Docker环境下的EFK日志分析实践:从Filebeat采集到Kibana可视化的完整部署指南
EFK日志方案:Elasticsearch储存检索,Filebeat轻量采集容器/主机日志,Kibana可视化;Docker-Compose一键部署,7.10.2-oss镜像免授权,支持单节点开发、持久化、元数据增强、basePath定制。适用微服务、云原生日志集中分析,快速部署,成本低,易扩展省。
言简意赅的讲解Elasticsearch、Logstash、Kibana解决的痛点
一、什么是 EFK
在传统的 ELK(Elasticsearch、Logstash、Kibana)日志分析堆栈中,人们往往会觉得 Logstash 过于臃肿,或者想在容器环境下使用更轻量的日志收集解决方案,这时候就衍生出了 EFK:
- Elasticsearch:负责存储和检索日志信息的搜索引擎
- Filebeat:轻量级日志收集器,负责从容器或主机上采集日志并发送到 Elasticsearch
- Kibana:与 Elasticsearch 配合使用的可视化和管理工具
相比 Logstash,Filebeat 占用更少的资源,在 Docker / 容器场景下也更易配置和维护。由于目前很多人都已经将微服务或业务应用容器化,因此 EFK 组合在容器日志采集领域非常常见。
二、为什么选择 OSS 版本(社区版)
Elasticsearch 与 Kibana 有社区版(Open Source Software,OSS)和商业版(Basic/Enterprise/Platinum 等)之分。
- 社区版(OSS 版):不包含 X-Pack 的商业特性,如高级安全、图表分析、机器学习等。但是对于普通的日志检索和可视化等基础场景,OSS 版已经足够使用。
- 商业版:提供更丰富的特性,比如内置认证、集群监控、报警机制、机器学习分析日志趋势等等。
本篇示例所使用的是官方提供的 *-oss:7.10.2 镜像(Elasticsearch OSS 版、Kibana OSS 版、Filebeat OSS 版),如果你需要更高级的功能,可考虑商业版。
三、Docker Compose 配置详解
以下是一个修正后的 Docker Compose 示例文件,它包含了 Elasticsearch、Kibana、Filebeat 三个服务的配置。
- 修复了原有的缩进问题,使之符合 Docker Compose 的标准结构;
- 指明了必要的环境变量;
- 备注了可选的 volumes 设置,以便数据持久化;
- 提供了健康检查(healthcheck)示例。
提示:如果你要在生产环境使用,记得修改默认账号密码(商业版或者自行启用安全插件),以及持久化 Elasticsearch 的数据。
请将以下内容保存为 docker-compose.yml(或你自己喜欢的文件名):
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms512m -Xmx1g # 最小 512MB,最大 1GB
# 如果需要数据持久化,请取消以下注释,并在同级定义一个 volume:
# volumes:
# - es_data:/usr/share/elasticsearch/data
ports:
- "9200:9200"
healthcheck:
# 检查 Elasticsearch 状态是否到达 yellow 状态(单节点集群很难达到 green)
test: ["CMD", "curl", "-f", "http://elasticsearch:9200/_cluster/health?wait_for_status=yellow&timeout=1s"]
interval: 30s
timeout: 10s
retries: 10
start_period: 30s
kibana:
image: docker.elastic.co/kibana/kibana-oss:7.10.2
container_name: kibana
environment:
- csp.enabled=false # 禁用 CSP 插件
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
- csp.strict=false # 禁用 Content Security Policy (CSP)
- ELASTICSEARCH_REQUESTTIMEOUT=120000 # 将请求超时设置为120秒
- server.basePath=/elastic/home # 设置 basePath 为 /elastic/home
- server.rewriteBasePath=true # 启用 basePath 重写
- server.host=0.0.0.0
- csp.warnLegacyBrowsers=false # 禁用对旧版浏览器的 CSP 警告
volumes:
