【计算引擎】OLAP之争:kylin、impala、druid、presto、clickhouse
文章目录1. 即席查询2. Kylin2.1 架构2.2 原理2.3 Cube构建优化3. Impala3.1 架构3.2 优化4. Druid4.1 架构4.2 数据结构4.2.1 DataSource4.2.2 Segment结构5. Presto5.1 架构5.2 数据源6. ClickHouse6.1 特性6.2 架构7.总结1. 即席查询即席查询是用户根据自己的要求,灵活的选择查询条件,
文章目录
1. OLAP即席查询
即席查询是用户根据自己的要求,灵活的选择查询条件,系统根据用户的选择生成相应的统计报表,快速的执行自定义SQL。
2. Kylin
- Apache kylin是一个开源分布式分析引擎、提供Hadoop、Spark之上的SQL 查询接口及多维分析(OLAP)能力,可以再亚秒内查询巨大的Hive表,还可以与BI工具集成ODBC、JDBC、RestAPI、还有自带的Zepplin插件,来访问Kylin服务。
2.1 架构
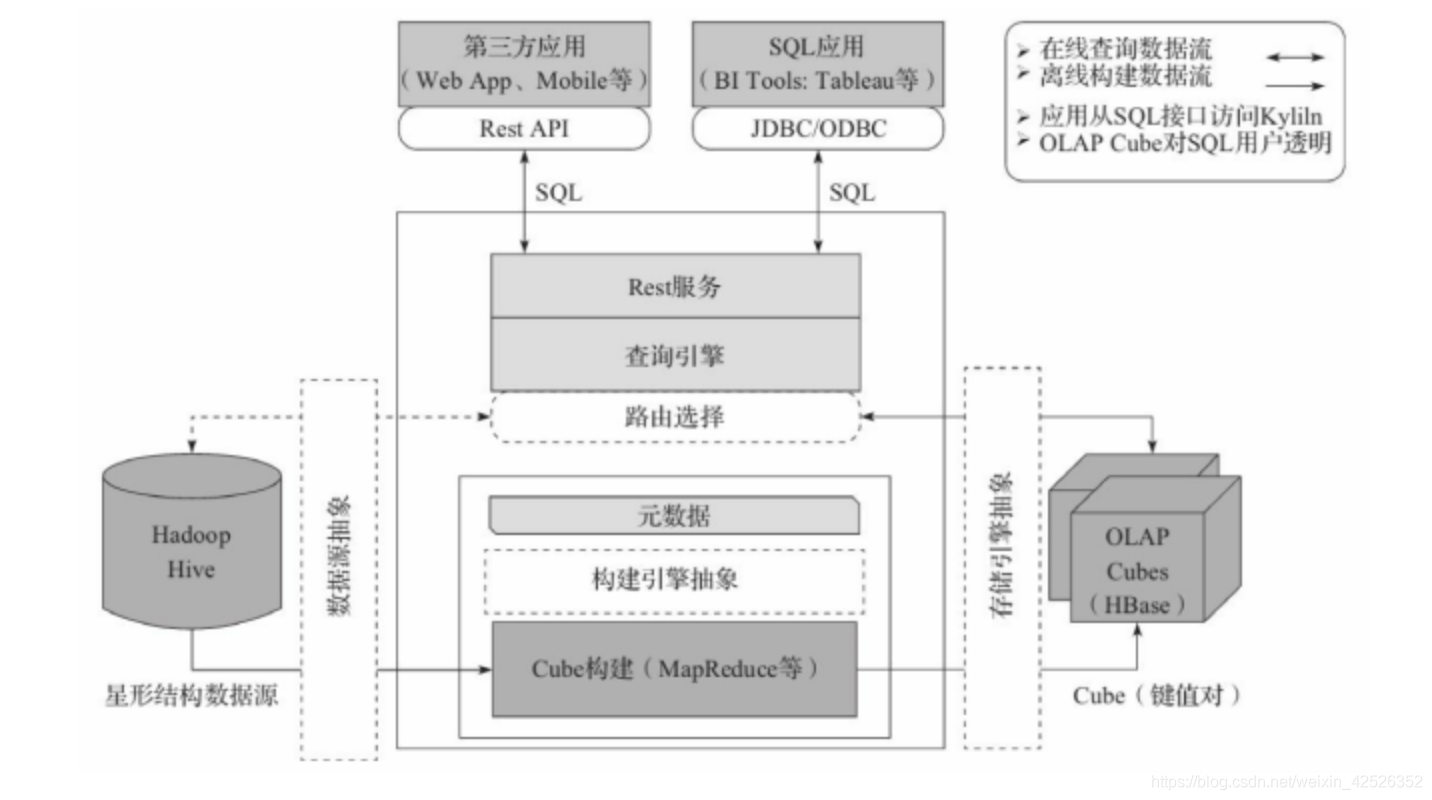
a、REST 服务层:应用程序开发的入口点
b、查询引擎层:Cube准备就绪后,与系统中的其他组件进行交互,从而向用户返回对应的结果
c、路由层:将解析的SQL生成的执行计划转换成Cube缓存的查询,cube通过预计算缓存在hbase中,这些操作可以在毫秒级完成,还有一些操作使用的原始查询,这部分延迟较高(麒麟高版本中已删除该层)
d、元数据管理工具:kylin的元数据管理存储在hbase中
e、任务引擎:处理所有离线任务:包括shell脚本、javaAPI以及MapReduce任务等等
Kylin为基础的MOLAP(多维立方体分析)模式在处理增量业务分析,固化维度场景,通过对数据模型做Cube预计算,并利用计算的结果加速查询,其中心思想是以空间换时间。
2.2 原理
其中先介绍与kylin相关的几个名词:
- 维度:即观察数据的角度
- 度量:即被聚合的统计值也就是聚合运算的结果
- Cuboid:对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。
- Cube:所有维度组合的Cuboid作为一个整体,称为Cube。计算N个维度之间的Cuboid需要2的N次方-1。
