k8s部署ELK系列五:集成Kibana实现日志可视化
Kibana 是 Elastic Stack 中用于数据可视化的组件,它通过与 Elasticsearch 紧密集成,提供了强大的可视化工具,使用户可以实时地浏览、查询和分析 Elasticsearch 中的数据。在 Kibana 中,用户可以创建仪表盘、设置数据视图,并使用强大的查询功能分析日志和指标数据。📌 在本系列中,我们成功完成了在 Kubernetes 集群中部署 ELK(Elasti
k8s部署ELK系列五:集成Kibana实现日志可视化
文章目录
在 Kubernetes 集群中,应用服务的日志对于故障排查和性能分析至关重要。传统的日志查看方式(如 kubectl logs)存在不便于集中管理和持久化存储的问题,因此,我们需要构建一套集中化的日志采集系统。
ELK(Elasticsearch + Logstash + Kibana)是目前主流的日志分析解决方案,其中 Kibana 作为 ELK 堆栈的最后一个组件,实现日志的可视化展示。Kibana 允许用户通过 Web 界面交互式地查询和可视化 Elasticsearch 中存储的数据,是日志分析中不可或缺的工具。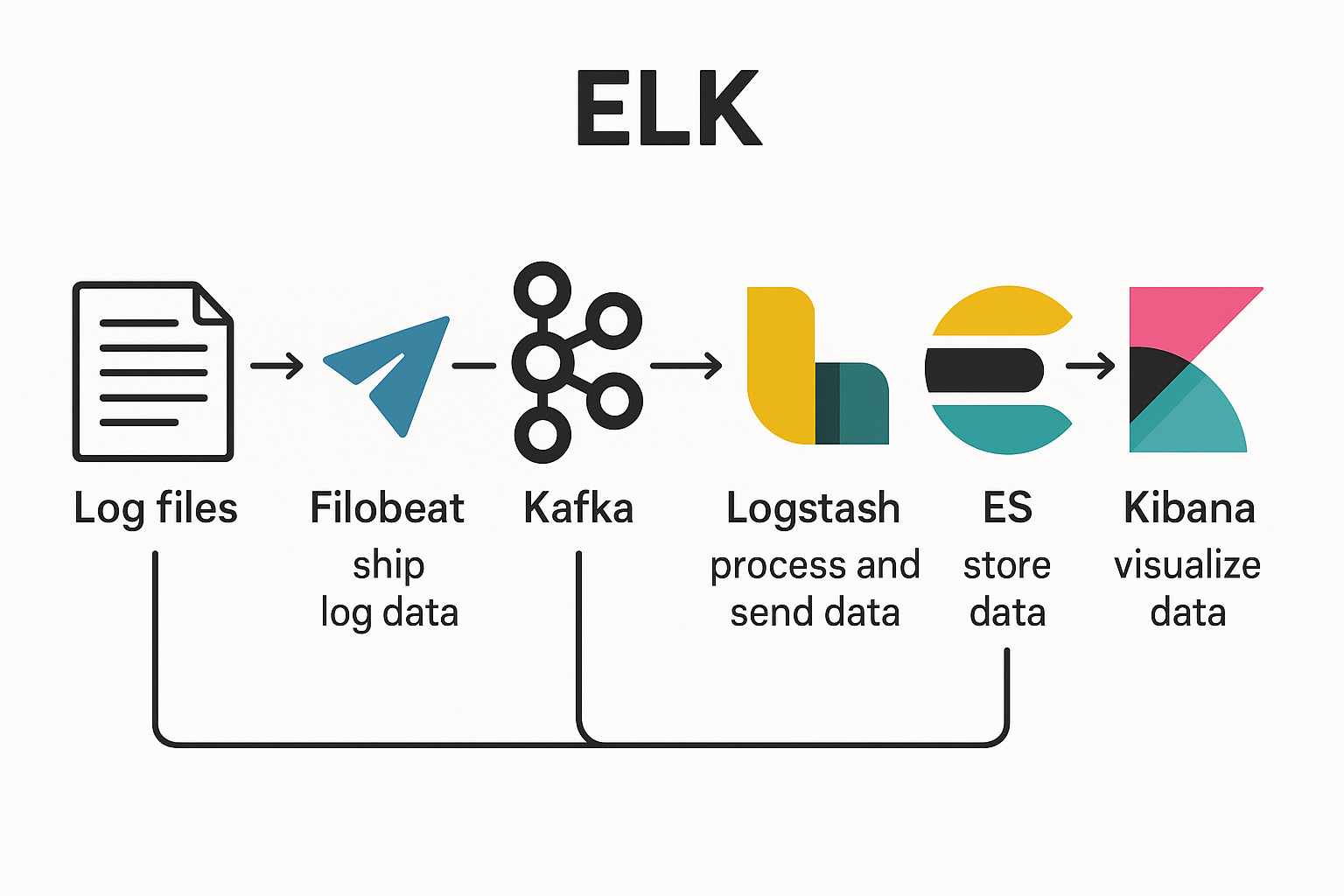
一、Kibana简介
Kibana 是 Elastic Stack 中用于数据可视化的组件,它通过与 Elasticsearch 紧密集成,提供了强大的可视化工具,使用户可以实时地浏览、查询和分析 Elasticsearch 中的数据。在 Kibana 中,用户可以创建仪表盘、设置数据视图,并使用强大的查询功能分析日志和指标数据。
二、Kibana实战部署
