器,日志服务器接收到日志后,对于保存在HTTP请求参数部分的自定义数据,即用户上传的数据,不做解析处理,只做转储,避免影响页面反应速度,可之后在处理。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)