kylin在预计算的过程:
- 指定数据模型,定义维度和度量
- 预计算Cube,计算所有Cuboid并保存为物化视图
预计算过程是kylin读取hive中的数据,按照我们设计的cube进行计算,将其结果保存在hbase中,默认计算引擎为Mapreduce,其中build一次的结果我们称为一个segment,其中涉及多个算法,由kylin.cube.algorithm参数决定,参数值可选auto,layer和inmen,默认值为auto。
- 逐层构建算法(layer)
逐层算法中,是按原始数据聚合而来,是基于它上一层的结果来计算的。比如:[group by a,b] 的结果,是基于[group by a,b,c]的结果,这样可以减少重复计算,每一轮的计算都是一个Mapreduce任务,且串行执行;一个N维的cube,至少需要N+1次。
缺点:该算法的效率较低,尤其是当cube维度系数较大的时候
- 快速构建算法(inmem)
算法主要的思想:对Mapper所分配的数据块,将它计算成一个完整的小Cube段(包含所有的Cuboid),每个Mapper将计算完的cube段输出给reducer做合并,生成大Cube。即利用mapper端计算先完成大部分聚合,再将聚合后的结果交给reducer,从而降低对网络瓶颈的压力。
与layer算法有两点不同:
- Map端会利用内存做预聚合,算出所有组合,Map端输出的每一个key都是不同的,这样会减少到Reduce端的数据量。
- 一轮mapreduce便会完成所有层次的计算,减少hadoop任务的调配。
- 执行,查询,读取Cubiod,生成查询结果
2.3 Cube构建优化
- 如何判断Cube是否足够优化?
在Web GUI的Model页面选择一个READY状态的Cube,当我们把光标移到该Cube的Cube Size列时,Web GUI会提示Cube的源数据大小,以及当前Cube的大小除以源数据大小的比例,称为膨胀率。
一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
1. cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数据过多。
2. cube中存在较高基数的维度,导致包含这类维度的每一个cuboid占用的空间都很大,这些cuboid积累造成整体cube体积变大。
- 如何优化?