- ./kibana.yml:/usr/share/kibana/config/kibana.yml:ro # 挂载本地 kibana.yml 文件
ports:
- "5601:5601"
depends_on:
elasticsearch:
condition: service_healthy
filebeat:
image: docker.elastic.co/beats/filebeat-oss:7.10.2
container_name: filebeat
user: root
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
volumes:
# 挂载 Docker 日志文件目录
- /var/lib/docker/containers:/var/lib/docker/containers:ro
# 挂载 业务 日志文件目录
- ./log:/log:ro
# 挂载 filebeat 自身日志目录
- ./log/filebeat:/var/log/filebeat
# 挂载 Filebeat 配置文件
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
# Docker 容器信息元数据所需
- /var/run/docker.sock:/var/run/docker.sock
entrypoint: ["/bin/sh", "-c", "chmod 0666 /var/run/docker.sock && filebeat"] # 修改 socket 权限并运行 filebeat
depends_on:
elasticsearch:
condition: service_healthy
# 如果需要持久化数据,需要在同级添加 volumes 节点,比如:
# volumes:
# es_data:
# driver: local
注意:以上示例使用了
:ro(只读)方式挂载部分文件或目录,以确保 Filebeat 对日志文件只读;并在entrypoint里修改了 Docker socket 的权限,这在有些场景下是必须的(否则有权限问题)。
四、Filebeat 配置文件解析与修正
接下来是你提供的 filebeat.yml 文件,已经合并并修复了部分错误。主要注意到你原本的配置里有两处 processors,这可能会导致解析冲突或覆盖。通常我们将所需的 processors 写在同一个 processors 列表中即可,如下所示:
# Filebeat Input Configuration
filebeat.inputs:
- type: container
paths:
- /var/lib/docker/containers/*/*.log # 确保这里的路径包含 .log 文件
json:
keys_under_root: true # 将 JSON 字段直接放置在根字段下
overwrite_keys: true # 如果字段已存在,允许覆盖
add_error_key: true # 如果解析失败,添加 error 字段
- type: log
paths:
- /log/kong/*.log # All kong logs
fields:
container.name: kong # 添加 container.name 字段
fields_under_root: true # 将自定义字段放置在根字段
# Optional: Processors to enhance logs
processors:
- add_docker_metadata:
host: "unix:///var/run/docker.sock" # 添加 Docker 容器的元数据信息
- add_fields:
target: "docker_info"
fields:
container_name: "${docker.container.name}"
container_id: "${docker.container.id}"
# Output Configuration
output.elasticsearch:
hosts: ["http://elasticsearch:9200"] # 指向 Elasticsearch OSS 实例
# Optional: Enable logging for Filebeat
logging:
level: info # 日志级别,可以是 debug、info、warn、error
to_files: true # 日志输出到文件
files:
path: /var/log/filebeat # 日志文件目录
name: filebeat # 日志文件名前缀
keepfiles: 7 # 保留的日志文件数量
permissions: 0644 # 日志文件权限
# Optional: Setup template
setup.template:
name: "filebeat" # 索引模板名称
pattern: "filebeat-*" # 模板匹配的索引模式