1. 创建Namespace(elk-namespace.yaml)
首先,创建一个新的命名空间,用于部署 ELK 相关的资源
apiVersion: v1
kind: Namespace
metadata:
name: elk
2. 创建Service(kibana-service.yaml)
接下来,创建一个 Kubernetes 服务(Service),以便暴露 Kibana Web 界面
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: elk
spec:
selector:
app: kibana
type: NodePort
ports:
- port: 5601
targetPort: 5601
nodePort: 30601
3. 创建ConfigMap(kibana-configmap.yaml)
创建一个 ConfigMap 来存储 Kibana 配置文件。配置项包括 Elasticsearch 的地址、Kibana 的日志设置以及访问设置
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kibana-config
namespace: elk
data:
kibana.yml: |
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://elasticsearch-0.elasticsearch-cluster.elk.svc.cluster.local:9200"]
kibana.index: ".kibana"
logging.dest: /usr/share/kibana/logs/kibana.log
i18n.locale: "zh-CN"
server.publicBaseUrl: "http://kibana.elk.svc.cluster.local:5601"
4. 创建Deployment(kibana-deployment.yaml)
使用 Deployment 方式部署 Kibana,此处我们将 Kibana 配置为与 Elasticsearch 集群通信,并挂载之前创建的 ConfigMap
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: elk
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
affinity:
nodeAffinity: #资源有限,这里配置节点亲和性,尽量调度到node1节点
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
containers:
- name: kibana
image: harbor.local/k8s/kibana:7.17.0 #内网仓库镜像
ports:
- containerPort: 5601
env:
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch-0.elasticsearch-cluster.elk.svc.cluster.local:9200"
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/kibana.yml
subPath: kibana.yml
- name: logs
mountPath: /usr/share/kibana/logs