- 使用聚合组,可以大大减少Cuboid的数量。
- 强制维度:如果一个维度被定义为强制维度,那么这个分组所产生的Cuboid中每一个都会包含维度
- 层级维度:维度数量按层级增加,例如一个层级中包含D1,D2,…,Dn,n个维度,那cubiod只会以[],[D1],[D1,D2],[D1,D2,D3],…,[D1,D2,…,Dn]这种形式出现。
- 联合维度:包含多个维度的情况。如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。
- 并发粒度优化
- 当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化。
kylin.hbase.region.cut的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。
kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。
3. Impala
提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。
3.1 架构
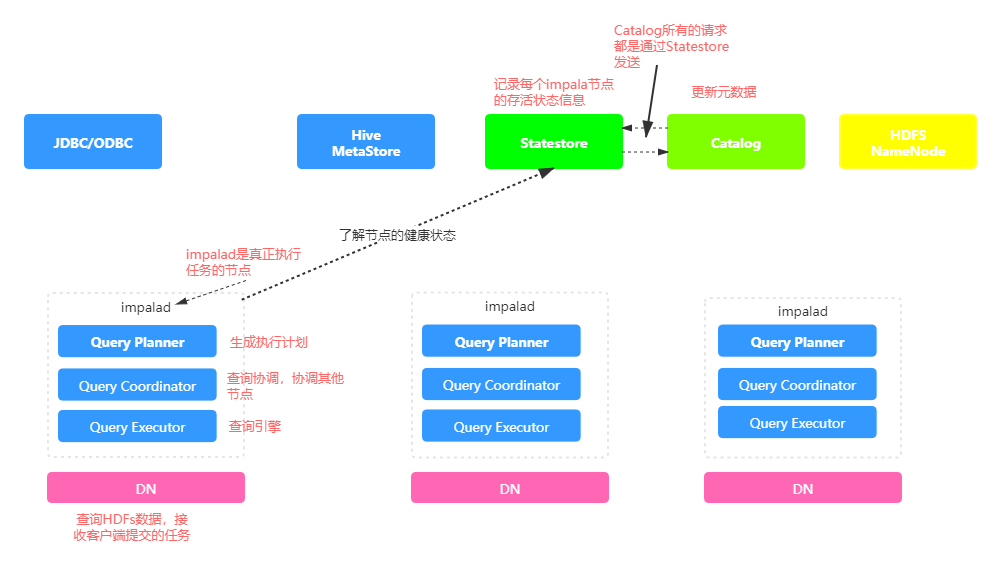
Impala自身包含三个模块:Impalad、Statestore和Catalog,除此之外它还依赖hive Metastore和HDFS NameNode。
- Impalad:
- 接收client的请求、Query执行并返回给中心协调节点。
- 子节点上的守护进程,负责向statestore保持通信,汇报工作。
- Catalog:
- 分发表的元数据信息到各个impalad中;
- 接收来自statestore的所有请求。
- Statestore:
- 负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息;
- 负责query的协调调度。
3.2 优化
- 尽量将StateStore和Catalog单独部署到同一个节点,保证他们正常通信。
- 通过对Impala Daemon内存限制(默认256M)及StateStore工作线程数,来提高Impala的执行效率。
- SQL优化,使用之前调用执行计划
- 选择合适的文件格式进行存储,提高查询效率。
- 避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表,将小文件数据存放到中间表。然后通过insert…select…方式中间表的数据插入到最终表中)
- 使用合适的分区技术,根据分区粒度测算