# Optional: Disable ILM (Index Lifecycle Management) since OSS version doesn't have it
setup.ilm.enabled: false # 社区版没有 ILM 功能,确保设置为 false
1. input 配置说明
type: container:专门用来采集 Docker 容器输出的日志。注意paths指向/var/lib/docker/containers下所有容器的.log文件。type: log:直接读取/log/kong/*.log文件,可用于采集你自定义的业务日志、Kong 网关日志等。
2. processors 配置说明
add_docker_metadata:让日志中自动带上容器的 metadata(容器名、镜像名等)。add_fields:自定义添加一些字段,比如这里将容器的 name、id 放到docker_info字段下,便于后续检索、可视化。
3. 输出与日志
- 输出到
Elasticsearch,通过output.elasticsearch指定地址。 - 自身日志输出到
/var/log/filebeat,便于排查 Filebeat 的问题。
五、启动与访问
-
启动容器
在含有docker-compose.yml文件的目录下,执行:docker-compose up -dDocker 会自动拉取(或使用已有的)Elasticsearch、Kibana、Filebeat 三个镜像并启动容器。
-
查看容器状态
docker ps确保
elasticsearch,kibana,filebeat均处于Up状态。 -
访问 Kibana
在浏览器中打开http://<宿主机IP>:5601/elastic/home(因为我们将server.basePath设置为了/elastic/home),即可进入 Kibana 页面。 -
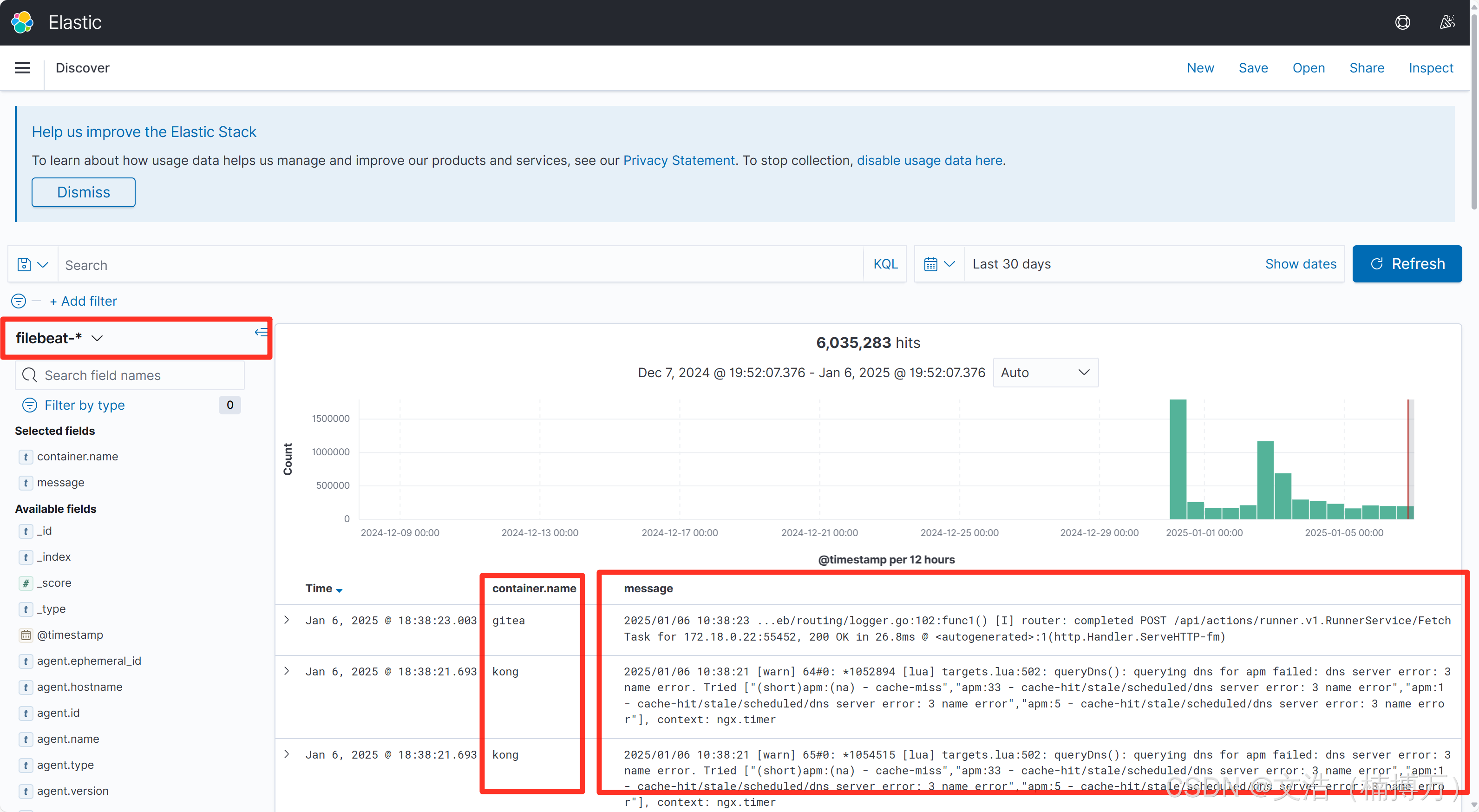
验证日志采集
- 在 Kibana 界面里,进入“Discover”页面,选择
filebeat-*索引(若没出现,需手动创建 Index Pattern)。 - 查看是否已经能搜到来自容器或自定义日志文件的日志。
- 在 Kibana 界面里,进入“Discover”页面,选择
六、更多优化与注意事项
-
持久化数据
- 如果仅是做测试,可以不持久化数据;
- 在生产环境中,请务必给 Elasticsearch 配置
volumes并定期备份,避免数据意外丢失。
-
内存限制
ES_JAVA_OPTS=-Xms512m -Xmx1g是个相对保守的设置;如果机器内存足够,最好将 Elasticsearch 的内存分配为总内存的 50% 左右,但是上限不要超过 32GB(超过会导致 JVM 关闭指针压缩,降低效率)。
-
安全认证
- OSS 版本默认不带高级安全插件,如需密码保护、用户管理,需要自行安装安全插件或切换到商业版;
- 如果需要对外网暴露接口,务必添加安全措施(如 Nginx Proxy + HTTP Basic Auth 或使用反向代理做认证)。
-
多节点集群
- 当前示例使用
discovery.type=single-node,适合开发和测试; - 生产环境往往需要多节点 Elasticsearch 集群,以保证高可用和横向扩展。
- 当前示例使用
-
Kibana basePath
- 本示例启用了
server.basePath=/elastic/home并重写,如果你不喜欢/elastic/home,可以自行修改成别的路径或干脆不设置。
- 本示例启用了
-
Filebeat 的高级配置
- 还可以增加更多 processors,如
drop_fields、geoip等; - 如果你的日志格式较为复杂,可使用 ingest pipelines(需要在 Elasticsearch 中配置)来做高级的日志解析。
- 还可以增加更多 processors,如
七、总结
通过上文的介绍与配置示例,你可以快速搭建一套 EFK (Elasticsearch + Filebeat + Kibana) 日志采集与可视化系统。
- Docker Compose 让部署更简单;
- Elasticsearch 负责日志检索与存储;
- Kibana 提供可视化与简单运维功能;
- Filebeat 以更轻量的方式采集容器或主机日志。
由于本文使用的是 OSS 版本镜像,如果你需要企业级功能,如内置安全、监控、报警、机器学习等高级特性,可以考虑商业版或自行研究如何给 OSS 版本添加插件。但对于大多数日常使用场景来说,OSS 版足以支撑常规的日志检索与展示需求。
通过上述内容,你就已经基本理解了这个方法,基础用法我也都有展示。如果你能融会贯通,我相信你会很强
Best
Wenhao (楠博万)

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)