resources:
requests:
cpu: "200m"
memory: "500Mi"
limits:
cpu: "500m"
memory: "1Gi"
# 如果不开启kibana认证就可以这样配
#livenessProbe:
#httpGet:
#path: /api/status
#port: 5601
#initialDelaySeconds: 90
#periodSeconds: 10
livenessProbe:
exec:
command:
- bash
- -c
- |
curl -u elastic:elastic -fs http://kibana.elk.svc.cluster.local:5601/api/status > /dev/null
initialDelaySeconds: 30
periodSeconds: 10
volumes:
- name: config
configMap:
name: kibana-config
- name: logs
emptyDir: {}
5. 部署所有资源
将上述 YAML 文件保存后,使用以下命令统一部署
kubectl apply -f elk-namespace.yaml
kubectl apply -f kibana-service.yaml
kubectl apply -f kibana-configmap.yaml
kubectl apply -f kibana-deployment.yaml
6. 验证Kibana Pod状态
kubectl get pod -n elk

三、 Kibana页面配置
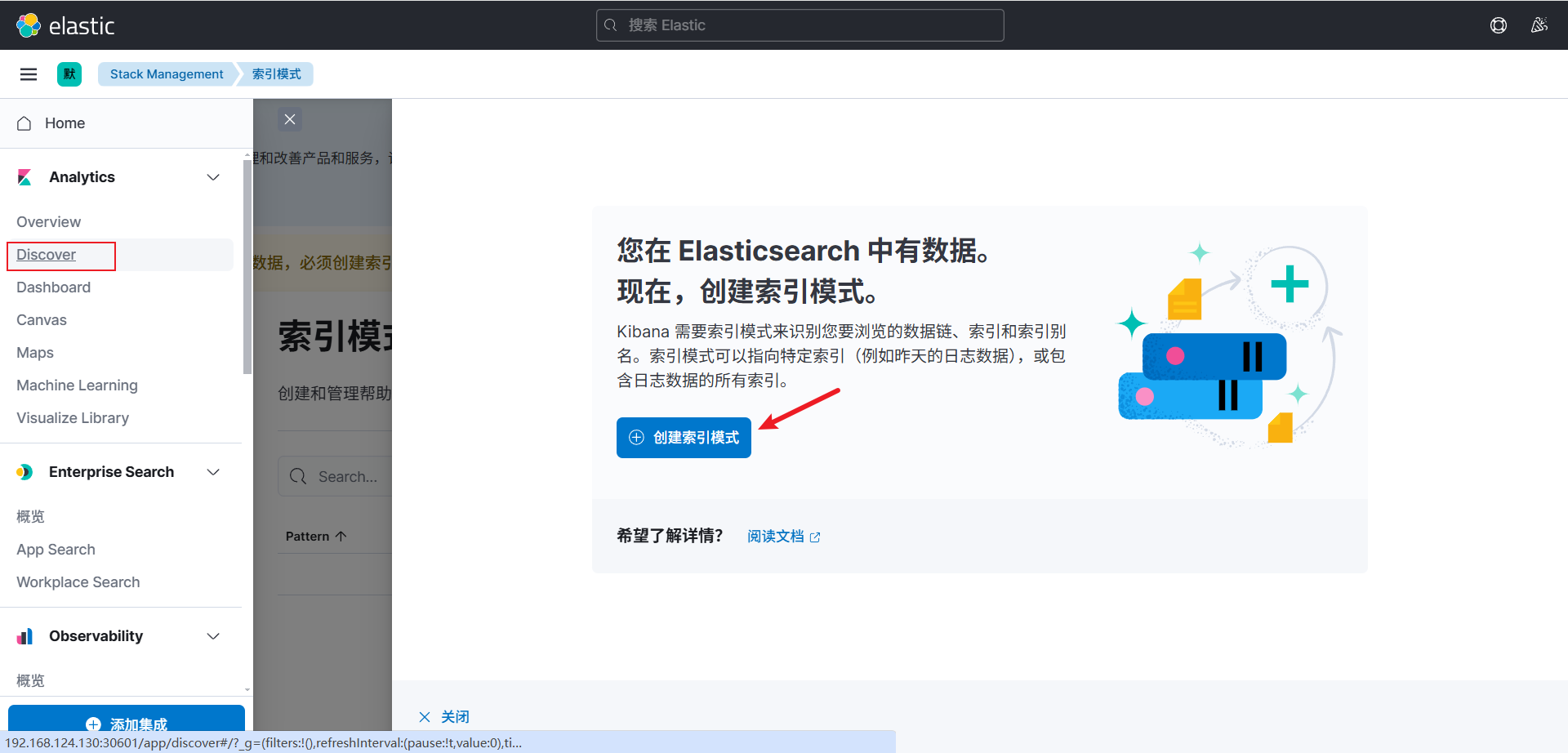