- 使用compute stats进行表信息搜集,当一个内容表或分区明显变化,重新计算统计相关数据表或分区。因为行和不同值的数量差异可能导致impala选择不同的连接顺序时进行查询。
- 网络io的优化:
- 避免把整个数据发送到客户端
- 尽可能的做条件过滤
- 使用limit字句
- 输出文件时,避免使用美化输出
- 尽量少用全量元数据的刷新
4. Druid
Druid 是一个分布式的支持实时分析的数据存储系统。具有以下几个特点:
- 亚秒级 OLAP 查询,包括多维过滤、Ad-hoc 的属性分组、快速聚合数据等等。
- 实时的数据消费,真正做到数据摄入实时、查询结果实时。
- 高效的多租户能力,最高可以做到几千用户同时在线查询。
- 扩展性强,支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发。
- 极高的高可用保障,支持滚动升级
适用场景:实时数据分析场景,这些场景的特点都是拥有大量的数据,且对数据查询的时延要求非常高,如:实时指标监控、推荐模型、广告平台、搜索模型,在实时指标监控中,系统问题需要在出现的一刻被检测到并及时给出警报。在推荐模型中,用户行为数据需要实时采集,并及时反馈到推荐系统中,用户点击几次后,系统能够识别其搜索意图,并在之后的搜索中推荐更合理的结果。
4.1 架构
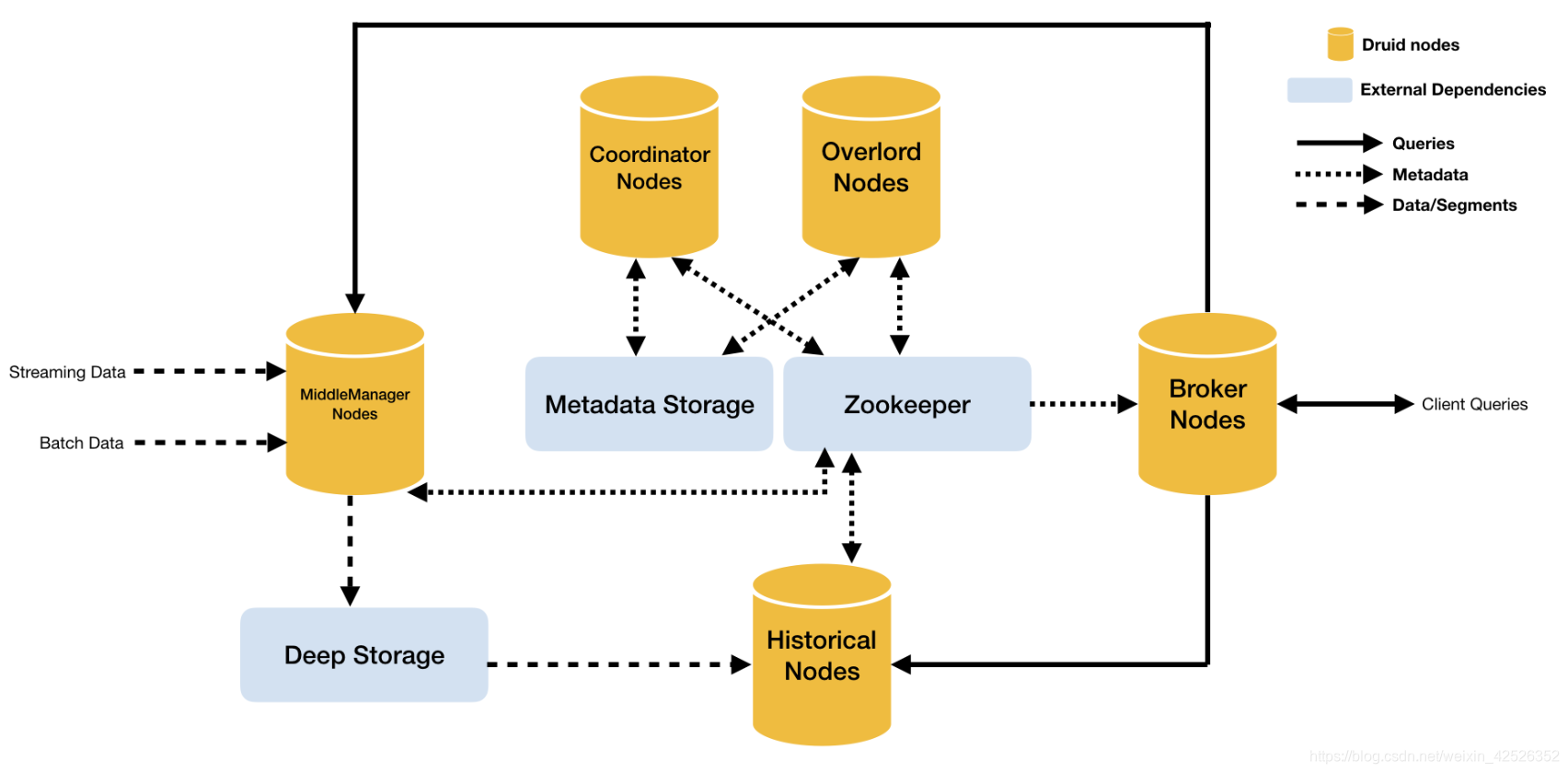
Druid总体包含以下5类节点:
-
中间管理节点(middleManager node):及时摄入实时数据,已生成Segment数据文件。
-
历史节点(historical node):加载已生成好的数据文件,以供数据查询。historical 节点是整个集群查询性能的核心所在,因为historical会承担绝大部分的segment查询。
-
查询节点(broker node):接收客户端查询请求,并将这些查询转发给Historicals和MiddleManagers。当Brokers从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者。
-
协调节点(coordinator node):主要负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期。协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、和为了负载均衡移动数据。
-
统治者(overlord node) :进程监视MiddleManager进程,并且是数据摄入Druid的控制器。他们负责将提取任务分配给MiddleManagers并协调Segement发布。
同时,Druid还包含3类外部依赖:
-
数据文件存储库(DeepStorage):存放生成的Segment数据文件,并供历史服务器下载,对于单节点集群可以是本地磁盘,而对于分布式集群一般是HDFS。
-
元数据库(Metastore),存储Druid集群的元数据信息,比如Segment的相关信息,一般用MySQL或PostgreSQL。
-
Zookeeper:为Druid集群提供以执行协调服务。如内部服务的监控,协调和领导者选举。
4.2 数据结构
DataSource与Segment数据结构,它们共同成就了Druid的高性能优势。
4.2.1 DataSource
若与传统的关系型数据库管理系统( RDBMS)做比较,Druid的DataSource可以理解为 RDBMS中的表(Table)。DataSource的结构包含以下几个方面。
-
时间列( TimeStamp):表明每行数据的时间值,默认使用 UTC时间格式且精确到毫秒级别。这个列是数据聚合与范围查询的重要维度。
-
维度列(Dimension):维度来自于 OLAP的概念,用来标识数据行的各个类别信息。
-
指标列( Metric):指标对应于 OLAP概念中的 Fact,是用于聚合和计算的列。这些指标列通常是一些数字,计算操作通常包括 Count、Sum和 Mean等。
无论是实时数据消费还是批量数据处理, Druid在基于DataSource结构存储数据时即可选择对任意的指标列进行聚合( RollUp)操作。该聚合操作主要基于维度列与时间范围两方面的情况。
相对于其他时序数据库, Druid在数据存储时便可对数据进行聚合操作是其一大特点,该特点使得 Druid不仅能够节省存储空间,而且能够提高聚合查询的效率。
4.2.2 Segment结构
DataSource是一个逻辑概念, Segment却是数据的实际物理存储格式, Druid正是通过 Segment实现了对数据的横纵向切割( Slice and Dice)操作。从数据按时间分布的角度来看,通过参数 segmentGranularity的设置,Druid将不同时间范围内的数据存储在不同的 Segment数据块中,这便是所谓的数据横向切割。
这种设计为 Druid带来一个显而易见的优点:按时间范围查询数据时,仅需要访问对应时间段内的这些 Segment数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