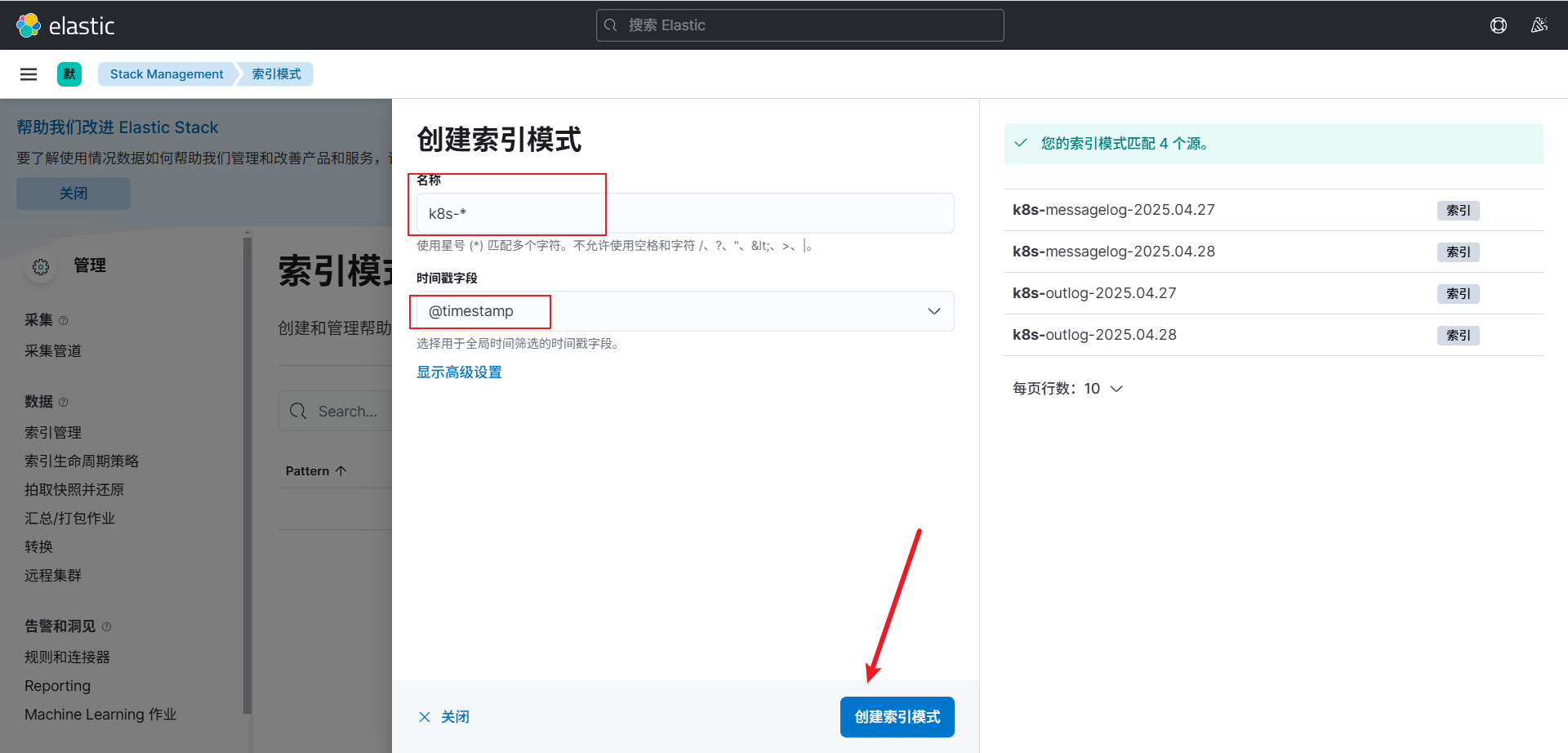
1. 创建索引模式
访问地址:http://ip:30601
在 Kibana Web 界面上,你可以创建索引模式来匹配 Elasticsearch 中存储的日志数据
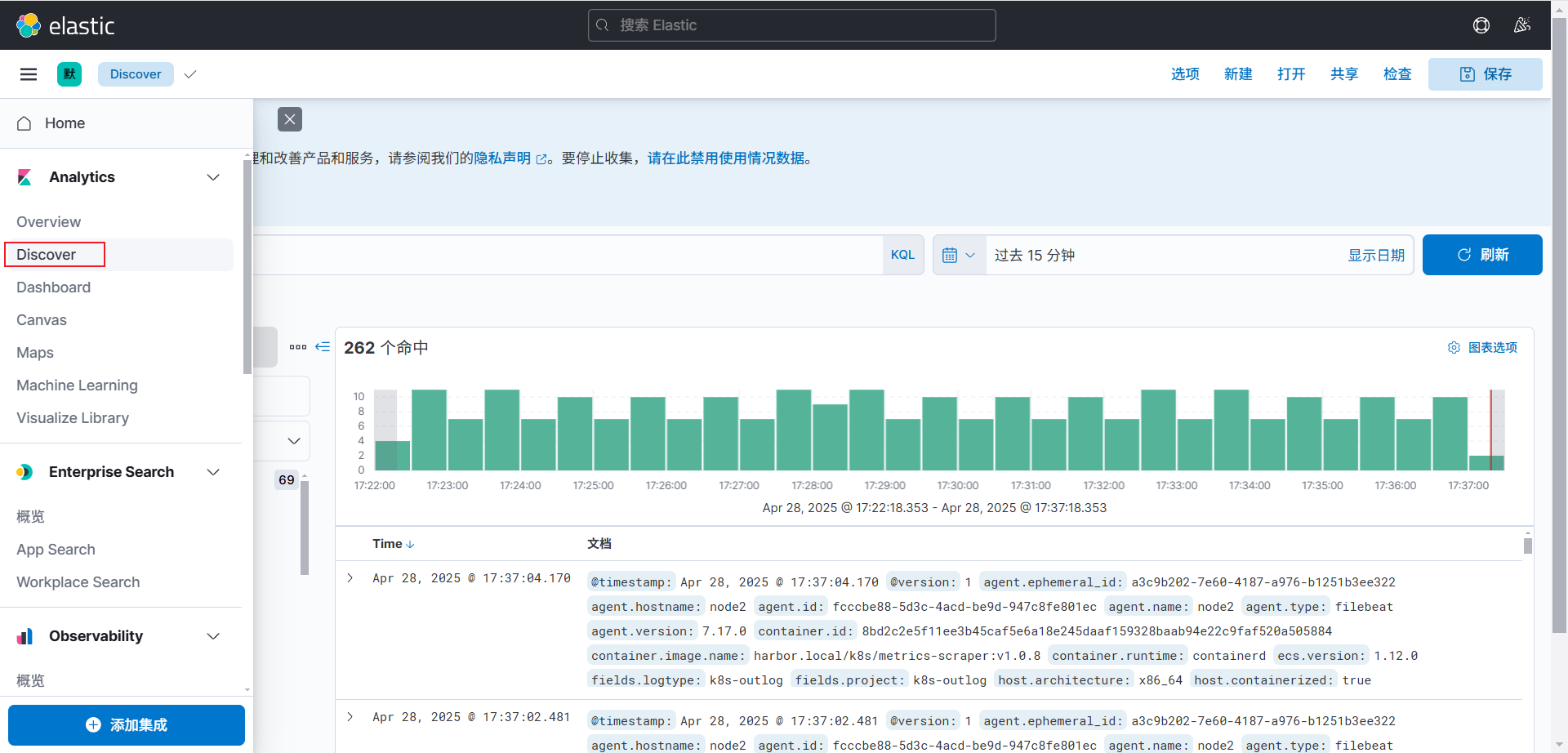
2. 展示数据
通过 Kibana 查询和展示 Elasticsearch 中的日志数据,帮助分析系统的运行状况
总结
📌 在本系列中,我们成功完成了在 Kubernetes 集群中部署 ELK(Elasticsearch + Logstash + Kibana)堆栈的全过程。通过结合 Kafka 来收集和传输日志数据,我们实现了高效的日志采集和处理。接着,利用 Filebeat 作为日志采集的工具,确保了从应用程序到 Kafka 的日志转发。然后,通过 Elasticsearch 存储日志数据,最后部署 Kibana 来展示和分析这些数据,实现了完整的日志管理解决方案。具体过程包括:
- 部署 Filebeat:用于在各个应用服务中采集日志,并将其发送到 Kafka
- 部署 Logstash:从 Kafka 中拉取日志并发送到 Elasticsearch
- 配置并部署 Elasticsearch 集群:用于存储日志数据,并提供高效的查询和分析能力
- 部署 Kibana:展示和分析 Elasticsearch 中存储的日志数据,提供交互式的可视化界面,帮助快速定位问题
至此,ELK 堆栈的部署工作已完成,接下来可以根据需求扩展集群规模、优化资源配置,进一步提高系统的可用性和扩展性。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)