通过 Segment将数据按时间范围存储,同时,在Segment中也面向列进行数据压缩存储,这便是所谓的数据纵向切割。而且在 Segment中使用了Bitmap等技术对数据的访问进行了优化。
5. Presto
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
Presto支持在线数据查询,包括Hive,关系数据库(MySQL、Oracle)以及专有数据存储。一条Presto查询可以将多个数据源的数据进行合并。
主要用来处理响应时间小于1秒到几分钟的交互式查询场景。
5.1 架构
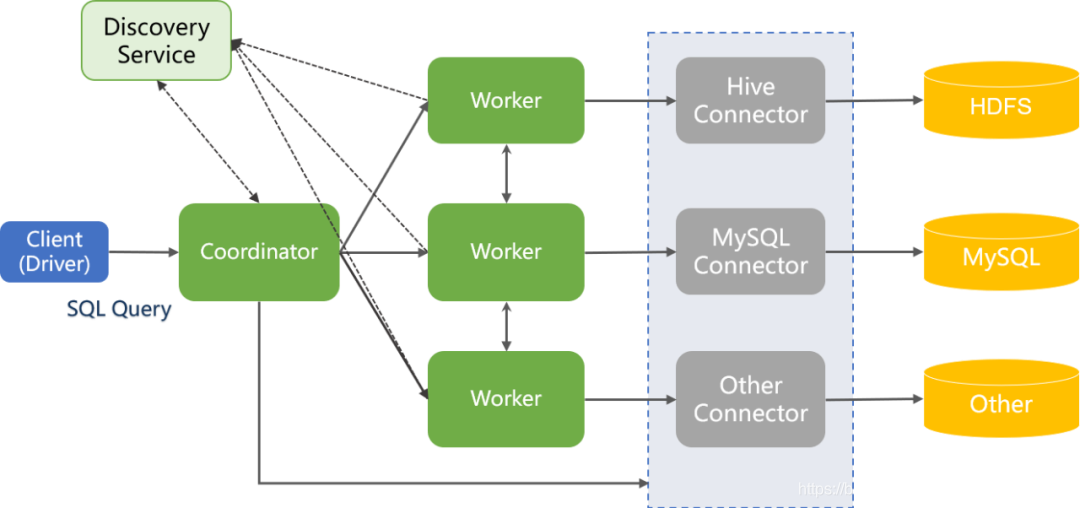
Presto采用典型的master-slave模型:
-
coordinator(master)负责meta管理,worker管理,query的解析和调度,Coordinator服务器是用来解析语句,执行计划分析和管理Presto的Worker结点。Presto安装必须有一个Coordinator和多个Worker。如果用于开发环境和测试,则一个Presto实例可以同时担任这两个角色。
Coordinator跟踪每个Work的活动情况并协调查询语句的执行。Coordinator为每个查询建立模型,模型包含多个Stage,每个Stage再转为Task分发到不同的Worker上执行。Coordinator与Worker、Client通信是通过REST API。 -
worker则负责计算和读写。Worker是负责执行任务和处理数据。Worker从Connector获取数据。Worker之间会交换中间数据。Coordinator是负责从Worker获取结果并返回最终结果给Client。
当Worker启动时,会广播自己去发现 Coordinator,并告知 Coordinator它是可用,随时可以接受Task。
Worker与Coordinator、Worker通信是通过REST API。 -
discovery server, 通常内嵌于coordinator节点中,也可以单独部署,用于节点心跳。在下文中,默认discovery和coordinator共享一台机器。
discovery和coordinator高可用性设计
由于service inventory的使用,监控程序可以在发现discovery挂掉后,修改service inventory中的内容,指向备机的discovery。无缝的完成切换。coordiantor的配置必须要在进程启动时指定,同一个集群中无法存活多个coordinator。因此最好的办法是和discovery配置到一台机器。
secondary机器部署备用的discovery和coordinator。在平时,secondary机器是一个只包含一台机器的集群,在primary宕机时,worker的心跳瞬间切换到secondary。
5.2 数据源
- Connector
Connector是适配器,用于Presto和数据源(如Hive、RDBMS)的连接。你可以认为类似JDBC那样,但却是Presto的SPI的实现,使用标准的API来与不同的数据源交互。
Presto有几个内建Connector:JMX的Connector、System Connector(用于访问内建的System table)、Hive的Connector、TPCH(用于TPC-H基准数据)。还有很多第三方的Connector,所以Presto可以访问不同数据源的数据。
每个Catalog都有一个特定的Connector。如果你使用catelog配置文件,你会发现每个文件都必须包含connector.name属性,用于指定catelog管理器(创建特定的Connector使用)。一个或多个catelog用同样的connector是访问同样的数据库。例如,你有两个Hive集群。你可以在一个Presto集群上配置两个catelog,两个catelog都是用Hive Connector,从而达到可以查询两个Hive集群。 - Catelog
一个Catelog包含Schema和Connector。例如,你配置JMX的catelog,通过JXM Connector访问JXM信息。当你执行一条SQL语句时,可以同时运行在多个catelog。
Presto处理table时,是通过表的完全限定(fully-qualified)名来找到catelog。例如,一个表的权限定名是hive.test_data.test,则test是表名,test_data是schema,hive是catelog。
Catelog的定义文件是在Presto的配置目录中。 - Schema
Schema是用于组织table。把catelog好schema结合在一起来包含一组的表。当通过Presto访问hive或Mysq时,一个schema会同时转为hive和mysql的同等概念。 - Table
Table跟关系型的表定义一样,但数据和表的映射是交给Connector。
6. ClickHouse
是一款MPP架构的列式存储数据库。
6.1 特性
- 完备的DBMS功能
clickhouse拥有完备的管理功能,所以它称得上是一个DBMS,具备DDL、DML、权限控制、数据备份与恢复、分布式管理。 - 列式存储与数据压缩
如果想让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助我们实现上述两点。 - 向量化执行引擎
向量化执行,数据级并行的方式,可以简单地看作一项消除程序中循环的优化。举一个栗子,为了制作n杯果汁,非向量化执行的方式时用1台榨汁机重复循环制作n次,而向量化执行的防止是用n台榨汁机执行一次。 - 多线程与分布式
如果说向量化执行时通过数据级并行的方式提升了性能,那么多线程处理就是通过线程级并行的方式实现了性能的提升。 - 性能强
CPP编写的,代码中大量使用了CPP最新的特性来对查询进行加速
6.2 架构
采用Multi-Slave主从架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。非常适用于多数据中心、异地多活的场景。
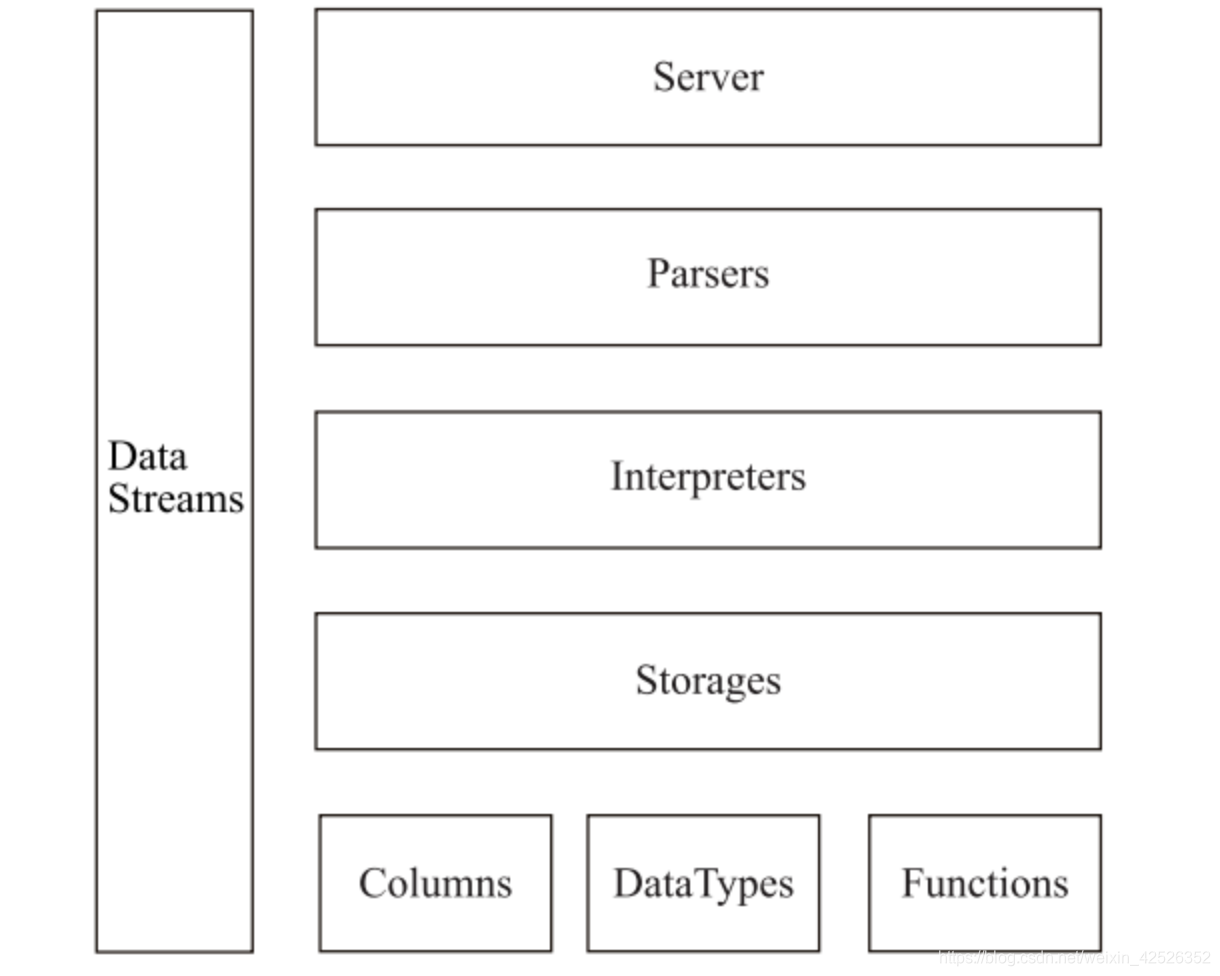
- column
column是clickhouse数据最基础的映射单元,内存中的一列数据由一个column对象表示。但如果需要操作单个具体的数值(单列中的一行数据),则需要使用field对象,field对象代表一个单值。 - datatype
数据的序列化和反序列化工作有datatype负责,虽然负责序列化相关工作,但并不直接负责数据的读取,而是转由从Column或field对象获取。 - parser与interpreter
sql解析层 - functions
主要提供两类函数,普通函数和聚合函数。
7.总结

-
Druid:是一个实时处理时序数据,采用预计聚合的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
-
Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
-
Presto:它没有使用Mapreduce,大部分场景下比HIVE块一个数量级,其中的关键是所有的处理都在内存中完成。
-
Impala:基于内存计算,速度快,支持的数据源没有Presto多。
-
SparkSQL:是spark用来处理结构化的一个模块,它提供一个抽象的数据集DataFrame,并且是作为分布式SQL查询引擎的应用。它还可以实现Hive on Spark,hive里的数据用sparksql查询。
-
clickhouse:一个高达版的Mpp架构系统,比druid自由,比presto快,基本满足即席查询引擎的所有要求。
6.框架选型:
从超大数据的查询效率来看:
ClickHouse>Druid>Kylin>Presto>SparkSQL

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)